Nv-Wavenet: лучший синтез речи с использованием графического процессора
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-04-25 18:19

WaveNets представляет exciting новую нейросеть используется для создания сырых аудио сигналов, в том числе способность синтезировать очень высокое качество речи. Эти сети оказались сложными для развертывания на процессорах, так как генерация речи в режиме реального времени или лучше требует существенных вычислений в сжатые сроки. К счастью, графические процессоры предлагают огромную параллельную вычислительную способность, необходимую для создания высокопроизводительного развертывания WaveNet в реальном времени с использованием nv-wavenet.
В этом посте я познакомлю НВ-wavenet, ссылочку реализация на CUDA с поддержкой авторегрессии WaveNet вывод двигателя. Более конкретно, реализации задач авторегрессии часть WaveNet вариант, описанный глубокий голос. Он включает в себя несколько различных вариантов реализации, позволяя компромиссы между сложностью, максимальной частотой дискретизации и пропускной способностью при заданной частоте дискретизации.
Несколько групп недавно выдвигал альтернативы авторегрессии WaveNet, таких как параллельный WaveNet и WaveRNN. Хотя эти альтернативы также хорошо работают на графических процессорах, я сосредоточусь исключительно на авторегрессионном выводе WaveNet. Наши исследования показали, что авторегрессионные WaveNets обеспечивают высокое качество результатов, но просты в обучении. Соответственно, ядра быстрого вывода для Авторегрессионных WaveNets ценны как для прямого развертывания, так и для увеличения скорости итерации исследователя во время обучения моделей преобразования текста в речь.
Авторегрессионный Вывод WaveNet
Autoregressive WaveNets может быть сложным для развертывания, так как вход для каждого timestep модели включает в себя выход модели для предыдущего timestep. Следовательно, развертывание имеет длинный последовательный критический путь. Чтобы понять, почему это может быть проблемой, давайте взглянем на разбавленную свертку, такую как та, которая используется WaveNets, показанная на рисунке 1.
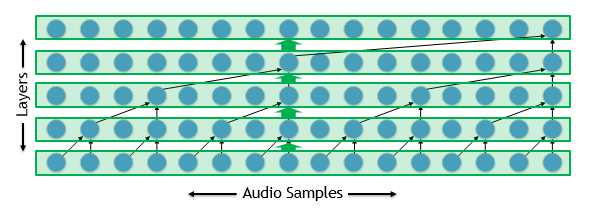
Реализация сети проста для обучения: мы реализуем каждый слой с одним или несколькими ядрами. Эти ядра параллельны многим тысячам звуковых сэмплов в нашей осциллограмме и могут работать достаточно эффективно.
С другой стороны, мы должны дождаться, пока модель произведет один образец, прежде чем мы сможем начать обработку следующего образца для вывода, как показано на рисунке 2.
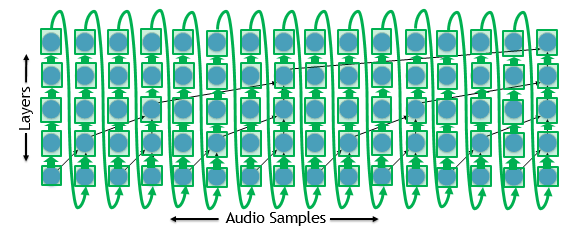
Предположим, мы хотим сгенерировать сигнал 24 кГц. У нас есть только 42,7 микросекунды, чтобы произвести каждый образец, учитывая их последовательную зависимость. Это дает нам чуть больше микросекунды для каждого слоя для 40-слойной модели. Запуск ядра GPU в микросекундах нецелесообразен, поэтому давайте попробуем что-то другое.
На рисунке 3 показано, что один из вариантов-запуск ядра для одного timestep, а не для одного слоя.

Это требует гораздо более сложного ядра, так как оно должно реализовать всю модель. Однако теперь у нас есть полные 42,7 микросекунды вместо мизерной 1 микросекунды на ядро. Чтобы взять его дальше, если мы уже столкнулись с проблемой реализации всей модели в одном ядре, мы могли бы также использовать это ядро для создания нескольких образцов для каждого вызова. Это освобождает нас от беспокойства о накладных расходах kernel полностью.
