Руководство по SEO JavaScript-сайтов. Часть 1. Интернет глазами Google
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-03-12 16:11
В частности, сегодня автор этого материала, Томаш Рудски из компании Elephate, расскажет о том, как сайты, которые используют современные JS-фреймворки, вроде Angular, React, Vue.js и Polymer, выглядят с точки зрения Google. А именно, речь пойдёт о том, как Google обрабатывает сайты, о технологиях, применяемых для анализа страниц, о том, как разработчик может проанализировать сайт для того, чтобы понять, сможет ли Google нормально этот сайт проиндексировать.
 JavaScript-технологии разработки веб-сайтов в наши дни весьма популярны, поэтому может показаться, что они уже достигли достаточно высокого уровня развития во всех мыслимых направлениях. Однако, в реальности всё не так. В частности, разработчики и SEO-специалисты всё ещё находятся в самом начале пути к тому, чтобы сделать сайты, построенные на JS-фреймворках, успешными в плане их взаимодействия с поисковыми системами. До сих пор множество подобных сайтов, несмотря на их популярность, занимают далеко не самые высокие места в поисковой выдаче Google и других поисковых систем.
JavaScript-технологии разработки веб-сайтов в наши дни весьма популярны, поэтому может показаться, что они уже достигли достаточно высокого уровня развития во всех мыслимых направлениях. Однако, в реальности всё не так. В частности, разработчики и SEO-специалисты всё ещё находятся в самом начале пути к тому, чтобы сделать сайты, построенные на JS-фреймворках, успешными в плане их взаимодействия с поисковыми системами. До сих пор множество подобных сайтов, несмотря на их популярность, занимают далеко не самые высокие места в поисковой выдаче Google и других поисковых систем.Может ли Google сканировать и анализировать сайты, основанные на JavaScript?
Ещё в 2014-м компания Google заявляла о том, что их системы неплохо индексируют сайты, использующие JavaScript. Однако, несмотря на эти заявления, всегда давались рекомендации осторожно относиться к этому вопросу. Взгляните на это извлечение из оригинала материала «Совершенствуем понимание веб-страниц» (здесь и далее выделение сделано автором материала):
«К сожалению, индексация не всегда проходит гладко, что может привести к проблемам, влияющим на позицию вашего сайта в результатах поиска … Если код JavaScript слишком сложный или запутанный, Google может проанализировать его некорректно… Иногда JavaScript удаляет контент со страницы, а не добавляет его, что также затрудняет индексацию».
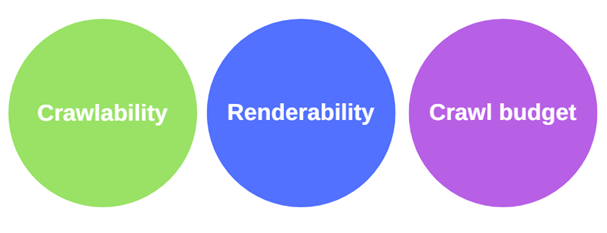
Для того, чтобы понять, сможет ли поисковая система правильно обработать сайт, то есть, обработать его так, как того ожидает создатель сайта, нужно учесть три фактора:
- Возможность сканирования сайта: системы Google должны быть способны просканировать сайт, учитывая его структуру.
- Возможность анализа сайта: системы Google не должны испытывать проблем в ходе анализа сайта с использованием технологий, используемых для формирования его страниц.
- Бюджет сканирования: времени, выделенного Google на обработку сайта, должно хватить для его полноценной индексации.
О клиентском и серверном рендеринге
Говоря о том, может ли Google сканировать и анализировать сайты, использующие JavaScript, нам нужно затронуть две очень важные концепции: рендеринг, или визуализация страниц, на стороне сервера, и на стороне клиента. Эти идеи необходимо понимать каждому специалисту по SEO, который имеет дело с JavaScript.
При традиционном подходе (серверный рендеринг), браузер или робот Googlebot загружают с сервера HTML-код, который полностью описывает страницу. Все необходимые материалы уже готовы, браузеру (или роботу) нужно лишь загрузить HTML и CSS и сформировать готовую к просмотру или анализу страницу. Обычно поисковые системы не испытывают никаких проблем с индексацией сайтов, использующих серверный рендеринг.
