Играем в Mortal Kombat с помощью TensorFlow.js
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-11-06 16:11
распознавание образов, реализация нейронной сети, примеры ии

Экспериментируя с улучшениями для модели прогнозирования Guess.js, я стал присматриваться к глубокому обучению: к рекуррентным нейронным сетям (RNN), в частности, LSTM из-за их «необоснованной эффективности» в той области, где работает Guess.js. В то же время я начал играться с свёрточными нейросетями (CNN), которые тоже часто используются для временных рядов. CNN обычно используют для классификации, распознавания и обнаружения изображений.
Исходный код для этой статьи и МК.js лежат у меня на GitHub. Я не выложил набор данных для обучения, но можете собрать свои собственные и обучить модель, как описано ниже!
Поиграв с CNN, я вспомнил об эксперименте, который проводил несколько лет назад, когда разработчики браузеров выпустили getUserMedia API. В нём камера пользователя служила контроллером для воспроизведения небольшого JavaScript-клона Mortal Kombat 3. Вы можете найти ту игру в репозитории GitHub. В рамках эксперимента я реализовал базовый алгоритм определения положения, который классифицирует изображение по следующим классам:
- Удар левой или правой рукой
- Удар левой или правой ногой
- Шаги влево и вправо
- Приседание
- Ничего из вышеперечисленного
Алгоритм настолько прост, что я могу объяснить его в нескольких фразах:
Алгоритм фотографирует фон. Как только пользователь появляется в кадре, алгоритм вычисляет разницу между фоном и текущим кадром с пользователем. Так он определяет положение фигуры пользователя. Следующий шаг — отображение тела пользователя белым на чёрном. После этого строятся вертикальная и горизонтальная гистограммы, суммирующие значения для каждого пикселя. На основе этого вычисления алгоритм определяет текущее положение тела.
На видео показано, как работает программа. Исходный код на GitHub.
Хотя крошечный клон MK работал успешно, алгоритм далёк от совершенства. Требуется кадр с фоном. Для правильной работы фон должен быть одинакового цвета на протяжении всего выполнения программы. Такое ограничение означает, что изменения света, тени и прочего внесут помехи и дадут неточный результат. Наконец, алгоритм не распознаёт действия; он классифицирует новый кадр всего лишь как положение тела из предопределённого набора.
Теперь, благодаря прогрессу в веб-API, а именно WebGL, я решил вернуться к этой задаче, применив TensorFlow.js.
Введение
В этом статье я поделюсь опытом создания алгоритма классификации положений тела с помощью TensorFlow.js и MobileNet. Рассмотрим следующие темы:
- Сбор обучающих данных для классификации изображений
- Аугментация данных с помощью imgaug
- Перенос обучения с MobileNet
- Двоичная классификация и N-ричная классификация
- Обучение модели классификации изображений TensorFlow.js в Node.js и использование её в браузере
- Несколько слов о классификации действий с LSTM
В этой статье мы сведём проблему до определения положения тела на основе одного кадра, в отличие от распознавания действия по последовательности кадров. Мы разработаем модель глубокого обучения с учителем, которая на основе изображения с веб-камеры пользователя определяет движения человека: удар рукой, ногой или ничего из этого.
К концу статьи мы сможем построить модель для игры в МК.js:
Для лучшего понимания статьи читатель должен быть знаком с фундаментальными понятиями программирования и JavaScript. Базовое понимание глубокого обучения тоже полезно, но не обязательно.
Сбор данных
Точность модели глубокого обучения в значительной степени зависит от качества данных. Нужно стремиться к сбору обширного набора данных, как в продакшне.
Наша модель должна уметь распознавать удары руками и ногами. Это означает, что мы должны собирать изображения трёх категорий:
- Удары рукой
- Удары ногой
- Другие
В этом эксперименте мне помогали собирать фотографии два волонтёра (@lili_vs и @gsamokovarov). Мы записали 5 видеороликов QuickTime на моём MacBook Pro, каждый из которых содержит 2?4 удара рукой и 2?4 удара ногой.
