Обобщенные Языковые Модели
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-06-24 12:51


В качестве продолжения встраивания слов мы обсудим модели изучения контекстуализированных векторов слов, а также новую тенденцию в больших неконтролируемых предварительно обученных языковых моделях, которые достигли потрясающих результатов SOTA по различным языковым задачам.
[Обновлено 2019-02-14: добавить ULMFiT и OpenAI GPT-2 .]

Инжир. 0. Я думаю, это Elmo & Bert? (Источник изображения: здесь)
Мы видели удивительный прогресс в НЛП в 2018 году. Крупномасштабные предварительно обученные языковые режимы, такие как OpenAI GPT и BERT, достигли высокой производительности в различных языковых задачах с использованием архитектуры универсальной модели. Идея аналогична тому, как предварительная подготовка ImageNet classification помогает многим задачам видения (*). Этот простой и мощный подход в НЛП, даже лучше, чем предварительная подготовка к классификации видения, не требует маркированных данных для предварительной подготовки, что позволяет нам экспериментировать с увеличенным масштабом обучения до самого нашего предела.
( * ) Хотя недавно он и др. (2018) обнаружил, что предварительное обучение может не потребоваться для задачи сегментации изображений.
В моем предыдущем сообщении NLP о внедрении word введенные вложения не зависят от контекста-они изучаются на основе параллелизма word, но не последовательного контекста. Поэтому в двух предложениях “ я ем яблоко ” и “у меня есть яблочный телефон” два слова "яблоко" относятся к очень разным вещам, но они все равно будут иметь один и тот же вектор встраивания слов.
Несмотря на это, раннее внедрение встраиваний слов в решение проблем заключается в использовании их в качестве дополнительных функций для существующей модели, специфичной для задачи, и таким образом улучшение ограничено.
В этом посте мы обсудим, как были предложены различные подходы, чтобы сделать вложения зависимыми от контекста и сделать их проще и дешевле применять к нижестоящим задачам в общем виде.
бухточка
CoVe (McCann et al. 2017), сокращенно от контекстуальных векторов слов, представляет собой тип вложений слов, изучаемых кодировщиком в модели машинного перевода seq-to-seq. В отличие от традиционных встраиваний слов , представленных здесь, представления слов CoVe являются функциями всего входного предложения.
NMT Recap
Здесь модель нейронной машинной трансляции (NMT ) состоит из стандартного двухслойного двунаправленного LSTM-кодера и двухслойного однонаправленного LSTM-декодера. Он предварительно обучен англо-немецкому переводу. Кодер изучает и оптимизирует векторы встраивания английских слов, чтобы перевести их на немецкий язык. С интуицией, что кодировщик должен захватить семантические и синтаксические значения высокого уровня прежде, чем преобразовать слова в другой язык, выходные данные кодировщика используются, чтобы обеспечить контекстуализированные вложения слова для различных последующих языковых задач.
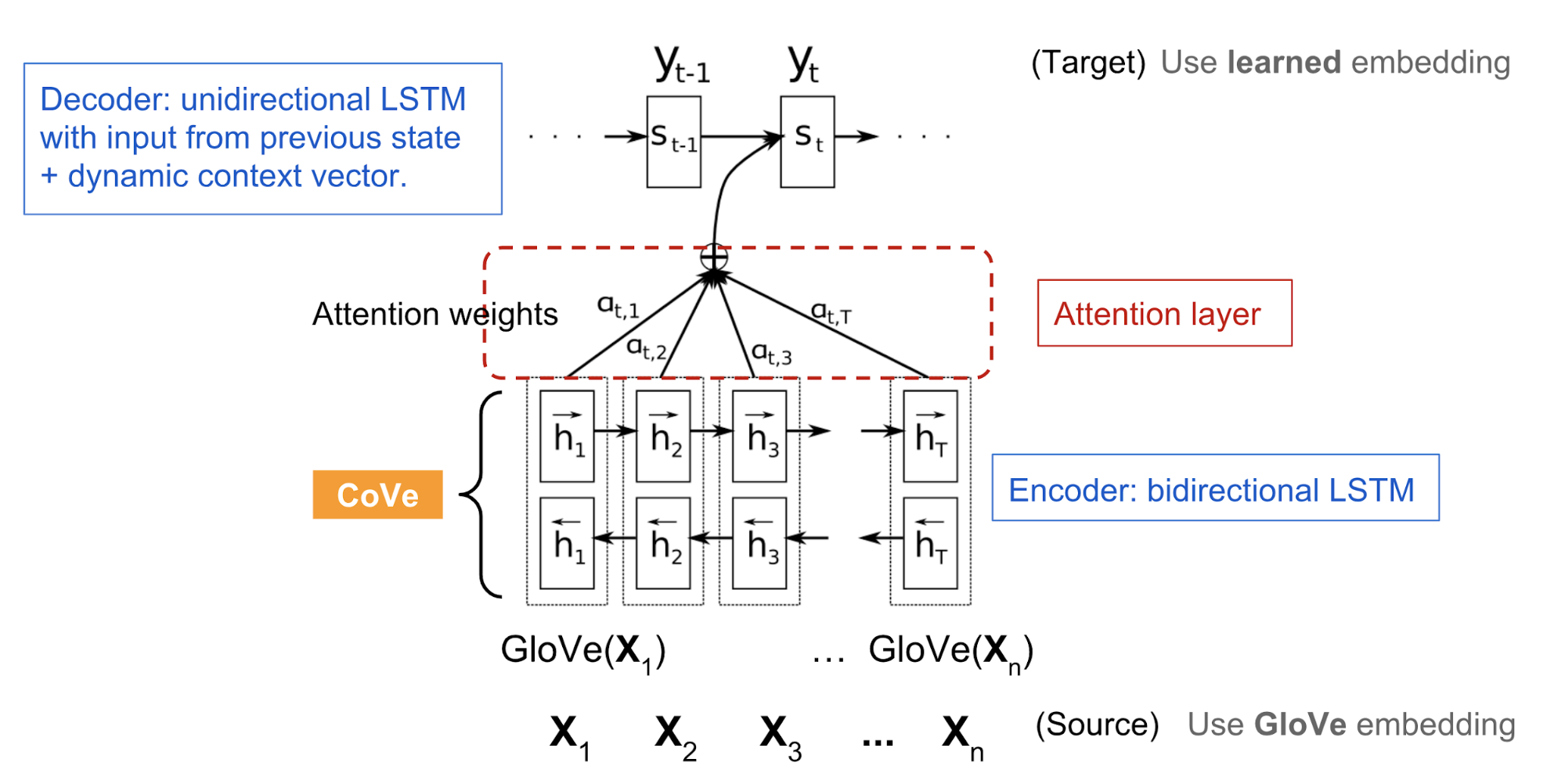
Инжир. 1. Базовая модель NMT, используемая в CoVe.
- Последовательность северный
слова на языке оригинала (английский): x = [ x 1,..., x n]
- .
- A sequence of м
- words in target language (German): y = [ y 1,..., y m]
- .
- The GloVe vectors of source words: Перчатка (x)
- .
- Randomly initialized embedding vectors of target words: z = [ z 1,..., z m]
- .
- The biLSTM encoder outputs a sequence of hidden states: h = [ h 1,..., h n ] = biLSTM ( перчатка ( x ))
- and h t = [ h ? t; h ? t] where the forward LSTM computes h ? t = LSTM ( x t, h ? t-1) and the backward computation gives us h ? t = LSTM (x t, h ? t-1)
- .
- The attentional decoder outputs a distribution over words: p (y T ? H , y 1,..., y t-1)
- where Ч is a stack of hidden states {h}
- along the time dimension:
decoder hidden state: stattention weights: ?tcontext-adjusted hidden state: h~tdecoder output: p(yt?H,y1,…,yt?1)=LSTM([zt?1;h~t?1],st?1)=softmax(H(W1st+b1))=tanh(W2[H??t;st]+b2)=softmax(Wouth~t+bout)
Использование CoVe в задачах Нисходящего Потока
Скрытые состояния NMT-кодера определяются как контекстные векторы для других языковых задач:
CoVe(x)=biLSTM(GloVe(x))
The paper proposed to use the concatenation of GloVe and CoVe for question-answering and classification tasks. GloVe learns from the ratios of global word co-occurrences, so it has no sentence context, while CoVe is generated by processing text sequences is able to capture the contextual information.
v = [ GloVe (x); CoVe (x )]
Учитывая нижестоящую задачу, мы сначала генерируем конкатенацию векторов GloVe + CoVe входных слов, а затем подаем их в конкретные модели задач в качестве дополнительных функций.
