Классификация в машинном обучении
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-01-09 12:17
Всем доброго времени суток! Сегодняшняя тема - классификация, её определение и практический пример.
Определение
Одной из важнейших задач машинного обучения является классификация - выбор одного варианта из множества классов.
Классификация делится на два вида: мультиклассовая и бинарная. Как вы уже поняли из названия, смысл бинарной классификации - выбор из двух вариантов (классов), а мультиклассовой - выбор из нескольких вариантов(классов).
Несколько примеров:
- предсказание пола человека по определённым признакам
- распределение отзывов сервиса на положительные и отрицательные
- предсказание модели автомобилей Ауди исходя из разных характеристик
Мы уже строили модель классификации на основе набора данных про рак молочной железы, что является примером бинарной классификации.
Практический пример
В качестве примера Андреас Мюллер в свой книге использовал датасет из sklearn про ирис. Придумывать ничего лишнего я не буду, потому в качестве примера построю несколько моделей на основе этого набора данных.

Что нам сегодня нужно: matplotlib для построения графиков обобщающей способности модели, функция разделения тестовых и обучающих данных, сам датасет, numpy для её нескольких функций и три класса, в которых реализованы "линейка", метод k ближайших соседей и дерево решений.
Загрузим наш датасет, вызвав функцию load_iris():

Отлично, теперь посмотрим, какие поля имеет наш датасет.

Здесь всё стандартно. В поле data хранятся наборы признаков, в поле target находятся ответы... Лучше покажу:
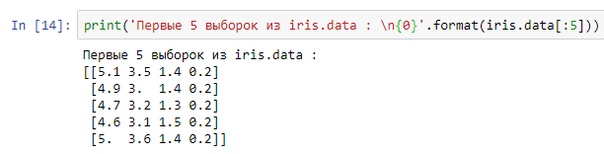

И тут появляется вопрос, что означают эти числа в выборках и нули в ответах. Для этого "распечатаем" iris.feature_names и iris.target_names.

Если совсем разбирать данный датасет как реальную задачу, то мы должны визуализировать набор, определить, есть ли значения не подходящего типа в столбцах, ведь у нас есть только численные значения, а могут присутствовать 'NaN' и т.д. Также необходимо преобразовать данные к одной системе измерения (исключить наличие значений в дюймах и т.д.). Однако всё любезно сделали за нас, нам остались только создать модели.
Для обучения моделей разделим данные, этот шаг мы проходили кучу раз:

Первой будет линейный классификатор:

Как мы видим, модель прекрасно справляется на наборе данных с небольшим кол-вом признаков. У этого класса есть параметр C, который уменьшает степень регуляризации(про неё мы говорили, когда обсуждали Ridge и Lasso).
Давайте посмотрим, как сильно влияет C на обобщающую способность модели:

Для этого построим график зависимости точности работы модели от C на тренировочной и тестовой выборках. Результат таков:
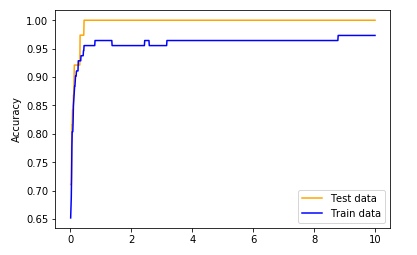
Как мы видим, чем больше C, тем меньше уровень регуляризации, что даёт нам более сложную модель. Теперь перейдем к методу "соседей".

У класса KNeighborsClassifier есть параметр, определяющий, сколько соседей будет рассмотрено. Мы уже рассматривали, как это влияет на сложность моделей здесь.
Отлично, на дереве решений остановимся подольше. Алгоритм довольно прост: дерево выстраивает цепочки условий <if ... else>, исходя из которых и определяет свой результат.

Как мы видим, дерево довольно хорошо сработало на небольших объемах данных(у нас здесь всего 150 строк), однако его сложность тяжело контролировать, ведь дерево при достаточной глубине сильно переобучается.
Дерево - сверхинтересный алгоритм МЛ, и у него есть куча фишек, такие как распечатка всех условий в формате .dot или .pdf. Так что чтобы не затягивать, дерево будет рассмотрено отдельно вместе с ансамблями(рандомный лес, градиентный бустинг деревьев).
Заключение. Сегодня мы разобрали понятие классификации, на какие виды она делится, и построили несколько моделей, которые дали ожидаемо отличный результат, так как набор данных включал в себя всего 4 признака и 150 выборок.
Также рекомендую ознакомиться с другими материалами посвященными Машинному обучению и языку программирования Python. Ну и подпишись на сообщество CODE BLOG, если все еще этого не сделал. Здесь публикуется лучший контент для программистов.
Источник: m.vk.com