Распознавание позы человека через веб-камеру в браузере с помощью TensorFlow.js.
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-05-21 20:30
машинное обучение новости, теория распознавания образов, свёрточные нейронные сети

Написал: Дэн Овед, внештатный креативный технолог в Google творческие лаборатории, аспирант ИТФ, нью-йоркском университете.
Редактирование и иллюстрации: Ирина Альварадо, креативный технолог и Алексис Галло, внештатный графический дизайнер, в Google творческие лаборатории
В сотрудничестве с компанией творческая Лаборатория, я рад объявить о выпуске TensorFlow.яш версия PoseNet1,2 машинного обучения модель, которая позволяет в реальном времени человека ставят оценку в браузере. Попробовать демо здесь.


PoseNet может обнаруживать человеческие фигуры в изображениях и видео, используя алгоритм с одной или несколькими позами-все из браузера.
Так что же такое оценка поза? Ставят оценки относится к технологии компьютерного зрения, которые обнаруживают человеческие фигуры в изображения и видео, так что можно определить, например, где кто-то в локте появляется в изображении. Чтобы было понятно, эта технология не признавая , кто является в образе — нет личной информации, связанных с определение. Алгоритм просто оценивает, где ключевые суставы тела.
Хорошо, и почему это интересно начать с? Ставят оценку имеет множество применений, от интерактивных инсталляций , которые реагируют на тело , чтобы дополненная реальность, анимация, фитнес-использует, и многое другое. Мы надеемся, что доступность этой модели вдохновит больше разработчиков и создателей экспериментировать и применять обнаружение позы для своих собственных уникальных проектов. В то время как многие альтернативное определение системы с открытым кодом, все требуют специализированного оборудования и/или камеры, а также совсем немного настройка системы. С PoseNet работает на TensorFlow.js любой, у кого есть приличный рабочий стол или телефон с веб-камерой, может испытать эту технологию прямо из веб-браузера. И так как мы уже с открытым исходным кодом модели, разработчики JavaScript может повозиться и использовать эту технологию с помощью всего нескольких строк кода. Более того, это может помочь сохранить конфиденциальность пользователей. С PoseNet на TensorFlow.js работает в браузере, никакие данные позы никогда не покидают компьютер пользователя.
Прежде чем мы углубимся в детали того, как использовать эту модель, shoutout на все люди, которые сделали этот проект возможным: Джордж Папандреу и Тайлер Чжу, Гугл исследователей за документы в сторону точного Multi-человека ставят оценку в дикой природе и PersonLab: человека ставят оценку и экземпляр Сегментация с снизу вверх, частью на основе геометрических внедрения модели, и Никхил Thorat и Даниэль Smilkov, инженеры на Гугл-мозг команды за TensorFlow.в JS библиотека.
Начало работы с PoseNet
PoseNet может быть использован для оценки либо в одном позе или нескольких позах, смысл есть версии алгоритма, который может обнаружить только одного человека на изображении/видео и одна версия, которую можно обнаружить несколько человек в изображение/видео. Почему существуют две версии? Детектор позы для одного человека быстрее и проще, но требует только одного субъекта, присутствующего в изображении (более подробно об этом позже). Сначала мы покрываем одну позу, потому что за ней легче следовать.
На высоком уровне оценка позы происходит в два этапа
- В RGB входной сигнал изображения подается через сверточная нейронная сеть.
- Один-поза или многоракурсного алгоритм декодирования используется для декодирования позы, позы доверия, оценки, выбора позиции, и точки доверия счеты с модельными данными.
Но подождите, что означают все эти ключевые слова? Рассмотрим наиболее важные из них
- Поза — на высшем уровне, PoseNet вернется в позу объект, который содержит список точек и экземпляр-уровень доверия результат для каждого обнаруженного лица.

PoseNet возвращает доверительные значения для каждого обнаруженного человека, а также для каждой обнаруженной ключевой точки. Изображение кредита: “Майкрософт Коко: Общие объекты в контексте набора данных”, протокол https://cocodataset.org.
- Поза доверия результат — это определяет общую уверенность в оценке позе. Оно колебается между 0.0 и 1.0. Его можно использовать, чтобы скрыть позы, которые не считаются достаточно сильными.