Всё большую популярность получает метод визуализации страниц на стороне клиента, который имеет определённые особенности. Эти особенности иногда приводят к проблемам с анализом таких страниц поисковыми системами. Весьма распространена ситуация, когда при первоначальной загрузке данных браузер (или Googlebot) получает пустую HTML-страницу.
Фактически, на такой странице либо вовсе нет данных, подходящих для анализа и индексации, либо их очень мало. Затем в дело вступают JavaScript-механизмы, которые асинхронно загружают данные с сервера и обновляют страницу (изменяя DOM).
Если на вы используете методику визуализации на стороне клиента, вам нужно убедиться в том, что Google в состоянии правильно сканировать и обрабатывать страницы вашего сайта.
JavaScript и ошибки
HTML и JS коренным образом различаются в подходах к обработке ошибок. Единственная ошибка в JavaScript-коде может привести к тому, что Google не сможет проиндексировать страницу.
Позвольте мне процитировать Матиаса Шафера, автора работы «Надёжный JavaScript»: «JS-парсер не отличается дружелюбием. Он совершенно нетерпим к ошибкам. Если он встречает символ, появление которого в определённом месте не ожидается, он немедленно прекращает разбор текущего скрипта и выдаёт SyntaxError. Поэтому единственный символ, находящейся не там, где нужно, единственная опечатка, может привести к полной неработоспособности скрипта.»
Ошибки разработчиков фреймворков
Возможно вы слышали об эксперименте по SEO в применении к JavaScript-сайтам, который провёл Бартош Горалевич, занимающий должность CEO в компании Elephate, для того, чтобы узнать, может ли Google индексировать веб-сайты, созданные с использованием распространённых JS-фреймворков.

В самом начале выяснилось, что Googlebot не в состоянии анализировать страницы, созданные с использованием Angular 2. Это было странно, так как Angular создан командой Google, поэтому Бартош решил выяснить причины происходящего. Вот что он пишет по этому поводу:
«Оказалось, что имелась ошибка в QuickStart Angular 2, в чём-то вроде учебного руководства, посвящённого тому, как готовить к работе проекты, основанные на этом фреймворке. Ссылка на это руководство присутствовала в официальной документации. Было выяснено, что команда Google Angular допустила ошибку, которая была исправлена 26-го апреля 2017 года».
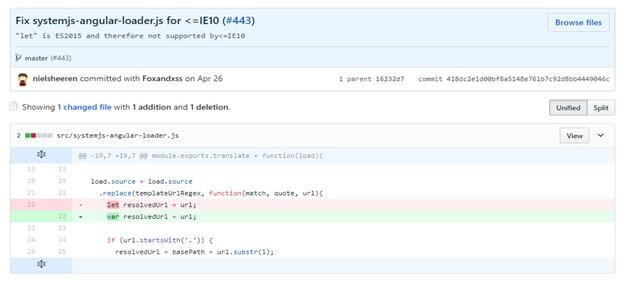
Исправление ошибки привело к возможности нормального индексирования тестового сайта на Angular 2.
Этот пример отлично иллюстрирует ситуацию, когда единственная ошибка может привести к тому, что Googlebot оказывается не в состоянии проанализировать страницу.
Масла в огонь подливает и то, что ошибка была совершена не новичком, а опытным человеком, участвующим в разработке Angular, второго по популярности JS-фреймворка.
Вот ещё один отличный пример, который, по иронии судьбы, снова связан с Angular. В декабре 2017-го Google исключила из индекса несколько страниц сайта Angular.io (веб-сайт, основанный на Angular 2+, на котором применяется технология визуализации на стороне клиента). Почему это произошло? Как вы можете догадываться, одна ошибка в их коде сделала невозможной визуализацию страниц средствами Google и привела к масштабному исключению страниц из индекса. Позже ошибка была исправлена.
Вот как Игорь Минар из Angular.io это объяснил:
«Учитывая то, что мы не меняли проблематичный код в течение 8 месяцев, и мы столкнулись со значительным падением трафика с поисковых систем, начиная примерно с 11 декабря 2017, я полагаю, что за это время что-то изменилось в системе сканирования сайтов, что и привело к тому, что большая часть сайта оказалась исключённой из поискового индекса, что, в свою очередь, стало причиной падения посещаемости ресурса.»
Исправление вышеупомянутой ошибки, препятствующей анализу страниц ресурса Angular.io, было возможным благодаря опытной команде JS-разработчиков, и тому факту, что они реализовали ведение журнала ошибок. После того, как ошибка была исправлена, Google снова смог проиндексировать проблемные страницы.