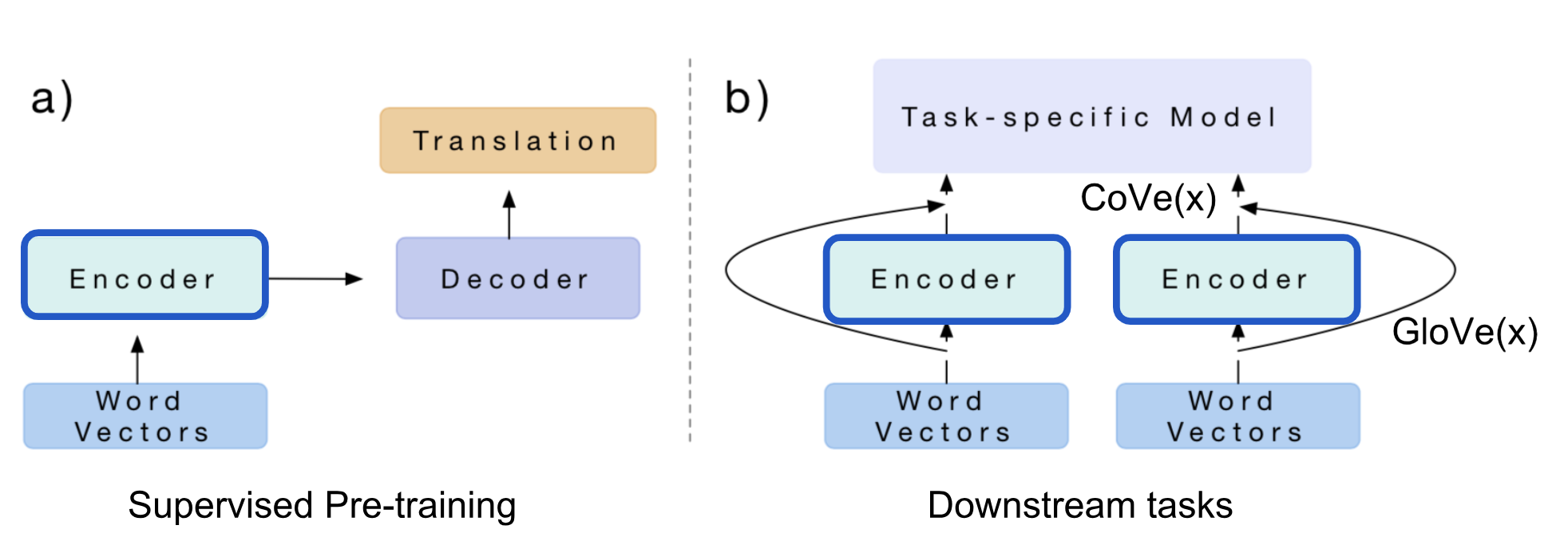
Инжир. 2. Вложения CoVe генерируются кодировщиком, обученным задаче машинного перевода. Кодировщик можно заткнуть в любую идущую дальше по потоку задач-специфическую модель. (Источник изображения: оригинальная бумага)
Резюме: ограничение CoVe очевидно: (1) предварительное обучение ограничено доступными наборами данных по контролируемой задаче перевода; (2) вклад CoVe в конечную производительность ограничен архитектурой модели, специфичной для задачи.
В следующих разделах мы увидим, что ELMo преодолевает проблему (1) путем неконтролируемого предварительного обучения, а OpenAI GPT & BERT еще больше преодолевает обе проблемы путем неконтролируемого предварительного обучения + с использованием архитектуры генеративной модели для различных нижестоящих задач.
ELMo
ELMo, сокращение от Embeddings from Language Model (Peters, et al, 2018 ) изучает контекстуализированное представление слов, предварительно обучая языковую модель неконтролируемым образом.
Двунаправленная Языковая Модель
Двунаправленная языковая модель (biLM) является основой для ELMo. Пока входной сигнал последовательность северный
жетоны, (x 1,..., x n)языковая модель учится предсказывать вероятность следующего токена с учетом истории.
В прямом проходе журнал содержит слова перед целевым токеном,
p (x 1 , ... , x n ) = ? i = 1 n p ( x i ? x 1,..., x i-1)
В обратном проходе журнал содержит слова после целевого маркера,
p (x 1 , ... , x n ) = ? i = 1 n p ( x i ? x i + 1,..., x n)
Предсказания в обоих направлениях моделируются многослойными LSTMs со скрытыми состояниями h ? i, ?
и h ? i, ? для входного маркера xi на уровне слоя ? = 1,..., L. Скрытое состояние последнего слоя h i, L = [ h ? i , L ; h ? i, L] используется для вывода вероятностей по токенам после нормализации softmax. Они совместно используют слой внедрения и слой softmax, параметризованный ?е и ?ссоответственно.
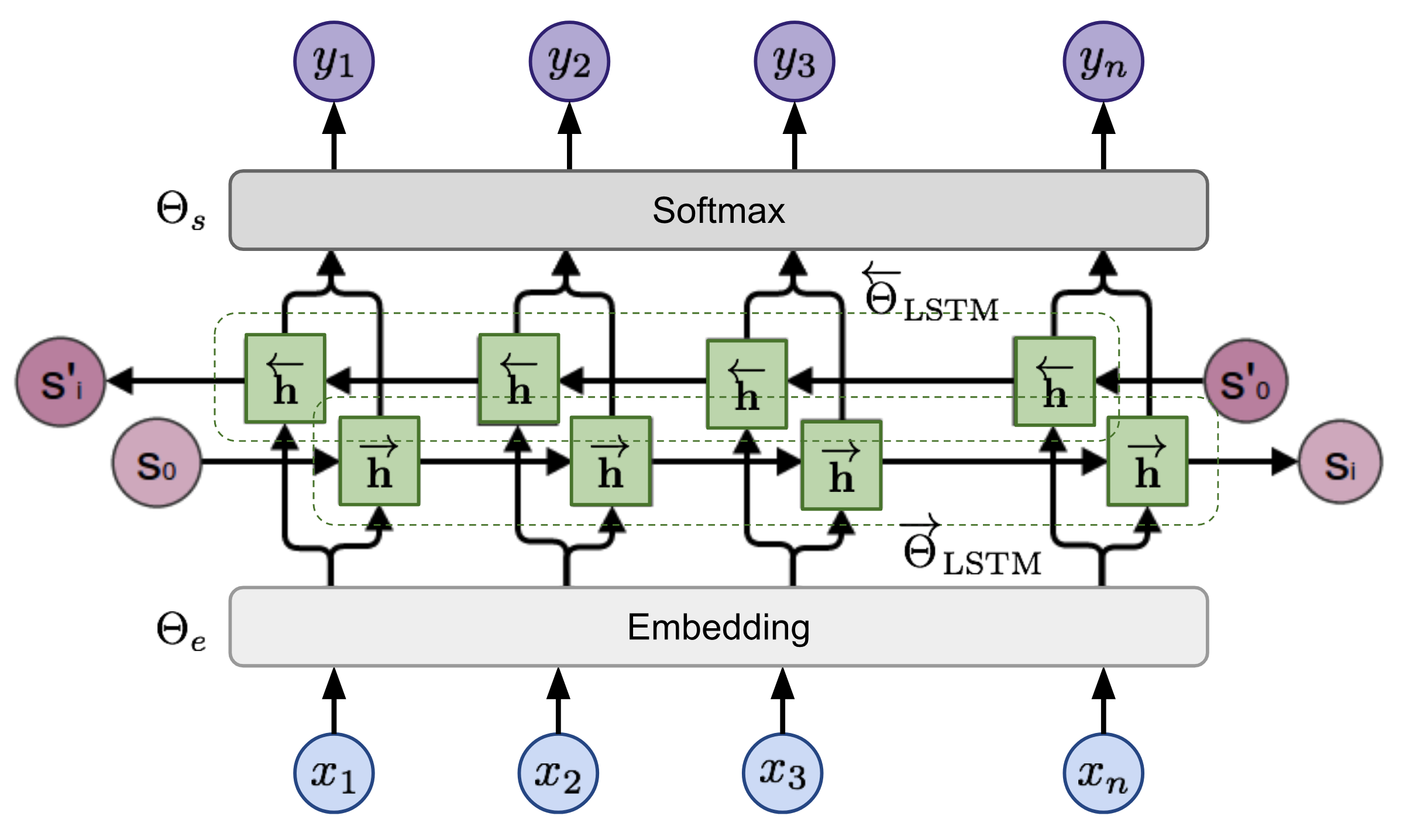
Инжир. 3. Базовая модель biLSTM ELMo. (Источник изображения: воссозданный на основе рисунка в” нейронных сетях, типах и функциональном программировании " Кристофера Олаха .)
Модель обучена минимизировать отрицательное логарифмическое правдоподобие (= максимизировать логарифмическое правдоподобие для истинных слов) в обоих направлениях:
Л=??я=1н(входп(хя?х1,...,хя?1;?е,??ЛСТМ,?С)+журналп(хя?хя+1,...,хн;?е,??ЛСТМ,?с))
Представления ELMo
На вершине Л
- layer biLM, ELMo складывает все скрытые состояния между слоями вместе, изучая линейную комбинацию задач. Скрытое представление состояния для маркера xi содержит 2L+1векторные иллюстрации:
R i = { h i, ? ? ? = 0,..., L}
где h 0, ? вывод слоя внедрения и h i, ? = [ h ? i, ? ; h ? i, ?].
Вес, s задача
, в линейной комбинации изучаются для каждой конечной задачи и нормируются softmax. Масштабный коэффициент ? задачаиспользуется для исправления рассогласования между распределением скрытых состояний biLM и распределением представлений конкретной задачи.
v i = f (r i ; ? task ) = ? task ? ? = 0 l s Task I h i , ?
Чтобы оценить, какая информация захватывается скрытыми состояниями на разных уровнях, ELMo применяется к семантически-интенсивным и синтаксически-интенсивным задачам соответственно с использованием представлений на разных уровнях biLM:
- Семантическая задача: задача устранения неоднозначности смысла слова (WSD) подчеркивает значение слова, данного контексту. Верхний слой biLM лучше справляется с этой задачей, чем первый слой.