- Точка — часть человека позу, которая оценивается, как нос, правое ухо, левое колено, правая нога и т. д. Она содержит как позиции и точку, результат доверия. PoseNet в настоящее время обнаруживает 17 характерных точек, проиллюстрированных на следующей схеме
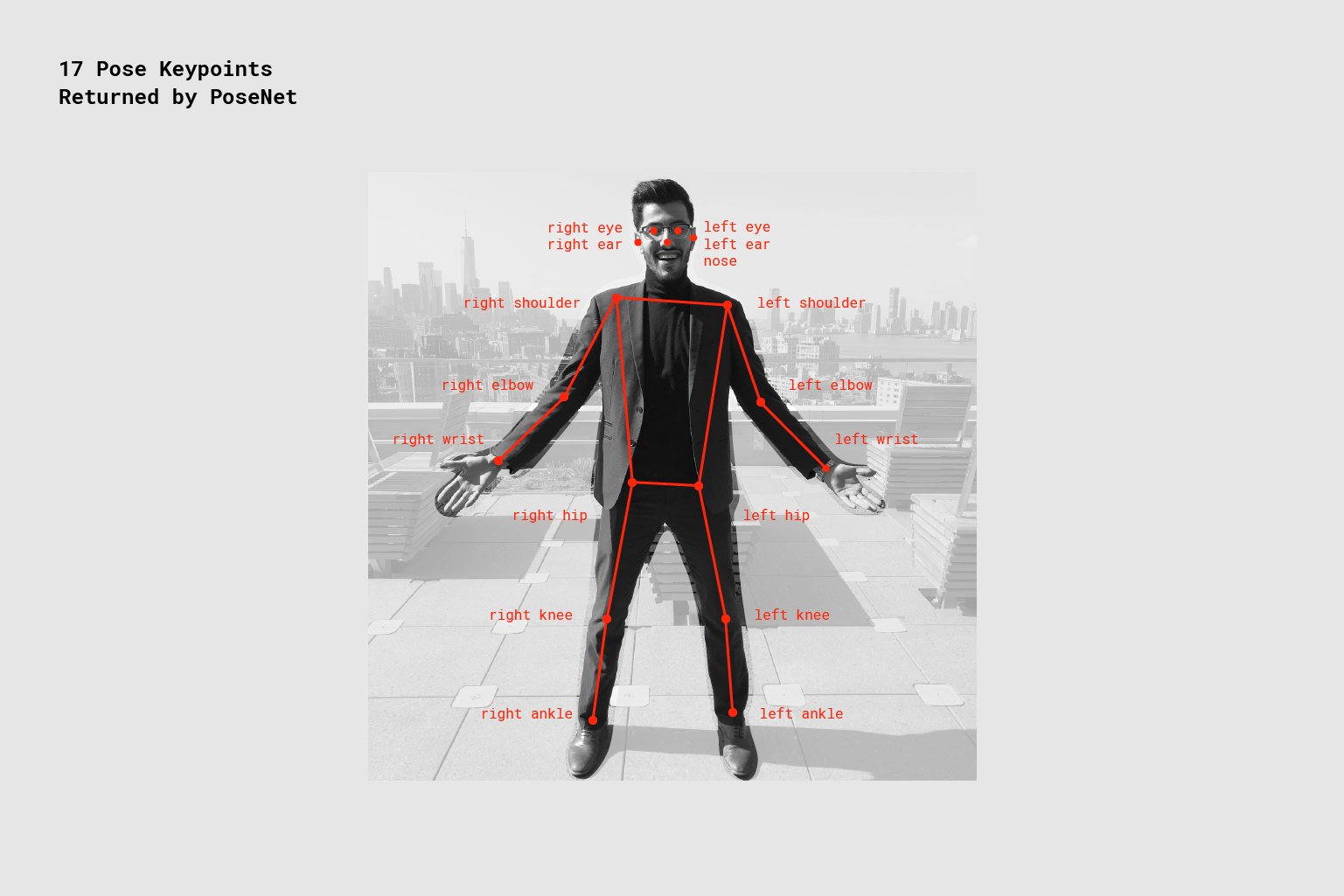
Семнадцать ключевых точек позы, обнаруженных PoseNet.
- Точки доверия результат — это определяет уверенность в том, что около точки установки является точной. Оно колебается между 0.0 и 1.0. Его можно использовать, чтобы скрыть ключевые точки, которые не считаются достаточно сильными.
- Точки установки — 2Д координаты X и Y в исходное изображения, где точки были обнаружены.
