Как запустить свой эффективный ИИ-стартап?
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-10-06 14:37


Вы хотите начать свой собственный стартап, используя технологии искусственного интеллекта (ИИ). Какие процессы вам нужно учитывать, как необходимо проводить подготовку и обработку данных для обучения нейронной сети и на что обратить внимание, когда дело дойдет до набора команды и тестирования?
В данной статье мы попытаемся в доступной форме ответить на все вопросы, взяв за основу отрывок из книги «Охватывая силу искусственного интеллекта» (ориг. Embracing the Power of AI - https://www.globant.com/our-books) (далее – книга).
Авторы книги: Хавьер Миньондо (Javier Minhondo), Хуан Хосе Лопес Мерфи (Juan Jos? L?pez Murphy), Халдо Спонтон (Haldo Spont?n), Мартин Мигоя (Mart?n Migoya) и Гвиберт Энглебьен (Guibert Englebienne).
Процесс
Решающее значение имеет как понимание потребностей бизнеса, так и понимание источников исходных данных. На чем сосредоточиться для принятия верного решения: на потребностях пользователей или на используемой технологии? В книге описано, что успешным является такой продукт с использованием ИИ, который создан для того, чтобы помочь людям получить доступ к информации или к непосредственной обработке такой информации, для принятия верных решений.
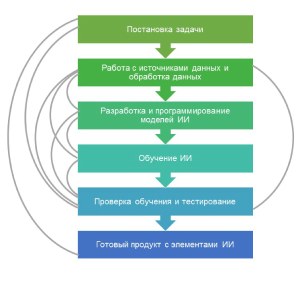
1. Определение цели и постановка задачи
Первым и самым важным вопросом для команды разработчиков является правильная постановка задачи, решение которой средствами ИИ и будет по сути являться потребностью бизнеса. В результате решения данной задачи, будет получен конечный ожидаемый результат, причем результат должен быть проверен, чтобы гарантировать максимальную точность.
2. Сбор и подготовка исходных данных
На следующем этапе необходимо определиться с источниками данных – насколько они достоверны, каковы пути интеграции этих данных в разрабатываемую систему и как команда разработчиков может использовать их для достижения бизнес-целей. Проще говоря, при работе с данными, их необходимо обработать максимально эффективно, не взирая на сложные преобразования и низкую скорость обработки, чтобы получить на выходе правильный результат.
Качество первичных данных не имеет значения, главное правильно подготовить обучающую выборку. Если принцип формирования выборки обучающих данных выбран корректно, то можно масштабировать задачу, используя более полный набор данных.
Резюмируя сказанное можно подготовить перечень вопросов:
• Какие источники данных доступны?
• Что собой представляют эти данные?
• Мы имеем достаточный объем данных?
• Откуда берутся, как собираются и обрабатываются данные?
Также есть еще ряд вопросов, которые также стоит обязательно задать в дальнейшем, т.к. если этого не сделать, то данный факт может существенно осложнить развитие проекта.
Дополнительные вопросы:
• Является ли выборка данных, которуе мы используем для обучения модели, репрезентативной?
• Существуют ли какие-либо «подводные камни», которые мы не учли?
• Содержатся ли в выборке персональные данные и имеем ли мы право их использовать?
Следующий шаг, который необходимо сделать до создания непосредственно самого алгоритма, - это обработка (подготовка, кластеризация) и нормировка данных. Этот шаг нужен для того, чтобы подготовить выборку для правильной интерпретации математической моделью ИИ.
К примеру, над числовой выборкой могут проведены такие операции: возведение переменных в степень или умножение на константу, что позволит линейным моделям моделировать нелинейные зависимости, для выявления общих закономерностей. Иногда необходимо выполнить преобразование Фурье для правильной интерпретации частотных характеристик при обработке звука или использования SIFT-алгоритма при решении задачи сопоставления изображений.
Нужно понимать, что нормирование и подготовка данных имеет решающее значение для традиционного машинного обучения (machine learning). Этот процесс существенно влияет на выбор архитектуры используемых нейронных сетей, в особенности при так называемом глубоком обучении (deep learning), когда необходимо правильно определить количество скрытых слоев в нейронной сети и количество искусственных нейронов в них. Одно из главных достоинств многослойных нейронных сетей - это моделирование работы некоей сложной математической зависимости.
3. Разработка модели ИИ, программирование и обучение нейронной сети
Теперь когда у нас есть четкая бизнес-цель, верный набор исходных данных для выборки и сама выборка, мы можем начать разработку нейросетевых моделей, программирование дальнейшее обучение нейронной сети.
Новый этап будет включать в себя выбор алгоритма обучения, применение алгоритма обучения, его визуализацию и оценку качества обучения.
Обучение нейронной сети можно сравнить с обучением собаки какой-либо команде, проделанное миллионы раз. Как бы тривиально это не звучало, но процесс обучения довольно прост. У вас есть обучающая выборка, содержащая исходные данные и конечные результаты.
Вы подаете на вход нейронной сети исходные данные и на выходе получаете некий результат обработки нейронной сетью. Далее вы сравниваете полученный результат, с конечным результатом из вышей выборки, указывая степень сходства.
