Еще одна статья о распознавании рабочих без касок нейросетями
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-04-23 11:55

КДПВ, снятая в реальном времени с камеры видеонаблюдения
Дано: доступ к камерам видеонаблюдения промышленных объектов работодателя, 2-4 студента-стажера (в ходе разработки число занятых проектом менялось).
Задача: разработать прототип системы, в реальном времени обнаруживающей сотрудников без касок. Выбор технологий — на свое усмотрение. Наш выбор пал на Python, как на язык, позволяющий с минимальными трудозатратами реализовать первый рабочий прототип, и — поначалу — OpenCV, как библиотеку машинного зрения, о которой мы были наиболее наслышаны.
OpenCV представляет собой библиотеку, реализующую преимущественно классические методы машинного зрения, такие как каскадные классификаторы. Суть данного подхода заключается в создании т.н. ансамбля слабых классификаторов, т.е. таких, что их соотношение верно классифицированных ими объектов к общему количеству положительных срабатываний было хотя бы незначительно больше 0.5. Один подобный классификатор не способен дать какого-либо результата, однако объединение тысяч таких классификаторов может дать крайне точный результат.

Пример того, как ансамбль слабых классификаторов способен выполнить достаточно точную классификацию. Источник
Очевидно, что задача обнаружения человека без каски сводится к задачам обнаружения человека как такового и… каски! Или же ее отсутствия. Доступ к видеокамерам позволил достаточно быстро собрать первый датасет из обрезанных фото касок и самих людей, как в касках, так и без (достаточно быстро нашлись и такие), и в дальнейшем довести его объем до 2к+ фотографий.

Разметка изображений для обучения
На этом этапе была найдена первая неприятная особенность OpenCV — официальная документация была разрознена и местами просто ссылалась на книгу одного из ведущих разработчиков библиотеки. Для многих параметров значения приходилось подбирать экспериментально.
 Первый же запуск классификатора, обученного на касках, обнаруживал их с точностью около 60% при единичных случаях ложноположительных срабатываний! Мы чувствовали, что находимся на верном пути. Задача обнаружения людей оказалась куда сложнее: в отличие от касок, люди появлялись в кадре под большим количеством ракурсов и в целом требовали от классификатора куда более продвинутых способностей к обобщению. Пока я занимался доработкой классификатора, обученного на касках, в качестве альтернативы тестировалось CV-классическое обнаружение объектов, базирующееся на алгоритме выделения контуров Canny и подсчете движущихся объектов.
Первый же запуск классификатора, обученного на касках, обнаруживал их с точностью около 60% при единичных случаях ложноположительных срабатываний! Мы чувствовали, что находимся на верном пути. Задача обнаружения людей оказалась куда сложнее: в отличие от касок, люди появлялись в кадре под большим количеством ракурсов и в целом требовали от классификатора куда более продвинутых способностей к обобщению. Пока я занимался доработкой классификатора, обученного на касках, в качестве альтернативы тестировалось CV-классическое обнаружение объектов, базирующееся на алгоритме выделения контуров Canny и подсчете движущихся объектов.
Параллельно мы разрабатывали подсистему для обработки получаемых от классификатора данных. Логика работы проста: с камеры наблюдения снимается кадр и передается в классификатор, производится проверка, совпадает ли количество распознанных людей и касок в кадре, в случае обнаружения человека без каски делается запись в базе данных с информацией о количестве распознанных объектов, а сам кадр сохраняется для ручного анализа. Данное решение обладало еще одним плюсом — кадры, сохраненные из-за ошибки классификатора, позволяли дообучить его именно на тех данных, с которыми он не справился.
И тут возникла новая проблема: подавляющее большинство кадров сохранялись из-за ошибок распознавания, а не персонала без касок. Обучение на свежих данных несколько улучшило результат распознавания, однако каски распознавались в ~75% случаев (при единичных ложных срабатываниях), а перекрывающие друг друга в кадре фигуры людей правильно подсчитывались лишь в чуть более чем половине случаев. Я убедил менеджера проекта выделить мне неделю на разработку нейросетевого детектора.
Одной из фич, делающих работу с НС удобной — как минимум по сравнению с классификаторами — является end-to-end подход: в процессе обучения классификатора помимо размеченных изображений касок/людей требовались изображения фона и изображения для валидации классификатора, которые требовалось конвертировать в специальный формат, при этом процесс конвертации управляется множеством различных нетривиальных параметров, не говоря уже о параметрах самого классификатора! В случае же работы с алгоритмами подсчета движущихся объектов и прочими процесс становится еще более сложным, к изображениям предварительно применяются фильтры, удаляется фон и т.д. End-to-end learning требует от разработчика "всего лишь" размеченный датасет и параметры обучаемой модели.
ML-фреймворк TensorFlow и недавно появившийся на тот момент репозиторий tensorflow/models удовлетворял моим требованиям — он был достаточно хорошо задокументирован, с его помощью можно было быстро написать работающий прототип (самые популярные архитектуры работают практически "из коробки"), в то же время его функционал полностью подходил для дальнейшей разработки, если прототип окажется успешным. После адаптации имеющегося туториала под имеющийся датасет с использованием 101-слойного резнета (принципы сверточных нейронных сетей уже неоднократно освещались на Хабре, я лишь позволю себе сослаться на статьи [1], [2]), обученного на датасете COCO (который включает в себя и фото людей), я сходу получил более чем 90% точности! Это было убедительным аргументом для начала разработки детектора касок на основе СНС.

