AI, практический курс. Предобработка и дополнение данных с изображениями
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-06-25 15:09
- Очистка данных. Предположим, что на изображениях присутствуют некоторые артефакты. Чтобы облегчить обучение модели, артефакты необходимо удалить на этапе предобработки.
- Дополнение данных. Иногда небольших наборов данных недостаточно для качественного глубокого обучения модели. Подход с дополнением данных весьма полезен при решении этой проблемы. Это процесс трансформации каждого образца данных различными способами и добавления к набору данных таких измененных образцов. Таким образом можно повысить эффективный размер набора данных.
Рассмотрим некоторые возможные методы трансформации при предобработке и их реализацию через Keras.

Данные
В этой и следующих статьях будет использован набор данных для анализа эмоциональной окраски изображений. Он содержит 1500 примеров изображений, разделенных на два класса — положительные и отрицательные. Рассмотрим некоторые примеры.


Трансформации по очистке
Теперь рассмотрим набор возможных трансформаций, обычно применяемых для очистки данных, их внедрение и влияние на изображения.
Все фрагменты кода можно найти в книге Preprocessing.ipynb.
Перемасштабирование
Изображения, как правило, хранятся в формате RGB (Red Green Blue). В этом формате изображение представлено трехмерным (или трехканальным) массивом.

Одно измерение используется для каналов (красного, зеленого и синего цветов), два других представляют местоположение. Таким образом, каждый пиксель кодируется тремя числами. Каждое число обычно хранится в виде 8-битового беззнакового целого типа (от 0 до 255).
Перемасштабирование — это операция, изменяющая числовой диапазон данных простым делением на заранее определенную константу. В глубоких нейронных сетях может потребоваться ограничить входные данные диапазоном от 0 до 1 из-за возможного переполнения, вопросов оптимизации, стабильности и т. п.
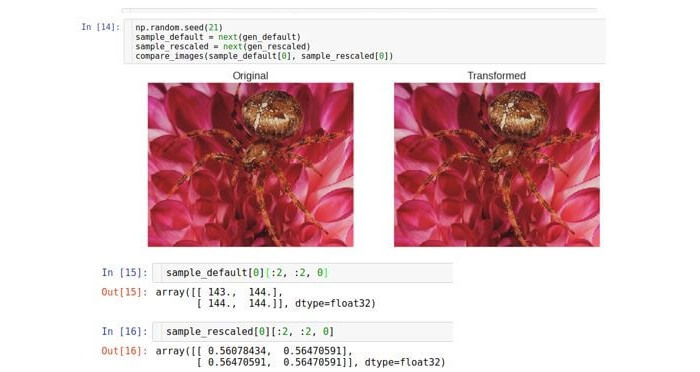
Например, перемасштабируем наши данные с диапазона [0; 255] в диапазон [0; 1]. Здесь и далее будем использовать класс Keras ImageDataGenerator, позволяющий выполнять все трансформации «на лету». Создадим два экземпляра этого класса: один для трансформированных данных, другой для исходных:

Все параметры можно найти в документации, но основными параметрами являются: путь к потоку и целевой размер изображения (если изображение не соответствует целевому размеру, генератор его просто обрезает или наращивает). Наконец, получим образец из генератора и рассмотрим результаты. Визуально оба изображения идентичны, но причина этого в том, что инструменты Python* автоматически перемасштабируют изображения
Перевод в оттенки серого
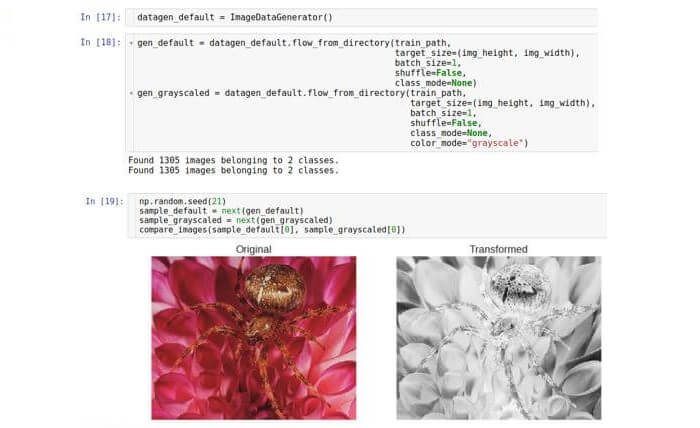
Еще один вид трансформации, который может оказаться полезным — это перевод в оттенки серого, который переводит цветное RGB-изображение в изображение, в котором все цвета представлены оттенками серого. Обычная обработка изображений может использовать перевод в оттенки серого в комбинации с последующим заданием порога. Эта пара трансформаций может отбрасывать шумные пиксели и определять формы на изображении. Сегодня все эти операции выполняются сверточными нейронными сетями (Convolutional Neural Network, CNN), но перевод в оттенки серого как этап предобработки по-прежнему может быть полезным. Запустим этот шаг в Keras с тем же классом генератора.
Центрирование образцов
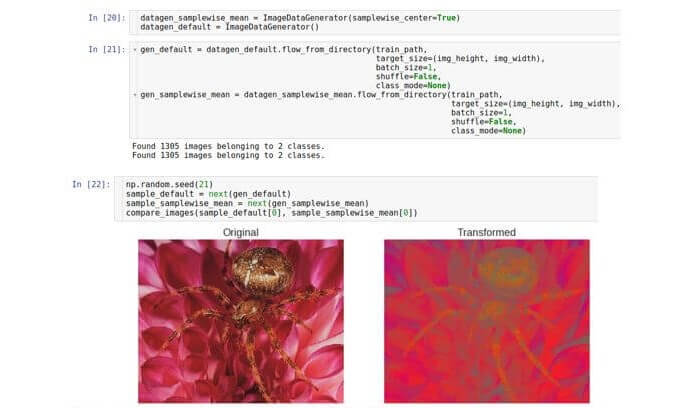
Мы уже видели, что значения необработанных данных находятся в диапазоне от 0 до 255. Таким образом, один образец представляет собой трехмерный массив чисел от 0 до 255. В свете принципов стабильности оптимизации (избавляться от проблемы исчезающих или насыщающих значений) может потребоваться нормализовать набор данных таким образом, чтобы среднее значение каждого образца данных равнялось 0.
Нормализация СКО образцов
Данный этап предобработки основан на той же идее, что и центрирование образцов, но вместо установки среднего в 0 от устанавливает значение среднеквадратичного отклонения в 1.