Процесс может показаться простым, но его эффективное и правильное выполнение на больших выборках данных далеко не так просто обеспечить. Необходимо правильно подобрать алгоритм обучения нейронной сети, иначе создаваемый искусственный интеллект может научиться неправильно интерпретировать входящий поток данных, что приведет к нежелательным ошибкам.
Один из таких случаев произошел с компанией Google, когда в программное обеспечение для распознавания лиц было загружено фото афро-американской семьи, а программа пометила изображение как семейство обезьян. Связан ли результат работы ИИ с расизмом в данном случае?
В итоге получается, что конечное поведение создаваемого ИИ вытекает из набора исходных данных, процедур их обработки и нормировки и используемого алгоритма обучения и критерия проверки достоверности результат обучения.
Именно на данном этапе совокупность нескольких подходов позволяет правильно обучить нейронную сеть так, чтобы взаимодействия с разработанной математической моделью было как можно более эффективным.
Одним из определяющих решений на этом этапе будет являться то какой процент объема обучающей выборки будет целиком использоваться для обучения нейронной сети, а какой будет предъявлен нейронной сети позднее, для последующего тестирования.
4. Тестирование и проверка полученных результатов
Выборка для тестирования также должна быть репрезентативной, как и набор данных для обучения.
Раньше эмпирическое правило заключалось в том, чтобы использовать исходную обучающую выборку в пропорции 80 на 20, из которых большая часть данных используется для обучения нейронной сети. Некоторые современные подходы к глубинному обучению (deep learning) предполагают использовать до 99 % данных для обучения, а 1% - для тестирования.
Теперь остается определиться с составом команды и ролью каждого участника. Группа разработчиков должна взять на себя работу по обучению нейронной сети, в частности разработку и проверку алгоритмов машинного обучения (machine learning).
Одна часть команды будет проводить обучение, а другая тестирование алгоритма, проверяя то, насколько точно качественно ИИ решает полученную задачу.
Одной из распространенных ошибок, с которой сталкиваются многие команды разработчиков, является использование одного и того же набора данных и для обучения и тестирования работы нейронной сети.
Это обычно приводит к тому, что ИИ покажет очень хорошие результаты при тестировании, т.к. данные тестирования были предъявлены еще на этапе обучения.
У команды разработчиков, которая попадет в эту ловушку, возникнет соблазн сказать, что в результате проведенного машинного обучения, нейронная сеть дает верный результат на выходе.
Наконец, команда разработчиков должна выполнить оценку работы нейросетевой модели с точки зрения чувствительности и себестоимости.
Не существует идеальных моделей, но не все ошибки одинаковы сами по себе.
Модель может выдавать на выходе так называемый ложноположительный или ложноотрицательный результат. Здесь, как и в медицине, стоит оценить какой диагноз наиболее безопасен для пациента. Безусловно – ложноположительный результат лучше, т.к. дает возможность немного перестраховаться при принятии решения. Например, в случае решения задачи распознавания террористов в аэропорту. Лишняя бдительность не помешает, но не стоит доходить до крайностей, обучив ИИ так, что он определит в качестве потенциальных террористов всех людей в аэропорту без исключения.
В случае решения задач в сфере розничной торговли, чрезмерное прогнозирование может способствовать росту затрат оборотного капитала, в то время как недооценка может привести к более существенным расходам, за счет резкого снижения продаж клиента.
Принятие решения о том, как правильно обучить нейронную сеть для решения конкретной задачи, всегда является компромиссным моментом.
Как ответить на вопрос, сколько необходимо провести циклов обучения? Является ли работа ИИ просто запоминанием массива данных и их извлечением или приоритетом будет выявление неких закономерностей для данных в этом массиве?
Равновесие между переобучением нейронной сети (запоминанием) и обобщением - еще одна сложная наука.
Базовая схема этой концепции для решения задач классификации приведена на рисунке ниже.
На протяжении всего процесса обучения основная проблема зачастую остается, как бы скрытой, пропадает из поля видимости. Например, как измерить успех, стоимость, предпочтение? Согласуется ли эта мера с требованиями бизнеса? Это технически полезно? Зачастую требуется сразу ответить на эти вопросы.
Все наборы исходных данных имеют свои слабые стороны и подводные камни, и не все они математически полезны для обучения! Как только команда разработчиков будет уверена в правильном решении задачи, она может работать над преобразованием результатов работы нейронной сети в идеи, элементы действий, прогнозы или просто использовать их, как результат обработки данных. Схема обобщенной концепции представлена ниже.
Только удостоверившись в том, что обученная нейронная сеть, готовое программное приложение или система действительно может работать в производстве, масштабироваться и способна контролировать сложные процессы, можно считать работу завершенной. Согласитесь, достижение такого результата требует серьезных инженерных навыков. Поэтому предлагаем усовершенствовать нашу схему, добавив обратные связи между этапами, что сделает схему универсальной.
Придерживаясь данной, схемы можно запустить любой ИИ-стартап с нуля, было бы желание.
Источник: www.globant.com