Обученная на стороннем датасете СНС с легкостью распознает стоящих рядом людей, но делает ошибку там, где от нее вообще не ждали распознавания :)
В ходе обучения моделей TensorFlow может генерировать чекпоинт-файлы, позволяющие компилировать и тестировать НС на разных этапах, что бывает полезно, если во время дообучения что-то пошло не так. Скомпилированная модель представляет из себя ориентированный вычислительный граф, начальные вершины которого представляют собой входные данные (в случае работы с изображениями — значения цвета каждого пикселя), а конечные — результаты распознавания.
Помимо данных о самой модели, чекпоинт может содержать метаданные о самом процессе обучения, которые могут быть визуализированы с помощью Tensorboard.
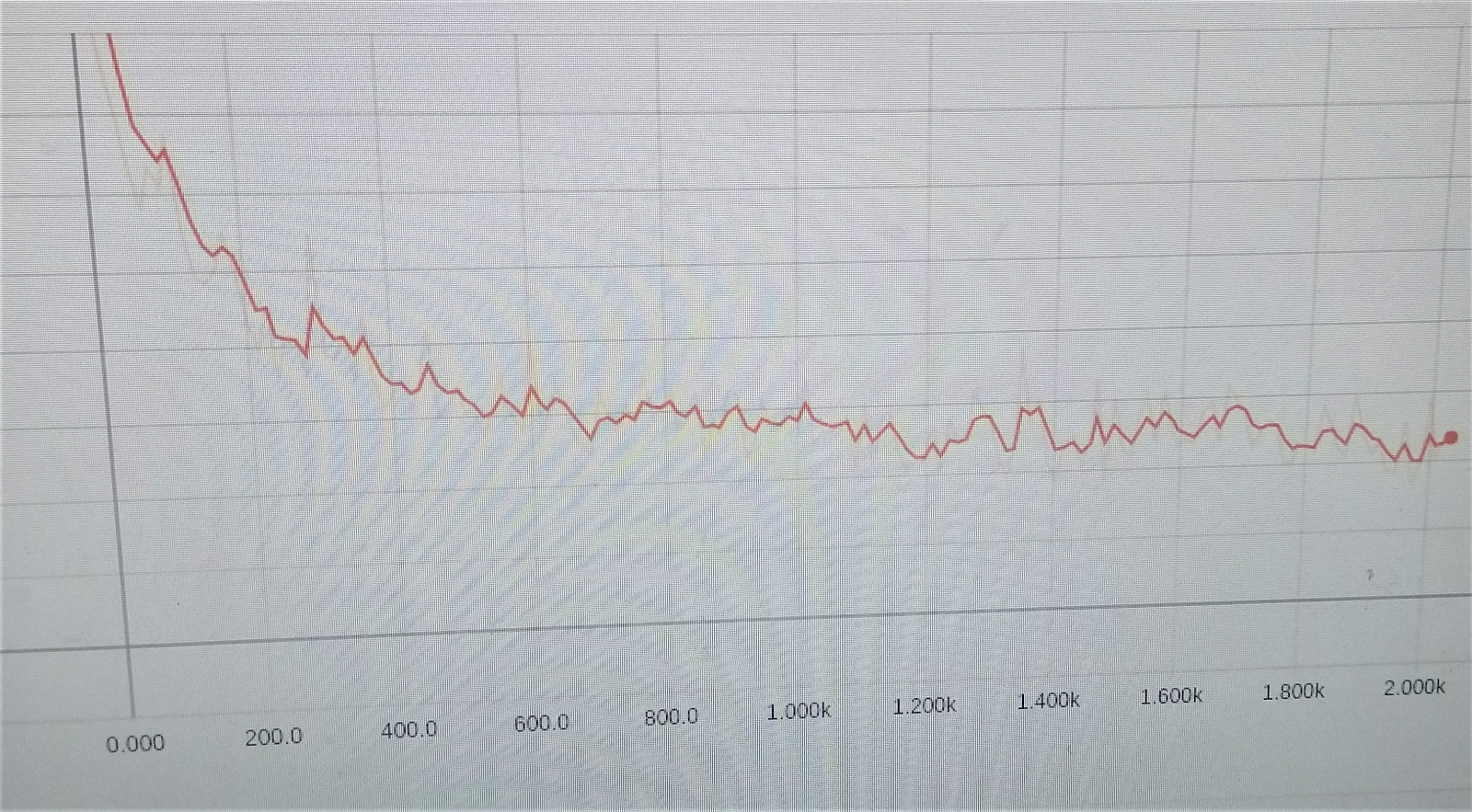
Заветный график уменьшения ошибки обучения
После тестирования ряда архитектур была выбрана ResNet-50 как обеспечивающая оптимум между быстродействием и качеством распознавания. После взвешивания всех "за" и "против" было решено оставить эту обученную сеть как есть, поскольку она уже давала приемлемый результат, и обучить на касках более простую Single Shot Detector (SSD) сеть [3], которая давала меньшую точность при распознавании людей, но обеспечивала удовлетворительные 90%+ при работе с касками. Это, казалось бы, нелогичное решение было обусловлено тем, что дополнительное использование SSD незначительно увеличивало время, затрачиваемое на само распознавание, но в разы сокращало время, затрачиваемое на обучение и тестирование сети с разными параметрами и обновленным датасетом (с нескольких суток до 20-30 часов на GTX 1060 6GB), а значит, увеличивало итеративность разработки.
Таким образом, можно сделать несколько выводов: во-первых, современные НС-фреймворки обладают низким порогом вхождения (но, бесспорно, их эффективное использование требует глубоких знаний в области машинного обучения) и гораздо более удобны и функциональны при решении задач распознавания образов; во-вторых, студенты бывают полезны для быстрой разработки прототипов и тестирования технологий ;)
Буду рад ответить на вопросы и конструктивную критику в комментариях.
Источник: habrahabr.ru