Затем используем ffmpeg для извлечения из видеороликов отдельных кадров и сохранения их в виде изображений jpg:
ffmpeg -i video.mov $filename%03d.jpg
Для выполнения вышеуказанной команды сначала нужно установить на компьютере ffmpeg.
Если мы хотим обучить модель, то должны предоставить входные данные и соответствующие им выходные данные, но на этом этапе у нас только куча изображений трёх человек в разных позах. Чтобы структурировать данные, нужно классифицировать кадры в трёх категориях: удары руками, ногами и другие. Для каждой категории создаётся отдельная директория, куда перемещаются все соответствующие изображения.
Таким образом, в каждом каталоге должно быть около 200 изображений, похожих на приведённые ниже:

Обратите внимание, что в каталоге «Другие» будет гораздо больше изображений, потому что относительно мало кадров содержат фотографии ударов руками и ногами, а на остальных кадрах люди ходят, оборачиваются или управляют видеозаписью. Если у нас слишком много изображений одного класса, то мы рискуем обучить модель предвзято к этому конкретному классу. В этом случае при классификации изображения с ударом нейронная сеть всё равно может определить класс «Другие». Чтобы уменьшить эту предвзятость, можно удалить некоторые фотографии из каталога «Другие» и обучать модель на равном количестве изображений из каждой категории.
Для удобства присвоим изображениям в каталогах цифры от 1 до 190, так что первое изображение будет 1.jpg, второе 2.jpg и т.д.
Если мы будем обучать модель только на 600 фотографиях, сделанных в одной среде с теми же людьми, то не достигнем очень высокого уровня точности. Чтобы извлечь как можно больше пользы из наших данных, лучше сгенерировать несколько дополнительных выборок с помощью аугментации данных.
Аугментация данных
Аугментация данных — это техника, которая увеличивает количество точек данных путём синтеза новых точек из существующего набора. Обычно аугментацию используют для увеличения размера и разнообразия обучающего набора. Мы передаём исходные изображения в конвейер преобразований, которые создают новые изображения. Нельзя слишком агрессивно подходить к преобразованиям: из удара рукой должны генерироваться только другие удары рукой.
Допустимые преобразования — вращение, инвертирование цветов, размытие и др. Есть отличные инструменты с открытым исходным кодом для аугментации данных. На момент написания статьи на JavaScript было не слишком много вариантов, поэтому я использовал библиотеку, реализованную на Python — imgaug. В ней есть набор аугментеров, которые можно применять вероятностно.
Вот логика аугментации данных для этого эксперимента:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5), # horizontally flip 50% of all images # crop images by -5% to 10% of their height/width sometimes(iaa.CropAndPad( percent=(-0.05, 0.1), pad_mode=ia.ALL, pad_cval=(0, 255) )), sometimes(iaa.Affine( scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # scale images to 80-120% of their size, individually per axis translate_percent={"x": (-0.1, 0.1), "y": (-0.1, 0.1)}, # translate by -10 to +10 percent (per axis) rotate=(-5, 5), shear=(-5, 5), # shear by -5 to +5 degrees order=[0, 1], # use nearest neighbour or bilinear interpolation (fast) cval=(0, 255), # if mode is constant, use a cval between 0 and 255 mode=ia.ALL # use any of scikit-image's warping modes (see 2nd image from the top for examples) )), iaa.Grayscale(alpha=(0.0, 1.0)), iaa.Invert(0.05, per_channel=False), # invert color channels # execute 0 to 5 of the following (less important) augmenters per image # don't execute all of them, as that would often be way too strong iaa.SomeOf((0, 5), [ iaa.OneOf([ iaa.GaussianBlur((0, 2.0)), # blur images with a sigma between 0 and 2.0 iaa.AverageBlur(k=(2, 5)), # blur image using local means with kernel sizes between 2 and 5 iaa.MedianBlur(k=(3, 5)), # blur image using local medians with kernel sizes between 3 and 5 ]), iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)), # emboss images iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.01*255), per_channel=0.5), # add gaussian noise to images iaa.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value) iaa.AddToHueAndSaturation((-20, 20)), # change hue and saturation # either change the brightness of the whole image (sometimes # per channel) or change the brightness of subareas iaa.OneOf([ iaa.Multiply((0.9, 1.1), per_channel=0.5), iaa.FrequencyNoiseAlpha( exponent=(-2, 0), first=iaa.Multiply((0.9, 1.1), per_channel=True), second=iaa.ContrastNormalization((0.9, 1.1)) ) ]), iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5), # improve or worsen the contrast ], random_order=True ) ], random_order=True ) im = np.zeros((16, 56, 100, 3), dtype=np.uint8) for c in range(0, 16): im[c] = image for im in range(len(grid)): misc.imsave(aug_path + "/" + filename + "_" + str(im) + ".jpg", grid[im])В этом скрипте используется метод main с тремя циклами for — по одному для каждой категории изображений. В каждой итерации, в каждом из циклов, мы вызываем метод draw_single_sequential_images: первый аргумент — имя файла, второй — путь, третий — каталог, куда сохранять результат.
