Простая реализация плотно Соединенных Сверточных сетей в PyTorch
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-09-07 19:00

В этом посте я постараюсь объяснить осуществлении плотно соединены Сверточных сетей с использованием PyTorch библиотека. Плотные сети являются относительно недавней реализацией Сверточных нейронных сетей, которые расширяют идею, предложенную для остаточных сетей, которые стали стандартной реализацией для извлечения признаков на данных изображения.
Подобно остаточным сетям, которые добавляют соединение из предыдущего слоя, плотные сети добавляют соединения ко всем предыдущим слоям, чтобы создать плотный блок. Проблема, которую решали остаточные сети, была проблемой исчезающего градиента, которая была вызвана многими слоями сети. Это помогло создать более крупные и эффективные сети и снизить частоту ошибок при выполнении задач классификации в ImageNet.
Таким образом, идея плотно Соединенных сетей заключается в том, что каждый слой связан со всеми его предыдущими слоями и последующими, таким образом образуя плотный блок. Авторы статьи сообщили, что их реализация выполнена лучше, чем Предыдущее состояние техники по классификации на ImageNet, которое кажется убедительным.
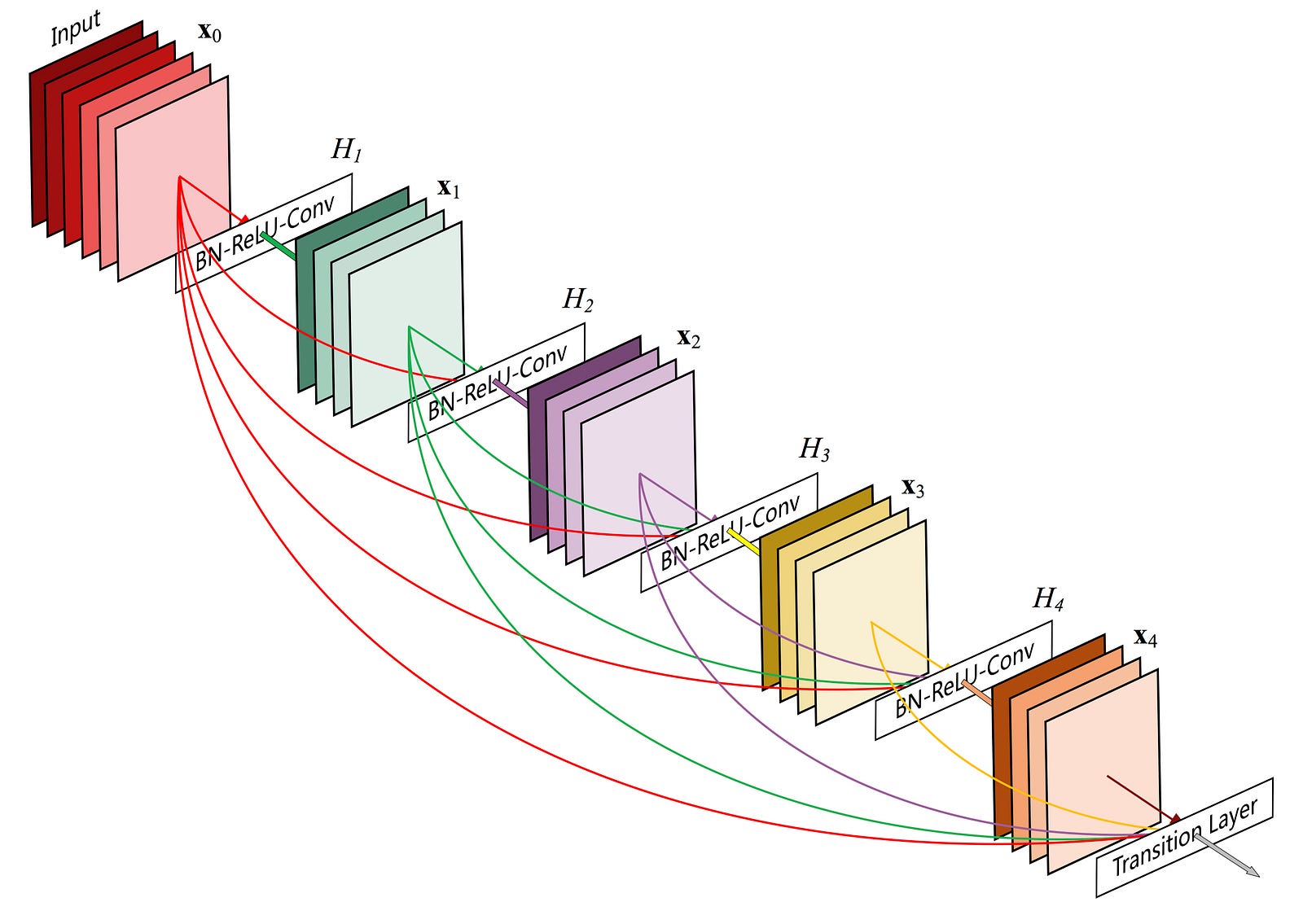
5-слойный плотный блок. Изображение взято из бумаги плотно соединены Сверточных сетей.
