Наивный Байес, или о том, как математика позволяет фильтровать спам
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-07-03 01:04

Без формул никуда, ну и краткая теория
Байесовский классификатор относится к разряду машинного обучения. Суть такова: система, перед которой стоит задача определить, является ли следующее письмо спамом, заранее обучена каким-то количеством писем точно известных где «спам», а где «не спам». Уже стало понятно, что это обучение с учителем, где в роли учителя выступаем мы. Байесовский классификатор представляет документ (в нашем случае письмо) в виде набора слов, которые якобы не зависят друг от друга (вот от сюда и вытекает та самая наивность).
Необходимо рассчитать оценку для каждого класса (спам/не спам) и выбрать ту, которая получилась максимальной. Для этого используем следующую формулу:
— вхождение слова в документ класса (со сглаживанием)*
— количество слов входящих в документ класса
М — количество слов из обучающей выборки
— количество вхождений слова в документ класса
— параметр для сглаживания
Когда объем текста очень большой, приходится работать с очень маленькими числами. Для того чтобы этого избежать, можно преобразовать формулу по свойству логарифма**:
Подставляем и получаем:
*Во время выполнения подсчетов вам может встретиться слово, которого не было на этапе обучения системы. Это может привести к тому, что оценка будет равна нулю и документ нельзя будет отнести ни в одну из категорий (спам/не спам). Как бы вы не хотели, вы не обучите свою систему всем возможным словам. Для этого необходимо применить сглаживание, а точнее – сделать небольшие поправки во все вероятности вхождения слов в документ. Выбирается параметр 0<??1 (если ?=1, то это сглаживание Лапласа)
**Логарифм – монотонно возрастающая функция. Как видно из первой формулы – мы ищем максимум. Логарифм от функции достигнет максимума в той же точке (по оси абсцисс), что и сама функция. Это упрощает вычисление, ибо меняется только численное значение.
От теории к практике
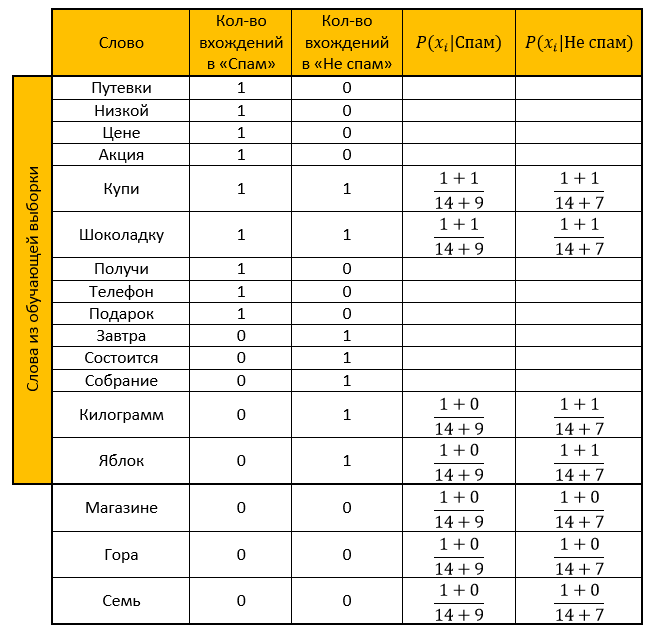
Пусть наша система обучалась на следующих письмам, заранее известных где «спам», а где «не спам» (обучающая выборка):
Спам:
- «Путевки по низкой цене»
- «Акция! Купи шоколадку и получи телефон в подарок»
Не спам:
- «Завтра состоится собрание»
- «Купи килограмм яблок и шоколадку»
Задание: определить, к какой категории отнести следующее письмо:
- «В магазине гора яблок. Купи семь килограмм и шоколадку»
Решение:
Составляем таблицу. Убираем все «стоп-слова», рассчитываем вероятности, параметр для сглаживания принимаем за единицу.
Оценка для категории «Не спам»:
Ответ: оценка «Не спам» больше оценки «Спам». Значит проверочное письмо — не спам!
То же самое рассчитаем и с помощью функции, преобразованной по свойству логарифма:
Оценка для категории «Спам»:
Оценка для категории «Не спам»:
Ответ: аналогично предыдущему ответу. Проверочное письмо – не спам!