О сложности сканирования сайтов, построенных с использованием JavaScript
Вот как происходит сканирование и индексирование обычных HTML-страниц. Тут всё просто и понятно:
- Googlebot загружает HTML-файл.
- Googlebot извлекает ссылки из кода страницы, в результате он может параллельно обрабатывать несколько страниц.
- Googlebot загружает CSS-файлы.
- Googlebot отправляет все загруженные ресурсы системе индексирования (Caffeine).
- Caffeine индексирует страницу.
Всё это происходит очень быстро.
Однако процесс усложняется, если работа ведётся с веб-сайтом, основанным на JavaScript:
- Googlebot загружает HTML-файл.
- Googlebot загружает CSS и JS-файлы.
- После этого Googlebot должен использовать Google Web Rendering Service (WRS) (эта система является частью Caffeine) для того, чтобы разобрать, скомпилировать и выполнить JS-код.
- Затем WRS получает данные из внешних API, из баз данных, и так далее.
- После того, как страница собрана, её, в итоге, может обработать система индексирования.
- Только теперь робот может обнаружить новые ссылки и добавить их в очередь сканирования.
Весь этот процесс гораздо сложнее, чем сканирование HTML-сайтов. Во внимание тут нужно принять следующее:
- Разбор, компиляция и выполнение JS — это операции, которые требуют немалых затрат времени.
- В случае с сайтами, на которых интенсивно используется JavaScript, Google приходится ждать до тех пор, пока будут выполнены все вышеописанные шаги прежде чем можно будет проиндексировать содержимое страниц.
- Процесс сборки страницы — это не единственная медленная операция. Это также относится к процессу обнаружения новых ссылок. На сайтах, интенсивно использующих JS, Google обычно не может обнаружить новые ссылки до того, как страница не будет полностью сформирована.

Теперь мне хотелось бы проиллюстрировать проблему сложности JavaScript-кода. Готов поспорить, что 20-50% посетителей вашего сайта просматривают его с мобильного устройства. Знаете ли вы о том, сколько времени занимает разбор 1 Мб JS-кода на мобильном устройстве? По информации Сэма Сакконе из Google, Samsung Galaxy S7 тратит на это примерно 850 мс, а Nexus 5 — примерно 1700 мс! После разбора JS-кода его ещё нужно скомпилировать и выполнить. А на счету — каждая секунда.
Если вы хотите больше узнать о бюджете сканирования, советую почитать материал Барри Адамса «JavaScript and SEO: The Difference Between Crawling and Indexing». SEO-специалистам, имеющим дело с JavaScript, особенно полезными будут разделы «JavaScript = Inefficiency» и «Good SEO is Efficiency». Заодно можете посмотреть и этот материал.
Google и браузер, выпущенный 3 года назад
Для того чтобы понять, почему при сканировании сайтов, использующих JS, у Google могут возникнуть проблемы, стоит поговорить о технических ограничениях Google.
Я уверен, что вы используете самую свежую версию вашего любимого браузера. Однако в Google дело обстоит не так. Тут, для рендеринга веб-сайтов, используется Chrome 41. Этот браузер был выпущен в марте 2015-го года. Ему уже три года! И браузер Google Chrome, и JavaScript за эти годы чрезвычайно сильно развились.
В результате оказывается, что существует множество современных возможностей, которые просто недоступны для робота Googlebot. Вот некоторые из его основных ограничений:
- Chrome 41 лишь частично поддерживает современный синтаксис JavaScript ES6. Например, он не понимает новые языковые конструкции.
- Интерфейсы, вроде IndexedDB и WebSQL, отключены.
- Куки, локальные хранилища и сессионные хранилища очищаются при перезагрузке страницы.
- И, опять же, перед нами браузер, который был выпущен три года назад!
Рассматривая технические ограничения Chrome 41, вы можете проанализировать разницу между Chrome 41 и Chrome 66 (самой свежей версией Chrome на момент написания этого материала).
Теперь, когда вы знаете, что для формирования страниц Google использует Chrome 41, найдите время на то, чтобы загрузить этот браузер и проверить собственные веб-сайты для того, чтобы понять, может ли этот браузер нормально с ними работать. Если нет — загляните в консоль Chrome 41 для того, чтобы попытаться узнать, что может быть причиной ошибок.