Реализация
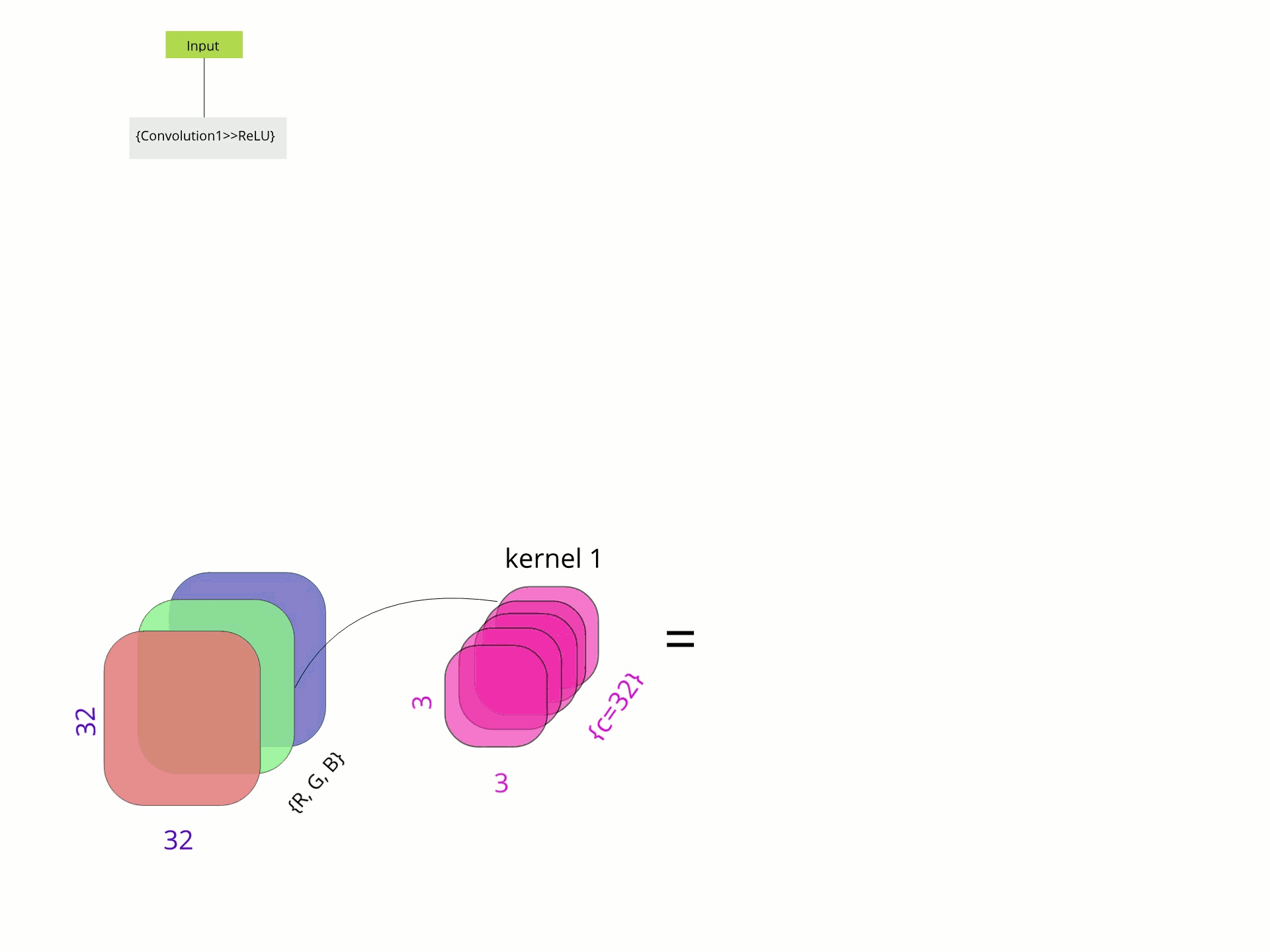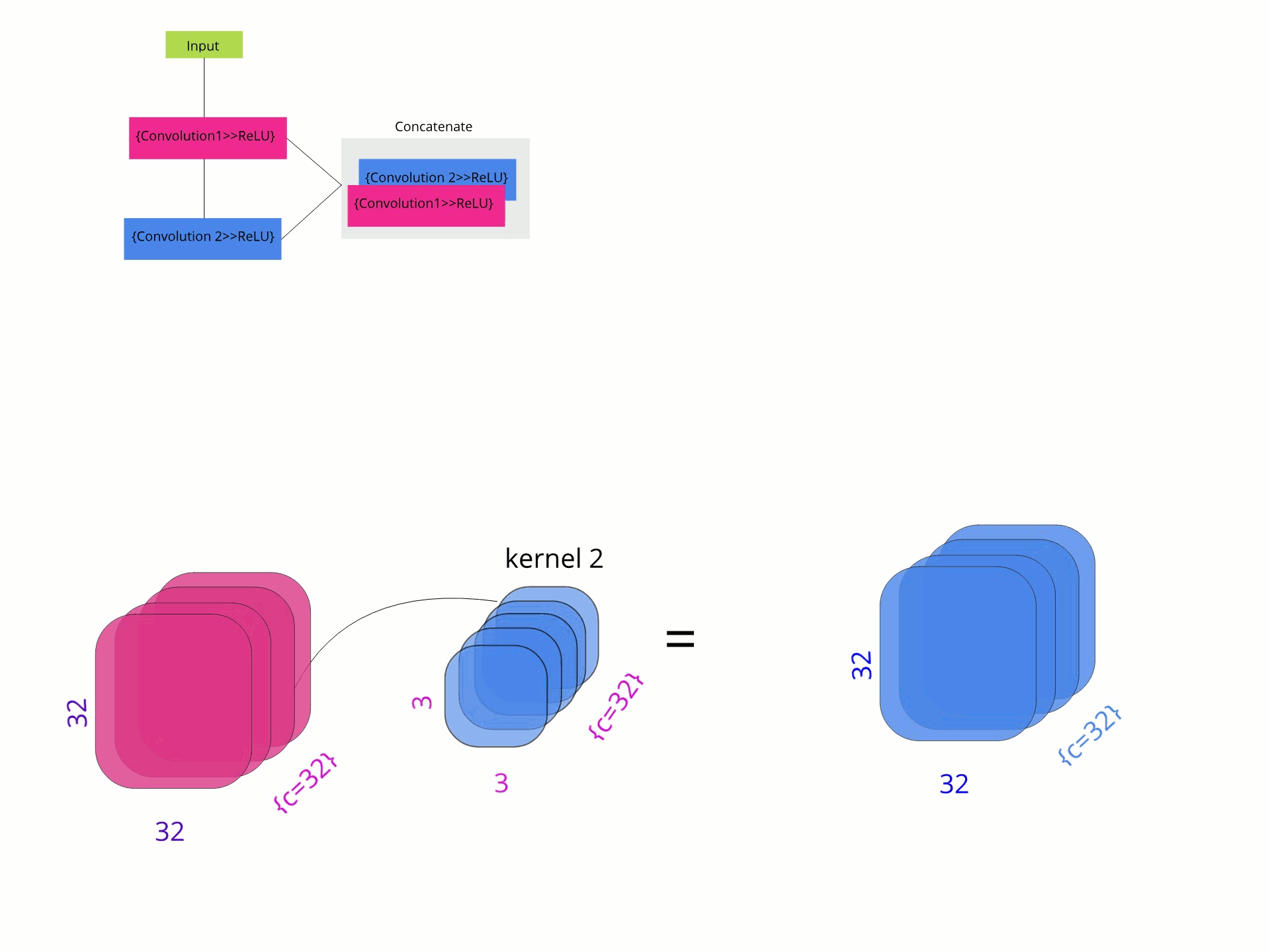