Intel открыл систему машинного обучения для обработки информации на естественном языке
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-05-29 13:03
Компания Intel представила проект NLP Architect, в рамках которого открыты наработки в области применения методов глубинного машинного обучения для обработки и распознавание смысла информации на естественном языке (NLP/NLU, Natural Language Processing/Understanding). Код библиотеки написан на языке Python и распространяется под лицензией Apache 2.0. Библиотека поддерживает работу с фреймворками машинного обучения Intel Nervana™ graph, Intel neon, Tensorflow, Dynet и Keras.
Из задач, для решения которых может применяться NLP Architect, называется проведение тренировки моделей с использованием предоставляемых алгоритмов, эталонных наборов данных и настроек (также предоставляются уже натренированные модели для различного применения); тренировка с использование своих данных; создание новых или расширение доступных моделей; исследование применимости различных моделей глубинного машинного обучения для решения задач обработки информации на естественном языке; проведение экспериментов и оптимизация алгоритмов машинного обучения; интеграция в свои проекты готовых модулей и утилит, предоставляемых библиотекой.
Библиотека предоставляет ряд готовых моделей NLP и NLU, пригодных для разбора зависимостей между языковыми конструкциями, определения смысловых примитивов и маркировки слотов, применения сетей памяти (Memory Networks) для построения диалогов, применения сетей ключ/значение (Key-value Network) для организации взаимодействия в форме вопрос/ответ, использования модели векторов для расстановки слов, пометка частей речи, проведения семантической сегментации словосочетаний, распознавания именованных сущностей (известных названий, имён, объектов), выделение терминов, определения смысловой информации (распознавание смысла прочитанного) и разбивки текста на структурные элементы.
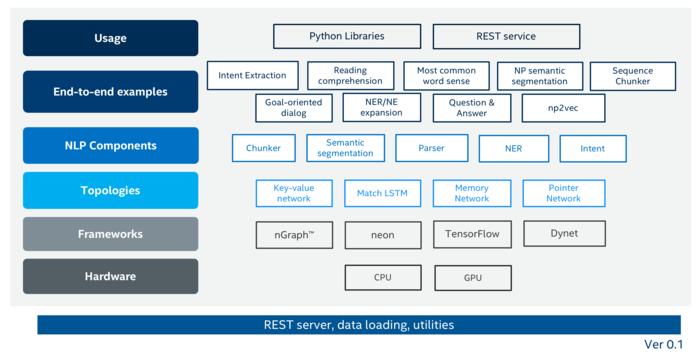
В состав NLP Architect входят следующие компоненты:
- Набор базовых моделей NLP для обработки информации на естественном языке (например, могут применяться для определения частей речи и выделения цепочек связи между словами);
- Модули NLU для распознавание смысла информации на естественном языке (например, для извлечения смысловых единиц и выделения терминов);
- Модули для семантического разбора (например, для определение словосочетаний и наиболее значимых слов);
- Компоненты для создания диалоговых систем с элементами инскуственного интеллекта, таких как чат-боты;
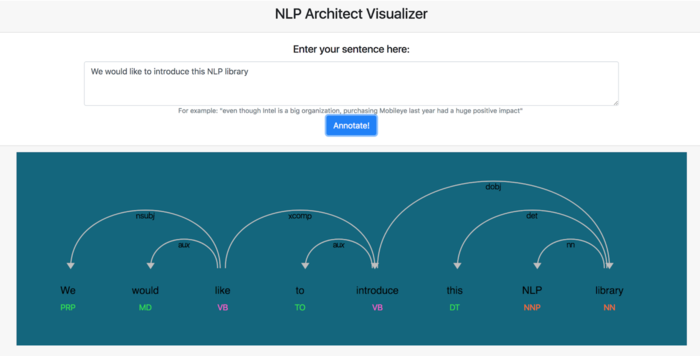
- Шаблоны для построения готовых сервисов и примеры приложений с реализацией отвечающих на вопросы автоинформаторов, систем машинного чтения и интерфейсов для визуализации взаимосвязи между словами.
Дополнительно можно отметить публикацию универсальной системы классификации текста, разработанной проектом fast.ai. Система позволяет расставлять метки для текста, в зависимости от его содержимого. Например, метод может применяться для определения спама и оскорбительных комментариев, разбора положительных и отрицательных отзывов, группировки статей по заданной тематике, выделения документов, в которых упоминаются определённые факты. Код классификатора написан на языке Python и распространяется под лицензией Apache 2.0. В качестве базового фреймворка применяется PyTorch. Для загрузки доступна уже натренированная модель на основе Wikitext.
Источник: www.opennet.ru