Кстати, раз уж заговорили об этом, вот мой материал, посвящённый работе с Chrome 41.
Современные возможности JavaScript и индексирование сайтов
Как быть тому, кто стремится использовать современные возможности JS, но при этом, хочет, чтобы Google нормально индексировал его сайты? На этот вопрос отвечает данный кадр из видео:
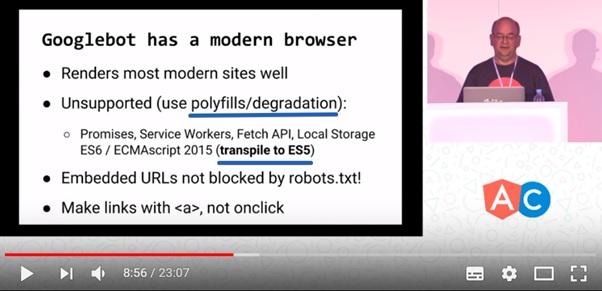
Браузер, применяемый в Google для формирования страниц сайтов, основанных на JS, может правильно обрабатывать сайты, использующие современные возможности JS, однако, разработчикам таких сайтов потребуется приложить для этого некоторые усилия. А именно, использовать полифиллы, создавать упрощённую версию сайта (используя технику постепенной деградации) и выполнять транспиляцию кода в ES5.
Постепенная деградация и полифиллы
Популярность JavaScript росла очень быстро, а теперь это происходит быстрее, чем когда бы то ни было. Однако некоторые возможности JavaScript просто не реализованы в устаревших браузерах (так уж совпало, что Chrome 41 — это как раз такой браузер). Как результат, нормальный рендеринг сайтов, использующих современные возможности JS, в таких браузерах невозможен. Однако, веб-мастера могут это обойти, используя технику постепенной деградации.
Если вам хочется реализовать некоторые современные возможности JS, которые поддерживают лишь немногие браузеры, в таком случае вам нужно обеспечить использование упрощённой версии вашего веб-сайта в других браузерах. Помните о том, что версию Chrome, которую использует Googlebot, определённо, нельзя считать современной. Этому браузеру уже три года.
Выполняя анализ браузера, вы можете в любое время проверить, поддерживает он некую возможность или нет. Если он эту возможность не поддерживает, вы, вместо неё, должны предложить нечто такое, что подходит для этого браузера. Эта замена и называется полифиллом.
Кроме того, если нужно, чтобы сайт мог быть обработан поисковыми роботами Google, вам совершенно необходимо использовать транспиляцию JS-кода в ES5, то есть, преобразование тех конструкций JS, которые не понимает Googlebot, в конструкции, понятные ему.
Например, когда транспилятор встречает выражение let x=5 (большинство старых браузеров эту конструкцию не поймут), он преобразует его в выражение var x=5 (эта конструкция понятна всем браузерам, в том числе и Chrome 41, который играет для нас особую роль).
Если вы используете современные возможности JavaScript и хотите, чтобы ваши сайты правильно обрабатывались поисковыми роботами Google, вам, определённо, стоит использовать транспиляцию в ES5 и полифиллы.
Тут я стараюсь объяснить всё это так, чтобы было понятно не только JS-разработчикам, но и, например, SEO-специалистам, которые далеки от JavaScript. Однако, в детали мы не вдаёмся, поэтому, если вы чувствуете потребность лучше разобраться в том, что такое полифиллы — взгляните на этот материал.
Googlebot — это не настоящий браузер
Когда вы путешествуете по интернету, ваш браузер (Chrome, Firefox, Opera, или любой другой) загружает ресурсы (изображения, скрипты, стили) и показывает вам страницы, из всего этого собранные.
Однако, Googlebot работает не так, как обычный браузер. Его цель — проиндексировать всё, до чего он может дотянуться, загружая при этом только самое важное.
Всемирная паутина — это огромное информационное пространство, поэтому Google оптимизирует систему сканирования с учётом производительности. Именно поэтому Googlebot иногда не посещает все страницы, на посещение которых рассчитывает веб-разработчик.
Ещё важнее то, что алгоритмы Google пытаются выявить ресурсы, которые необходимы с точки зрения формирования страницы. Если какой-то ресурс выглядит, с этих позиций, не особенно важным, он попросту может быть не загружен роботом Googlebot.