Часть 1: Импорт TensorFlow.библиотеки JS и PoseNet
Много работы ушло на абстрагирование сложности модели и инкапсулирование функциональности в простые в использовании методы. Давайте рассмотрим основы настройки проекта PoseNet.
Библиотека может быть установлена с помощью npm
npm install @tensorflow-models/posenet
и импортированный используя модули es6
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();
или через пачку в странице
<html>
<body>
<!-- Load TensorFlow.js -->
<script src="https://unpkg.com/@tensorflow/tfjs"></script> <!-- Load Posenet --> <script src="https://unpkg.com/@tensorflow-models/posenet"> </script> <script type="text/javascript"> posenet.load().then(function(net) { // posenet model loaded }); </script> </body> </html>
Часть 2а: Оценка положения одного человека

Пример алгоритма оценки положения одного человека, примененного к изображению. Изображение кредита: “Майкрософт Коко: Общие объекты в контексте набора данных”, протокол https://cocodataset.org.
Как указывалось выше, алгоритм однократной оценки является более простым и быстрым из двух. Его идеально использовать случай, когда есть только один человек, центрированный во входном изображении или видео. Недостатком является то, что если в изображении есть несколько человек, то ключевые точки от обоих людей, вероятно, будут оцениваться как часть одной и той же позы — это означает, например, что левая рука человека #1 и правое колено человека #2 могут быть объединены алгоритмом как принадлежащие к той же позе. Если существует вероятность того, что входные изображения будут содержать несколько человек, то вместо этого следует использовать алгоритм многозначной оценки.
Давайте рассмотрим входов на один-ставят оценку алгоритма
- Входное изображение элемент — элемент HTML, который содержит изображение, чтобы предсказать, позирует, такие как видео или изображения тег. Главное, изображение или видео элемент ФРС должна быть квадратной.
- Изображения масштабный коэффициент — это число от 0,2 до 1. По умолчанию 0,50. Что масштабировать изображение, прежде чем кормить его через сеть. Установите это число ниже, чтобы уменьшить масштаб изображения и увеличить скорость при питании через сеть за счет точности.
- Отразить по горизонтали — по умолчанию false. Если позы должны быть перевернуты / зеркальные по горизонтали. Это должно быть установлено в true для видео, где видео по умолчанию перевернуто горизонтально (т. е. веб-камера), и вы хотите, чтобы позы были возвращены в правильной ориентации.
- Выход шага — должно быть 32, 16 или 8. По умолчанию 16. Этот параметр влияет на высоту и ширину слоев в нейронной сети. На высоком уровне, это влияет на точность и скорость ставят оценки. В нижнее значение выходного шаг, тем выше точность, но меньше скорость, тем выше значение тем выше скорость, но ниже точность. Лучший способ увидеть эффект на выход шагом на выход качество, чтобы играть с один-ставят оценку демо.
Теперь давайте рассмотрим выходов на один-ставят оценку алгоритма:
- Поза, содержащая как оценку достоверности поза и массив из 17 характерных точек.
- Каждая характерная точка содержит положение характерной точки и оценку уверенности характерной точки. Опять же, все положения характерных точек имеют координаты x и y во входном пространстве изображения и могут быть сопоставлены непосредственно с изображением.
Этот короткий блок кода показывает, как использовать алгоритм оценки одной позы
const imageScaleFactor = 0.50; const flipHorizontal = false; const outputStride = 16;
const imageElement = document.getElementById('cat');// load the posenet model const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);
Пример выходной позы выглядит следующим образом
{ "score": 0.32371445304906, "keypoints": [
{ // nose "position":
{ "x": 301.42237830162,
"y": 177.69162777066 },
"score": 0.99799561500549 },
{ // left eye
"position": { "x": 326.05302262306,
"y": 122.9596464932 },
"score": 0.99766051769257 },
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388 },
"score": 0.99926537275314 }, ... ] }Часть 2b: оценка позы для нескольких человек

Пример алгоритма оценки позы от нескольких лиц, примененного к изображению. Изображение кредита: “Майкрософт Коко: Общие объекты в контексте набора данных”, протокол https://cocodataset.org
Алгоритм оценки позы от нескольких лиц может оценить множество поз / лиц в изображении. Это более сложный и немного медленнее, чем алгоритм с одной позой, но у него есть преимущество, что если несколько человек появляются на картинке, их обнаруженные ключевые точки меньше связаны с неправильной позой. По этой причине, даже если вариант использования заключается в обнаружении позы одного человека, этот алгоритм может быть более желательным.
