Первый видеокодек на машинном обучении кардинально превзошёл все существующие кодеки, в том числе H.265 и VP9
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-11-29 08:00

Примеры реконструкции фрагмента видео, сжатого разными кодеками с примерно одинаковым значением BPP (бит на пиксель). Сравнительные результаты тестирования см. под катом
Исследователи из компании WaveOne утверждают, что близки к революции в области видеокомпрессии. При обработке видео высокого разрешения 1080p их новый кодек на машинном обучении сжимает видео примерно на 20%лучше, чем самые современные традиционные видеокодеки, такие как H.265 и VP9. А на видео «стандартной чёткости» (SD/VGA, 640?480) разница достигает 60%. Разработчики называют нынешние методы видеокомпрессии, которые реализованы в H.265 и VP9, «древними» по стандартам современных технологий: «За последние 20 лет основы существующих алгоритмов сжатия видео существенно не изменились, — пишут авторы научной работы во введении своей статьи. — Хотя они очень хорошо спроектированы и тщательно настроены, но остаются жёстко запрограммированными и как таковые не могут адаптироваться к растущему спросу и всё более разностороннему спектру применения видеоматериалов, куда входят обмен в социальные СМИ, обнаружение объектов, потоковое вещание виртуальной реальности и так далее». Применение машинного обучения должно наконец перенести технологии видеокомпрессии в 21 век. Новый алгоритм сжатия значительно превосходит существующие видеокодеки. «Насколько нам известно, это первый метод машинного обучения, который показал такой результат», — говорят они.
Основная идея сжатия видео заключается в удалении избыточных данных и замене их более коротким описанием, которое позволяет воспроизводить видео позже. Большая часть сжатия видео происходит в два этапа.
Первый этап — сжатие движения, когда кодек ищет движущиеся объекты и пытается предсказать, где они будут в следующем кадре. Затем вместо записи пикселей, связанных с этим движущимся объектом, в каждом кадре алгоритм кодирует только форму объекта вместе с направлением движения. Действительно, некоторые алгоритмы смотрят на будущие кадры, чтобы определить движение ещё более точно, хотя это явно не сможет работать для прямых трансляций.
Второй шаг сжатия удаляет другие избыточности между одним кадром и следующим. Таким образом, вместо того, чтобы записывать цвет каждого пикселя в голубом небе, алгоритм сжатия может определить область этого цвета и указать, что он не изменяется в течение следующих нескольких кадров. Таким образом, эти пиксели остаются того же цвета, пока не сказали, чтобы изменить. Это называется остаточным сжатием.
Новый подход, который представили учёные, впервые использует машинное обучение для улучшения обоих этих методов сжатия. Так, при сжатии движения методы машинного обучения команды нашли новые избыточности на основе движения, которые обычные кодеки никогда не были в состоянии обнаружить, а тем более использовать. Например, поворот головы человека из фронтального вида в профиль всегда даёт аналогичный результат: «Традиционные кодеки не смогут предсказать профиль лица исходя из фронтального вида», — пишут авторы научной работы. Напротив, новый кодек изучает эти виды пространственно-временных шаблонов и использует их для прогнозирования будущих кадров.
Другая проблема заключается в распределении доступной полосы пропускания между движением и остаточным сжатием. В некоторых сценах более важно сжатие движения, а в других остаточное сжатие обеспечивает наибольший выигрыш. Оптимальный компромисс между ними отличается от кадра к кадру.
Традиционные алгоритмы обрабатывают оба процесса отдельно друг от друга. Это означает, что нет простого способа отдать преимущество тому или другому и найти компромисс.
Авторы обходят это путём сжатия обоих сигналов одновременно и на основе сложности кадра определяют, как распределить пропускную способность между двумя сигналами наиболее эффективным способом.
Эти и другие усовершенствования позволили исследователям создать алгоритм сжатия, который значительно превосходит традиционные кодеки (см. бенчмарки ниже).