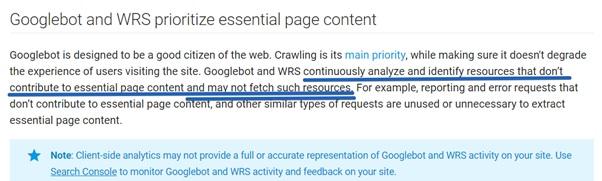
В результате может оказаться так, что сканер не станет загружать некоторые из ваших JS-файлов, так как его алгоритмы решили, что, с точки зрения формирования страницы, они не важны. То же самое может произойти и из-за проблем с производительностью (то есть, в ситуации, когда выполнение скрипта занимает слишком много времени).
Хочу отметить, что Том Энтони заметил одну интересную особенность в поведении робота Googlebot. Когда используется JS-функция
setTimeout, настоящий браузер получает указание подождать определённое время. Однако, Googlebot не ждёт, он выполняет всё немедленно. Этому не стоит удивляться, так как цель роботов Google заключается в том, чтобы проиндексировать весь интернет, поэтому их оптимизируют с учётом производительности.Правило пяти секунд
Многие эксперименты в области SEO указывают на то, что, в целом, Google не может ждать окончания выполнения скрипта, который выполняется более 5 секунд. Мои эксперименты, похоже, это подтверждают.
Не принимайте этот как должное: добейтесь того, чтобы ваши JS-файлы загружались и завершали работу менее чем за 5 секунд.
Если ваш веб-сайт загружается по-настоящему медленно, вы можете многое потерять. А именно:
- Посетителям сайта будет некомфортно с ним работать, они могут его покинуть.
- У Google могут возникнуть проблемы с анализом страниц.
- Это может замедлить процесс сканирования сайта. Если страницы медленны, Google может решить, что его роботы замедляют ваш сайт и снизить частоту сканирования. Подробнее об этом можно почитать здесь.
Постарайтесь сделать ваш сайт не слишком тяжёлым, обеспечьте высокую скорость реакции сервера, а так же убедитесь в том, что сервер нормально работает под высокой нагрузкой (используйте для этого, например, Load Impact). Не усложняйте жизнь роботам Google.
Обычная ошибка в плане производительности, которую совершают разработчики, заключается в том, что они помещают код всех компонентов страницы в единственный файл. Но если пользователь переходит на домашнюю страницу проекта, ему совершенно не нужно загружать то, что относится к разделу, предназначенному для администратора сайта. То же самое справедливо и в применении к поисковым роботам.
Для решения проблем с производительностью рекомендуется найти соответствующее руководство по применяемому JS-фреймворку. Его стоит изучить и выяснить, что можно сделать для ускорения сайта. Кроме того, советую почитать этот материал.
Как взглянуть на интернет глазами Google?
Если вы хотите взглянуть на интернет, и, особенно, на свой веб-сайт, глазами роботов Google, вы можете воспользоваться одним из двух подходов:
- Используйте инструменты Fetch (сканирование) и Render (отображение) из Google Search Console (очевидно!). Но не полагайтесь на них на 100%. Настоящий Googlebot может иметь таймауты, отличающиеся от тех, которые предусмотрены в Fetch и Render.
- Используйте Chrome 41. Как уже было сказано, достоверно известно, что Google использует для рендеринга загружаемых роботами страниц Chrome 41. Загрузить этот браузер можно, например, здесь. Использование Chrome 41 имеет множество преимуществ перед применением загрузки страниц с использованием Google Search Console:
- Благодаря использованию Chrome 41 вы можете видеть журнал ошибок, выводимый в консоль браузера. Если вы столкнётесь с ошибками в этом браузере, вы можете быть практически полностью уверены в том, что и Googlebot столкнётся с теми же ошибками.
- Инструменты Fetch и Render не покажут вам результаты отрисовки DOM, а браузер покажет. Используя Chrome 41 вы можете проверить, увидит ли Googlebot ваши ссылки, содержимое панелей, и так далее.
Вот ещё один вариант: инструмент Rich Results Test (проверка расширенных результатов). Я не шучу — это средство может показать вам, как Google интерпретирует вашу страницу, демонстрируя результаты визуализации DOM, а это очень полезно. Google планирует добавить результаты рендеринга DOM в инструменты Fetch и Render. Так как до сих пор это не сделано, Джон Мюллер советует применять для этого Rich Results. Сейчас не вполне понятно, следует ли Rich Results тем же правилам рендеринга, что и система индексирования Google. Пожалуй, для того, чтобы это выяснить, стоит провести дополнительные эксперименты.
