Rekko Challenge — как занять 2-е место в конкурсе по созданию рекомендательных систем
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-06-05 13:05
машинное обучение новости, большие данные big data, поисковые системы
Всем привет. Моя команда в Тинькофф занимается построением рекомендательных систем. Если вы довольны вашим ежемесячным кэшбэком, то это наших рук дело. Также мы построили рекомендательную систему спецпредложений от партнеров и занимаемся индивидуальными подборками Stories в приложении Tinkoff. А еще мы любим участвовать в соревнованиях по машинному обучению чтобы держать себя в тонусе.
На Boosters.pro в течении двух месяцев с 18 февраля по 18 апреля проходило соревнование по построению рекомендательной системы на реальных данных одного из крупнейших российских онлайн-кинотеатров Okko. Организаторы преследовали цель улучшить существующую рекомендательную систему. На данный момент соревнование доступно в режиме песочницы, в которой вы можете проверить свои подходы и отточить навыки в построении рекомендательных систем.
Описание данных
Доступ к контенту в Okko осуществляется через приложение на телевизоре или смартфоне, либо через веб-интерфейс. Контент можно взять в аренду®, купить(P) или посмотреть по оформленной подписке(S). Организатор соревнования предоставил данные о просмотрах за N дней (N > 60), дополнительно была доступна информация о проставленных рейтингах и добавлениях в закладки. Стоит иметь в виду одну важную деталь, если пользователь посмотрел один фильм несколько раз или несколько серий сериала, то в табличке будет зафиксирована лишь дата последней транзакции и суммарное время потраченное на единицу контента.
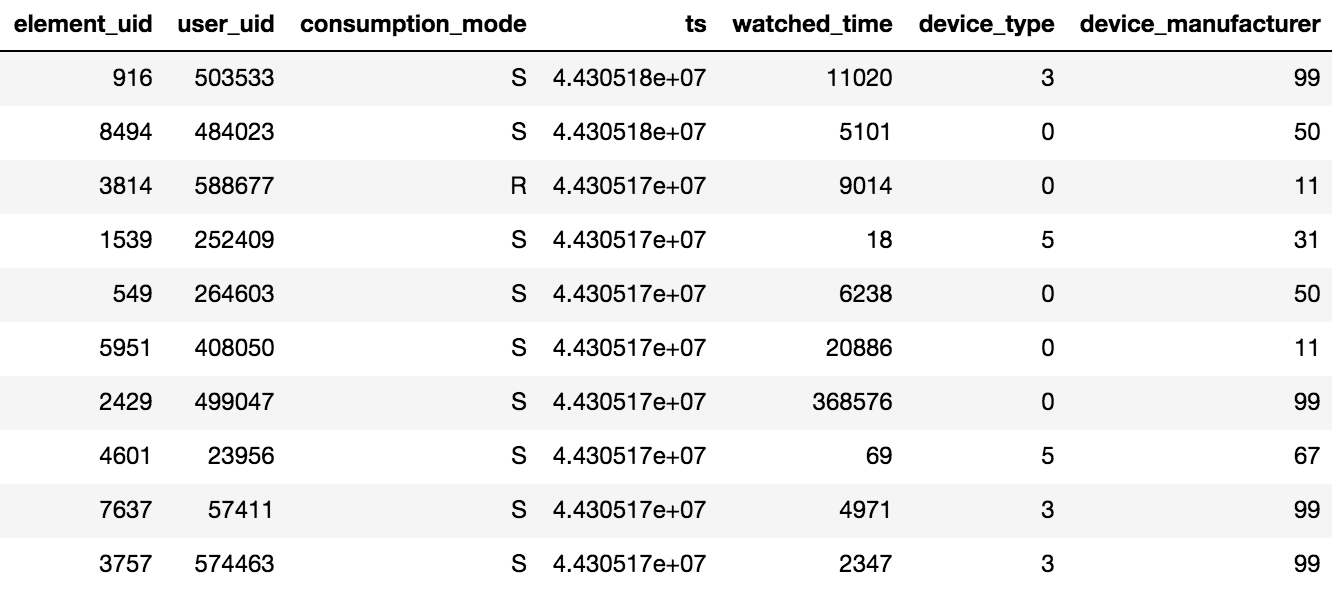
Было предоставлено порядка 10 миллионов транзакций, 450 тысяч оценок и 950 тысяч фактов добавлений в закладки по 500 тысячам пользователей.