После этого мы считываем изображение с диска и применяем к нему ряд преобразований. Я задокументировал большинство преобразований в приведенном выше фрагменте кода, поэтому не будем повторяться.
Для каждого изображения создаётся 16 других картинок. Вот пример, как они выглядят:

Обратите внимание, что в приведённом выше скрипте мы масштабируем изображения до 100x56пикселей. Мы это делаем, чтобы уменьшить объём данных и, соответственно, количество вычислений, которые наша модель выполняет во время обучения и оценки.
Построение модели
Теперь построим модель для классификации!
Поскольку мы имеем дело с изображениями, то используем свёрточную нейросеть (CNN). Эта сетевая архитектура, как известно, подходит для распознавания изображений, обнаружения объектов и классификации.
Перенос обучения
На рисунке ниже показан популярная CNN VGG-16, используемая для классификации изображений.
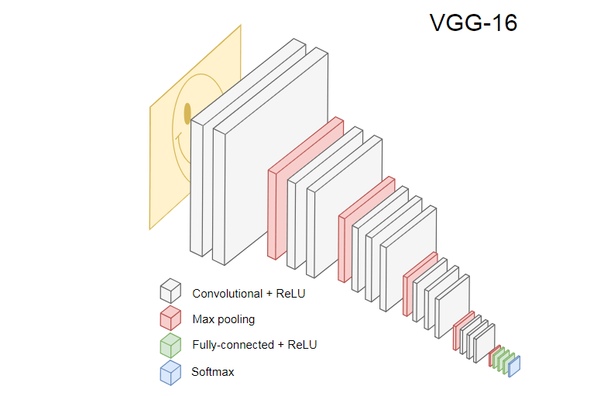
Нейросеть VGG-16 распознаёт 1000 классов изображений. У неё 16 слоёв (не считая слои пулинга и выходных данных). Такую многослойную сеть трудно обучить на практике. Для этого потребуется большой набор данных и много часов обучения.
Скрытые слои обученной CNN распознают различные элементы изображений из обучающего набора, начиная с краёв, переходя к более сложным элементам, таким как фигуры, отдельные объекты и так далее. Обученная CNN в стиле VGG-16 для распознавания большого набора изображений должна иметь скрытые слои, которые усвоили много признаков из обучающего набора. Такие признаки будут общими для большинства изображений и, соответственно, многократно использоваться в разных задачах.
Перенос обучения позволяет повторно использовать уже существующую и обученную сеть. Мы можем взять выходные данные из любого из слоёв существующей сети и передать их в качестве входных данных новой нейронной сети. Таким образом, обучая вновь созданную нейросеть, со временем её можно научить распознавать новые признаки более высокого уровня и корректно классифицировать изображения из классов, которых исходная модель никогда раньше не видела.