- Задача синтаксиса: задача тегирования части речи (POS) направлена на то, чтобы вывести грамматическую роль слова в одном предложении. Более высокая точность может быть достигана путем использование слоя biLM первого чем верхний слой.
Сравнительное исследование показывает, что синтаксическая информация лучше представлена на более низких уровнях, а семантическая информация-на более высоких. Потому что различные слои, как правило, несут разный тип информации, укладка их вместе помогает .
Использование ELMo в последующих задачах
Подобно тому, как CoVe может помочь различным нижестоящим задачам, векторы внедрения ELMo включены во входные или более низкие уровни моделей, специфичных для задач. Более того, для некоторых задач (т. е. SNLI и SQuAD , но не SRL) добавление их в выходной уровень тоже помогает.
Улучшения, поднятые ELMo, являются самыми большими для задач с небольшим контролируемым набором данных. С ELMo, мы можем также достигнуть подобного представления с гораздо меньше обозначенными данными.
Реферат: языковая модель предварительного обучения является неконтролируемой, и теоретически предварительное обучение может быть увеличено настолько, насколько это возможно, поскольку немаркированные текстовые корпуса в изобилии. Тем не менее, он по-прежнему зависит от моделей, настроенных для задач, и, таким образом, улучшение является только инкрементным, в то время как поиск хорошей архитектуры модели для каждой задачи остается нетривиальным.
Перекрестное Обучение
В ELMo неконтролируемое предварительное обучение и обучение по конкретным задачам происходит для двух независимых моделей на двух отдельных этапах обучения. Перекрестное обучение (abbr. CVT; Clark et al., 2018) объединяет их в одну единую полу-контролируемую процедуру обучения, где представление кодера biLSTM улучшается как контролируемым обучением с маркированными данными, так и неконтролируемым обучением с немаркированными данными о вспомогательных задачах.
Архитектура Модели
Модель состоит из двухслойного двунаправленного кодера LSTM и основного модуля прогнозирования. Во время обучения модель подается с маркированными и немаркированными пакетами данных поочередно.
- На примерах с метками все параметры модели обновляются с помощью стандартного контролируемого обучения. Потеря-стандартная перекрестная энтропия.
- На немаркированных примерах основной модуль предсказания все еще может создать “мягкую” цель, хотя мы не можем точно знать, насколько они точны. В нескольких вспомогательных задачах предиктор видит и обрабатывает только ограниченный вид входных данных, например, используя только представление скрытого состояния кодера в одном направлении. Ожидается, что выходные данные вспомогательной задачи будут соответствовать основной цели прогнозирования для полного представления входных данных.
Таким образом, кодер вынужден перегонять знание полного контекста в частичное представление. На этом этапе кодер biLSTM является обратным, но основной модуль прогнозирования является фиксированным . Потери сводятся к минимизации расстояния между вспомогательными и первичными прогнозами.
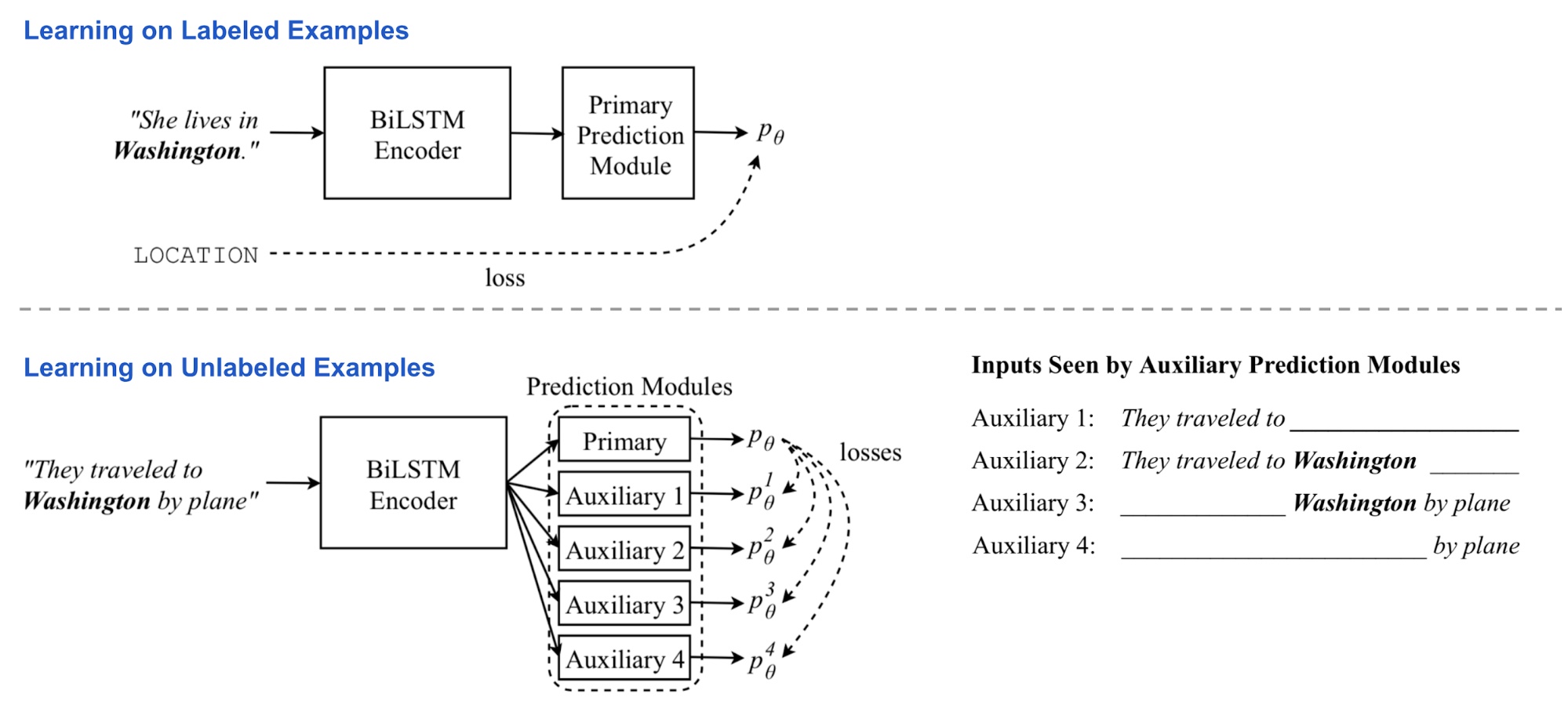
Инжир. 4. Обзор полу-контролируемой языковой модели перекрестного обучения. (Источник изображения: оригинальная бумага)
Многозадачное Обучение
При одновременном обучении нескольким задачам CVT добавляет несколько дополнительных первичных моделей прогнозирования для дополнительных задач. Все они используют один и тот же кодер представления предложений. Во время контролируемой тренировки, как только одна задача случайно выбрана, параметры в своих соответствуя предикторе и кодировщике представления уточнены. С unlabeled образцами данных, шифратор оптимизирован совместно через все задачи путем уменьшать разницы между вспомогательными выходами и главным предсказанием для каждой задачи.
Многозадачное обучение поощряет лучшую общность представления и в то же время создает хороший побочный продукт: все задачи-помеченные примеры из немаркированных данных. Они являются ценными метками данных, учитывая, что метки перекрестных задач полезны, но довольно редки.
Использование CVT в последующих задачах
Теоретически модуль первичного прогнозирования может принимать любую форму, общую или специфичную для конкретной задачи. Примеры, представленные в резюме, включают оба случая.
В задачах последовательного тегирования (классификация для каждого токена), таких как Ner или POS, модуль предиктора содержит два полностью связанных слоя и слой softmax на выходе для получения распределения вероятности по меткам классов. Для каждого токена xi
, берем соответствующие скрытые состояния в двух слоях, h (i) 1 и h (i) 2:
p ? (y i ? x i ) = NN (h (i)) = NN ([ h (i ) 1 ; h (i ) 2]) = softmax (W ? ReLU (W ' ? [ h (i) 1; h (i ) 2 ]) + b)
Вспомогательные задачи подаются только с прямым или обратным состоянием LSTM на первом уровне. Поскольку они наблюдают только частичный контекст, либо слева, либо справа, они должны учиться как языковая модель, пытаясь предсказать следующий токен с учетом контекста.