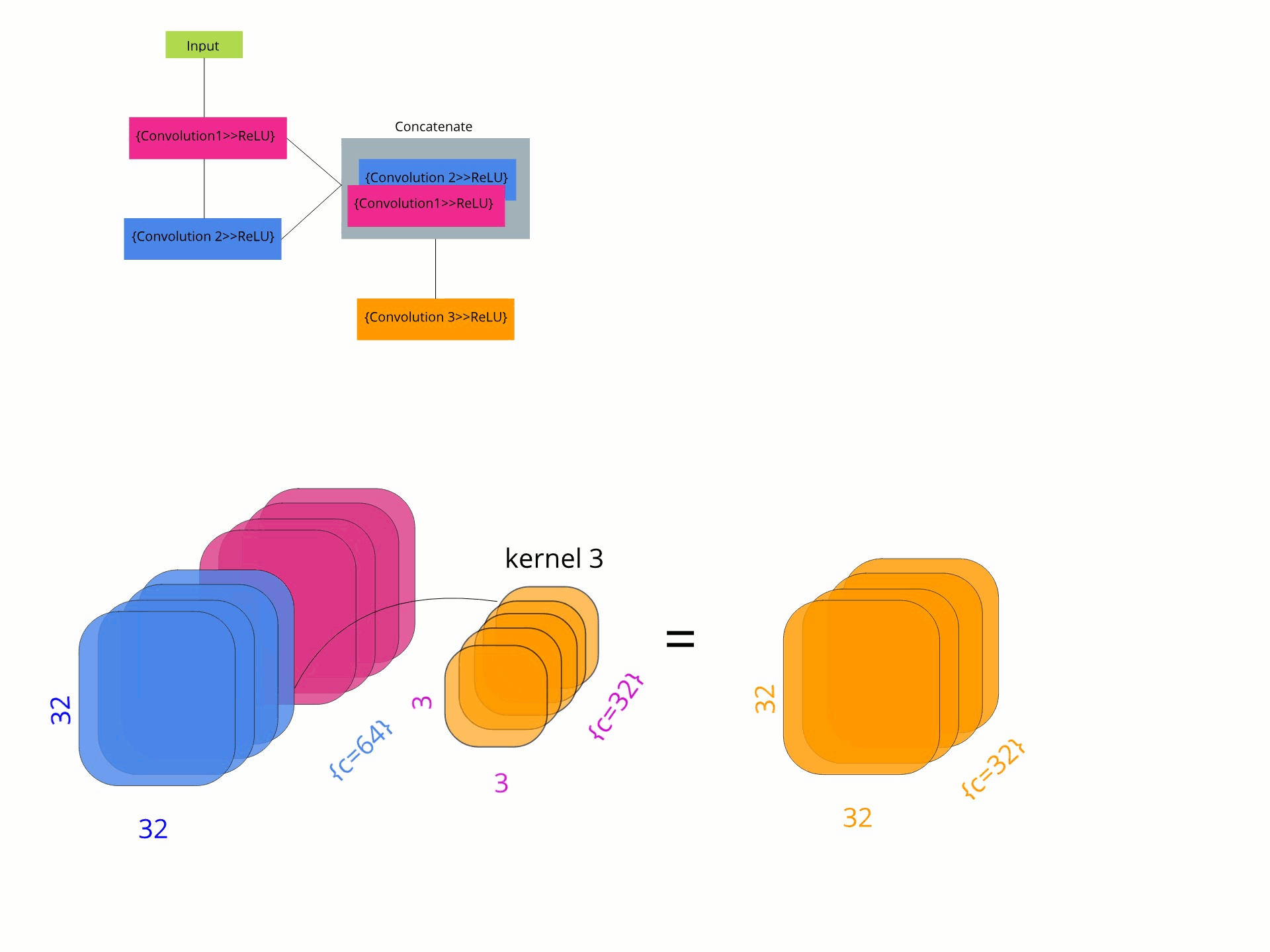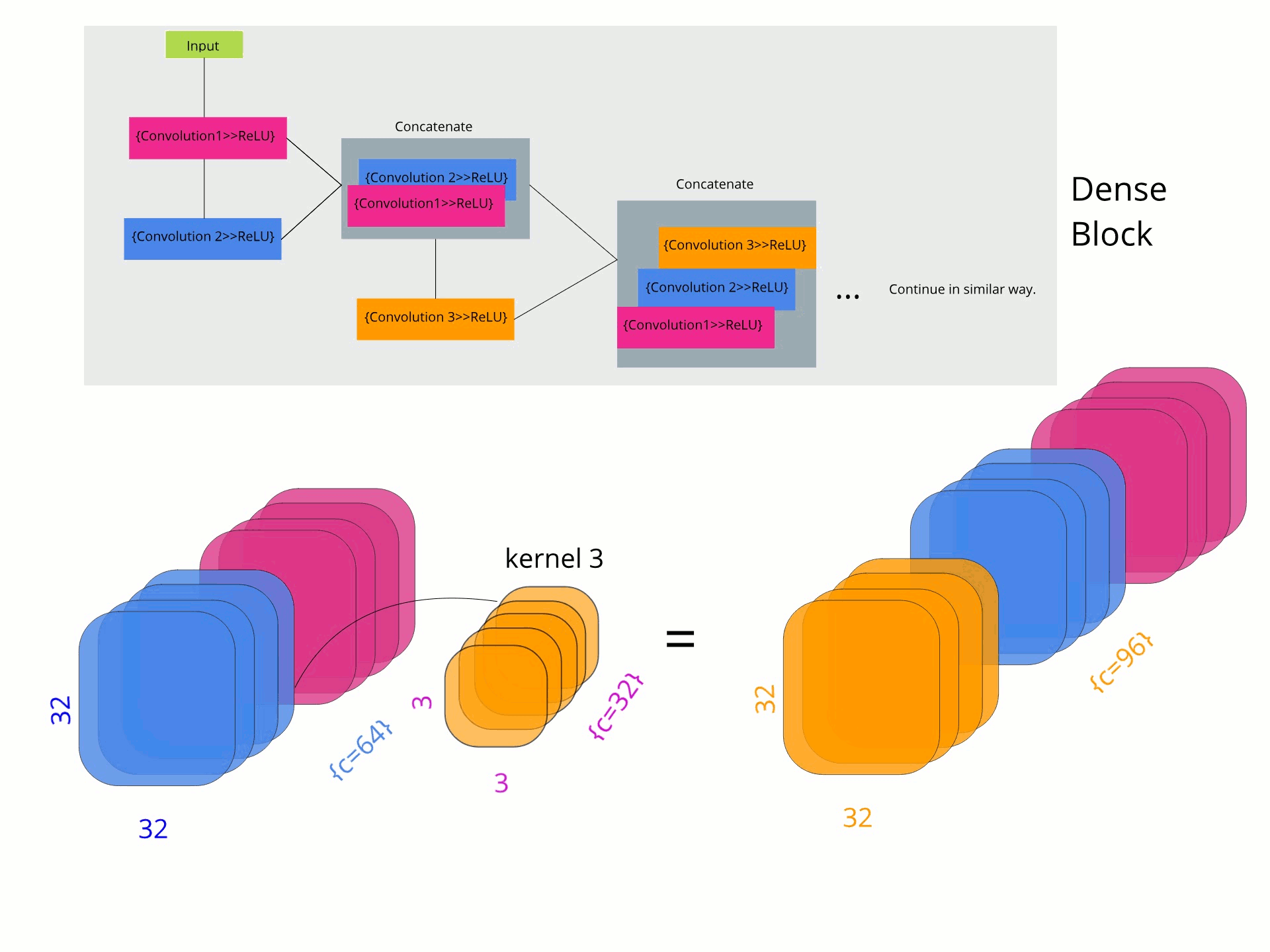
Поэтому, чтобы разбить эту реализацию на более