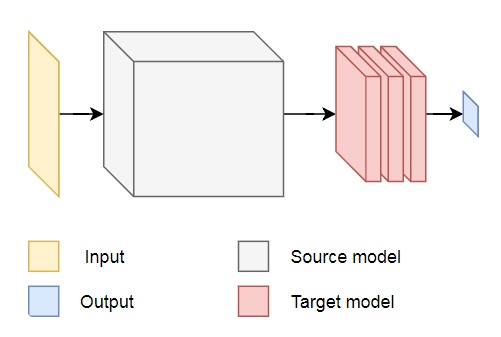
Для наших целей возьмём нейросеть MobileNet из пакета @tensorflow-models/mobilenet. MobileNet так же мощна, как и VGG-16, но она намного меньше, что ускоряет прямое распространение, то есть активацию сети (forward propagation), и уменьшает время загрузки в браузере. MobileNet обучалась на наборе данных для классификации изображений ILSVRC-2012-CLS.
При разработке модели с переносом обучения у нас есть варианты выбора по двум пунктам:
- Выдачу с какого слоя исходной модели использовать в качестве входных данных для целевой модели.
- Сколько слоёв из целевой модели мы собираемся обучать, если таковые имеются.
Первый момент весьма существенен. В зависимости от выбранного слоя, мы получим признаки на более низком или более высоком уровне абстракции в качестве входных данных для нашей нейронной сети.
Мы не собираемся обучать какие-то слои MobileNet. Выберем выходные данные из global_average_pooling2d_1 и передадим их в качестве входных данных нашей крошечной модели. Почему я выбрал именно этот слой? Эмпирически. Я сделал несколько тестов, и этот слой работает достаточно хорошо.
Определение модели
Первоначальная задача состояла в том, чтобы классифицировать изображение по трём классам: удары рукой, ногой и другие движения. Давайте сначала решим проблему поменьше: определим, есть в кадре удар рукой или нет. Эта типичная задача бинарной классификации. Для этой цели мы можем определить следующую модель:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });Такой код определяет простую модель, слой с 1024 юнитами и активацией ReLU, а также один выходной юнит, который проходит через функцию активации sigmoid. Последняя выдаёт число от 0 до 1, в зависимости от вероятности наличия удара рукой в данном кадре.
Почему я выбрал 1024 юнита для второго уровня и скорость обучения 1e-6? Ну, я попробовал несколько разных вариантов и увидел, что такие параметры работают лучше всего. «Метод тыка» кажется не лучшим подходом, но в значительной степени именно так работает настройка гиперпараметров в глубоком обучении — основываясь на своём понимании модели, мы используем интуицию для обновления ортогональных параметров и эмпирически проверяем, как работает модель.
Метод compile компилирует слои вместе, подготавливая модель для обучения и оценки. Здесь мы объявляем, что хотим использовать алгоритм оптимизации adam. Также объявляем, что будем вычислять потерю (loss) с перекрёстной энтропии, и указываем, что хотим оценить точность модели. Затем TensorFlow.js вычисляет точность по формуле:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)
Если переносить обучение с исходной модели MobileNet, то сначала нужно загрузить её. Поскольку нецелесообразно обучать нашу модель на более чем 3000 изображениях в браузере, мы применим Node.js и загрузим нейросеть из файла.
Скачать MobileNet можно здесь. В каталоге лежит файл model.json, который содержит архитектуру модели — слои, активации и т.д. Остальные файлы содержат параметры модели. Вы можете загрузить модель из файла с помощью такого кода:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };Обратите внимание, что в методе loadModel мы возвращаем функцию, которая в качестве входных данных принимает одномерный тензор и возвращает mn.infer(input, Layer). Метод infer принимает в качестве аргументов тензор и слой. Слой определяет, из какого скрытого слоя мы хотим получить выходные данные. Если вы откроете model.json и поищете global_average_pooling2d_1, то найдёте такое название у одного из слоёв.