Более того, привлекательным свойством этого алгоритма является то, что на производительность не влияет количество людей во входном изображении. Есть ли 15 человек, чтобы обнаружить или 5, Время вычисления будет то же самое.
Рассмотрим входы:
- Входное изображение элемента — так же, как один-ставят оценку
- Изображения коэффициент масштабирования — же как один-ставят оценку
- Отразить по горизонтали — так же, как один-ставят оценку
- Выход шагом — так же, как один-ставят оценку
- Максимальная поза обнаружений — целое число. По умолчанию 5. Максимальное количество поз для обнаружения.
- Поза доверия балл порог — от 0.0 до 1.0. По умолчанию 0,5. На высоком уровне, это контролирует минимальный балл доверия поз, которые возвращаются.
- Не-максимального подавления (НМС) радиус — число в пикселях. На высоком уровне это управляет минимальным расстоянием между возвращаемыми позами. Это значение по умолчанию равно 20, что, вероятно, хорошо для большинства случаев. Он должен быть увеличен / уменьшен как способ отфильтровать менее точные позы, но только если настройка оценки достоверности поз недостаточно хороша.
Лучший способ увидеть, какое влияние эти параметры, чтобы играть с мульти-ставят оценку демо.
Рассмотрим выходы:
- Обещание, которое разрешается с массивом поз.
- Каждая поза содержит ту же информацию, как описано в алгоритме оценки одного человека.
Этот короткий блок кода показывает, как использовать алгоритм многозначной оценки
const imageScaleFactor = 0.50; const flipHorizontal = false;
const outputStride = 16; // get up to 5 poses
const maxPoseDetections = 5; // minimum confidence of the root part of a pose
const scoreThreshold = 0.5; // minimum distance in pixels between the root parts of poses
const nmsRadius = 20;
const imageElement = document.getElementById('cat');// load posenet const net = await posenet.load();
const poses = await net.estimateMultiplePoses( imageElement,
imageScaleFactor, flipHorizontal, outputStride, maxPoseDetections, scoreThreshold, nmsRadius);
An example output array of poses looks like the following:
// array of poses/persons [
{ // pose #1 "score": 0.42985695206067,
"keypoints": [ { // nose
"position": {
"x": 126.09371757507,
"y": 97.861720561981 },
"score": 0.99710708856583 }, ... ] },
{ // pose #2 "score": 0.13461434583673,