fwdИbwdвспомогательные задачи только принимают одно направление.futureИpastзадачи делают один шаг дальше в прямом и обратном направлении, соответственно.ппереднеприводных?(ГЯ?хя)пназад?(ГЯ?хя)пбудущем?(ГЯ?хя)ппрошлом?(ГЯ?х, я)=ННпереднеприводных(ч?(я))=ННназад(ч?(я))=ННбудущем(ч?(я?1))=ННпрошлом(ч?(я+1))
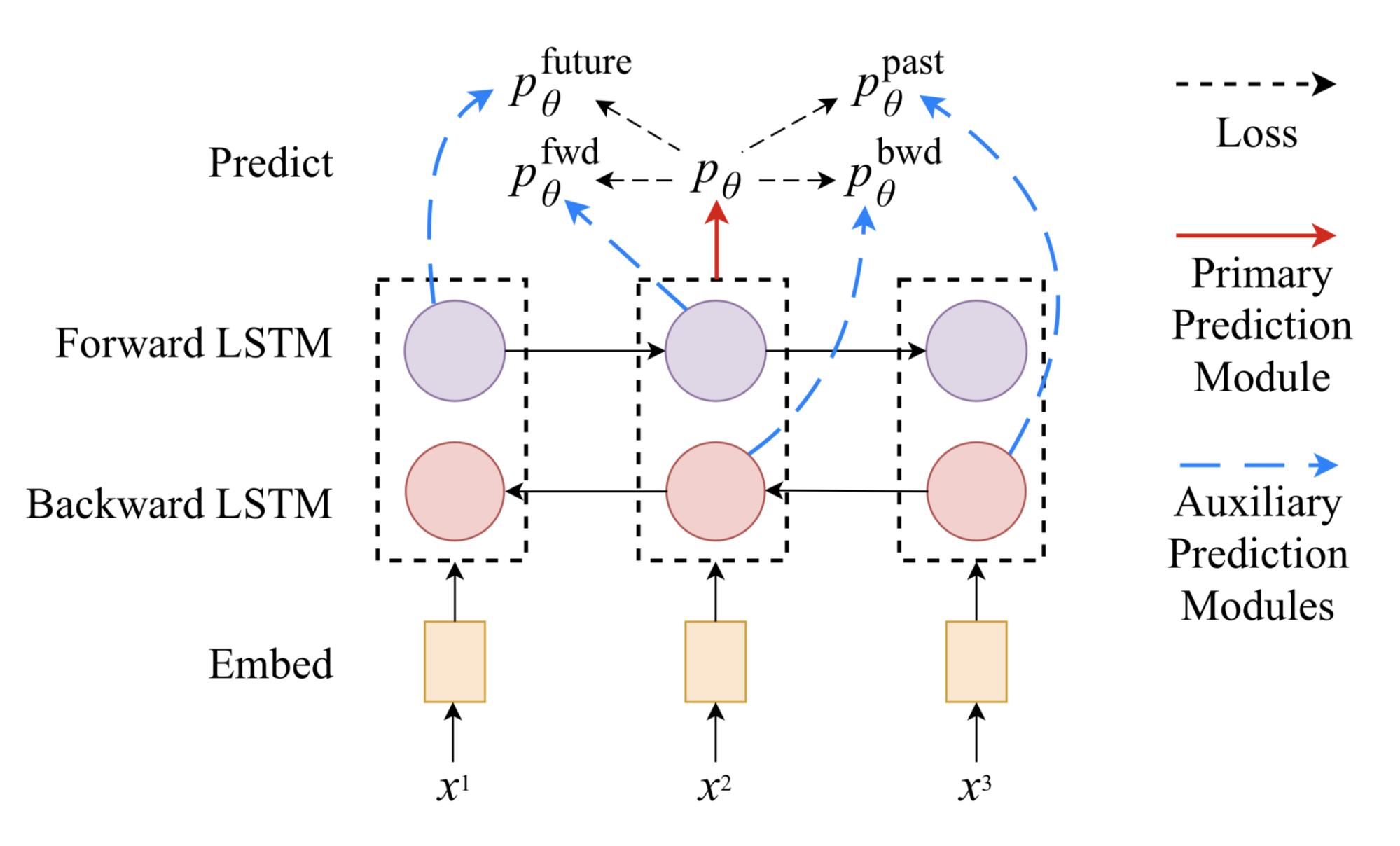
Инжир. 5. Задача последовательного пометки зависит от четырех вспомогательных моделей прогнозирования, их входы включают только скрытые состояния в одном направлении: вперед, назад, будущее и прошлое. (Источник изображения: оригинальная бумага)
Обратите внимание, что если основной модуль прогнозирования имеет отсев, отсевающий слой работает как обычно при обучении с помеченными данными, но он не применяется при создании “мягкой” цели для вспомогательных задач во время обучения с немеченными данными.
В задаче машинного перевода основной модуль прогнозирования заменяется стандартным однонаправленным декодером LSTM с особым вниманием. Существуют две вспомогательные задачи: (1) применить отсев к вектору веса внимания путем случайного обнуления некоторых значений; (2) предсказать будущее слово в целевой последовательности. Основное предсказание для вспомогательных задач, которые должны соответствовать, является лучшей предсказанной целевой последовательностью, произведенной, запустив фиксированный основной декодер на входной последовательности с поиском луча .
ULMFiT
Идея использования generative pretrained LM + Task-specific fine-tuning была впервые исследована в ULMFiT (Howard & Ruder, 2018 ), непосредственно мотивированная успехом использования предварительной подготовки ImageNet для задач компьютерного зрения. Базовая модель AWD-LSTM .
ULMFiT следует три шага для достижения хороших результатов передачи обучения на нижестоящих задачах классификации языков:
1) общая подготовка к фильму : по тексту Википедии.
2) целевая задача тонкой настройки LM : ULMFiT предложил две методики обучения для стабилизации процесса тонкой настройки. Увидеть ниже.
Дискриминационная тонкая настройка мотивируется тем фактом, что различные слои пленки захватывают различные типы информации (см. обсуждение выше). ULMFiT предложил настраивать каждый слой с разной скоростью обучения, { ? 1,..., ? ?,..., ? L}
всего слоев.
Наклонные треугольные скорости обучения (STLR) относятся к специальному планированию скорости обучения, которое сначала линейно увеличивает скорость обучения, а затем линейно распадается. Стадия увеличения коротка так, чтобы модель могла сходиться к пространству параметров, подходящему для задачи быстро, в то время как период распада длинен, учитывая лучшую настройку.
3) тонкая настройка классификатора целевых задач : предварительно обученная пленка дополняется двумя стандартными слоями прямой передачи и нормализацией softmax в конце для прогнозирования распределения целевых меток.
Объединение пулов извлекает max-polling и mean-pooling по истории скрытых состояний и объединяет их с конечным скрытым состоянием.
Постепенное размораживание помогает избежать катастрофического забывания, постепенно размораживая слои модели, начиная с последнего. Сначала последний слой размораживается и настраивается на одну эпоху. Затем следующий нижний слой размораживается. Этот процесс повторяется до тех пор, пока все слои не будут настроены.
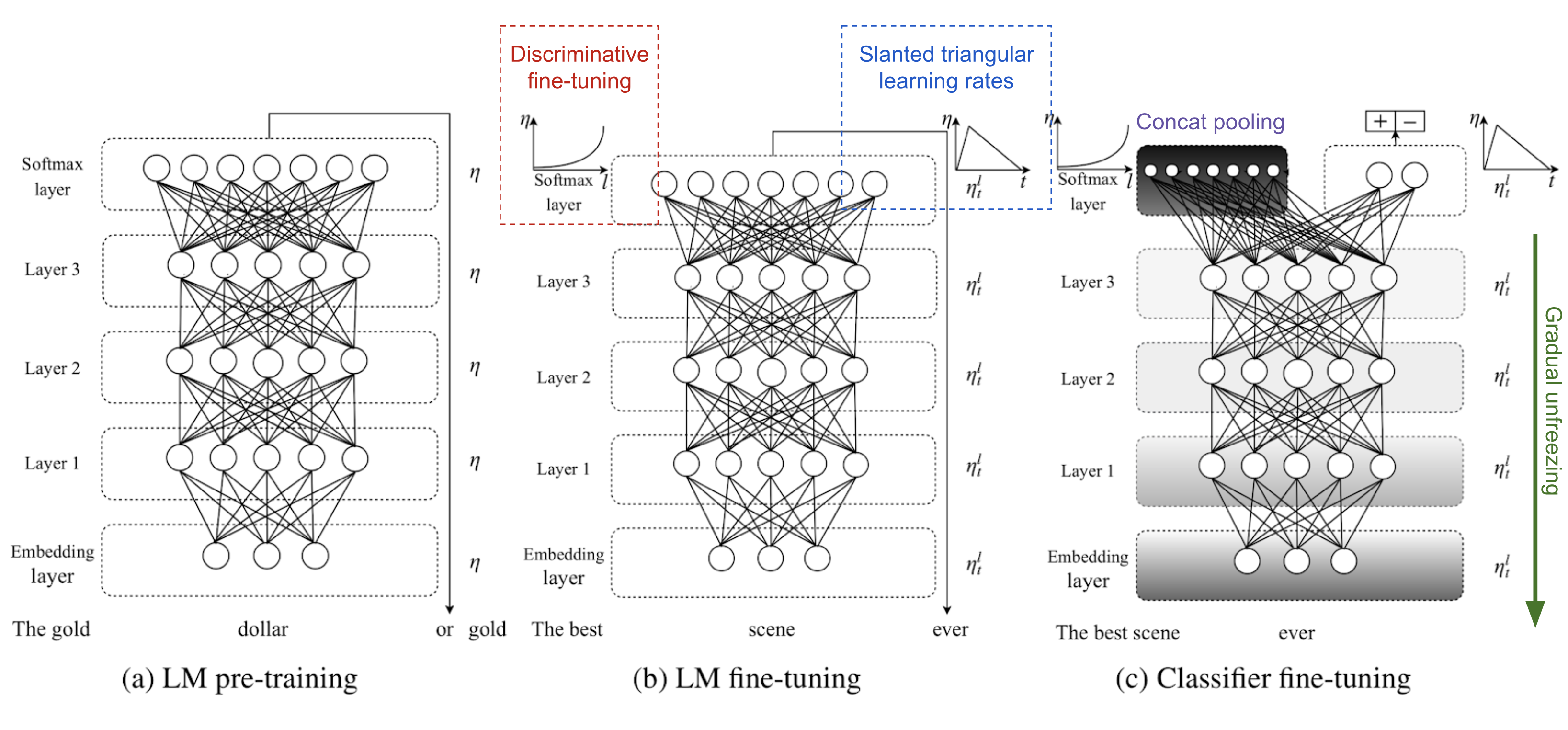
Инжир. 6. Три этапа обучения ULMFiT. (Источник изображения: оригинальная бумага)
OpenAI GPT
Следуя аналогичной идее ELMo, OpenAI GPT, сокращенно от Generative Pre-training Transformer (Radford et al., 2018), расширяет неконтролируемую языковую модель в гораздо большем масштабе путем обучения на гигантской коллекции корпусов свободного текста. Несмотря на сходство, GPT имеет два основных отличия от ELMo.