мелкие части, сначала я собираюсь построить плотный блок с 5 слоями, используя PyTorch. Чтобы иметь визуальное представление кода, я создал следующий график.
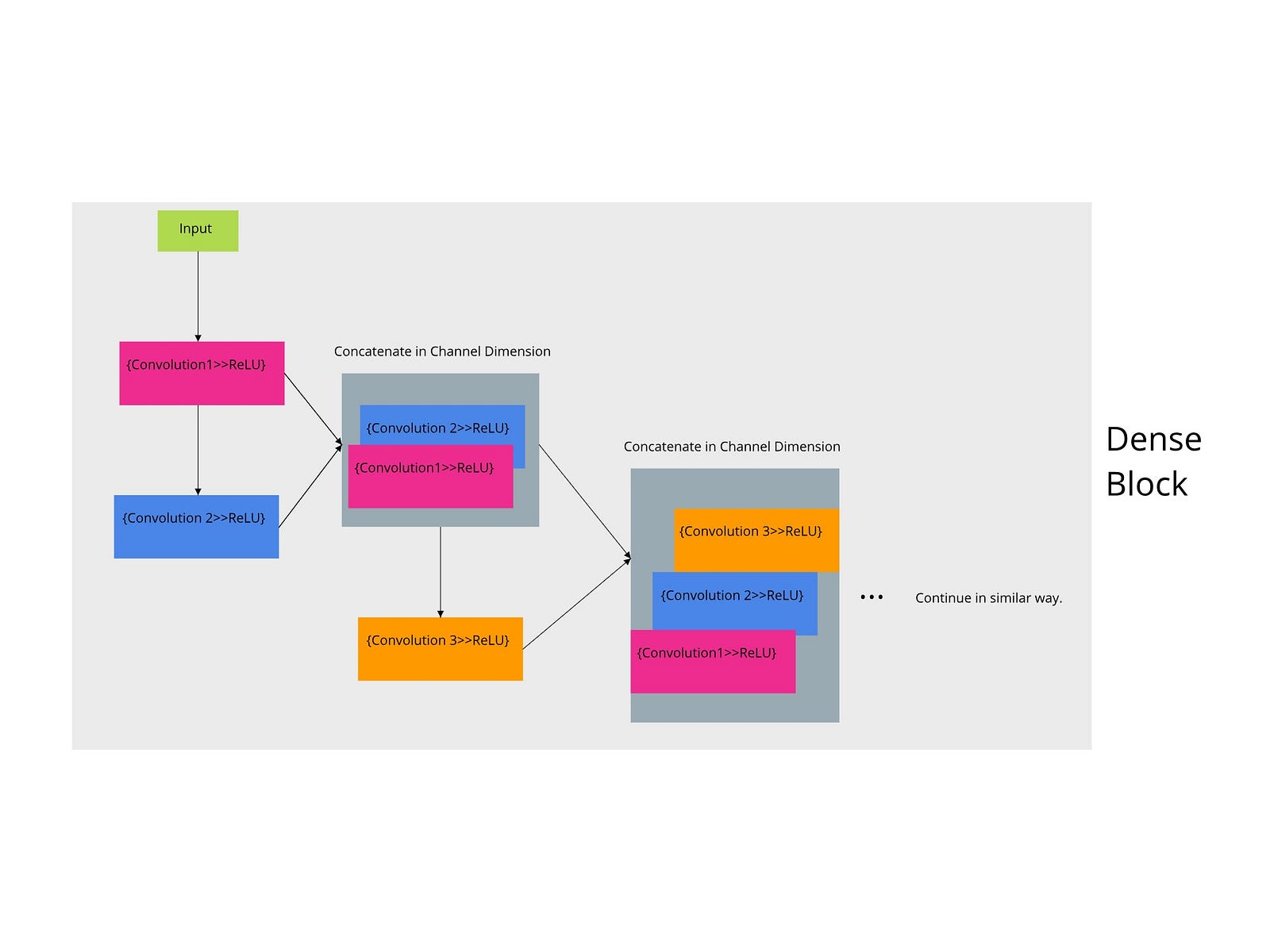
Плотная структурная схема.