"keypositions": [ { // nose
"position": { "x": 116.58444058895,
"y": 99.772533416748 },
"score": 0.9978438615799 }, ... ] }, ... ]
Если вы дочитали до этого места, вы знаете достаточно, чтобы начать работу с PoseNet демос. Это наиболее подходящее время. Если вам интересно узнать больше о технических деталях модели и реализации, мы приглашаем вас, чтобы продолжить чтение ниже.
Для Любопытных Умов: Техническое Глубокое Погружение
В этом разделе мы рассмотрим немного больше технических деталей относительно алгоритма оценки с одной позой. На высоком уровне процесс выглядит так
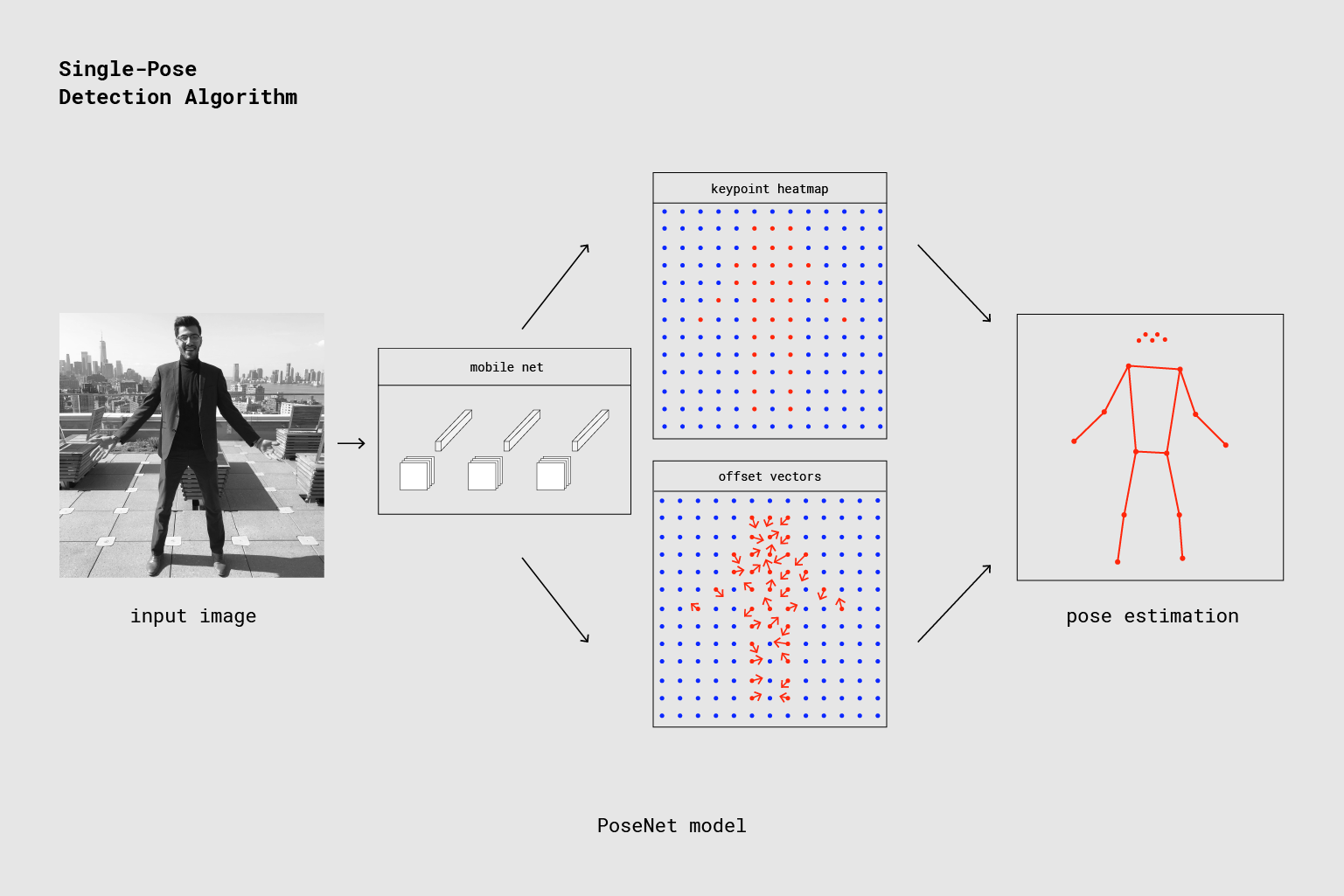
Одиночная персона представляет трубопровод детектора используя PoseNet
Одна важная деталь следует отметить, что исследователи обучили как ResNet и сайт mobilenet модель PoseNet. Хотя модель ResNet имеет более высокую точность, ее большой размер и множество слоев сделают время загрузки страницы и время вывода менее идеальным для любых приложений в режиме реального времени. Мы пошли с моделью MobileNet, поскольку она предназначена для работы на мобильных устройствах.
Пересмотр алгоритма оценки одной позы
Обработка модельных входов: объяснение выходных сдвигов
Сначала мы расскажем, как получить PoseNet модели выходов (в основном, тепловыми картами и смещение векторов) путем обсуждения выходной успехов.
Удобно, что модель PoseNet является инвариантом размера изображения, что означает, что она может предсказать позы в том же масштабе, что и исходное изображение, независимо от того, является ли изображение пониженным. Это значит, PoseNet может быть настроен, чтобы иметь более высокую точность за счет снижения производительности путем настройки вывода шаг мы уже упомянутое выше во время выполнения.
Выходной шаг определяет, насколько мы масштабируем Выходные данные относительно размера входного изображения. Это влияет на размер слоев и выходных данных модели. В выше выходного шага, тем меньше разрешение слоев в сети и выходы, и, соответственно, их точность. В этой реализации выходной шаг может иметь значения 8, 16 или 32. Другими словами, шаг выхода 32 приведет к самой быстрой производительности, но самой низкой точности, в то время как 8 приведет к самой высокой точности, но самой медленной производительности. Мы рекомендуем начать с 16.