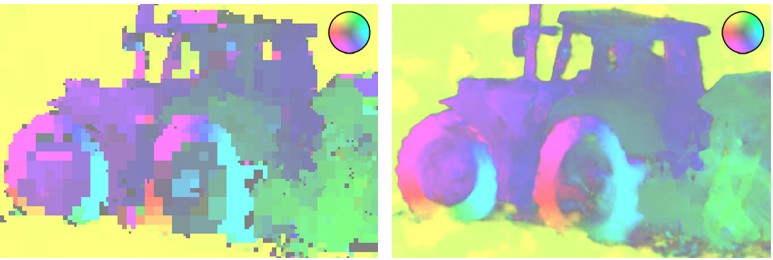
Однако новый подход не лишен некоторых недостатков, отмечает издание MIT Technology Review. Пожалуй, главным недостатком является низкая вычислительная эффективность, то есть время, необходимое для кодирования и декодирования видео. На платформе Nvidia Tesla V100 и на видео VGA-размера новый декодер работает со средней скоростью около 10 кадров в секунду, а кодер и вовсе со скоростью около 2 кадров в секунду. Такие скорости просто невозможно применить в прямых видеотрансляциях, да и при офлайновом кодировании материалов новый кодер будет иметь весьма ограниченную сферу использования.
Более того, скорости декодера недостаточно даже для просмотра видеоролика, сжатого этим кодеком, на обычном персональном компьютере. То есть для просмотра этих видеороликов даже в минимальном качестве SD в данный момент требуется целый вычислительный кластер с несколькими графическими ускорителями. А для просмотра видео в качестве HD (1080p) понадобится целая компьютерная ферма.
Остаётся надеяться только на увеличение мощности графических процессоров в будущем и на совершенствование технологии: «Текущая скорость не достаточна для развёртывания в реальном времени, но должна быть существенно улучшена в будущей работе», — пишут они.
Бенчмарки
В тестировании принимали участие все ведущие коммерческие кодеки HEVC/H.265, AVC/H.264, VP9 и HEVC HM 16.0 в эталонной реализации. Для первых трёх использовался Ffmpeg, а для последнего — официальная реализация. Все кодеки были максимально настроены, насколько позволили знания исследователей. Например, для удаления B-фреймов использовался H.264/5 с опцией bframes=0, в кодеке аналогичная процедура осуществлялась настройкой -auto-alt-ref 0 -lag-in-frames 0 и так далее. Для максимизации производительности на соответствие метрике MS-SSIM, естественно, кодеки запускались с флагом -ssim.