- Архитектуры модели различны: ELMo использует мелкую конкатенацию независимо обученных left-to-right и right-to-left многослойных LSTMs, в то время как GPT является многослойным трансформаторным декодером.
- Использование контекстуализированных вложений в последующих задачах отличается: Elmo передает вложения в модели, настроенные для конкретных задач в качестве дополнительных функций, в то время как GPT настраивает одну и ту же базовую модель для всех конечных задач.
Трансформаторный декодер как языковая модель
По сравнению с оригинальной архитектурой трансформатора модель декодера трансформатора отбрасывает часть кодера, поэтому существует только одно входное предложение, а не две отдельные исходные и целевые последовательности.
Эта модель применяет несколько блоков трансформатора к вложениям входных последовательностей. Каждый блок содержит маскированный многоголовый слой самооценки и поточечный слой прямой связи. Окончательный вывод производит распределение по целевым токенам после нормализации softmax.
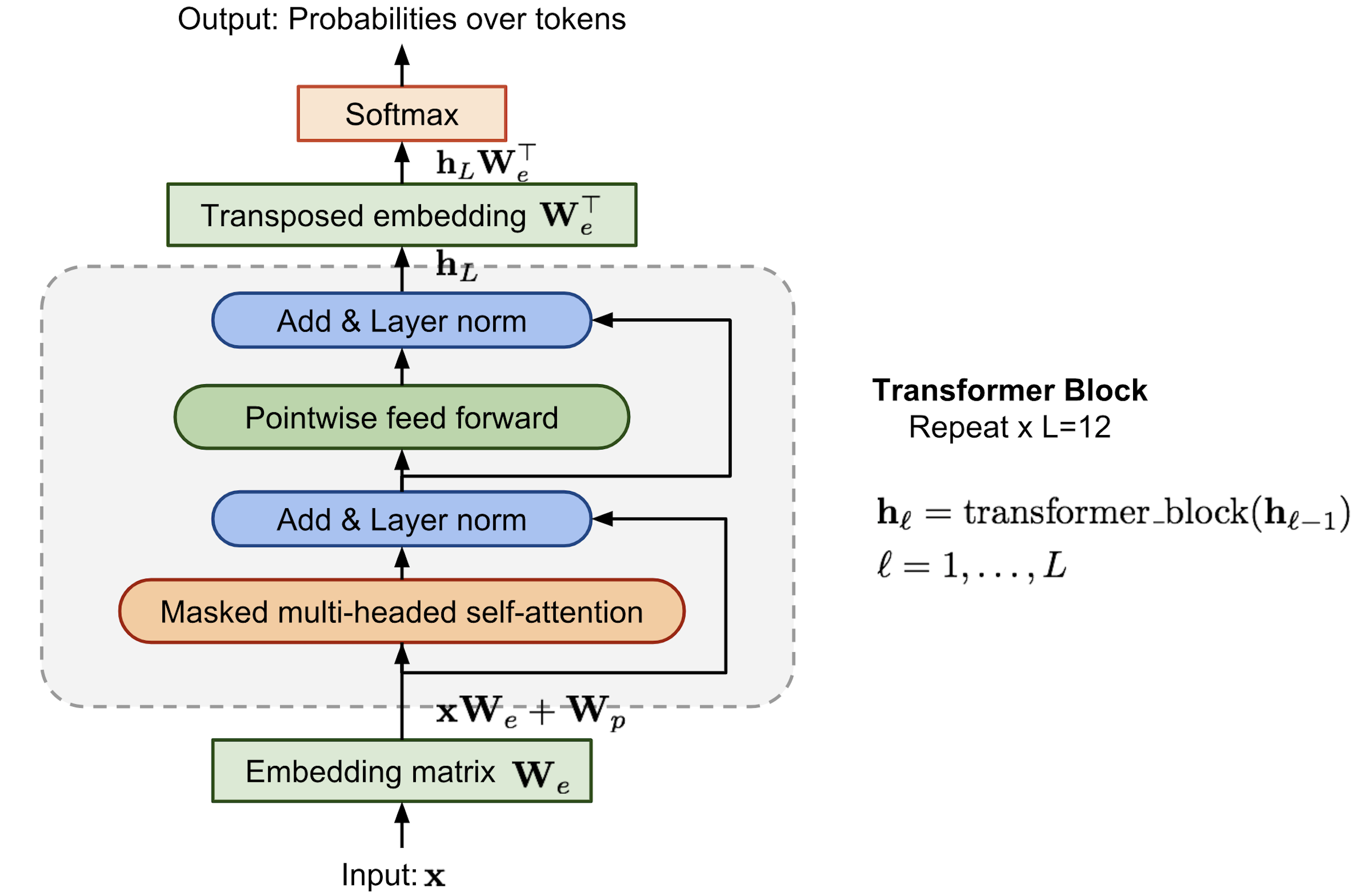
Инжир. 7. Архитектура модели декодера трансформатора в OpenAI GPT.
Потеря-это отрицательная логарифмическая вероятность, такая же , как ELMo, но без обратных вычислений. Допустим, контекстное окно размером тысяча
находится перед целевым словом и потеря будет выглядеть так:
L LM = - ? I log p (x i ? x i-k,..., x i-1)
BPE
Кодирование пар байтов (BPE) используется для кодирования входных последовательностей. BPE был первоначально предложен в качестве алгоритма сжатия данных в 1990-х годах, а затем был принят для решения проблемы открытого словаря в машинном переводе, поскольку мы можем легко столкнуться с редкими и неизвестными словами при переводе на новый язык. Руководствуясь интуицией, что редкие и неизвестные слова часто могут быть разложены на несколько подсловов, BPE находит лучшую сегментацию слов путем итеративного и жадного слияния частых пар символов.
Контролируемая Тонкая Настройка
Самое существенное обновление, предложенное OpenAI GPT, заключается в том, чтобы избавиться от модели конкретной задачи и напрямую использовать предварительно подготовленную языковую модель!
Возьмем классификацию в качестве примера. Скажем, в помеченном наборе данных каждый вход имеет северный
жетоны, x = (x 1,..., x n), и один ярлык год. GPT сначала обрабатывает входную последовательность икс через предварительно обученный трансформаторный декодер и вывод последнего слоя для последнего токена xn есть h (n ) L. Тогда только с одной новой обучаемой матрицей веса Wy, он может предсказать распределение по меткам классов.

P ( y ? x 1 , ... , x n ) = softmax ( h (n ) L W y)
Потеря состоит в том, чтобы минимизировать отрицательную вероятность журнала для истинных меток. Кроме того, добавление потери пленки в качестве дополнительной потери оказывается полезным, поскольку:
- (1) это помогает ускорить конвергенцию во время обучения и
- (2) предполагается улучшить обобщение контролируемой модели.
ЛЦБСлЛМЛ=?(Х,У)?D ижурналп(г?х1,...,хП)=?(Х,У)?Джурналsoftmax(ч(н)л(х)ЖГ)=??яжурналп(хя?хя?к,...,Хя?1)=лЦБС+?лЛМ
При схожих конструкциях для других конечных задач не требуется настраиваемая структура модели (см. рис. 7). Если ввод задачи содержит несколько предложений,
$между каждой парой предложений добавляется специальный разделитель token (). Вложение для этого маркера разделителя-это новый параметр, который нам нужно изучить, но он должен быть довольно минимальным.Для задачи подобия предложения, поскольку порядок не имеет значения, включены оба порядка. Для задачи множественного выбора контекст соединяется с каждым кандидатом ответа.