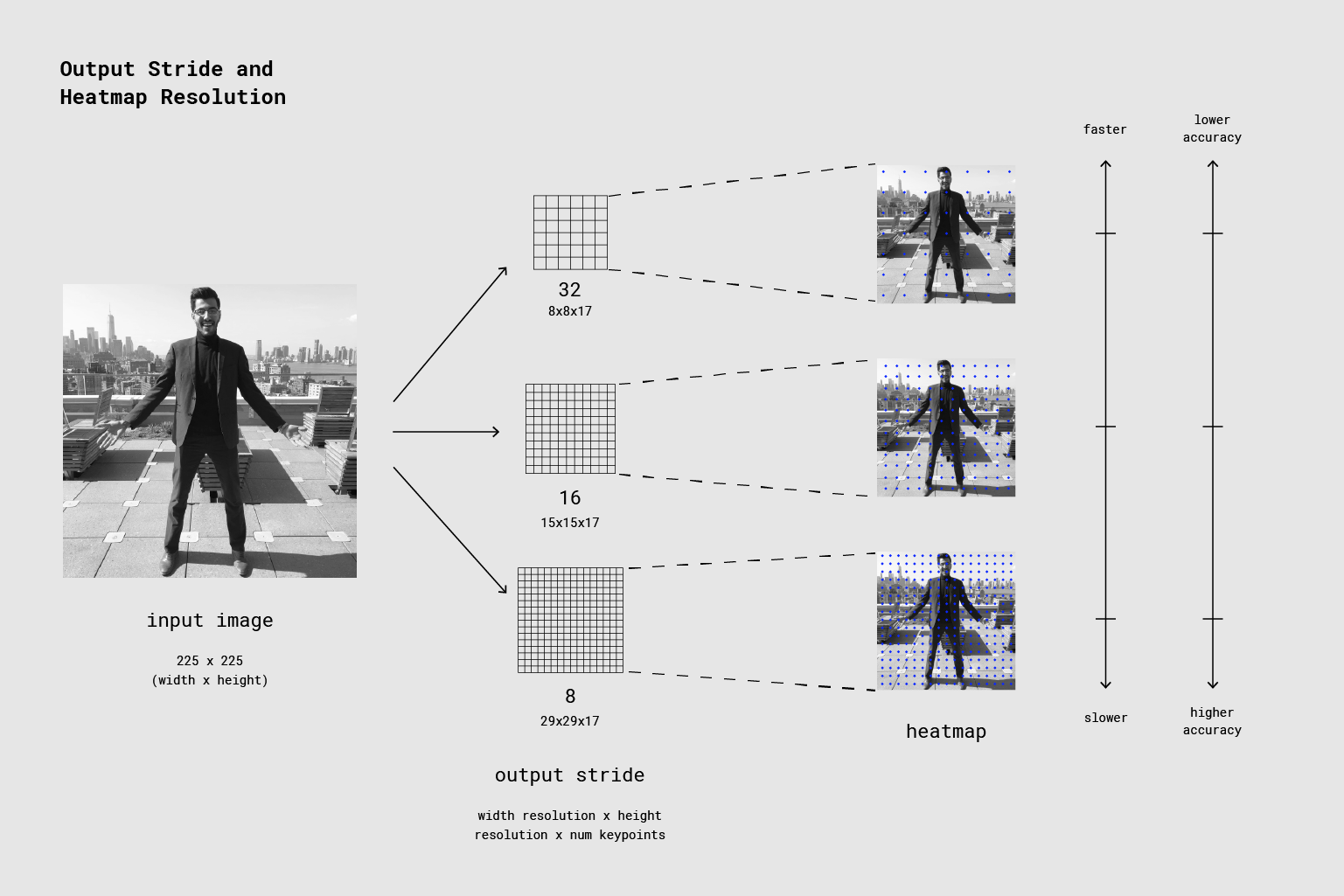
Выходной шаг определяет, насколько мы масштабируем Выходные данные относительно размера входного изображения. Более высокий шаг выхода более быстр но результаты в более низкой точности.
Под капотом, когда выходной шаг установлен на 8 или 16, Количество входных шагов в слоях уменьшается, чтобы создать большее выходное разрешение. Атрус свертка используется, чтобы включить фильтры свертки в последующих слоях, чтобы иметь широкое поле зрения (атрус свертки не применяется при выходе шаг 32). В то время как Tensorflow поддерживает atrous свертку, TensorFlow.яш не сделал, поэтому мы добавили пиара , чтобы включить это.