Все кодеки проверяли на стандартной базе видеороликов в форматах SD и HD, которые часто используются для оценки алгоритмов сжатия видео. Для SD-качества использовалась библиотека видео в разрешении VGA от e Consumer Digital Video Library (CDVL). Она содержит 34 видеоролика с общей длиной 15 650 кадров. Для HD использовался набор данных Xiph 1080p: 22 видеоролика общей длиной 11 680 кадров. Все видеоролики 1080p были обрезаны по центру до высоты 1024 (в данный подход нейросеть исследователей способна обрабатывать только измерения с размерностями, кратными 32 по каждой стороне).
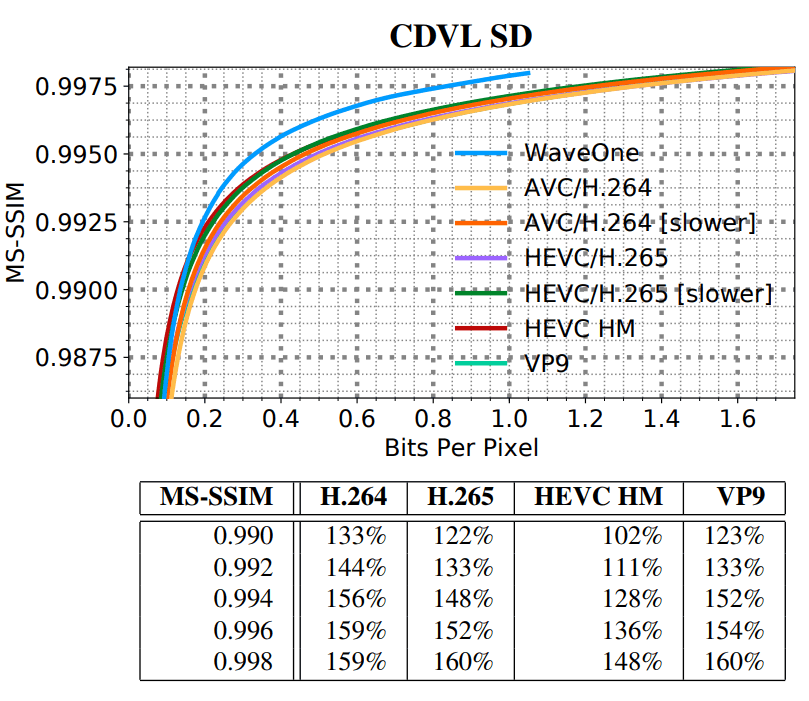
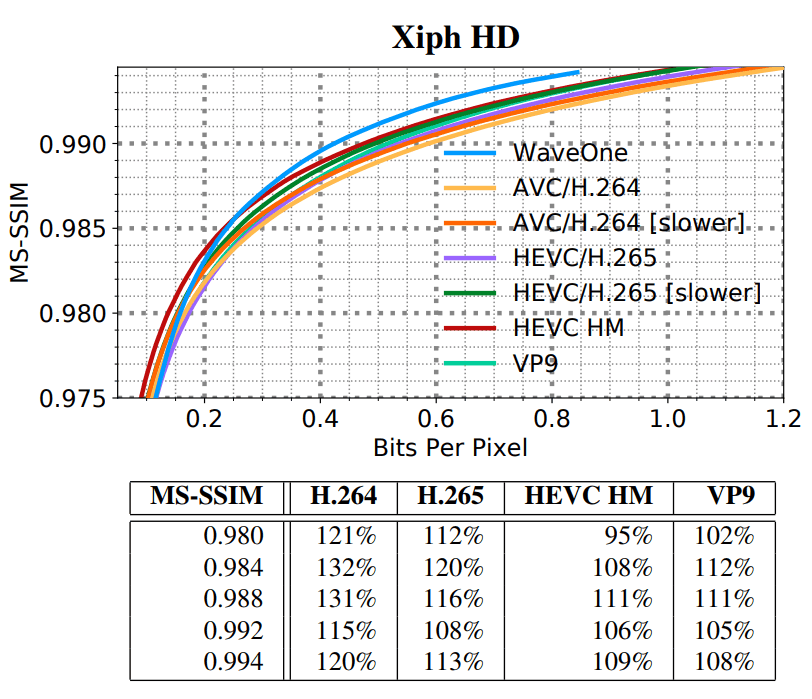
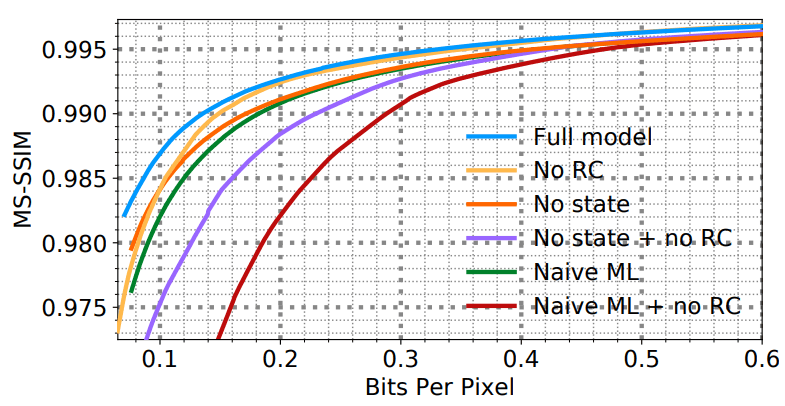
Различные результаты тестирования показаны на диаграммах ниже:
- средние значения MS-SSIM для всех видеороликов в наборе для каждого кодека;
- сравнение размеров файла при усреднении значения MS-SSIM для всех кодеков;
- влияние различных компонентов кодека WaveOne на качество сжатия (нижняя диаграмма).
Не стоит удивляться такому высокому уровню сжатия и кардинальному превосходству над традиционными видеокодеками. Данная работа во многом основана на предыдущих научных статьях, где описываются различные методы сжатия статичных изображений на базе машинного зрения. Все они намного превосходят по уровню и качеству сжатия традиционные алгоритмы. Например, см. работы G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar. Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell. Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli. End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici. Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 и другие. Прогресс в области ML-сжатия статических изображений неизбежно привёл к появлению первых видеокодеков, основанных на машинном обучении. С увеличением производительности графических ускорителей реализация видеокодеков стала первым кандидатом.
Статья «Выученное сжатие видео» опубликована 16 ноября 2018 года на сайте препринтов arXiv.org (arXiv:1811.06981). Авторы научной работы — Орен Риппель (Oren Rippel), Санджей Наир (Sanjay Nair), Карисса Лью (Carissa Lew), Стив Брэнсон (Steve Branson), Александер Андерсон (Alexander G. Anderson), Любомир Бурдев (Lubomir Bourdev).
Лучший комментарий Stas911: Altaisky: Статья про видеокодек и ни одного видео. Нечего было показать? Stas911: Они ещё декодируют первый кадр. Проявите терпение.
Источник: habr.com