Данная трансформация может применяться в моделях глубокого обучения для повышения стабильности оптимизации путем снижения влияния проблемы взрывающихся градиентов.
Центрирование признаков
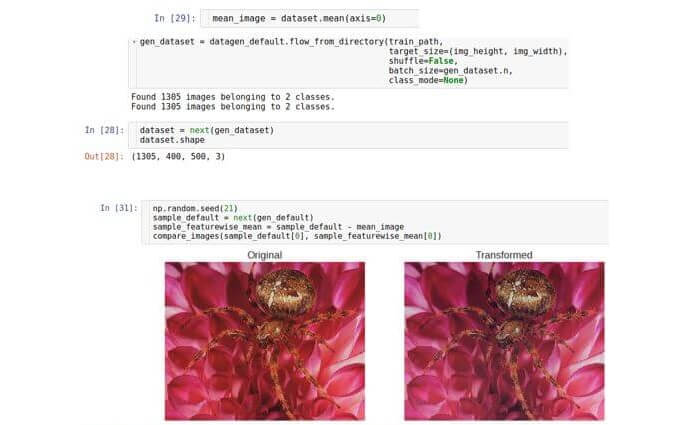
В двух предыдущих разделах использовалась техника нормализации, рассматривающая каждый отдельный образец данных. Существует альтернативный подход к процедуре нормализации. Рассмотрим каждое число в массиве изображения как признак. Тогда каждое изображение представляет собой вектор признаков. В наборе данных много таких векторов; следовательно, мы можем рассматривать их в виде некоторого неизвестного распределения. Это распределение является многопараметрическим, и размерность его будет равна количеству признаков, т. е. ширина ? высота ? 3. Хотя истинное распределение данных неизвестно, можно попытаться нормализовать его путем вычитания среднего значения распределения. Следует отметить, что среднее значение представляет собой вектор той же размерности, то есть, тоже является изображением. Другими словами, мы усредняем по всему набору данных, а не по одному образцу.
Существует специальный параметр Keras под названием featurewise_centering, но, к сожалению, по состоянию на август 2017 года в его реализации была ошибка; поэтому реализуем его самостоятельно. Сначала считаем весь набор данных в память (мы можем себе это позволить, так как имеем дело с небольшим набором данных). Мы сделали это, установив размер пакета равным размеру набора данных. Затем рассчитаем среднее изображение по всему набору данных и, наконец вычтем его из тестового изображения.
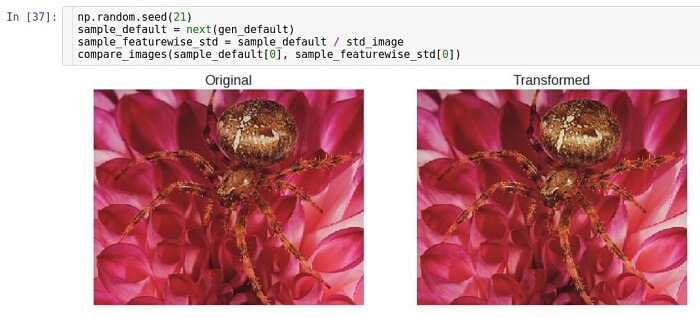
Нормализация СКО признаков
Идея нормализации среднеквадратичного отклонения в точности та же, что и идея центрирования. Единственная разница состоит в том, что вместо вычитания среднего значения мы производим деление на значение среднеквадратичного отклонения. Визуально результат не сильно отличается. То же происходило

Трансформации с дополнением
В данном разделе мы рассмотрим несколько трансформаций, зависимых от данных, явным образом использующих графическую природу данных. Эти типы трансформации часто используются в процедурах дополнения данных.
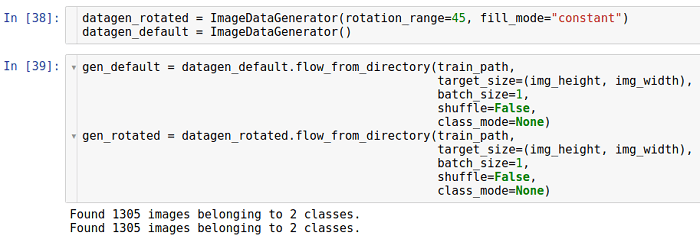
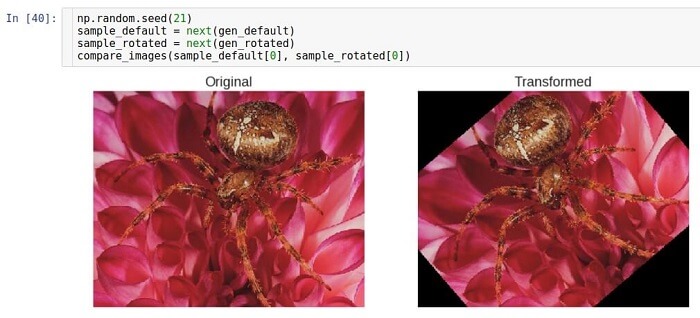
Вращение
Этот вид трансформации вращает изображение в определенном направлении (по или против часовой стрелки).
Параметр, позволяющий осуществлять вращение, называется rotation_range. Он указывает на диапазон в градусах, из которого случайным образом с равномерным распределением выбирается угол поворота. Следует отметить, что при вращении размер изображения не меняется. Таким образом, некоторые участки изображения могут быть обрезаны, а некоторые заполнены.
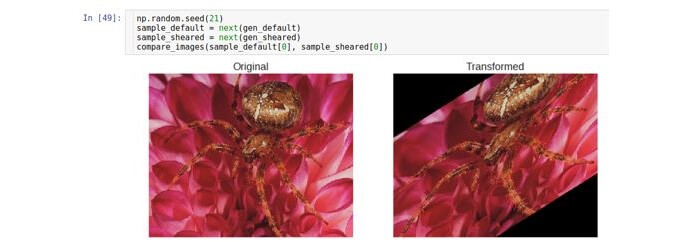
Горизонтальный сдвиг
Этот вид трансформации сдвигает изображение в определенном направлении по горизонтальной оси (влево или вправо).