Выходы модели: тепловые карты и векторы смещения
Когда PoseNet обрабатывает изображения, что на самом деле возвращается в виде тепловой карты вместе с смещение векторов , которые могут быть декодированы, чтобы найти высокое доверие участки изображения, которые соответствуют ставят точки. Мы перейдем к тому, что каждый из них означает через минуту, но пока на рисунке ниже на высоком уровне показано, как каждая из характерных точек позы связана с одним тензором тепловых карт и тензором вектора смещения.
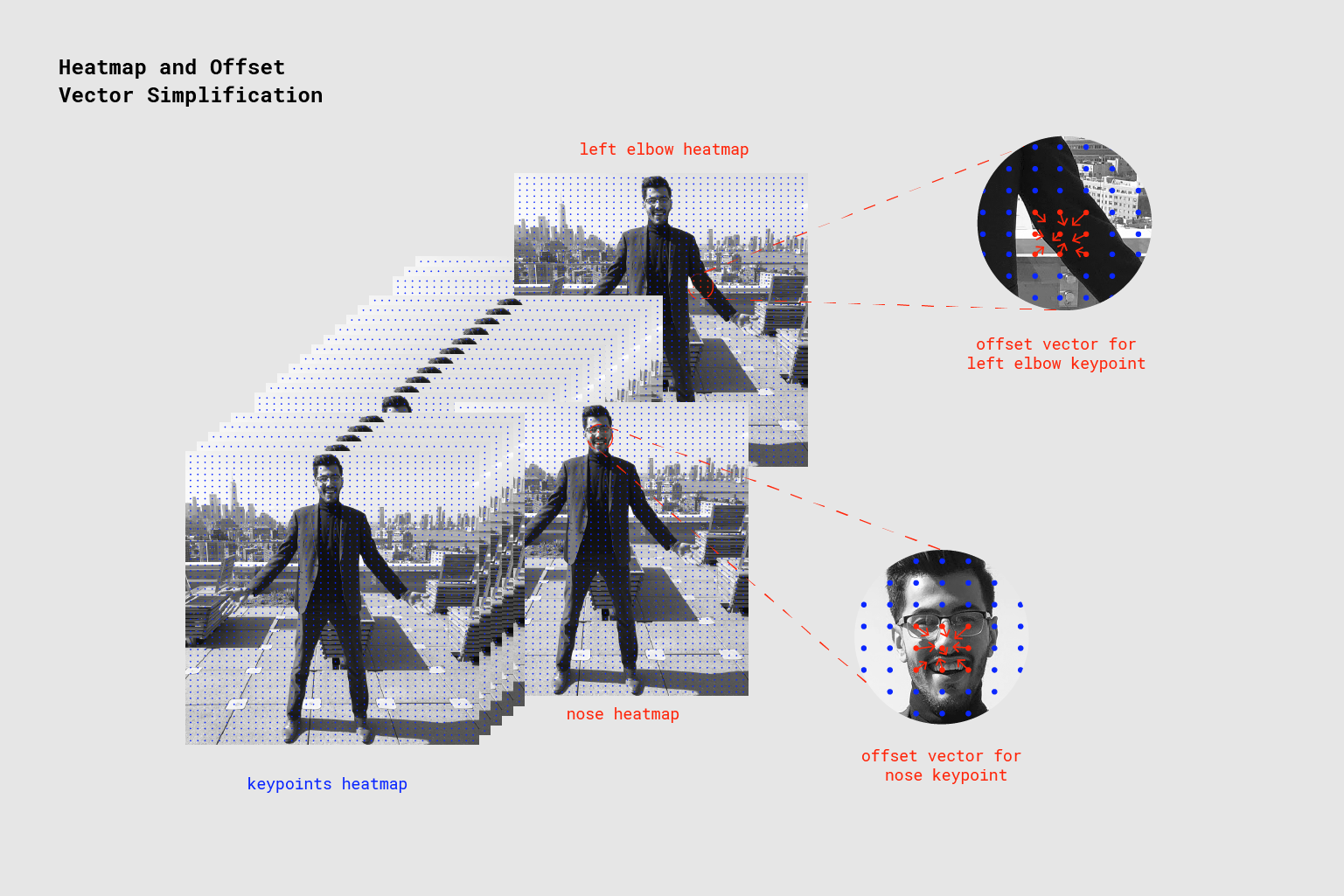
Каждая из 17 поз характерных точек, возвращаемых PoseNet, связана с одним тензором heatmap и одним тензором вектора смещения, используемым для определения точного местоположения характерной точки.