Код
class Dense_Block(nn.Module): def __init__(self, in_channels): super(Dense_Block, self).__init__() self.relu = nn.ReLU(inplace = True) self.bn = nn.BatchNorm2d(num_channels = in_channels) self.conv1 = nn.Conv2d(in_channels = in_channels, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv2 = nn.Conv2d(in_channels = 32, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv3 = nn.Conv2d(in_channels = 64, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv4 = nn.Conv2d(in_channels = 96, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv5 = nn.Conv2d(in_channels = 128, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) def forward(self, x): bn = self.bn(x) conv1 = self.relu(self.conv1(bn)) conv2 = self.relu(self.conv2(conv1)) # Concatenate in channel dimension c2_dense = self.relu(torch.cat([conv1, conv2], 1)) conv3 = self.relu(self.conv3(c2_dense)) c3_dense = self.relu(torch.cat([conv1, conv2, conv3], 1)) conv4 = self.relu(self.conv4(c3_dense)) c4_dense = self.relu(torch.cat([conv1, conv2, conv3, conv4], 1)) conv5 = self.relu(self.conv5(c4_dense)) c5_dense = self.relu(torch.cat([conv1, conv2, conv3, conv4, conv5], 1)) return c5_denseКак вы можете видеть, каждый раз, когда происходит операция свертки предыдущего слоя, за ней следует конкатенация тензоров. Это позволено по мере того как размеры канала, высота и ширина входного сигнала остаются этими же после свертки с размером 3x3 и прокладкой ядра 1.
Авторы заявляют, что таким образом произведено особенность карты более разнообразными и, как правило, богаче моделей. Кроме того, другим преимуществом будет лучший информационный поток во время обучения.
Вы можете посмотреть полную презентацию этого документа на YouTube по следующим ссылка.
Как-то информативное представление GIF
Я сделал этот GIF, используя Gravit и Gimp, и я считаю, что это представление о том, что делают сетевые операции.
Построение всего класса сети
Теперь, используя приведенную выше реализацию плотного блока, я собираюсь реализовать плотную сеть с 3 плотными блоками и 3 переходными слоями. В переходных слоях я использую среднюю операцию объединения, которая уменьшает размер его входных данных.
