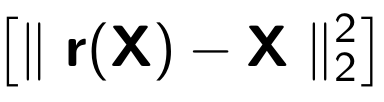Мы уже писали в самой первой статье нашего корпоративного блога о том, как работает алгоритм обнаружения переводных заимствований. Лишь пара абзацев в той статье посвящена теме сравнения текстов, хотя идея достойна гораздо более развернутого описания. Однако, как известно, обо всем сразу рассказать нельзя, хоть и очень хочется. В попытках воздать должное этой теме и архитектуре сети под названием «автокодировщик», к которой мы питаем очень теплые чувства, мы с Oleg_Bakhteev и написали этот обзор. Источник: Deep Learning for NLP (without Magic) Как мы упоминали в той статье, сравнение текстов у нас было “смысловое” – мы сопоставляли не сами текстовые фрагменты, а векторы, им соответствующие. Такие векторы получались в результате обучения нейронной сети, которая отображала текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. Как получить такое отображение и как научить сеть выдавать нужные результаты – отдельный вопрос, о которой и пойдет речь ниже.
Что такое автокодировщик?
Формально, автокодировщиком (или автоэнкодером) называется нейронная сеть, которая тренируется восстанавливать объекты, принимаемые на вход сети.
Автокодировщик состоит из двух частей: энкодера f, который кодирует выборку X в свое внутреннее представление H, и декодера g, который восстанавливает исходную выборку. Таким образом, автокодировщик пытается совместить восстановленную версию каждого объекта выборки с исходным объектом.
При обучении автокодировщика минимизируется следующая функция: Где за r обозначается восстановленная версия исходного объекта: Рассмотрим пример, представленный в blog.keras.io: На вход сеть принимает объект x (в нашем случае — цифра 2).
Наша сеть кодирует этот объект в скрытое состояние. Затем по скрытому состоянию восстанавливается реконструкция объекта r, которая должна быть похожа на x. Как мы видим, восстановленное изображение (справа) стало более размытым. Объясняется это тем, что мы стараемся сохранить в скрытом представлении только наиболее важные признаки объекта, поэтому объект восстанавливается с потерями.
Модель автокодировщика обучается по принципу испорченного телефона, где один человек (encoder) передает второму человеку (decoder) информацию (x), а тот в свою очередь, рассказывает его третьему (r(x)).
Одно из основных предназначений таких автокодировщиков — снижение размерности исходного пространства. Когда мы имеем дело с автокодировщиками, то сама процедура тренировки нейросети заставляет автокодировщик запоминать основные признаки объектов, по которым будет проще восстановить исходные объекты выборки.
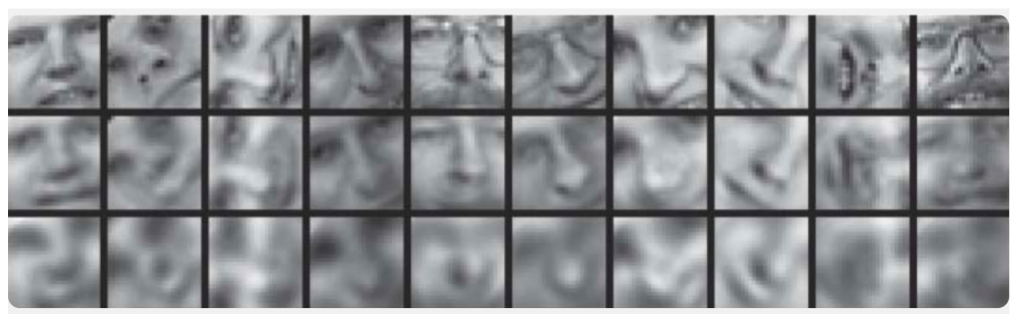
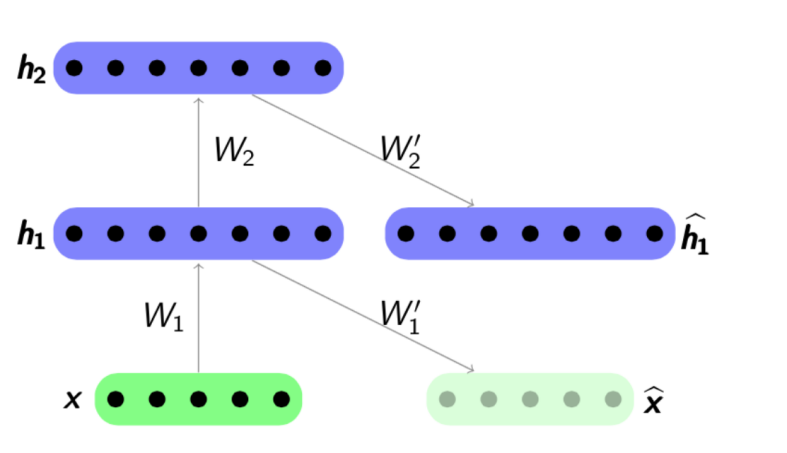
Здесь можно провести аналогию с методом главных компонент: это метод снижения размерности, результатом работы которого является проекция выборки на подпространство, в котором дисперсия этой выборки максимальна. Действительно, автокодировщик является обобщением метода главных компонент: в случае, когда мы ограничиваемся рассмотрением линейных моделей, автокодировщик и метод главных компонент дают одинаковые векторные представления. Разница возникает, когда мы рассматриваем в качестве энкодера и декодера более сложные модели, например, многослойные полносвязные нейронные сети. Пример сравнения метода главных компонент и автокодировщика представлен в статье Reducing the Dimensionality of Data with Neural Networks: Здесь продемонстрированы результаты обучения автокодировщика и метода главных компонент для выборки изображений человеческих лиц. В первой строке показаны лица людей из контрольной выборки, т.