Представляем nv-wavenet
НВ-wavenet является открытым исходным кодом реализации нескольких различных ядра подходы к WaveNet вариант, описанный глубокий голос. Реализация фокусируется на авторегрессионной части WaveNet, так как она наиболее критична для производительности. Обусловливающие данные, которые определяют, какую речь производится должны быть предоставлены из внешнего источника.
В настоящее время существуют три варианта реализации nv-wavenet: одноблочный, двухблочный и постоянный.
Вариант с одним блоком
На рисунке 4 показан вариант с одним блоком, который реализует всю модель в одном блоке потока.
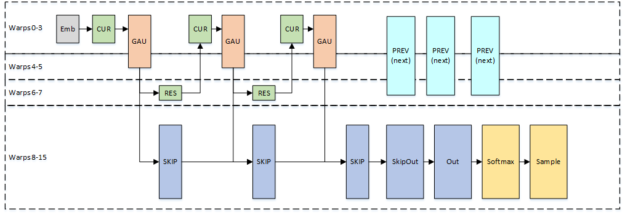
PREV и CUR-две половинки 2 ? 1 разбавленной свертки. PREV обрабатывает данные из предыдущего timestep, определяемого расширением слоя, в то время как CUR обрабатывает данные из текущего timestep. ГАУ, Закрытая Единица активации, состоит из Таня и сигмоида с последующим точечным умножением. RES и SKIP составляют окончательную свертку в остаточном слое. RES создает остаточные каналы, а SKIP - каналы пропуска.Поскольку предварительные вычисления зависят только от остаточных слоев, мы перекрываем предварительные вычисления для следующей выборки с конечными слоями текущей выборки, чтобы уменьшить Общее время генерации выборки.
Так как блок thread должен загружать веса для всей модели для каждого сгенерированного образца, наша Максимальная частота дискретизации ограничена пропускной способностью считывания одного Мультипроцессора потоковой передачи. Мы используем деформацию специализации для конвейера весовых нагрузок с вычислением использовать пропускную способность наиболее эффективно. Некоторые искажения нагружают веса, в то время как другие искажения выполняют вычисления, как показано на рисунке 5.
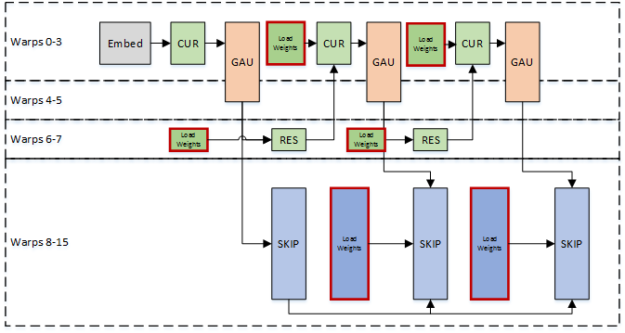
Масштабирование пропускной способности
Если мы реализуем всю модель в одном блоке, один вывод может использовать только один Потоковый Многопроцессор. Это неэффективное использование ресурсов на Tesla V100 GPU, который имеет 80 потоковых Многопроцессоров. Мы можем просто увеличить количество выводов, которые мы хотели бы выполнить, запустив несколько блоков, чтобы лучше использовать эти простаивающие ресурсы. Рисунок 6 показывает, как пропускная способность может увеличиться еще больше, запустив небольшой пакет на блок потока, пока мы балансируем Размер пакета на блок в соответствии с бюджетом времени, предоставленным нашей целевой частотой дискретизации.
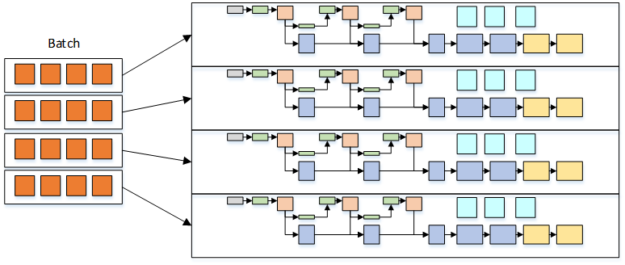
Вариант с двумя блоками
Одноблочный подход может не достичь желаемой частоты дискретизации, если модель слишком велика. Одна простая альтернатива: разбить модель на два блока потоков. Поскольку эти блоки потоков могут работать на разных потоковых Многопроцессорах, мы фактически удвоили нашу доступную пропускную способность для загрузки весов модели. Рисунок 8 показывает, как мы разделили модель по блокам.