Реализация на языке программирования R
Комментировал почти каждое свое действие, ибо знаю, насколько порой не хочется разбираться в чужом коде, поэтому надеюсь, чтение моего не вызовет у вас трудностей. (ой как надеюсь)
А тут, собственно, и сам код
library("tm") #Библиотека для stopwords library("stringr") #Библиотека для работы со строками #Обучаюшая выборка со спам письмами: spam <- c( 'Путевки по низкой цене', 'Акция! Купи шоколадку и получи телефон в подарок' ) #Обучающая выборка с не спам письмами: not_spam <- c( 'Завтра состоится собрание', 'Купи килограмм яблок и шоколадку' ) #Письмо требующее проверки test_letter <- "В магазине гора яблок. Купи семь килограмм и шоколадку" #----------------Для спама-------------------- #Убираем все знаки препинания spam <- str_replace_all(spam, "[[:punct:]]", "") #Делаем все маленьким регистром spam <- tolower(spam) #Разбиваем слова по пробелу spam_words <- unlist(strsplit(spam, " ")) #Убираем слова, которые совпадают со словами из stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] #Создаем таблицу с уникальными словами и их количеством unique_words <- table(spam_words) #Создаем data frame main_table <- data.frame(u_words=unique_words) #Переименовываем столбцы names(main_table) <- c("Слова","Спам") #---------------Для не спама------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #---------------Для проверки------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- #Создаем новый столбик для подсчета не спам писем main_table$Не_спам <- 0 for(i in 1:length(not_spam_words)){ #Создаем логическую переменную need_word <- TRUE for(j in 1:(nrow(main_table))){ #Если "не спам" слово существует, то к счетчику уникальных слов +1 if(not_spam_words[i]==main_table[j,1]) { main_table$Не_спам[j] <- main_table$Не_спам[j]+1 need_word <- FALSE } } #Если слово не встречалось еще, то добавляем его в конец data frame и создаем счетчики if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(Слова=not_spam_words[i],Спам=0,Не_спам=1)) } } #------------- #Создаем столбик содержащий вероятности того, что выбранное слово - спам main_table$Вероятность_спам <- NA #Создаем столбик содержащий вероятности того, что выбранное слово - не спам main_table$Вероятность_не_спам <- NA #------------- #Создаем функцию подсчета вероятности вхождения слова Xi в документ класса Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- #Считаем количество слов из обучающей выборки quantity <- nrow(main_table) for(i in 1:length(test_letter)) { #Используем ту же логическую переменную, чтобы не создавать новую need_word <- TRUE for(j in 1:nrow(main_table)) { #Если слово из проверочного письма уже существует в нашей выборке то считаем вероятность каждой категории if(test_letter[i]==main_table$Слова[j]) { main_table$Вероятность_спам[j] <- formula_1(main_table$Спам[j],quantity,sum(main_table$Спам)) main_table$Вероятность_не_спам[j] <- formula_1(main_table$Не_спам[j],quantity,sum(main_table$Не_спам)) need_word <- FALSE } } #Если слова нет, то добавляем его в конец data frame, и считаем вероятность спама/не спама if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(Слова=test_letter[i],Спам=0,Не_спам=0,Вероятность_спам=NA,Вероятность_не_спам=NA)) main_table$Вероятность_спам[nrow(main_table)] <- formula_1(main_table$Спам[nrow(main_table)],quantity,sum(main_table$Спам)) main_table$Вероятность_не_спам[nrow(main_table)] <- formula_1(main_table$Не_спам[nrow(main_table)],quantity,sum(main_table$Не_спам)) } } #Переменная для подсчета оценки класса "Спам" probability_spam <- 1 #Переменная для подсчета оценки класса "Не спам" probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$Вероятность_спам[i])) { #Шаг 1.1 Определяем оценку того, что письмо - спам probability_spam <- probability_spam * main_table$Вероятность_спам[i] } if(!is.na(main_table$Вероятность_не_спам[i])) { #Шаг 1.2 Определяем оценку того, что письмо - не спам probability_not_spam <- probability_not_spam * main_table$Вероятность_не_спам[i] } } #Шаг 2.1 Определяем оценку того, что письмо - спам probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam #Шаг 2.2 Определяем оценку того, что письмо - не спам probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam #Чья оценка больше - тот и победил ifelse(probability_spam>probability_not_spam,"Это сообщение - спам!","Это сообщение - не спам!") - Очень хорошая статья о наивном бейесовском классификаторе
- Черпал знания из Wiki: тут, тут, и тут
- Лекции по Data Mining Чубуковой И.А.
Источник: habr.com