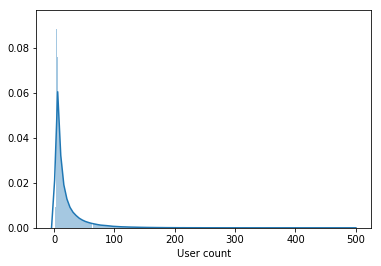
В выборке содержатся не только активные пользователи, но и пользователи посмотревшие пару фильмов за весь период.
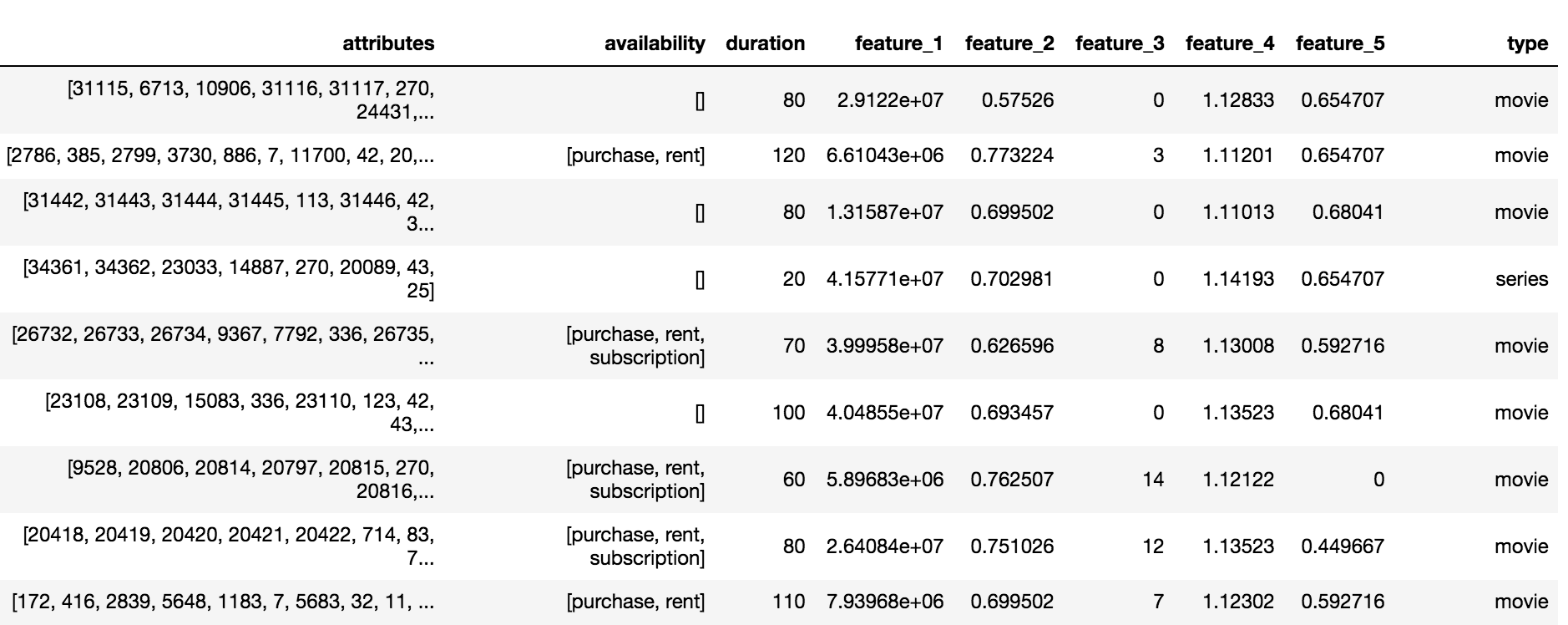
Каталог Okko содержит контент трех типов: фильмы(movie), сериалы(series) и многосерийные фильмы(multipart_movie), всего 10200 объектов. По каждому объекту был доступен набор анонимизированных атрибутов(attributes) и признаков(feature_1,… ,feature_5), доступность по подписке, аренде или покупке и длительность.