Теперь нужно создать набор данных для обучения модели. Для этого мы должны пропустить все изображения через метод infer в MobileNet и присвоить им метки: 1 для изображений с ударами и 0для изображений без удара:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;В приведённом коде мы сначала считываем файлы в каталогах с ударами и без. Затем определяем одномерный тензор, содержащий выходные метки. Если у нас n изображений с ударами и m других изображений, в тензоре будет n элементов со значением 1 и m элементов со значением 0.
В xs мы складываем результаты вызова метода infer для отдельных изображений. Обратите внимание, что для каждого изображения мы вызываем метод readInput. Вот его реализация:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };readInput сначала вызывает readImage функции, а после этого делегирует её вызов imageToInput. Функция readImage считывает изображение с диска и после этого декодирует jpg из буфера с помощью пакета jpeg-js. В imageToInput мы преобразуем изображение в трёхмерный тензор.
В итоге, для каждого i от 0 до TotalImages должно быть ys[i] равно 1, если xs[i] соответствует изображению с ударом, и 0 в противном случае.
Обучение модели
Теперь модель готова к обучению! Вызываем метод fit:
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });Приведённый выше код вызывает fit с тремя аргументами: xs, ys и объектом конфигурации. В объекте конфигурации мы установили, сколько эпох будет обучаться модель, размер пакета и обратный вызов, который TensorFlow.js будет генерировать после обработки каждого пакета.
Размер пакета определяет xs и ys для обучения модели за одну эпоху. Для каждой эпохи TensorFlow.js выберет подмножество xs и соответствующие элементы из ys, выполнит прямое распространение, получит выходные данные слоя с активацией sigmoid, а после этого на основе потери выполнит оптимизацию с использованием алгоритма adam.
После запуска обучающего скрипта вы увидите результат, похожий на приведённый ниже:
Cost: 0.84212, accuracy: 1.00000 eta=0.3 >---------- acc=1.00 loss=0.84 Cost: 0.79740, accuracy: 1.00000 eta=0.2 =>--------- acc=1.00 loss=0.80 Cost: 0.81533, accuracy: 1.00000 eta=0.2 ==>-------- acc=1.00 loss=0.82 Cost: 0.64303, accuracy: 0.50000 eta=0.2 ===>------- acc=0.50 loss=0.64 Cost: 0.51377, accuracy: 0.00000 eta=0.2 ====>------ acc=0.00 loss=0.51 Cost: 0.46473, accuracy: 0.50000 eta=0.1 =====>----- acc=0.50 loss=0.46 Cost: 0.50872, accuracy: 0.00000 eta=0.1 ======>---- acc=0.00 loss=0.51 Cost: 0.62556, accuracy: 1.00000 eta=0.1 =======>--- acc=1.00 loss=0.63 Cost: 0.65133, accuracy: 0.50000 eta=0.1 ========>-- acc=0.50 loss=0.65 Cost: 0.63824, accuracy: 0.50000 eta=0.0 ==========> 293ms 14675us/step - acc=0.60 loss=0.65 Epoch 3 / 50 Cost: 0.44661, accuracy: 1.00000 eta=0.3 >---------- acc=1.00 loss=0.45 Cost: 0.78060, accuracy: 1.00000 eta=0.3 =>--------- acc=1.00 loss=0.78 Cost: 0.79208, accuracy: 1.00000 eta=0.3 ==>-------- acc=1.00 loss=0.79 Cost: 0.49072, accuracy: 0.50000 eta=0.2 ===>------- acc=0.50 loss=0.49 Cost: 0.62232, accuracy: 1.00000 eta=0.2 ====>------ acc=1.00 loss=0.62 Cost: 0.82899, accuracy: 1.00000 eta=0.2 =====>----- acc=1.00 loss=0.83 Cost: 0.67629, accuracy: 0.50000 eta=0.1 ======>---- acc=0.50 loss=0.68 Cost: 0.62621, accuracy: 0.50000 eta=0.1 =======>--- acc=0.50 loss=0.63 Cost: 0.46077, accuracy: 1.00000 eta=0.1 ========>-- acc=1.00 loss=0.46 Cost: 0.62076, accuracy: 1.00000 eta=0.0 ==========> 304ms 15221us/step - acc=0.85 loss=0.63
Обратите внимание, как со временем увеличивается точность, а потеря уменьшается.