Оба эти выходы являются 3D тензоров с высоты и ширины, что мы называем разрешением. Разрешение определяется как размером входного изображения, так и выходным шагом в соответствии с этой формулой
Resolution = ((InputImageSize - 1) / OutputStride) + 1
// Example: an input image with a width of 225 pixels and an output
// stride of 16 results in an output resolution of 15
// 15 = ((225 - 1) / 16) + 1
Тепловые карты
Каждая карта представляет собой 3D тензора Размер разрешение x разрешение x 17, так как 17 число характерных точек, обнаруженных PoseNet. Например, с размером изображения 225 и выходным шагом 16, это будет 15x15x17. Каждый срез в третьем измерении (из 17) соответствует тепловой карте для определенной характерной точки. Каждая позиция в этой heatmap имеет доверительную оценку, которая является вероятностью того, что часть этого типа характерной точки существует в этой позиции. Его можно рассматривать как исходное изображение, разбитое на сетку 15x15, где оценки heatmap обеспечивают классификацию того, насколько вероятно, каждая характерная точка существует в каждом квадрате сетки.
Смещение Векторов
Каждое смещение вектора является 3D тензора Размер разрешение x разрешение x 34, где 34-количество временных точек * 2. С размером изображения 225 и выходным шагом 16, это будет 15x15x34. Поскольку тепловые карты представляют собой приближение того, где расположены характерные точки, векторы смещения соответствуют в местоположении точкам тепловой карты и используются для предсказания точного местоположения характерных точек, перемещаясь вдоль вектора из соответствующей точки тепловой карты. Первые 17 срезов вектора смещения содержат x вектора, а последние 17-y. Размеры вектора смещения находятся втот же масштаб, что и исходное изображение.
Оценка поз по результатам модели
После того, как изображение подается через модель, мы выполняем несколько расчетов, чтобы оценить позу с выходов. Алгоритм оценки одной позы, например, возвращает оценку достоверности позы, которая сама по себе содержит массив характерных точек (индексированных по идентификатору детали), каждая из которых имеет доверительную оценку и позицию x, Y.
Чтобы получить ключевые точки позы
- В сигмовидной активация производится на карту, чтобы получить баллы.
scores = heatmap.sigmoid() - argmax2d делается на точки доверия баллы, чтобы получить X и Y индекс в карту с максимальным количеством баллов за каждую часть, которая по сути, где часть является, скорее всего, существовать. Это создает тензор размера 17x2, при этом каждая строка является индексом y и x в heatmap с наибольшим количеством баллов для каждой части.
heatmapPositions = scores.argmax(y, x) - На смещение вектора для каждой части извлекается путем получения X и Y от смещения, соответствующие X и Y индекс в карту для той части. Это создает тензор размера 17x2, причем каждая строка является вектором смещения для соответствующей характерной точки. Например, для детали в индексе k, когда heatmap находится в положении y и d, смещение вектора
offsetVector = [offsets.get(y, x, k), offsets.get(y, x, 17 + k)] - Чтобы получить точку, каждая часть это тепловая карта X и Y умножаются на выход страйд затем добавил к соответствующим смещением вектора, который находится в том же масштабе, что и исходное изображение.
keypointPositions = heatmapPositions * outputStride + offsetVectors - Наконец, каждая точка доверия результат - это уверенность в результат его тепловая карта установки. В позе доверия результат - это десятки точек.
Оценка позы Multi-персоны
Детали многозначного алгоритма оценки выходят за рамки этого поста. В основном, этот алгоритм отличается тем, что он использует жадный процесс для группы точек в позах после перемещения векторов вдоль части-графа. В частности, он использует быстрые жадные декодирования алгоритм исследования PersonLab: человека ставят оценку и экземпляр Сегментация с снизу вверх, частью на основе геометрических внедрения модели. Для получения более подробной информации о мульти-создают алгоритм, пожалуйста, ознакомьтесь с полным исследовательскую работу или посмотреть на код.
Мы надеемся, что как больше моделей портированы на TensorFlow.js, мир машинного обучения становится более доступным, гостеприимным и интересным для новых кодеров и создателей. PoseNet на TensorFlow.js-это небольшая попытка сделать это возможным. Мы хотели бы увидеть, что вы делаете — и не забудьте поделиться своими удивительными проектами с помощью #tensorflowjs и #posenet!
Источник: medium.com