Целевая переменная и метрика
В задаче требовалось предсказать множество контента, который пользователь потребит за следующие 60 дней. Считается, что пользователь потребит контент, если он:
- Купит его или возьмет в аренду
- Посмотрит больше половины фильма по подписке
- Посмотрит больше трети сериала по подписке
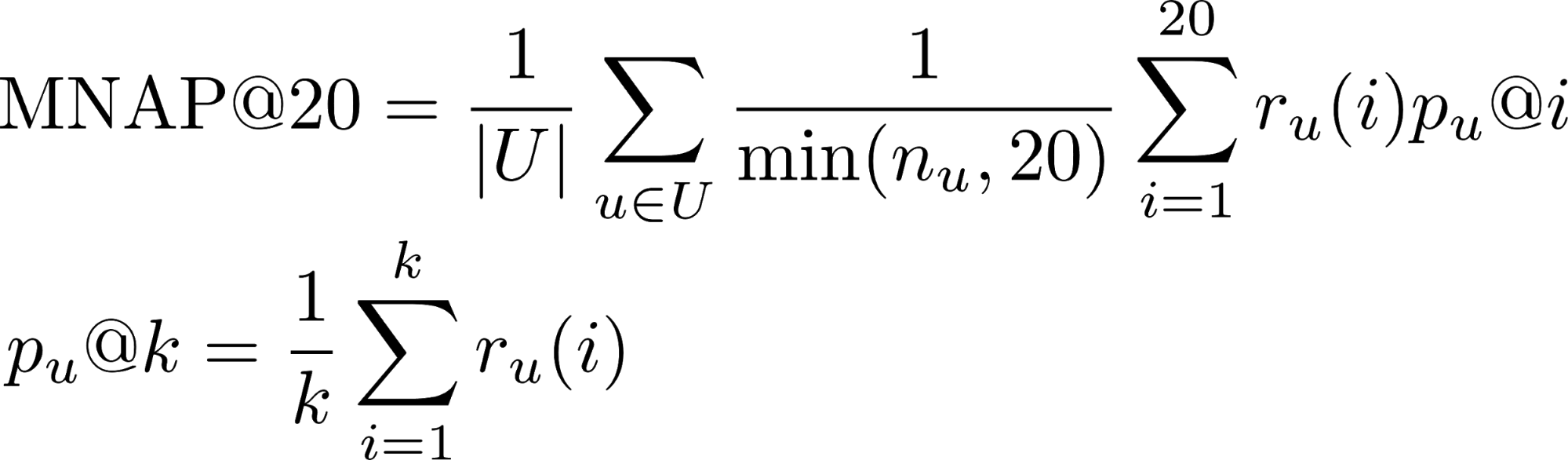
- r_u(i) — потребил ли пользователь u контент, предсказанныи? ему на месте i (1 либо 0)
- n_u — количество элементов, которые пользователь потребил за тестовыи? период
- U — множество тестовых пользователеи?
Подробнее о метриках для задачи ранжирования можно узнать из этого поста.
Большинство пользователь досматривают фильмы до конца, поэтому по транзакциям доля положительного класса составляет 65%. Оценка качества работы алгоритма производилась по подмножеству из 50 тысяч пользователей из представленной выборки.