На моём наборе данных модель после обучения показала точность 92%. Имейте в виду, что точность может быть не очень высокой из-за небольшого набора обучающих данных.
Запуск модели в браузере
В предыдущем разделе мы обучили модель бинарной классификации. Теперь запустим её в браузере и подключим к игре MK.js!
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });В приведённом коде несколько деклараций:
videoсодержит ссылку на элементHTML5 videoна страницеLayerсодержит имя слоя из MobileNet, из которого мы хотим получить выходные данные и передать их в качестве входных данных для нашей моделиmobilenetInfer— функция, которая принимает экземпляр MobileNet и возвращает другую функцию. Возвращаемая функция принимает входные данные и возвращает соответствующие выходные данные из указанного слоя MobileNetcanvasуказывает на элементHTML5 canvas, который мы будем использовать для извлечения кадров из видеоscale— ещё одинcanvas, который используется для масштабирования отдельных кадров
После этого мы получаем видеопоток с камеры пользователя и устанавливаем его в качестве источника для элемента video.
Следующий шаг — реализовать фильтр оттенков серого, который принимает canvas и преобразует его содержимое:
const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };В качестве следующего шага свяжем модель с MK.js:
let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });В приведённом коде сначала загружаем модель, которую обучали выше, а после этого загружаем MobileNet. Передаём MobileNet в метод mobilenetInfer, чтобы получить путь для вычисления вывода из скрытого слоя сети. После этого вызываем метод startInterval с двумя сетями в качестве аргументов.
const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };Самое интересное начинается в методе startInterval! Во-первых, мы запускаем интервал, где каждые 100ms вызываем анонимную функцию. В ней сначала поверх canvas рендерится видео c текущим кадром. Потом уменьшаем размер кадра до 100x56 и применяем к нему фильтр оттенков серого.
Следующим шагом передаём кадр в MobileNet, получаем выходные данные из желаемого скрытого слоя и передаём их в качестве входных данных в метод predict нашей модели. Тот возвращает тензор с одним элементом. С помощью dataSync получаем значение из тензора и присваиваем его константе punching.
Наконец, проверяем: если вероятность удара рукой превышает 0.4, то вызываем метод onPunchглобального объекта Detect. MK.js предоставляет глобальный объект с тремя методами: onKick, onPunch и onStand, которые мы можем использовать для управления одним из персонажей.
Готово! Вот результат!
Распознавание ударов ногой и рукой с N-ричной классификацией
В следующем разделе сделаем более умную модель: нейросеть, которая распознаёт удары руками, ногами и другие изображения. На этот раз начнём с подготовки обучающего набора:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;Как и раньше, сначала читаем каталоги с изображениями ударов рукой, ногой и другие изображения. После этого, в отличие от прошлого раза, формируем ожидаемый результат в виде двумерного тензора, а не одномерного. Если у нас n картинок с ударом рукой, m картинок с ударом ногой и k других изображений, то в тензоре ys будет n элементов со значением [1, 0, 0], m элементов со значением [0, 1, 0] и k элементов со значением [0, 0, 1].
Вектор из n элементов, в котором n - 1 элементов со значением 0 и один элемент со значением 1, мы называем унитарным вектором (one-hot vector).
После этого формируем входной тензор xs, складывая выход каждого изображения из MobileNet.
Тут придётся обновить определение модели:
const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });Единственными двумя отличиями от предыдущей модели являются:
- Количество юнитов в выходном слое
- Активации в выходном слое
В выходном слое три юнита, потому что у нас три разных категории изображений:
- Удар рукой
- Удар ногой
- Другие
На этих трёх юнитах вызывается активация softmax, которая преобразовывает их параметры к тензору с тремя значениями. Почему три юнита для выходного слоя? Каждое из трёх значений для трёх классов можно представить двумя битами: 00, 01, 10. Сумма значений тензора, созданного softmax, равна 1, то есть мы никогда не получим 00, поэтому не сможем классифицировать изображения одного из классов.