На код
class Dense_Block(nn.Module): def __init__(self, in_channels):super(Dense_Block, self).__init__() self.relu = nn.ReLU(inplace = True) self.bn = nn.BatchNorm2d(num_channels = in_channels) self.conv1 = nn.Conv2d(in_channels = in_channels, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv2 = nn.Conv2d(in_channels = 32, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv3 = nn.Conv2d(in_channels = 64, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv4 = nn.Conv2d(in_channels = 96, out_channels = 32, kernel_size = 3, stride = 1, padding = 1) self.conv5 = nn.Conv2d(in_channels = 128, out_channels = 32, kernel_size = 3, stride = 1, padding = 1)def forward(self, x): bn = self.bn(x) conv1 = self.relu(self.conv1(bn)) conv2 = self.relu(self.conv2(conv1)) # Concatenate in channel dimension c2_dense = self.relu(torch.cat([conv1, conv2], 1))conv3 = self.relu(self.conv3(c2_dense)) c3_dense = self.relu(torch.cat([conv1, conv2, conv3], 1)) conv4 = self.relu(self.conv4(c3_dense)) c4_dense = self.relu(torch.cat([conv1, conv2, conv3, conv4], 1)) conv5 = self.relu(self.conv5(c4_dense)) c5_dense = self.relu(torch.cat([conv1, conv2, conv3, conv4, conv5], 1)) return c5_denseкласс Transition_Layer (nn.Модуль): деф __инит__(самостоятельная, in_channels, out_channels): супер(Transition_Layer, самовыдвижение).__инит__() самостоятельно.relu = nn.Релуи(на месте = истина) самостоятельно.БН = НН.BatchNorm2d(num_features = out_channels) самостоятельно.conv = nn.Conv2d(in_channels = in_channels, out_channels = out_channels, kernel_size = 1, смещение = ложь) самостоятельно.avg_pool = nn.AvgPool2d (kernel_size = 2, stride = 2, padding = 0
деф вперед(я, х): БН = собственн.Б.(самовыдвижение.релуи(самовыдвижение.сопуа(х))) из = себя.avg_pool(БН) возвращения из
класс DenseNet (nn.Модуль): деф __инит__(самостоятельная, nr_classes): супер(DenseNet, самовыдвижение).__инит__() самостоятельно.lowconv = nn.Conv2d(in_channels = 3, out_channels = 64, kernel_size = 7, отступ = 3, уклон = ложь) самостоятельно.relu = nn.Релуи() # сделать плотные блоки самостоятельно.denseblock1 = self._make_dense_block(Dense_Block, 64) самостоятельно.denseblock2 = self._make_dense_block(Dense_Block, 128) самостоятельно.denseblock3 = self._make_dense_bl ((Dense_bl 128, 128
# Переход слоями самостоятельно.transitionLayer1 = self._make_transition_layer(Transition_Layer, in_channels = 160, out_channels = 128) самостоятельно.transitionLayer2 = self._make_transition_layer(Transition_Layer, in_channels = 160, out_channels = 128) самостоятельно.transitionLayer3 = self._make_transition_layer(Transition_Layer, in_channels = 160, out_channels = 64
# Классификатором самостоятельно.БН = НН.BatchNorm2d(num_features = 64) самостоятельно.pre_classifier = nn.Линейные(64*4*4, 512) самостоятельно.classifier = nn.Линейный(512, nr_classes) деф _make_dense_block(самовыдвижение, блок, in_channels): слои = [] слои.добавить(блок(in_channels)) возвращать НН.Последовательный (*layers
деф _make_transition_layer(собственной личности, слой, in_channels, out_channels): модули = [] модулей.добавить(слой(in_channels, out_channels)) возвращать НН.Последовательный (*модули
деф вперед(я, х): из = себя.relu (self.lowconv (x
out = self.denseblock1(уходит) из = себя.transitionLayer1 (out
out = self.denseblock2(уходит) из = себя.transitionLayer2(уходит) из = себя.denseblock3(уходит) из = себя.transitionLayer3(уходит) из = себя.БН(уходит) выход = выход.вид(-1, 64*4*4) из = себя.pre_classifier(уходит) из = себя.классификатор(уходит) возвращения из
Тестирование кода на CIFAR10
Теперь, чтобы выполнить некоторые тесты и посмотреть, как работает сеть, я оптимизирую модель на CIFAR10 с помощью Стохастического Градиентного спуска с импульсом. Я использовал пакеты изображений размера 10, с скоростью обучения, равной 0,001 и импульса 0,95. Я запускаю метод оптимизации для 10 эпох. Общее время обучения модели составило 30 минут. Я смог оптимизировать модель на Nvidia K80 с доступной памятью 12 ГБ бесплатно с помощью Google Colab, так как они имеют в наличии эти ресурсы для 12-часового цикла бесплатно.
Ниже Вы можете увидеть результаты.