Агрегированный рейтинг
Решение соревнование началось с агрегации всех интеракций пользователей с контентом в единую шкалу рейтинга. Предполагалось, что если пользователь купил контент, то это означает максимальную заинтересованность. Фильм короче сериала, следовательно за просмотр сериала целиком нужно давать больше баллов. В итоге агрегированный рейтинг формировался по следующим правилам:
- Доля просмотра фильма * 5
- Доля просмотра сериала * 10
- [Добавление в закладки фильма] * 0.5
- [Добавление в закладки сериала] * 1.5
- [Покупка/аренда контента] * 15
- Рейтинг + 2
Модель первого уровня
Организаторы предоставили базовое решение на основе коллаборативной фильтрации с весами Tf-IDF. Добавление всех типов интеракций в агрегированный рейтинг, увеличение числа ближайших соседей с 20 до 150 и замена Tf-IDF на веса BM25 выбило порядка 0.03 на LB(Leader Board).
Вдохновившись постом команды, занявшей 3-е место на RecSys Challenge 2018, я выбрал модель LightFM c WARP лоссом в качестве второй базовой модели. LightFM c подобранным гипер-параметрами: learning_rate, no_components, item_alpha, user_alpha, max_sampled дал 0.033 на LB.

Валидация модели производилась по времени: в трейн попадали первые 80% интеракций, оставшиеся 20% в валидацию. Для сабмита на LB отдельно обучалась модель на всем датасете с параметрами подобранными на валидации.
Блендинг моделей
В предыдущем этапе, получилось построить два сильных бэйзлайна, более того их рекомендаций пересекались в среднем по 60 процентам рекомендованного контента. Если есть две сильных и одновременно слабо скоррелированных модели, то разумным шагом является их блендинг.
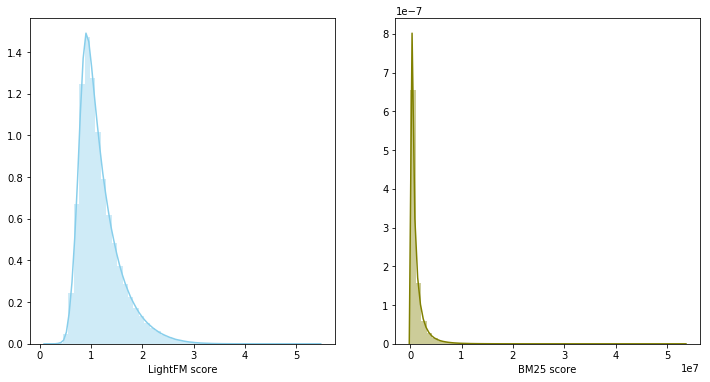
В данном случае скоры моделей относятся к разным распределениям и имеют разный масштаб, поэтому было принято решение использовать сумму рангов для объединения двух моделей. Блендинг моделей дал 0.0347 на LB.

Модель второго уровня
В рекомендательных системах часто используется двухуровневый подход для построения моделей: сначала отбирается top кандидатов простой моделью первого уровня, далее выбранный top ранжируется заново более сложной моделью с добавлением большого числа признаков.

Датасет разбивался по времени на обучающую и валидационную части. На валидационную часть для каждого пользователя собиралась подборка из рекомендаций, состоящая из объединения top200 предсказаний моделей первого уровня с исключением уже просмотренных фильмов. Далее, требовалось научить модель переранжировать получившийся топ для каждого пользователя. Задача формулировалась в терминах бинарной классификации. Пара (пользователь, контент) относилась к положительному классу только в том случае, если пользователь потребил контент за валидационный период. В качестве модели второго уровня использовался градиентный бустинг, а именно пакет LightGBM.
Признаки
Модели первого уровня для пар (пользователь, контент) оценивают релевантность в виде скора, отсортировав который по убыванию можно получить ранг. Модель обученная на признаках ранг и скор в совокупности с признаками из каталога контента выбили 0.0359 на LB.