После обучения модель на протяжении 500 эпох я достиг точности около 92%! Это неплохо, но не забывайте, что обучение велось на небольшом наборе данных.
Следующий шаг — запустить модель в браузере! Поскольку логика очень похожа на запуск модели для двоичной классификации, взглянем на последний шаг, где выбирается действие на основе выходного результата модели:
const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();Сначала вызываем MobileNet с уменьшенным кадром в оттенках серого, потом передаём результат нашей обученной модели. Модель возвращает одномерный тензор, который мы преобразуем в Float32Array с dataSync. На следующем шаге используем Array.from для приведения типизированного массива к массиву JavaScript. Затем извлекаем вероятности того, что на кадре присутствует удар рукой, удар ногой или ничего.
Если вероятность третьего результата превышает 0.4, возвращаемся. В противном случае, если вероятность удара ногой выше 0.32, отправляем в MK.js команду удара ногой. Если вероятность удара рукой выше 0.32 и выше вероятности удара ногой, то отправляем действие удара рукой.
В целом это всё! Результат показан ниже:
Распознавание действий
Если собрать большой и разнообразный набор данных о людях, которые бьют руками и ногами, то можно построить модель, которая отлично работает на отдельных кадрах. Но достаточно ли этого? Что если мы хотим пойти ещё дальше и выделить два разных типа ударов ногой: с разворота и со спины (back kick).
Как видно на кадрах внизу, в определённый момент времени с определённого угла оба удара выглядят одинаково:


Но если посмотреть на исполнение, то движения совсем другие:
Как же обучить нейросеть анализировать последовательность кадров, а не один фрейм?
Для этой цели мы можем исследовать другой класс нейронных сетей, называемый рекуррентными нейронными сетями (RNN). Например, RNN отлично подходят для работы с временными рядами:
- Обработка естественного языка (NLP), где каждое слово зависит от предыдущих и последующих
- Прогнозирование следующей страницы на основе истории посещённых страниц
- Распознавание действия в последовательности кадров
Реализация такой модели выходит за рамки этой статьи, но давайте рассмотрим пример архитектуры, чтобы получить представление о том, как всё это будет работать вместе.
Мощь RNN
На диаграмме ниже показана модель распознавания действий:
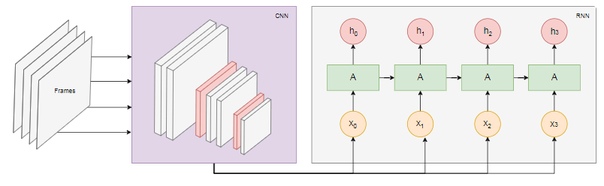
Берём последние n кадров из видео и передаём их CNN. Выход CNN для каждого кадра передаём в качестве входных данных RNN. Рекуррентная нейросеть определит зависимости между отдельными кадрами и распознает, какому действию они соответствуют.
Вывод
В этой статье мы разработали модель классификации изображений. Для этой цели мы собрали набор данных: извлекли кадры видео и вручную разделили их по трём категориям. Затем осуществили аугментацию данных, добавив изображения с помощью imgaug.
После этого мы объяснили, что такое перенос обучения, и использовали в своих целях обученную модель MobileNet из пакета @tensorflow-models/mobilenet. Мы загрузили MobileNet из файла в процессе Node.js и обучили дополнительный плотный слой, куда данные подавались из скрытого слоя MobileNet. После обучения мы достигли точности более 90%!
Для использования этой модели в браузере мы загрузили её вместе с MobileNet и запустили категоризацию кадров с веб-камеры пользователя каждые 100 мс. Мы связали модель с игрой MK.js и использовали выходные данные модели для управления одним из персонажей.
Наконец, мы рассмотрели, как улучшить модель, объединив ее с рекуррентной нейросетью для распознавания действий.
Надеюсь, вам понравился этот крошечный проект не меньше, чем мне! ?
Источник: m.vk.com