Введение в задачу распознавания эмоций
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-08-03 22:19

Распознавание эмоций – горячая тема в сфере искусственного интеллекта. К наиболее интересным областям применения подобных технологий можно отнести: распознавание состояния водителя, маркетинговые исследования, системы видеоаналитики для умных городов, человеко-машинное взаимодействие, мониторинг учащихся, проходящих online-курсы, носимые устройства и др.
В этой статье я постараюсь дать краткий экскурс в проблему распознавания эмоционального состояния человека и расскажу и подходах к ее решению.

Что такое эмоции?
Эмоция – это особый вид психических процессов, которые выражают переживание человеком его отношения к окружающему миру и самому себе. Согласно одной из теорий, автором которой является российский физиолог П.К. Анохин, способность испытывать эмоции была выработана в процессе эволюции как средство более успешной адаптации живых существ к условиям существования. Эмоция оказалась полезной для выживаемости и позволила живым существам быстро и наиболее экономно реагировать на внешние воздействия.
Эмоции играют огромную роль в жизни человека и межличностном общении. Они могут быть выражены различными способами: мимикой, позой, двигательными реакциями, голосом и вегетативными реакциями (частота сердечных сокращений, артериальное давление, частота дыхания). Однако наибольшей выразительностью обладает лицо человека.
Каждый человек выражает эмоции несколько по-разному. Известный американский психолог Пол Экман, исследуя невербальное поведение изолированных племен в Папуа-Новой Гвинее в 70-х годах прошлого века, установил, что ряд эмоций, а именно: гнев, страх, печаль, отвращение, презрение, удивление и радость являются универсальными и могут быть поняты человеком, независимо от его культуры.
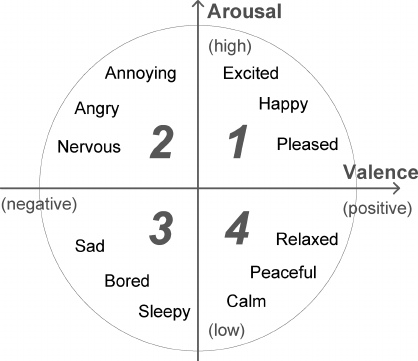
Люди способны выражать широкий спектр эмоций. Считается, что их можно описать как комбинацию базовых эмоций (например, ностальгия – это что-то среднее между печалью и радостью). Но такой категориальный подход не всегда удобен, т.к. не позволяет количественно охарактеризовать силу эмоции. Поэтому наряду с дискретными моделями эмоций, был разработан ряд непрерывных. В модели Дж. Рассела водится двумерный базис, в котором каждая эмоция характеризуется знаком (valence) и интенсивностью (arousal). Ввиду своей простоты модель Рассела в последнее время приобретает все большую популярность в контексте задачи автоматической классификации выражения лица.
Итак, мы выяснили, что если вы не пытаетесь скрыть эмоциональное возбуждение, то ваше текущее состояние можно оценить по мимике лица. Более того, используя современные достижения в области deep learning возможно даже построить детектор лжи, по мотивам сериала «Lie to me», научной основой которого послужили непосредственно работы Пола Экмана. Однако эта задача далеко не так проста. Как показали исследования нейробиолога Лизы Фельдман Барретт, при распознавании эмоций человек активно использует контекстную информацию: голос, действия, ситуацию. Взгляните на фотографии ниже, это действительно так. Используя только область лица, правильное предсказание сделать невозможно. В связи с этим для решения этой задачи необходимо использовать как дополнительные модальности, так и информацию об изменении сигналов с течением времени.

Здесь мы рассмотрим подходы к анализу только двух модальностей: аудио и видео, так как эти сигналы могут быть получены бесконтактным путем. Чтобы подступиться к задаче в первую очередь нужно раздобыть данные. Вот список наиболее крупных общедоступных баз эмоций, известных мне. Изображения и видео в этих базах были размечены вручную, некоторые с использованием Amazon Mechanical Turk.
Классический подход к задаче классификации эмоций
Наиболее простой способ определения эмоции по изображению лица основан на классификации ключевых точек (facial landmarks), координаты которых можно получить, используя различные алгоритмы PDM, CML, AAM, DPM или CNN. Обычно размечают от 5 до 68 точек, привязывая их к положению бровей, глаз, губ, носа, челюсти, что позволяет частично захватить мимику. Нормализованные координаты точек можно непосредственно подать в классификатор (например, SVM или Random Forest) и получить базовое решение. Естественно положение лиц при этом должно быть выровнено.

