Google Research Football: новая среда для обучения RL-агентов
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-06-10 17:51

Google AI опубликовали новую задачу для тренировки алгоритмов обучения с подкреплением (RL). Агенты будут учиться играть в футбол.
Обучения с подкреплением фокусируется на задаче обучить агентов взаимодействовать со средой, в которую они помещены, и решать комплексные задачи. Уже сейчас методы обучения с подкреплением используются в робототехнике, беспилотных автомобилях и киберспорте. Игра в футбол требует агентов держать краткосрочный контроль, выучивать концепты из игры (напр., передача мяча) и уметь формировать стратегии игры.
Football Environment была смоделирована на примере футбольных видеоигр. Среда представляет собой 3D симуляцию, где агенты контролируют игру одного игрока или всю команду. Цель агента — выиграть у команды противников.
Бета-версия находится в открытом доступе.
Видеодемонстрация среды:
Игровая симуляция
Главная часть Football Environment — это продвинутая симуляция игры в футбол (Football Engine). Симуляция базируется на значительно модифицированной версии Gameplay Football. В зависимости от входных действий двух противоборствующих команд, симулируются все аспекты футбольного матча: голы, нарушения правил, угловые и пенальти удары и офсайды.
Football Engine реализован на C++. Это позволяет пользоваться симулятором на готовых машинах с GPU и без. Благодаря своей реализации, можно совершать около 25 миллионов шагов за день на шестиядерной машине.
Дополнительный функционал симуляции:
- Возможность как учить репрезентации состояний, который содержат информацию о локации игрока, так и учить агентов на сырых данных пикселей;
- Чтобы оценить эффект случайности, можно прогонять симуляцию в стохастическом (есть доля случайности в решениях агентов и в среде) или детерминистическом (нет случайности) режимах;
- Совместим с API OpenAI Gym;
- Возможность для исследователей играть за своего агента с помощью клавиатуры или геймпада
Список задач
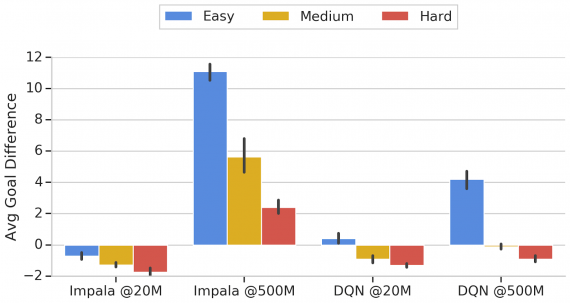
Исследователи предлагают набор проблем в обучении с подкреплением (Football Benchmarks), которые можно решить с помощью Football Engine. Цель этих задач в том, чтобы обыграть основанного на правилах игрока. Правила для агента прописывались вручную.
В Football Benchmarks есть три типа задач:
- Easy Benchmark;
- Medium Benchmark;
- Hard Benchmark
Задачи различаются силой основанного на правилах оппонента. Исследователи протестировали задачи на двух state-of-the-art подходах в обучении с подкреплением: DQN и IMPALA.
Источник: neurohive.io