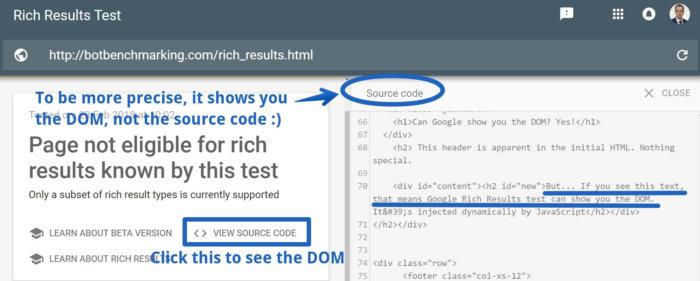
Инструменты Fetch и Render и проверка тайм-аутов системы индексирования
Инструменты Fetch и Render могут лишь сообщить вам о том, имеет ли Google техническую возможность сформировать анализируемую страницу. Однако не полагайтесь на них, когда речь заходит о тайм-аутах. Я часто сталкивался с ситуацией, когда Fetch и Render были способны вывести страницу, но система индексирования Google не могла проиндексировать эту страницу из-за используемых этой системой тайм-аутов. Вот доказательства этого утверждения.
Я провёл простой эксперимент. Первый JS-файл, включённый в анализируемую страницу, загружался с задержкой в 120 секунд. При этом технической возможности избежать этой задержки не было. Nginx-сервер был настроен на двухминутное ожидание перед выдачей этого файла.
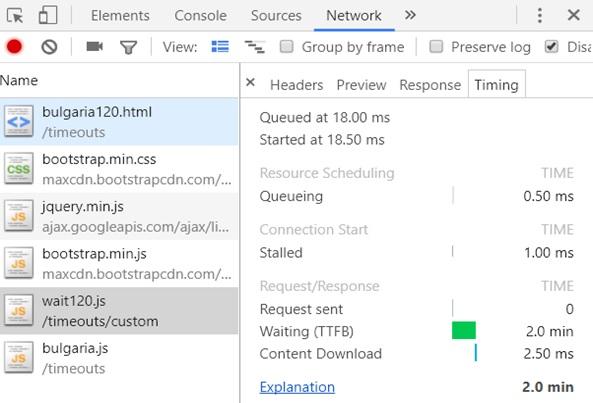
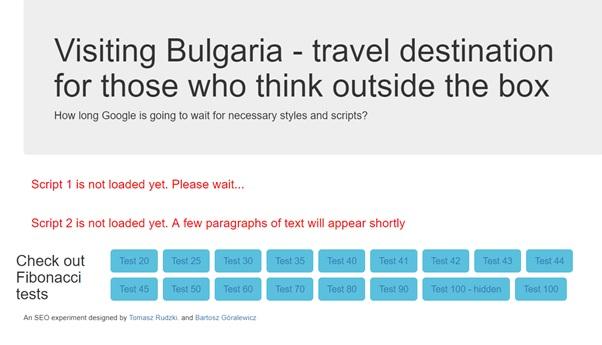
Оказалось, что инструменты Fetch и Render ждали загрузки скрипта 120 секунд (!), после чего страница выводилась правильно.
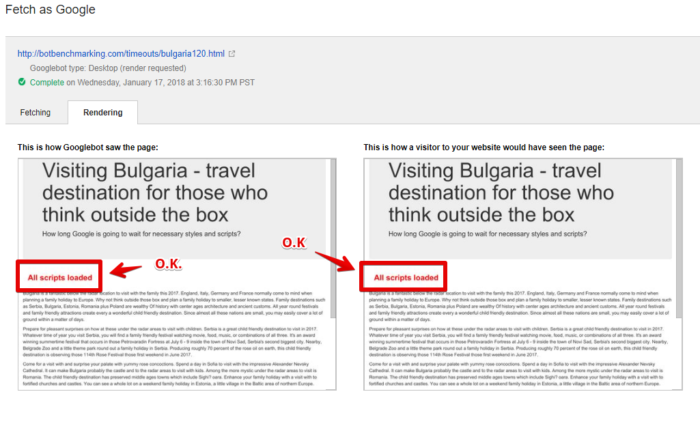
Однако система индексирования оказалась не такой терпеливой.