Из формы распределения первого из анонимизированных признаков было заключено, что он является датой появления фильма в каталоге, следовательно модель сильно переобучалась на этот признак при выбранной схеме валидации. Удаление признака из выборки дало прирост на LB до 0.0367
Модель LightFM кроме предсказания релевантности контента для пользователя возвращает два вектора: item bias и user bias, коррелирующие со степенью популярности контента и числом просмотренных пользователем фильмов соответственно. Добавление признаков подняло скор на LB до 0.0388.
Присваивать ранг для пары (пользователь, контент) можно либо до, либо после удаления уже просмотренных фильмов. Изменения метода на последний обеспечило прирост на LB до 0.0395.
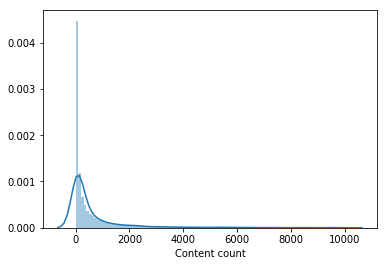
Значительную часть каталога фильмов практически никто не смотрел. Из выборки для обучения модели второго уровня был удален контент, который посмотрело менее 100 пользователей, что сократило каталог в два раза. Удаление непопулярного контента сделало подборку от моделей первого уровня более релевантной и только после этого вектора пользователей из LightFM улучшили скор на валидации и дали прирост на LB до 0.0429.
Далее, был добавлен признак — пользователь добавил фильм в закладки, но не посмотрел за трейновый период, который поднял скор на LB до 0.0447. Также были добавлены признаки о дате первой и последней транзакций, они подняли скор до 0.0457 на LB.

Будем считать эту модель финальной. Наиболее значимыми оказались признаки от моделей первого уровня и анонимизированные признаки из каталога контента.
К финальной модели не дали прироста следующие признаки:
- число закладок + доля просмотренного контента из закладок — 0.0453 LB
- число купленных фильмов 0.0451 LB
Но при бленднинге с финальной моделью выбили 0.0465 на LB. Воодушевившись результатом от блендинга были отдельно обучены следующие модели:
- c различными долями обучающей выборки для модели первого уровня. Разбиение 90%/10% дало прирост, в отличие от разбиений 95%/5% и 70%/30%.
- с измененным методом агрегации рейтинга.
- с добавлением непопулярных фильмов в обучающую выборку для модели второго уровня. Для каждой единицы контента составлялась подборка из 1000 пользователей.
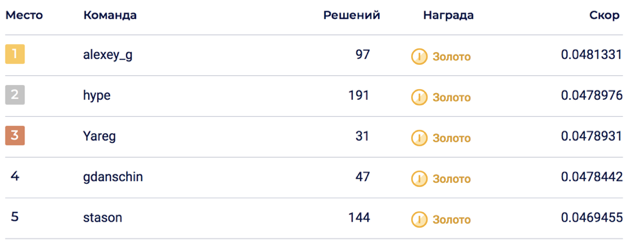
Финальный блендинг 6 моделей позволил добиться 0.0469678 на LB, что соответствовало 5-му месту.

На private части случился шейк ап, подкинувший решение на 2-е место. Думаю, что решение оказалось устойчивым благодаря блендингу большого числа моделей.
Не зашло
В процессе решения соревнования было сгенерировано много признаков, которые казалось, что точно должны зайти, но увы. Признаки и подходы в которые верилось больше всего:
- Анонимизированные атрибуты контента. Достоверно не было известно, что в них содержится, но все участники соревнования считали, что в них содержится информация об актерах, режиссерах, композиторах… В своем решения я пробовал добавлять их в нескольких форматах: топ популярных в качестве бинарных признаков, раскладывать матрицу контент-атрибуты при помощи LightFM и BigARTM, а далее вытаскивать вектора и добавлять в модель второго уровня.
- Вектора контента из модели LigthFM в модели второго уровня.
- Атрибуты устройств, с которых пользователь смотрел контент.
- Понижение весов популярного контента для модели второго уровня.
- Доля фильмов/сериалов по отношению к общему числу просмотренного контента.
- Ранжирующие метрики из CatBoost.