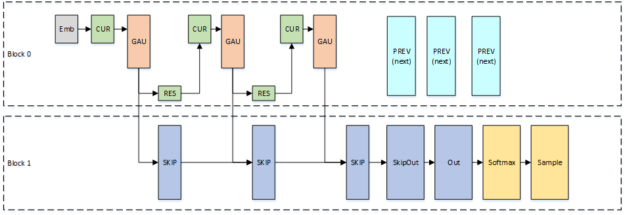
Постоянный вариант
В конечном счете, мы хотим, чтобы избежать беспокоиться о полосе пропускания веса на всех для очень больших моделей или очень высокой частоты дискретизации. Постоянный вариант делит модель на множество блоков потоков, как показано на рисунке 9. Каждый блок потока загружает подмножество весов и удерживает их для всей генерации сигнала. Время вычисления плюс время взаимодействия между блоками теперь ограничивает частоту дискретизации, а не время загрузки весов.
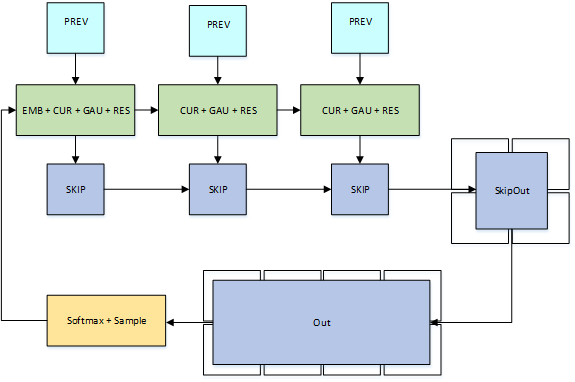
Постоянный вариант реализует каждый остаточный слой в виде трех блоков потока:один блок потока вычисляет часть разбавленной свертки, которая вычисляет данные из предыдущего timestep, второй блок потока реализует остальную часть разбавленной свертки в дополнение к логике gated активации и остаточной свертки, а третий блок реализует пропуск свертки. Окончательные свертки могут быть гораздо большле и таким образом снабжены с множественными сотрудническими блоками резьбы.
Производительность nv-wavenet
Давайте взглянем на то, как эти разные варианты работать на двух разных WaveNets описано в глубокий голос бумаги:
- "Medium" - самая большая модель, для которой авторы Deep Voice смогли достичь вывода 16 кГц на CPU. Оно использует 64 остаточных канала, 128 каналов скипа, и 20 слоев.
- "Большой" обеспечивает гораздо лучшее качество, но авторы Deep Voice не смогли достичь своей цели 16 кГц. Эта модель использует 64 остаточных канала, 256 каналов пропуска, и 40 слоев.
Все показанные данные для nv-wavenet составленного при CUDA 9.0 бежать на Tesla V100-SXM2. Пока nv-wavenet поддерживает оба fp16 и fp32, мы только показываем данные fp16.
Максимальная частота дискретизации
Во-первых, давайте рассмотрим максимальную частоту дискретизации для одного несогласованного вывода на рисунке 10
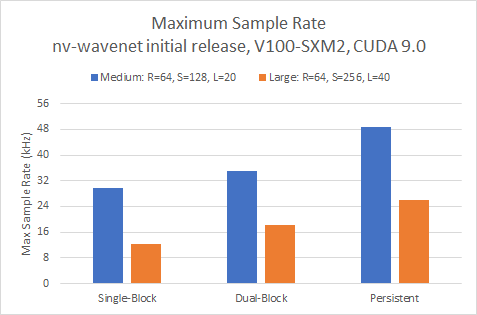
Все три подхода легко превосходят наши цели в реальном времени 16 и 24 кГц для меньшей из двух моделей. Нам нужно использовать вариант с двумя блоками, чтобы превысить 16 кГц для более крупной модели, в то время как толчок выше, чем 24 кГц требует постоянного варианта.