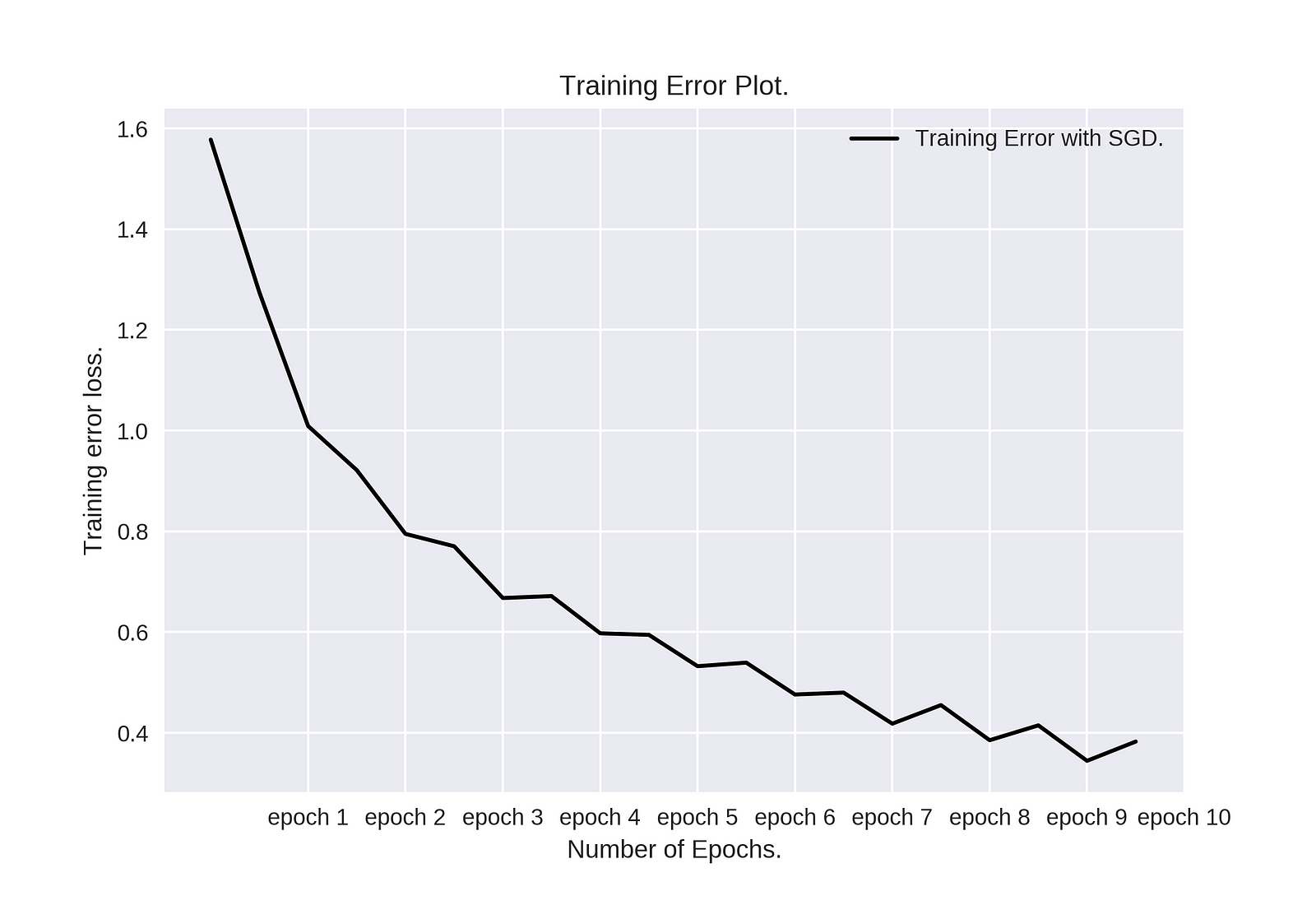
Сюжет о тренировочной ошибке. Конечная точность модели на 10000 тестовых изображений для набора данных CIFAR10 составляет 79%.
Для проверки точности модели на тестовом наборе на CIFAR10 я выполняю следующее.
правильно = 0 Итого = 0
для сведения в testloader: изображений, надписей = данные изображения = переменная(изображений).технология CUDA() выходов = densenet(изображений) _, предсказал = факел.max (выходы.ЦПУ.)(сведения, 1) Общая += ярлыки.Размер(0) правильно += (предсказал == метки).сумма
печать ("точность сети на 10000 тестовых изображений: %d % %" % (100 * правильно / всегоТочность эта модель производит 79% на 10000 изображениях теста, с как раз 10 эпохами.
Теперь мы хотим, как сеть работает для каждого отдельного класса. Результаты показаны ниже
Accuracy of plane : 79 %Accuracy of car : 87 %Accuracy of bird : 71 %Accuracy of cat: 63 %
Accuracy of deer : 72 %Accuracy of dog : 71 %Accuracy of frog : 86 %Accuracy of horse : 78 %Accuracy of ship : 89 % Accuracy of truck : 91 %Как вы можете видеть, класс cat получил самую низкую точность классификации!
Чтобы просмотреть весь код, реализацию и результаты, сами поэкспериментировать с кодом, проверьте ноутбук я произвел с Google Colab в этой ссылке.
Вывод
Статья о плотно Соединенных Сверточных сетях получила награду cvpr17 best paper award. Результаты, представленные в этой статье, являются убедительными и обеспечивают новый современный эталон для задач классификации на конкурсе ImageNet. Кроме того, реализация с подключением всех слоев сети друг к другу, открывает возможности для тестирования новых вещей и новых идей с ним, в то время как бенч-маркировка для лучших результатов.
Источник: towardsdatascience.com