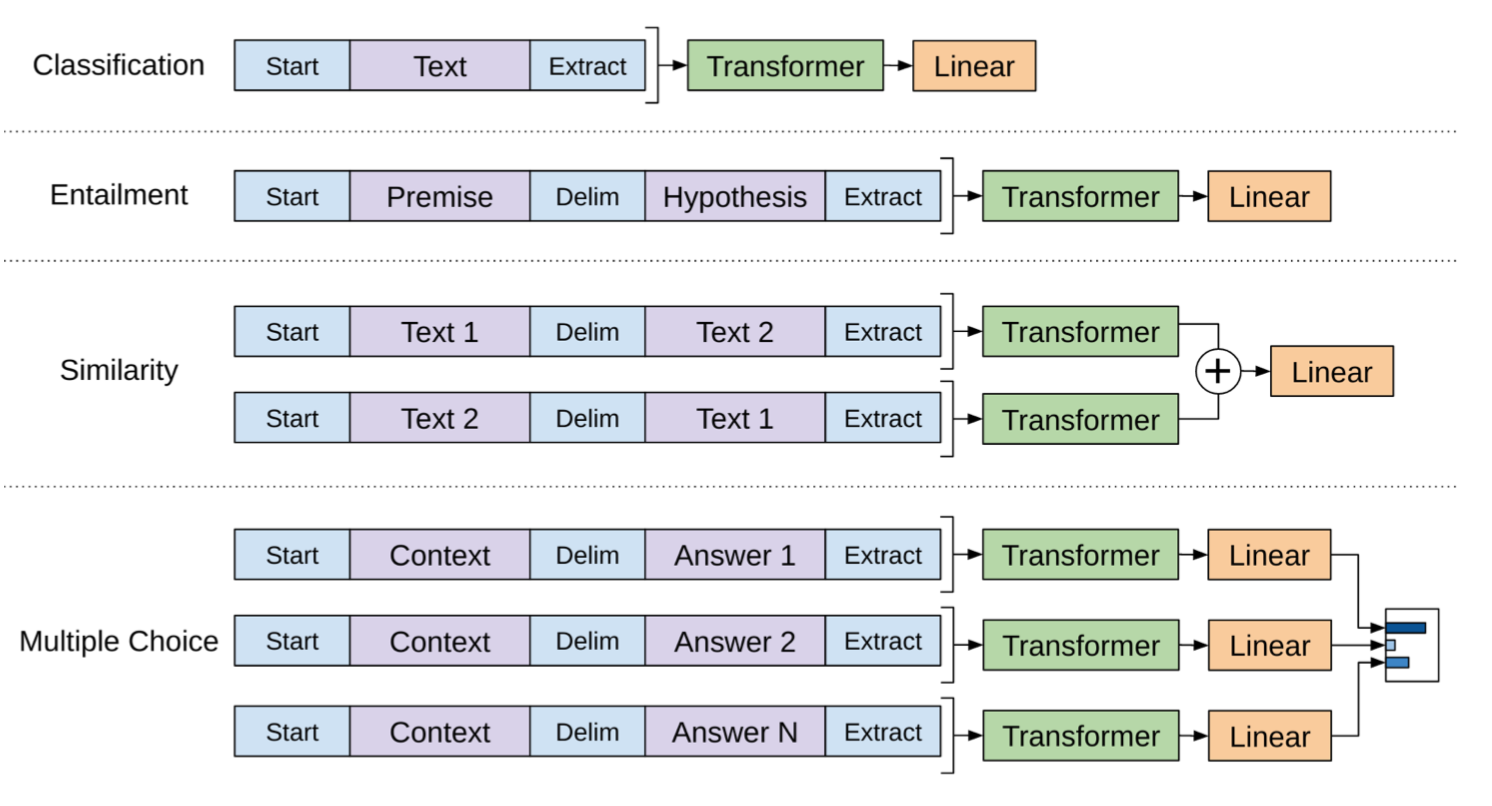
Инжир. 8. Объекты тренировки в немножко доработанных моделях трансформатора GPT для идущих дальше по потоку задач. (Источник изображения: оригинальная бумага)
Резюме: очень аккуратно и обнадеживающе видеть, что такая общая структура способна победить SOTA в большинстве языковых задач в то время (июнь 2018). На первом этапе генеративная подготовка языковой модели позволяет усвоить как можно больше свободного текста. Затем на втором этапе модель настраивается на конкретные задачи с небольшим помеченным набором данных и минимальным набором новых параметров для изучения.
Одним из ограничений GPT является его однонаправленный характер — модель только обучена предсказывать будущий контекст слева направо.
БЕРТ
BERT, сокращение от Bidirectional Encoder Representations from Transformers (Devlin, et al., 2019) является прямым потомком GPT : обучите большую языковую модель свободному тексту, а затем точно настроитесь на конкретные задачи без настраиваемых сетевых архитектур.
По сравнению с GPT, наибольшая разница и улучшение BERT заключается в том, чтобы сделать обучение двунаправленным . Модель учится предсказывать как контекст слева, так и справа. В статье, согласно исследованию абляции, утверждалось, что:
"двунаправленный характер нашей модели является самым важным новым вкладом”
Задачи предварительной подготовки
Модельная архитектура BERT разнослоистый двухнаправленный шифратор трансформатора.
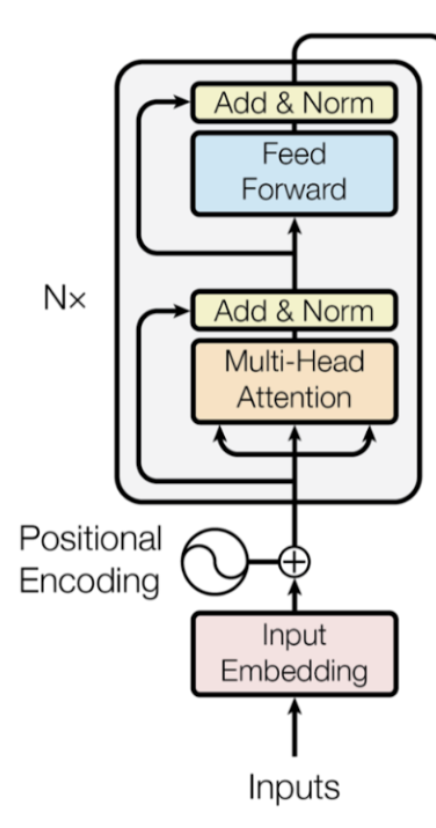
Инжир. 9. Резюме архитектуры модели трансформаторного энкодера. (Источник изображения: трансформаторная бумага)
Чтобы стимулировать двунаправленное предсказание и понимание на уровне предложения, Берт обучается двум вспомогательным задачам вместо основной языковой задачи (то есть предсказывать следующий токен данного контекста).
Задача 1: Модель языка маски (МЛМ)
Из Википедии: "тест cloze (также Тест удаления cloze) - это упражнение, тест или оценка, состоящая из части языка с определенными элементами, словами или знаками (текст cloze), где участнику предлагается заменить отсутствующий элемент языка. ... Это упражнение было впервые описано У. Л. Тейлором в 1953 году.”
Неудивительно полагать, что представление, которое изучает контекст вокруг слова, а не только после того, как слово способно лучше уловить его значение, как синтаксически, так и семантически. Берт призывает модель сделать это путем обучения задаче " модель языка масок:
- Случайным образом маскируйте 15% токенов в каждой последовательности. Потому что если мы заменим маскированные токены только специальным заполнителем
[MASK], то специальный токен никогда не будет обнаружен во время тонкой настройки. Следовательно, Берт использовал несколько эвристических трюков:- а) с вероятностью 80% заменить выбранные слова
[MASK]; - (b) с вероятностью 10% заменить случайным словом;
- (c) с вероятностью 10%, держите его таким же.
- а) с вероятностью 80% заменить выбранные слова
- Модель только предсказывает недостающие слова, но не имеет информации о том, какие слова были заменены или какие слова должны быть предсказаны. Выходной размер составляет всего 15% от входного размера.
Задача 2: предсказание следующего предложения
Мотивированный тем фактом, что многие последующие задачи связаны с пониманием отношений между предложениями (т. е. QA, NLI), Берт добавил еще одну вспомогательную задачу по обучению двоичного классификатора для определения того, является ли одно предложение следующим предложением другого:
- Пример пары предложений (A, B), так что:
- a) в 50% случаев B следует за A;
- (b) 50% времени, B не следует A.
- Модель обрабатывает оба предложения и выводит двоичную метку, указывающую, является ли B следующим предложением A.
Обучающие данные для обеих вышеуказанных вспомогательных задач могут быть тривиально получены из любого одноязычного корпуса. Поэтому масштабы обучения безграничны. Потеря обучения-это сумма средней маскированной вероятности LM и вероятности предсказания следующего предложения.
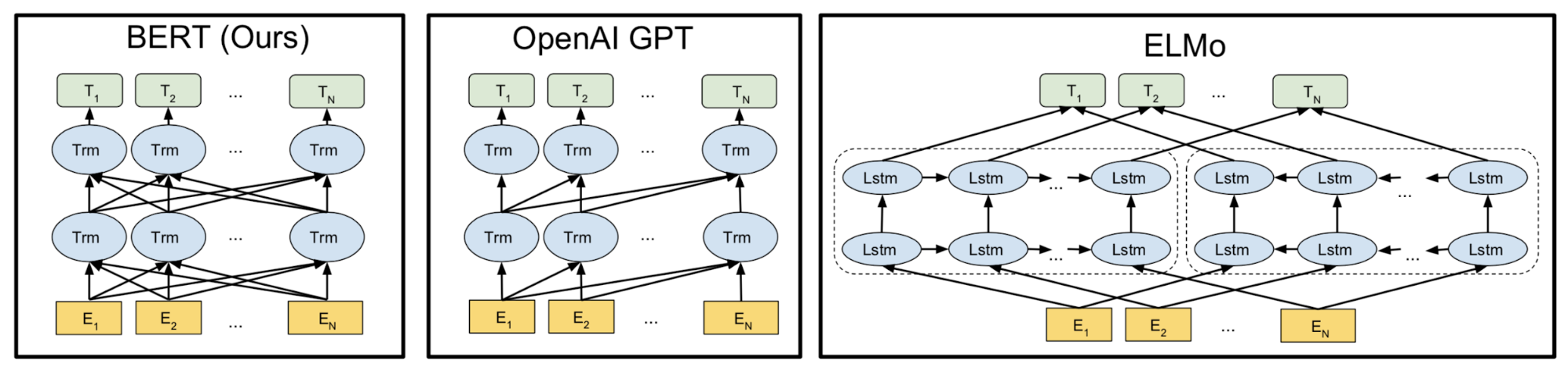
Инжир. 10. Сравнение архитектур моделей BERT, OpenAI GPT и ELMo. (Источник изображения: оригинальная бумага)
Врезать Входного Сигнала
Входное вложение-это сумма трех частей:
- Встраивания токенизации WordPiece: модель WordPiece была первоначально предложена для японской или корейской проблемы сегментации. Вместо использования естественно разделенного английского слова, они могут быть далее разделены на меньшие единицы подслова так, чтобы было более эффективно обращаться с редкими или неизвестными словами. Пожалуйста, прочитайте связанные документы для оптимального способа разделения слов, если это интересно.
