Эхо войны в мировых новостях
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-02-25 01:33
«Системный Блокъ» уже не раз рассказывал о той магии, которая получается из соединения методов машинного обучения, больших корпусов текстов — и лингвистического знания о том, что смысл слов в языке задается контекстом их употребления. Научное название такой магии — дистрибутивная семантика. С ее помощью компьютерные модели обучаются видеть смысловую близость между словами — например, понимать что слово помидор близко к слову огурец, но далеко от слова философия.
Дистрибутивную семантику можно применять для исследования смысловых сдвигов в языке. Например, на основе анализа контекстов несложно установить, когда основным значением слова gay стало не «веселый», а «гомосексуалист».
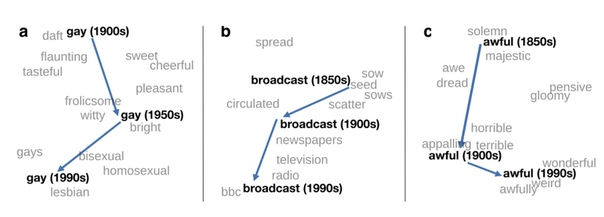
А можно ли через сдвиги в языке отслеживать изменения в обществе? Команда исследователей из Университета Осло решила попробовать — и применила дистрибутивную семантику для автоматического выявления эскалации вооруженных конфликтов на основе новостных текстов.
Мониторинг войн онлайн
Сбором данных о конфликтах занимаются исследователи из Университете Уппсалы в рамках программы Uppsala Conflict Data Program при участии Института исследования мира (Peace Research Institute) в Осло. Вместе они поддерживают цифровую базу данных вооруженных конфликтов, происходящих в мире с 1946 года. Конфликтом считается всякое вооруженное противостояние, в котором погибли не менее 25 человек. В базе хранится информация об интенсивности и динамике конфликтов: если столкновения ослабевают, показатель интенсивности в базе за соответствующий год снижается. Также у конфликта указаны место и дата начала и может быть дата окончания.
Большую часть базы составляют внутренние конфликты вроде гражданских войн, повстанческих выступлений, этнических чисток и т.п. С ними и работали исследователи. Они попытались построить модель, которая анализировала бы контексты употребления названий стран и территорий (например, «Конго» или «Колумбия») в новостях за разные годы — и на основе этих данных пыталась предсказать динамику конфликта в этих странах: ослаб он, усилился или остался без изменений.
Таким образом, задача была сведена к классификации пар «год + локация конфликта» на три класса: «war» — усиление конфликта, peace — ослабление, деэскалация, stable — изменений не произошло. База конфликтов в таком случае служит как обучающие данные для предсказательной модели: ведь там уже размечено, в каком году в какой стране начался/закончился/усилился/ослаб вооруженный конфликт.
Для построения и тестирования модели ученые взяли огромный корпус новостей Gigaword — почти 12 гигабайт новостных текстов от Associated Press, Agence France Press, New York Times и английской службы китайского агентства Xinhua. Тексты разделили по годам, и затем построили для каждого года дистрибутивные модели — говоря упрощенно, некоторое математическое представление того, в каких контекстах употребляются разные слова.
Первый способ, который применили исследователи, был уже известен раньше — он использовался как раз для отслеживания семантических сдвигов в словах. В этом способе просто сравнивались вектора в модели за один год — с векторами предыдущего года (либо всех предыдущих лет). Однако этот способ показал крайне низкие результаты.
Лексикон войны
Также ученые предложили свой собственный вариант, когда исследуется поведение конкретного набора слов, связанных с конфликтом. Например, слов kill (убивать), die (умирать), injury (ранение), dead (мертвый), death(смерть), wound (рана), massacre (побоище, расправа). Далее в каждом году измеряется расстояние векторов контекстов этих слов — относительно контекстного вектора локации, в которой происходит конфликт.
Этот метод показал результат, заметно превышающий показатели первого способа: F-мера (геометрическое среднее точности и полноты информационного поиска) поднялась с 15% до 36%. Интересно, что сравнение текущего года с предыдущим дает лучший результат при определении динамики вооруженного конфликта, чем сравнение с моделью для всех предыдущих лет. По-видимому, при обучении на новостях за несколько лет модель оказывается менее конкретной, «зашумляется» лишней информацией.
Пока качество обнаружения конфликтов лингвистической моделью остается недостаточным для полной автоматизации. Однако авторы исследования планируют дорабатывать свой метод. По их мнению, такая предсказательная модель может быть использована для полуавтоматической разметки данных в социальных исследованиях. Еще одно интересное направление исследований — сравнение конфликтов в разных источниках новостей, например, в New York Times и китайском агенстве Xinhua.
P.S. Если вам интересно, как лингвисты предсказывают смерти от инфарктов и инсультов, вам сюда. А узнать больше о дистрибутивной семантике можно здесь и здесь.
Источник: www.aclweb.org