Максимальная частота дискретизации является только частью изображения. Мы хотели бы сделать много выводов параллельно, чтобы максимально использовать наш GPU. Давайте посмотрим на самый большой размер партии, который мы можем достичь, все еще достигая целевой частоты дискретизации, показанной на рисунке 11.
Пропускная способность при 16 кГц
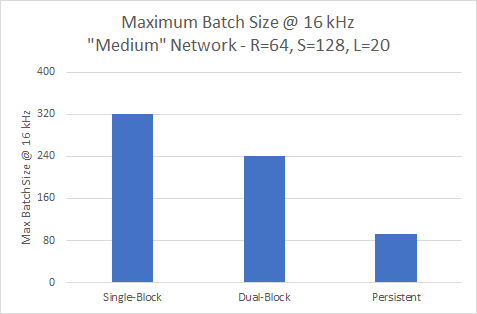
Вариант с одним блоком обеспечивает наибольшую пропускную способность всех трех вариантов на уровне 16 кГц для меньшей модели, но имеет наименьшую максимальную частоту дискретизации.
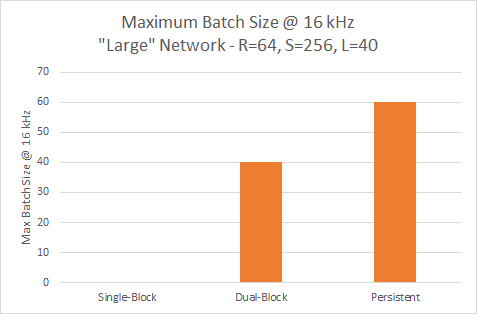
Вариант с одним блоком не может достигать 16 кГц с более крупной моделью, поэтому требуется, чтобы постоянный вариант обеспечивал самую высокую пропускную способность, как вы можете видеть на рисунке 12.
Пропускная способность 24 кГц
Тенденция, показанная ранее, продолжается для меньшей сети на 24kHz. На рисунке 13 показан вариант с одним блоком, обеспечивающий наибольшую пропускную способность при пакете 106.
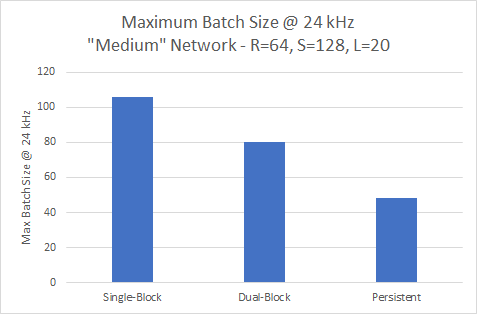
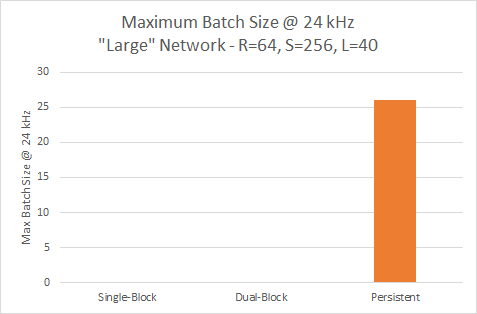
Рисунок 14 иллюстрирует, что только постоянный вариант достигает 24 кГц для более крупной модели, где он может запускать пакет из 26.
NV-Wavenet использует GPU для генерации речи
WaveNets дает нам захватывающий подход к синтезу речи. CUDA предоставляет отличную платформу для развертывания этих сетей в режиме реального времени, используя массово параллельные вычислительные ресурсы графических процессоров NVIDIA. Я особенно рад NVIDIA сделал nv-wavenet с открытым исходным кодом, что позволяет пользователям изменять код в соответствии с их уникальными требованиями. Мы сделали НВ-wavenet исходный код доступен для скачивания. Если у вас есть вопросы или пожелания, пожалуйста, примите наши НВ-wavenet обследования - это всего лишь несколько вопросов и дает нам лучшее представление о ваших случаях использования. Не стесняйтесь взять nv-wavenet для спина, изменить его, дать нам обратную связь о том, как мы можем сделать его лучше.
Источник: devblogs.nvidia.com