- Сегментные вложения: если входные данные содержат два предложения, они имеют предложения A и предложения B вложения соответственно, и они разделены специальным символом
[SEP]; только предложение a вложения используются, если входные данные содержат только одно предложение. - Позиционные вложения: позиционные вложения изучаются, а не жестко закодированы.
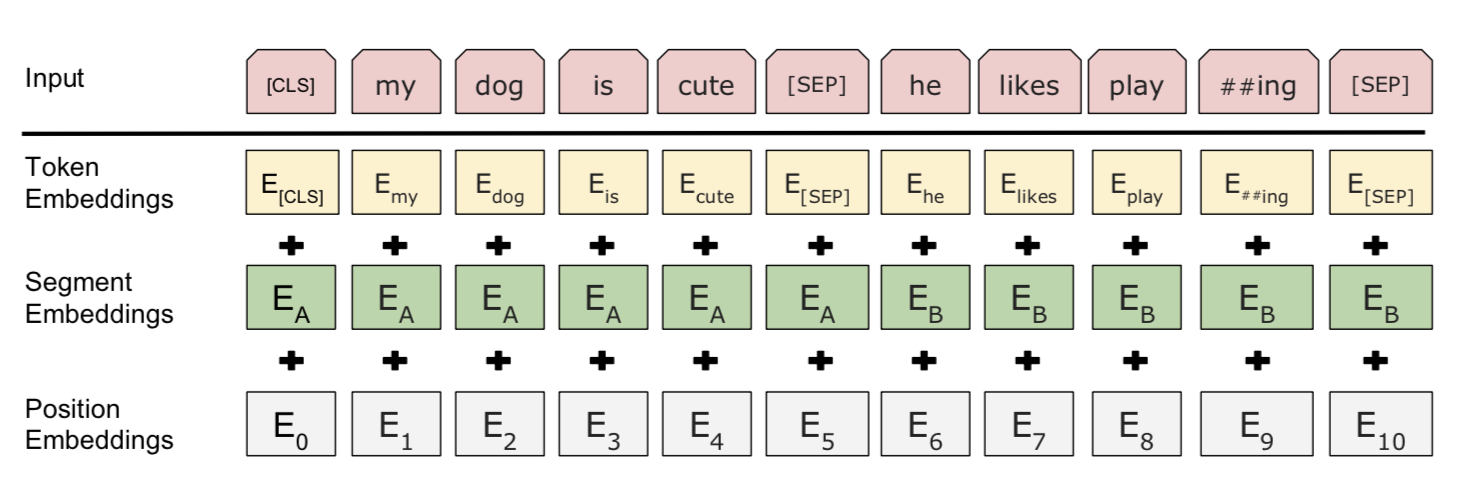
Инжир. 11. Входное представление Берта. (Источник изображения: оригинальная бумага)
Обратите внимание, что первый маркер всегда принудительно
[CLS]— заполнитель, который будет использоваться позже для прогнозирования в последующих задачах.Использование BERT в последующих задачах
Для тонкой настройки BERT требуется всего несколько новых параметров, как и для OpenAI GPT.
Для задач классификации мы получаем прогноз, принимая окончательное скрытое состояние специального первого токена
, и умножая его на матрицу малого веса, softmax (h [CLS] L W cls)[CLS], h[CLS]L.
Для задач QA, таких как SQuAD, нам нужно предсказать диапазон текста в данном абзаце для данного вопроса. Берт предсказывает два распределения вероятности каждого токена, начиная и заканчивая текстовым интервалом. Только две новые маленькие матрицы, Ws
и We, недавно изучены во время тонкой настройки и softmax (h (i) L W s) и softmax (h (i) L W e)определите два распределения вероятности.
В целом, дополнительная часть для тонкой настройки конечной задачи очень минимальна-одна или две матрицы веса для преобразования скрытых состояний преобразования в интерпретируемый формат. Проверьте документ на предмет деталей реализации для других случаев.
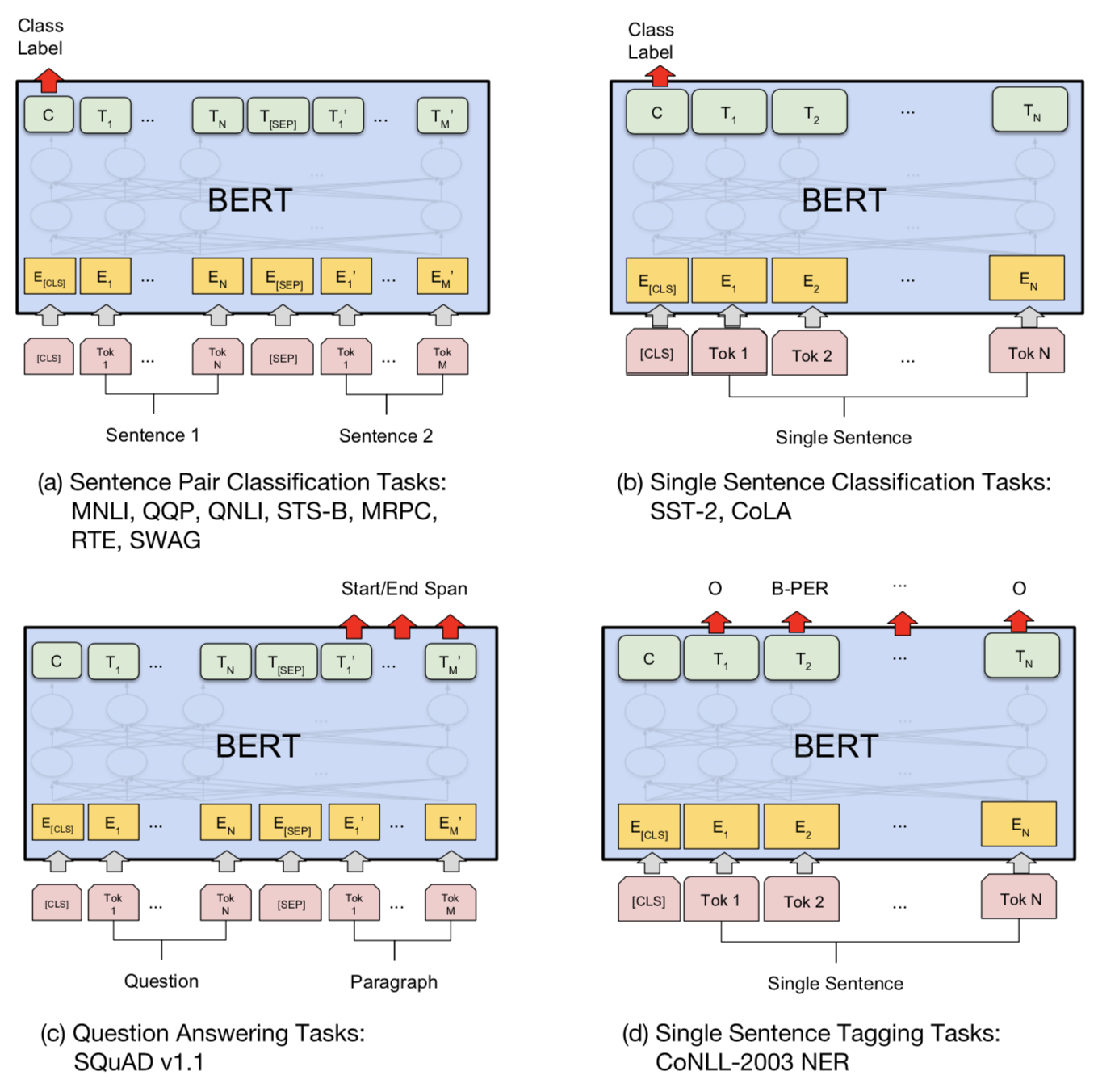
Инжир. 12. Объекты обучения в слегка измененных моделях Берта для последующих задач. (Источник изображения: оригинальная бумага)
Сводная таблица сравнивает различия между тонкой настройкой OpenAI GPT и BERT.
OpenAI GPT БЕРТ Специальный символ [SEP]и[CLS]вводятся только на этапе тонкой настройки.[SEP]и[CLS]и предложения a/b вложения изучаются на этапе предварительной подготовки.Учебный процесс 1M шаги, размер партии 32k слов. Шаги 1M, размер партии 128k слов. Тонкая настройка lr = 5e-5 для всех задач тонкой настройки. Используйте LR для точной настройки. OpenAI GPT-2
Языковая модель OpenAI GPT-2 является прямым преемником GPT . GPT-2 имеет параметры 1.5 B, 10x больше чем первоначально GPT, и оно достигает результатов SOTA на 7 из 8 испытанных наборов данных моделирования языка в установке перехода нул-съемки без любой задач-специфической подстройки. Набор данных предварительной подготовки содержит 8 миллионов веб-страниц, собранных путем обхода квалифицированных исходящих ссылок из Reddit . Большие улучшения OpenAI GPT-2 особенно заметны на небольших наборах данных и наборах данных, используемых для измерения долгосрочной зависимости .
