Diversity in Faces - датасет от IBM с миллионом лиц для борьбы с предвзятостью алгоритмов
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2019-01-30 18:00
большие данные big data, распознавание образов, искусственный интеллект

Diversity in Faces — большой и разнообразный набор данных, который содержит миллион изображений размеченных лиц людей. Открывая доступ к датасету, в IBM Research надеются повысить точность распознавания лиц людей разных рас, полов и возрастов и уменьшить предвзятость алгоритмов.
Исследователи уже работают с такими признаками, как возраст, пол и цвет кожи, но эти функции не обеспечивают достаточно разнообразия, чтобы охарактеризовать всех людей. По словам IBM, необходимо учитывать другие признаки, такие как симметрия лица, контраст, разрез и размер глаз, носа, лба и рта.
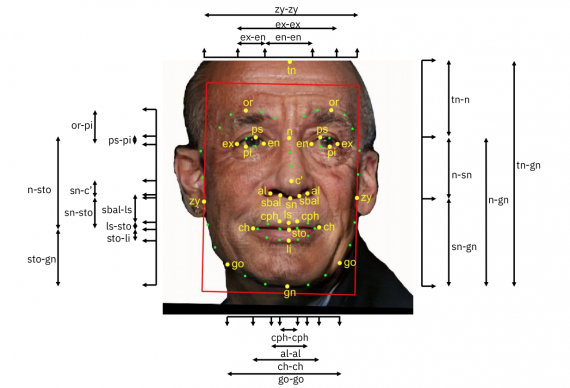
В наборе Diversity in Faces ученые из IBM собрали миллион изображений лиц из другого крупного датасета — Flickr Creative Commons и аннотировали их с помощью 10 «устоявшихся и независимых» систем кодирования (методов оценки) из научных публикаций. Каждое кодирование включает разные объективные измерения: размер головы, контраст лица, длину носа, высоту лба, пропорции лица, возраст, пол и другие параметры и их соотношение друг к другу. Вместе эти измерения создают «отпечаток лица», который алгоритм будет использовать, например, для сопоставления нескольких фотографий одного и того же человека.
«Мы хотим, чтобы распознавание лиц работало точно для каждого из нас. Производительность не должна отличаться для разных людей или разных групп населения» — написали исследователи в статье. Разработчики не ожидают, что первая версия набора поможет полностью избежать предвзятости, но это — конечная цель.
Датасет Diversity in Faces предоставляется по запросу. Для получения доступа нужно заполнить анкету и отправить заявку.
Источник: neurohive.io