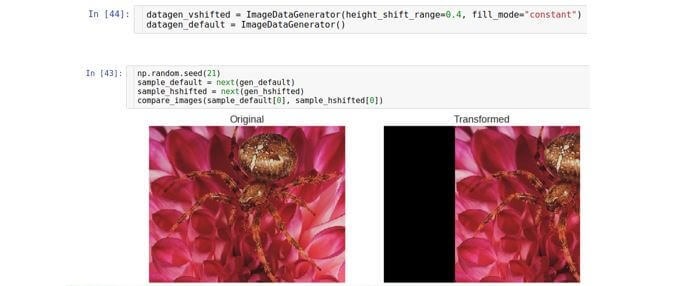
Вертикальный сдвиг
Обрезка
Преобразование обрезки или обрезка смещает каждую точку в вертикальном направлении на величину, пропорциональную расстоянию от этой точки до края изображения. Отметим, что в общем случае направление не обязано быть вертикальным и является произвольным.
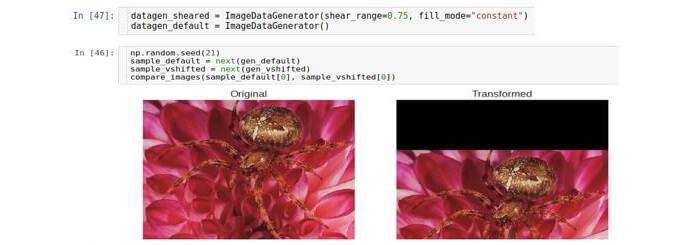
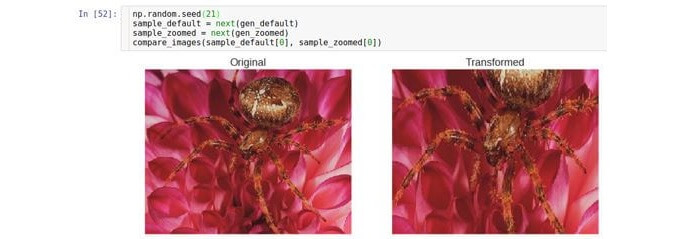
Приближение/удаление

Горизонтальный переворот

Вертикальный переворот

Комбинация
Применим все описанные виды трансформаций дополнения одновременно и посмотрим, что из этого получится. Напомним, что параметры для всех трансформаций выбираются случайным образом из определенного диапазона; таким образом, мы должны получить набор образцов со значительной степенью разнообразия.
Инициируем ImageDataGenerator со всеми доступными параметрами и проверим на изображении красного гидранта.

Заключение
В данной статье представлен обзор основных техник предобработки изображений, таких как: масштабирование, нормализация, вращение, сдвиг и обрезка. Также продемонстрирована реализация этих техник трансформации при помощи Keras и внедрение их в процесс глубокого обучения как технически (класс ImageDataGenerator), так и идеологически (дополнение данных).
Источник: habr.com