Передача Нулевого Выстрела
Задача подготовки к GPT-2-исключительно языковое моделирование. Все нижестоящие языковые задачи сформулированы как предсказывающие условные вероятности, и нет никакой специфичной для задачи тонкой настройки.
- Генерация текста проста с помощью LM.
- Задача машинного перевода, например, с английского на китайский, индуцируется путем кондиционирования LM на парах “английское предложение = китайское предложение” и “целевое английское предложение =” в конце.
- Например, условная вероятность предсказания может выглядеть следующим образом:
P(? | I like green apples. = ??????? A cat meows at him. = ???????It is raining cats and dogs. =")
- Например, условная вероятность предсказания может выглядеть следующим образом:
- Задача QA форматируется аналогично переводу с парами вопросов и ответов в контексте.
- Задача суммирования индуцируется добавлением
TL;DR:после статей в контекст.
BPE в байтовых последовательностях
То же, что и исходный GPT, GPT-2 использует BPE, но на последовательностях байтов UTF-8. Каждый байт может представлять 256 различных значений в 8 битах, пока UTF-8 может использовать до 4 байта для одного характера, поддерживая до 231
всего персонажей. Поэтому для представления последовательности байтов нам нужен только словарь размером 256 и не нужно беспокоиться о предварительной обработке, токенизации и т. д. Несмотря на преимущество, текущие LM байтового уровня по-прежнему имеют незначительный разрыв производительности с LM уровня слова SOTA.
BPE объединяет часто встречающиеся пары байтов жадным образом. Чтобы предотвратить создание нескольких версий общих слов (т. е.
dog.dog!иdog?для словаdog), GPT-2 предотвращает слияние символов BPE по категориям (таким образомdog, не будет объединяться с пунктуациями , такими как.!and?). Эти приемы помогают повысить качество конечной сегментации байтов.Используя представление последовательности байтов, GPT-2 может назначить вероятность любой строке Unicode, независимо от каких-либо шагов предварительной обработки.
Модификации Модели
Сравненный к GPT, за исключением иметь еще многие слои и параметры трансформатора, GPT-2 включает только немного изменений зодчества:
- Нормализация слоя была перемещена на вход каждого подблока, аналогично остаточной единице типа "строительный блок “(в отличие от исходного типа” узкое место", он имеет нормализацию партии, применяемую перед весовыми слоями).
- Дополнительная нормализация слоя была добавлена после заключительного блока самооценки.
- Модифицированная инициализация была построена как функция глубины модели.
- Веса остаточных слоев первоначально масштабировались с коэффициентом 1/N???
- где N-количество остаточных слоев.
- Используйте больший размер словаря и размер контекста.
Краткие сведения
Базовая модель предварительная подготовка Последующие задачи Нисходящая модель Тонкая настройка бухточка модель seq2seq NMT контролируемый основанный на характеристик конкретная задача / ELMo двухслойный билстм неконтролируемый основанный на характеристик конкретная задача / ВАРИАТОР двухслойный билстм полу-контролируемый основанный на модели специфичная задача / задача-агностик / ULMFiT AWD-LSTM неконтролируемый основанный на модели задача-агностик все слои; с различными трюками обучения GPT Трансформаторный дешифратор неконтролируемый основанный на модели задача-агностик предварительно подготовленные слои + верхний слой(слои) задач) БЕРТ Трансформаторный шифратор неконтролируемый основанный на модели задача-агностик предварительно подготовленные слои + верхний слой(слои) задач) GPT-2 Трансформаторный дешифратор неконтролируемый основанный на модели задача-агностик предварительно подготовленные слои + верхний слой(слои) задач) Метрика: Недоумение
Perplexity is often used as an intrinsic evaluation metric for gauging how well a language model can capture the real word distribution conditioned on the context.
Недоумение дискретного распределения вероятностей p
определяется как возведение в степень энтропии:
2 H (p ) = 2 - ? x p (x ) log 2 p (x)
Учитывая предложение Северный
слова, s = (w 1,..., w N) энтропия выглядит следующим образом, просто предполагая, что каждое слово имеет одинаковую частоту, 1N:
H (s) = - ? i = 1 N P (w i ) log 2 p (w i) = - ? i = 1 N 1 N log 2 p (w i)
Недоумение для предложения становится:
2 H (s ) = 2-1 n ? n i = 1 log 2 p (w i) = (2 ? N i = 1 log 2 p (w i)) - 1 N = (p (w 1 ) ... p (w N)) - 1 N
Хорошая языковая модель должна предсказывать высокие вероятности слов. Поэтому чем меньше недоумение, тем лучше.
Общие задачи и наборы данных
Вопрос-Ответ
- SQuAD (Stanford Question Answering Dataset): набор данных для понимания чтения, состоящий из вопросов, заданных в наборе статей Википедии, где ответ на каждый вопрос-это текст.
- Гонка (понимание прочитанного от экзаменов): крупномасштабный набор данных понимания прочитанного с более чем 28 000 проходов и почти 100 000 вопросов. Набор данных собран из экзаменов по английскому языку в Китае, которые предназначены для учащихся средних и старших классов.
Рассуждения Здравого Смысла
- Story Cloze Test: здравый смысл рассуждения рамки для оценки понимания истории и поколения. Тест требует, чтобы система выбрала правильное окончание истории с несколькими предложениями из двух вариантов.
- SWAG (ситуации с состязательными поколениями): множественный выбор; содержит 113k примеров завершения пары предложений, которые оценивают обоснованный вывод здравого смысла
Вывод естественного языка ( NLI): также известный как перенос текста , упражнение, чтобы различить в логике, может ли одно предложение быть выведено из другого.
- RTE (распознавание текстового вовлечения): набор данных, инициированный вызовом текстового вовлечения.
- SNLI (Stanford Natural Language Inference): коллекция из 570k человеко-письменных английских пар предложений, вручную помеченных для сбалансированной классификации с метками
entailmentcontradiction, иneutral. - MNLI (Multi-Genre NLI): похоже на SNLI, но с более разнообразным разнообразием стилей текста и тем, собранных из транскрибированной речи, популярной художественной литературы и правительственных отчетов.
- QNLI (вопрос NLI): преобразуется из набора данных SQuAD в двоичную задачу классификации по парам (вопрос, предложение).
- SciTail: набор данных entailment, созданный из нескольких вариантов научных экзаменов и веб-предложений.
Named Entity Recognition ( NER): маркирует последовательности слов в тексте, которые являются названиями вещей, такими как имена людей и компаний или имена генов и белков
- Задача Ner CoNLL 2003: состоит из новостей от Reuters, концентрирующихся на четырех типах названных сущностей: лица, местоположения, организации и имена разных сущностей.
- Онтоноты 0.5: этот корпус содержит текст на английском, арабском и китайском языках, помеченный четырьмя различными типами сущностей (PER, LOC, ORG, MISC).
- Reuters Corpus:большая коллекция новостей Reuters.
- Мелкозернистый NER (FGN)
Анализ Настроений
- SST (Stanford Sentiment Treebank)
- IMDb: большой набор данных обзоров фильмов с метками классификации бинарных настроений.
Семантическая ролевая маркировка (SRL) : моделирует структуру предиката-аргумента предложения и часто описывается как ответ “кто сделал то, что кому”.
Сходство предложения: также известный как обнаружение перефразирования
- MRPC (MicRosoft Paraphrase Corpus): содержит пары предложений, извлеченных из источников новостей в интернете, с аннотациями, указывающими, является ли каждая пара семантически эквивалентной.
- QQP (пары вопросов Quora) STS Benchmark: семантическое текстовое сходство
Приемлемость предложения: задача аннотирования предложений для грамматической приемлемости.
- Кола (корпус лингвистической приемлемости): бинарная задача классификации с одним предложением.
Фрагментация текста: разделение текста на синтаксически коррелированные части слов.
Маркировка части речи (POS): маркировка частей речи для каждого токена, таких как существительное, глагол, прилагательное и т. д. The Wall Street Journal часть Pennal Treebank (Маркус и др., 1993).
Машинный перевод: см. стандартную страницу НЛП.
- WMT 2015 английский-чешские данные (Большой)
- WMT 2014 англо-немецкие данные (средний)
- IWSLT 2015 английский-вьетнамский data (Small)
Разрешение Coreference: кластер упоминает в тексте, которые относятся к тем же базовым сущностям реального мира.
Зависимость на большие расстояния
- LAMBADA (языковое моделирование, расширенное для учета аспектов дискурса): коллекция повествовательных отрывков, извлеченных из книжного корпуса, и задача состоит в том, чтобы предсказать последнее слово, для которого требуется не менее 50 токенов контекста для человека, чтобы успешно предсказать.
- Детская книга тест : построен из книг, которые находятся в свободном доступе в проекте Гутенберг . Задача-предсказать пропущенное слово среди 10 кандидатов.
Многозадачный бенчмарк
- Клей многозадачный бенчмарк: https://gluebenchmark.com
- decaNLP benmark: https://decanlp.com
Неконтролируемый набор данных предварительного обучения
- Книги корпус: корпус содержит " более 7000 уникальных неопубликованных книг из различных жанров, включая приключения, фэнтези и романтики.”
- 1b тест модели языка Word
- Английская Википедия: ~2500M words
Источник: lilianweng.github.io