е. из специально отложенной части выборки, которая не использовалась алгоритмами в процессе обучения. На второй и третьей строке — восстановленные изображения из скрытых состояний автокодировщика и метода главных компонент соответственно одинаковой размерности. Здесь хорошо заметно, насколько более качественно сработал автокодировщик. В этой же статье еще один показательный пример: сравнение результатов работы автокодировщика и метода LSA для задачи информационного поиска. Метод LSA, как и метод главных компонент, является классическим методом машинного обучения и часто применяется в задачах, связанных с обработкой естественного языка. На рисунке представлены 2D-проекции множества документов, полученные с помощью автокодировщика и метода LSA. Цветами обозначена тематика документа. Видно, что проекция от автокодировщика хорошо разбивает документы по темам, в то время как LSA выдает куда более зашумленный результат. Другим важным применением автокодировщиков является предобучение сетей. Предобучение сетей применяется в случае, когда оптимизируемая сеть является достаточно глубокой. В этом случае обучение сети “с нуля” может оказаться досточно сложным, поэтому сначала всю сеть представляют в виде цепочки энкодеров. Алгоритм предобучения достаточно прост: для каждого слоя мы обучаем свой автокодировщик, и затем задаем, что выход очередного энкодера является одновременно входом для последующего слоя сети. Полученная модель состоит из цепочки энкодеров, обученных жадно сохранять наиболее важные признаки объектов, каждый на своем слое. Схема предобучения представлена ниже: Источник: psyyz10.github.io Такая структура называется Stacked Autoencoder и часто применяется как “разгон” для дальнейшего обучения полной модели глубокой сети. Мотивация такого обучения нейросети заключается в том, что глубокая нейросеть является невыпуклой функцией: в процессе обучения сети оптимизация параметров может “застрять” в локальном минимуме. Жадное предобучение параметров сети позволяет найти хорошую точку старта для итогового обучения и тем самым постараться избежать таких локальных минимумов. Конечно, мы рассмотрели далеко не все возможные структуры, ведь есть еще Sparse Autoencoders, Denoising Autoencoders, Contractive Autoencoder, Reconstruction Contractive Autoencoder. Они различаются между собой использованием различных функций ошибки и штрафных слагаемых к ним. Все эти архитектуры, как нам кажется, достойны отдельного обзора. В нашей же статье мы показываем прежде всего общую концепцию автокодировщиков и те конкретные задачи текстового анализа, которые решаются с его использованием.
А как это работает в текстах?
Перейдем теперь к конкретным примерам применения автокодировщиков для задач анализа текстов. Нас интересуют обе стороны применения – как модели для получения внутренних представлений, так и использования этих внутренних представлений как признаков, например, в дальнейшей задаче классификации. Статьи по этой теме чаще всего затрагивают такие задачи, как сентимент анализ, или детектирования перефразирований, но также встречаются работы, описывающие применения автокодировщиков для сравнения текстов на разных языках или для машинного перевода.