Интересные факты о соревновании
- Top1 решение оказалось хуже продуктовой модели okko 0.048 vs 0.062. Стоит иметь в виду, что продуктовая модель уже была запущена на момент сбора выборки.
- Примерно через неделю после начала соревнования изменили датасет, тем кто участвовал с самого начала добавили 30 сабмитов, которые неожиданно сгорели после мерджа команд.
- Валидация не всегда коррелировала с LB, что говорило о возможном шейк апе.
Код решения
Решение доступно на github в виде двух jupyter-ноутбуков: агрегация рейтинга, обучение моделей первого и второго уровней. Решение 3-го места также доступно на github.
Решение организаторов
Вместо тысячи слов прикладываю топ фичей организаторов.
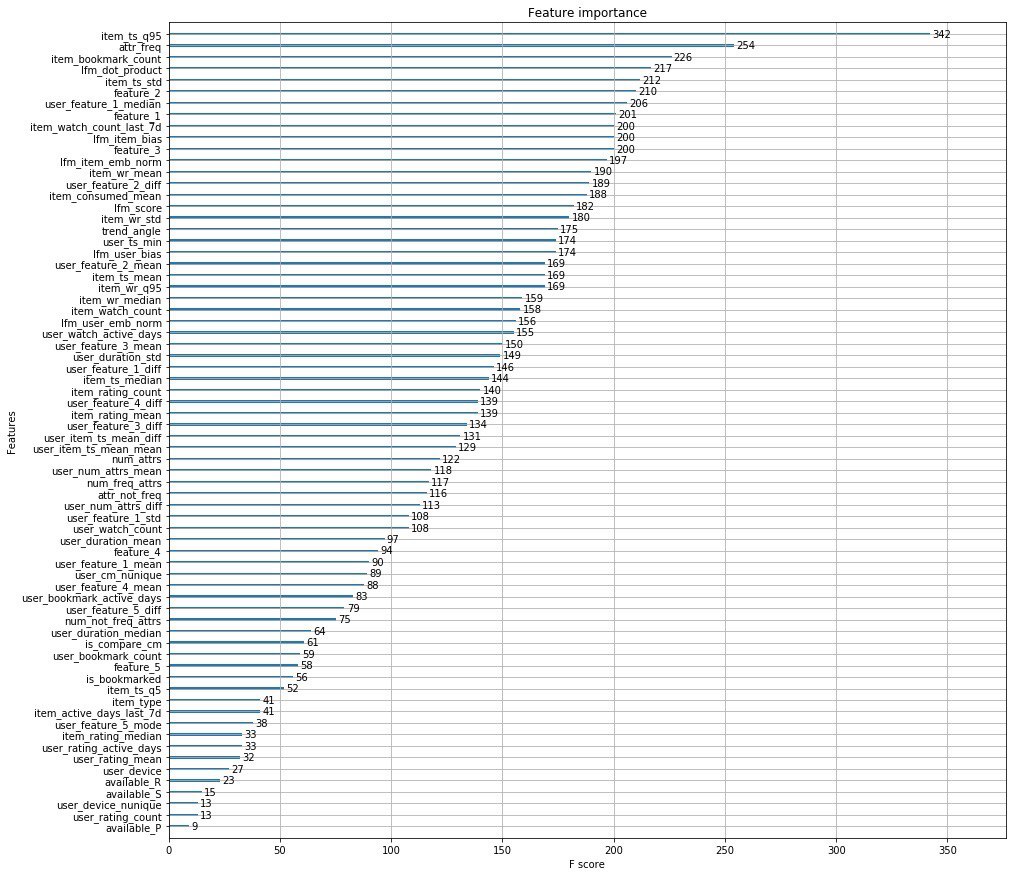
В дополнении ребята из Окко выпустили статью в которой рассказывают о этапах развития своего рекомендательного движка.
P.S. тут можно посмотреть выступление на Data Fest 6 об этом решении задачи.
Источник: habr.com