Деревья решений
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-03-11 08:17
Сегодня мы разберём такой вид алгоритмов машинного обучения, как деревья решений
Немного теории
Сегодня на повестке дня новый алгоритм ML - деревья решений. Само по себе дерево можно представить как кучу вложенных конструкций if / else, для которых установлена максимальная глубина(уровень вложенности).
На деле оно работает не совсем так, а пример визуализированой работы дерева решений изображен ниже:

Тонкости алгоритма
Так как дерево решений по методу своей работы несколько отличается от тех алгоритмов, которые мы рассматривали ранее, то у него так тем более есть свои "подводные камни".
Одним из таких "камней" есть склонность к переобучению. Даже при грамотной настройке параметров модели довольно часто можно встретить слишком хорошую точность на тренировочной выборке.
Вторым, скорее положительным моментом, есть отсутствие необходимости в нормализации входных данных.
Так же хотелось бы выделить негибкую гиперпараметризацию модели. Здесь есть один основной параметр - max_depth, отвечающий, как вы уже поняли, за максимальную "высоту" дерева.
Реализация в sklearn
Алгоритм дерева решений реализован в подмодуле sklearn.tree в классе DecisionTreeClassifier/DecisionTreeRegressor. Для сегодняшнего тестирования я нашел очень "чистый" датасет, в котором приведены характеристики более 17000 звезд(признаюсь честно, я ничего не понимаю в астрономии, поэтому если вы мне напишите, что значат эти характеристики, я буду очень признателен). Всё это нужно для определения того, является ли звезда пульсаром. Подробнее про пульсары можно почитать в Википедии.
Сам датасет можно найти на Kaggle.
Также я оставлю файл .csv в своем Телеграмм-канале.
Подготовка датасета
Начало нашей работы всегда начинается с импортирования модулей.

Для начала будем использовать Pandas, NumPy, функцию разделения данных и сам класс дерева решений, а потом будем импортировать другие нужные нам классы и функции (однако согласно РЕР8 все модули нужно импортировать в начале файла, сейчас я так не сделаю, чтобы не "убить интригу").
Запишем данные из файла в DataFrame:

Dataframe.head(). На самом деле метод head() может принимать любое целое число от 1 до длины файла для вывода нужного кол-ва колонок, а по умолчанию этот параметр равняется 5.
Теперь посмотрим, значения какого типа у нас есть и встречаются ли NaN(Not a Number) значения.

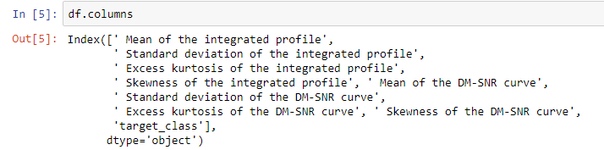
Видите отступы возле названий признаков? Когда я готовил код для этой статьи, это сбило меня с толку. Оказывается, названия признаков начинаются с пробела. Убирать это мы не будем, но запомним.
Чтобы подтвердить мою гипотезу, воспользуемся полем df.columns.
Наша "цель":

Нам желательно бы узнать, сколько настоящих пульсаров имеется у нас в наборе.

Довольно удобная функция, которая позволила нам узнать, что в датасете имеется 1639 настоящих пульсаров.
Теперь разделим таблицу на обучающие данные и цель:

Срезы в DataFrame. В отличии от срезов NumPy или стандартного среза Python, в Pandas срезы включают последний элемент.
По стандарту, разделяем данные на обучающие и тестовые:

Примечание. На скриншотах кода может быть плохо видно, ссылка на весь код из статьи будем в конце.
Да да, train_test_split работает с объектами DataFrame.
Теперь инициализируем класс дерева с настройками по умолчанию:

Оценим его обобщающую способность:

API sklearn. Как мы можем заметить, все модели sklearn имеют общий набор методов, что делает работу даже с неизвестными моделями намного легче.
Как мы видим, мы столкнулись с переобучением, о чем говорилось выше. Давайте поменяем параметр настройки модели max_depth:

Так-то лучше. Однако такая обобщающая способность на таком "простом" наборе данных выглядит так себе. Далее мы разберём ансамбли на основе дерева.
Визуализация дерева
Задержку в публикации этой статьи вызвал мой ступор в использовании graphviz. Пакет python, установленный с помощью pip3, проблемы не решал.
Для того, чтобы всё работало корректно, необходимо скачать архив вот отсюда и распаковать его, указав в PATH путь к распакованному архиву. Пакет python также нужно установить.
Также возможно использование модуля pydotplus(устанавливаем с тем же pip3/pip).

Функция export_graphviz возвращает .dot код. Также мы можем получить визуализированое дерево скопировав содержимое export_graphviz и вставив его в webgraphviz.com.
Мы также можем "открыть" дерево в самом блокноте:

или записать в картинку и вывев её в блокноте:

Примечание. По неизвестной мне причине, качество фотографии оставляет желать лучшего(скрин из блокноте выглядит в разы лучше).
Ансамбли
Ансамбль решений - объединение слабых учеников для увеличения обобщающей способности.
RandomForest
Случайный лес - ансамбль на основе дерева, создающий множество деревьев, немного отличающихся друг от друга. Т.к. деревья быстро переобучаются, мы уменьшим степень переобучения путём усреднения их результатов.
В sklearn ансамбли находятся в подмодуле ensemble:

Мы сразу получаем неплохую обобщающую способность, однако дальше больше. Мы можем настроить параметр n_estimator для регулирования кол-ва слабых учеников и max_depth для максимальной глубины отдельного ученика.

Теперь "правильность" модели перешагнула за 98%.
Дополнение. Я решил поиздеваться над своим ПК и запустил такой фрагмент кода:

Да да, я обучал рандомный лес 450 раз, получив такие графики:

К сожалению, качество картинки ухудшается, потому если кто хочет, можете запустить и попробовать самим, однако это "опасно".
Сохранить результат в картинку можно так:

Градиентный бустинг
Суть градиентного бустинга в объединении множества слабых учеников, каждый из которых даёт хороший результат для некоторого объема данных. Таким образом, для увеличения обобщающей способности используется всё большее количество деревьев.
Кроме тех параметров, которые мы наблюдали у случайного леса, тут также присутствует параметр learning_rate - темп обучения, который регулирует сложность модели. Чем сложнее модель, тем выше шанс на хорошую "аккуратность", однако и обучаться она будет дольше.
Пример использования градиентного бустинга:

На данный момент градиентный бустинг является одним из лидеров в соревнованиях по машинному обучению, а также часто используется в коммерческих целях.
Заключение
Сегодня мы разобрали новый вид алгоритмов машинного обучения - деревья, и ансамбли на основе деревьев. Были проанализированы основные трудности в работе с деревьями, а также гиперпараметризация моделей в sklearn.
Весь код из статьи можно найти тут.
Источник: m.vk.com