В задачах текстового анализа чаще всего объектом выступает предложение, т.е. упорядоченная последовательность слов. Таким образом, автокодировщик принимает на вход именно эту последовательность слов, а точнее – векторных представлений этих слов, взятых из некоторой предобученной ранее модели. Что такое векторные представления слов, было рассмотрено на Хабре достаточно подробно, например здесь. Таким образом, автокодировщик, принимая на вход последовательность слов, должен обучить некоторое внутреннее представление всего предложения, отвечающее тем характеристикам, которые важны для нас, исходя из поставленной задачи. В задачах текстового анализа нам необходимо отобразить предложения в векторы так, чтобы они были близки в смысле некоторой функции расстояния, чаще всего косинусной меры:
Источник: Deep Learning for NLP (without Magic) Одним из первых авторов, кто показал успешное применение автокодировщиков в текстовом анализе, был Richard Socher. В своей статье Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection он описывает новую структуру автокодировщика — Unfolding Recursive Autoencoder (Unfolding RAE) (см. на рисунок ниже). Unfolding RAE Предполагается, что структура предложения задана синтаксическим парсером. Рассматривается самая простая структура – структура бинарного дерева. Такое дерево состоит из листьев — слов фрагмента, внутренних узлов (узлов ветвления) — словосочетании? и терминальнои? вершины. Принимая на вход последовательность слов (x1,x2,x3) (три векторных представления слов в этом примере), автокодировщик последовательно кодирует, в данном случае, справа-налево, векторные представления слов предложения в векторные представления словосочетаний, а затем в векторное представление всего предложения. Конкретно в этом примере мы сначала кoнкатенируем векторы x2 и x3, затем домножаем их на матрицу We, имеющую размерность hidden?2visible, где hidden – где размер скрытого внутреннего представления, visible – размерность вектора слова. Таким образом, мы снижаем размерность, затем добавляя нелинейность с помощью функции tanh. На первом шаге мы получаем скрытое векторное представление для словосочетания двух слов x2 и x3: h1=tanh?(We [x2,x3 ]+be). На втором мы объединяем его и оставшееся слово h2 = tanh?(We [h1,x1 ]+be) и получаем векторное представление для всего предложения целиком — h2. Как и говорилось выше, в определении автокодировщика, нам нужно минимизировать ошибку между объектами и их восстановленными версиями. В нашем случае это – слова. Поэтому, получив финальное векторное представление всего предложения h2, мы раскодируем его ввосстановленные версии (x1',x2',x3'). Декодер здесь работает по тому же принципу, что и энкодер, только матрица параметров и вектор сдвига здесь другие: Wd и bd.
Используя структуру бинарного дерева, можно кодировать предложения любой длины в вектор фиксированной размерности – мы всегда объединяем по паре векторов одинаковой размерности, используя при этом одну и ту же матрицу параметров We. В случае небинарного дерева нужно просто заранее инициализировать матрицы для случаев, если мы хотим объединять больше двух слов – 3, 4, … n, в данном случае матрица будет просто иметь размерность hidden?invisible.
Примечательно то, что в этой статье обученные векторные представления фраз используются не только для решения задачи классификации — перефразированными или нет является пара предложений. Приводятся также данные эксперимента по поиску ближайших соседей — основываясь лишь на полученном векторе предложения, для него ищутся ближайшие в выборке вектора, которые близки ему по смыслу:
Однако никто не мешает нам использовать для последовательного объединения слов в предложение и другие архитектуры сетей для кодирования и декодирования. Вот пример из статьи NIPS 2017 — Deconvolutional Paragraph Representation Learning: Мы видим, что кодирование выборки X в скрытое представление h происходит с помощью сверточной нейронной сети, по такому же принципу работает и декодер. Или вот пример с использованием GRU-GRU в статье Skip-Thought Vectors. Интересной особенность здесь является то, что модель работает с тройками предложений: (si-1, si, si+1). Предложение si кодируется с применением стандартных формул GRU, а декодер, используя информацию о внутреннем представлении si, пытается раскодировать si-1 и si+1, также используя GRU.
Принцип работы в данном случае напоминает стандартную модель нейросетевого машинного перевода, который работает по схеме encoder-decoder. Однако, здесь у нас нет двух языков, мы подаем на вход нашему блоку кодирования фразу на одном языке и ее же пытаемся восстановить. В процессе обучения идет минимизация некоторого внутреннего функционала качества (это не всегда ошибка реконструкции), затем, если требуется, предобученные векторы используются в качестве признаков в другой задаче. В другой работе — Bilingual Correspondence Recursive Autoencoders for Statistical Machine Translation — представлена архитектура, которая позволяет по-новому взглянуть на машинный перевод. Сначала для двух языков отдельно обучаются рекурсивные автокодировщики (по принципу, описанному выше — там, где вводился Unfolding RAE). Затем, между ними обучается третий автокодировщик — отображение между двумя языками. Такая архитектура имеет явное преимущество — при отображении текстов на разных языках в одно общее скрытое пространство мы можем сравнивать их, не используя машинный перевод, как промежуточный шаг. Предобучение автокодировщиков на текстовых фрагментах часто встречается в статьях по обучению ранжирования. Тут, опять же, важен тот факт, что мы для обучения итогового функционала качества ранжирования сначала предобучаем автокодировщик для лучшей инициализации векторов запросов и ответов, подаваемых на вход сети. И, разумеется, мы не можем не упомянуть о Вариационных автокодировщиках (Variational Autoencoders, или VAE) как о генеративных моделях. Лучше всего, конечно, просто посмотреть эту запись лекции от Яндекса. Нам же достаточно сказать следующее: если мы хотим из скрытого пространства обычного автокодировщика генерировать объекты, то качество такой генерации будет невысоким, поскольку мы ничего не знаем о распределении скрытой переменной. Но можно сразу тренировать автокодировщик на генерацию, вводя предположение о распределении.