Простое использование координат без визуальной компоненты приводит к существенной потере полезной информации, поэтому для улучшения системы в этих точках вычисляют различные дескрипторы: LBP, HOG, SIFT, LATCH и др. После конкатенации дескрипторов и редукции размерности с помощью PCA полученный вектор признаков можно использовать для классификации эмоций.
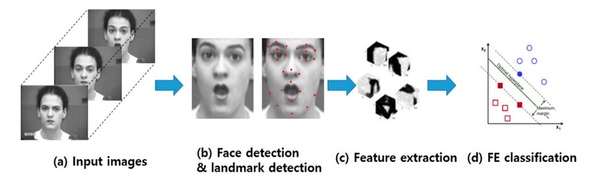
Однако такой подход уже считается устаревшим, так как известно, что глубокие сверточные сети являются лучшим выбором для анализа визуальных данных.
Классификация эмоций с применением deep learning
Для того чтобы построить нейросетевой классификатор достаточно взять какую-нибудь сеть с базовой архитектурой, предварительно обученную на ImageNet, и переобучить последние несколько слоев. Так можно получить хорошее базовое решение для классификации различных данных, но учитывая специфику задачи, более подходящими будут нейросети, используемые для крупномасштабных задач распознавания лиц.
Итак, построить классификатор эмоций по отдельным изображениям достаточно просто, но как мы выяснили, мгновенные снимки не совсем точно отражают истинные эмоции, которые испытывает человек в данной ситуации. Поэтому для повышения точности системы необходимо анализировать последовательности кадров. Сделать это можно двумя путями. Первым способом является подача высокоуровневых признаков, полученных от CNN, классифицирующей каждый отдельный кадр, в рекуррентную сеть (например, LSTM) для захвата временной составляющей.
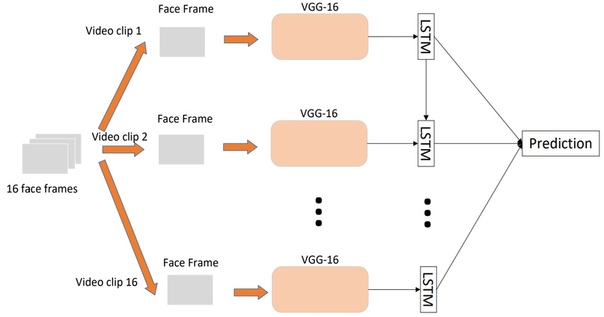
Второй способ заключается в непосредственной подаче последовательности кадров, взятых из видео с некоторым шагом, на вход 3D-CNN. Подобные CNN используют свертки с тремя степенями свободы, преобразующие четырехмерный вход в трехмерные карты признаков.
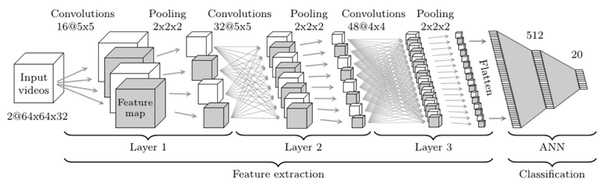
На самом деле в общем случае эти два подхода можно объединить, сконструировав вот такого монстра.

Классификация эмоций по речи
На основе визуальных данных можно с высокой точностью предсказывать знак эмоции, но при определении интенсивности предпочтительнее использовать речевые сигналы. Анализировать аудио немного сложнее ввиду сильной вариативности длительности речи и голосов дикторов. Обычно для этого используют не исходную звуковую волну, а разнообразные наборы признаков, например: F0, MFCC, LPC, i-вектора и др. В задаче распознавания эмоций по речи хорошо себя зарекомендовала открытая библиотека OpenSMILE, содержащая богатый набор алгоритмов для анализа речи и музыкальных сигналов. После извлечения, признаки могут быть поданы в SVM или LSTM для классификации.
Однако в последнее время сверточные нейронные сети стали проникать и в область анализа звука, вытесняя устоявшиеся подходы. Для того чтобы их применить, звук представляют в виде спектрограмм в линейной или mel-шкале, после чего с полученными спектрограммами оперируют как с обычными двумерными изображениями. При этом проблема произвольного размера спектрограмм по временной оси элегантно решается при помощи статистического пулинга или за счет включения в архитектуру рекуррентной сети.

Аудиовизуальное распознавание эмоций
Итак, мы рассмотрели ряд подходов к анализу аудио- и видеомодальностей, остался заключительный этап – объединение классификаторов для вывода окончательного решения. Простейшим способом является непосредственное объединение их оценок. В этом случае достаточно взять максимум или среднее. Более сложным вариантом является объединение на уровне эмбеддингов для каждой модальности. Для этого часто применяют SVM, но это не всегда корректно, так как эмбеддинги могут иметь различную норму. В связи с этим были разработаны более продвинутые алгоритмы, например: Multiple Kernel Learning и ModDrop.
Ну и конечно стоит упомянуть о классе так называемых end-to-end решений, которые могут обучаться непосредственно на сырых данных от нескольких датчиков без всякой предварительной обработки.
В целом задача автоматического распознавания эмоций еще далека от решения. Судя по результатам прошлогоднего конкурса Emotion Recognition in the Wild, лучшие решения достигают точности порядка 60%. Надеюсь, что представленной в этой статье информации будет достаточно, для того чтобы попытаться построить собственную систему распознавания эмоций.
Источник: m.vk.com