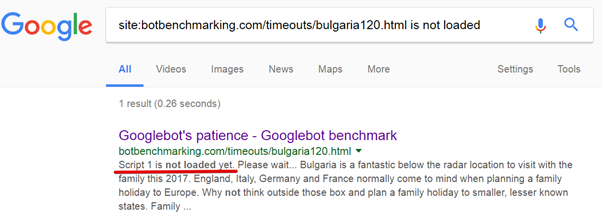
Здесь видно, что система индексирования Google просто не стала дожидаться загрузки первого скрипта и проанализировала страницу без учёта результатов работы этого скрипта.
Как видите, Google Search Console — это отличный инструмент. Однако пользоваться им следует только для проверки технической возможности анализа страницы роботами Google. Не используйте это средство для того, чтобы проверить, дождётся ли система индексирования загрузки ваших скриптов.
Анализ кэша Google и сайты, интенсивно использующие JavaScript
Многие специалисты в области SEO применяли кэш Google для поиска проблем с анализом страниц. Однако эта методика не подходит для сайтов, интенсивно использующих JS, так как сам по себе кэш Google представляет собой исходный HTML, который Googlebot загружает с сервера (обратите внимание — это многократно подтверждено Джоном Мюллером из Google).

Просматривая содержимое кэша, вы видите, как ваш браузер интерпретирует HTML, собранный средствами Googlebot. Это не имеет никакого отношения к формированию страницы для целей индексирования. Если вы хотите узнать подробности о кэше Google — взгляните на этот материал.
Использование команды site вместо анализа кэша Google
В настоящий момент один из лучших способов проверки того, были ли какие-то данные проиндексированы Google, заключается в использовании команды site.
Для того чтобы это сделать, просто скопируйте какой-нибудь фрагмент текста с вашей страницы и введите в поисковике Google команду следующего вида:
site:{your website} "{fragment}"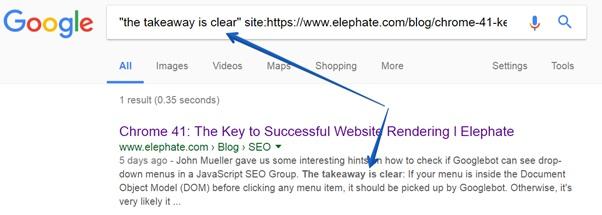
Если вы, в ответ на такую команду, увидите в поисковой выдаче искомый фрагмент, это значит, что данные были проиндексированы.
Тут хотелось бы отметить, что подобные поисковые запросы рекомендуется выполнять в анонимном режиме. Несколько раз у меня были случаи, когда редакторы сайта меняли тексты, и по какой-то причине команда
site сообщала о том, что проиндексированы были старые тексты. После переключения в анонимный режим браузера эта команда стала выдавать правильный результат.Просмотр HTML-кода страницы и аудит сайтов, основанных на JS
HTML-файл представляет собой исходную информацию, которая используется браузером для формирования страницы. Я предполагаю, что вам известно, что такое HTML-документ. Он содержит сведения о разметке страницы — например, о разбиении текста на абзацы, об изображениях, ссылках, он включает в себя команды для загрузки JS и CSS-файлов.
Посмотреть HTML-код страницы в браузере Google Chrome можно, вызвав щелчком правой кнопки мыши контекстное меню и выбрав команду View page source (просмотр кода страницы).
Однако, воспользовавшись этим режимом просмотра кода страницы, вы не увидите динамического содержимого (то есть тех изменений, которые внесены в страницу средствами JavaScript).
Вместо этого следует анализировать DOM. Сделать это можно с помощью команды того же меню Inspect Element (просмотреть код).
Различия между исходным HTML-кодом, полученным с сервера, и DOM
Исходный HTML-код, полученный с сервера (то, что выводится по команде View page source) — это нечто вроде кулинарного рецепта. Он предоставляет информацию о том, какие ингредиенты входят в состав некоего блюда, содержит инструкции по приготовлению. Но рецепт — это не готовое блюдо.
DOM (команда Inspect Element) — это блюдо, приготовленное по «HTML-рецепту». В самом начале браузер загружает «рецепт», потом занимается приготовлением блюда, и уже в итоге, после того, как страница полностью загружена, перед нами появляется нечто «съедобное».
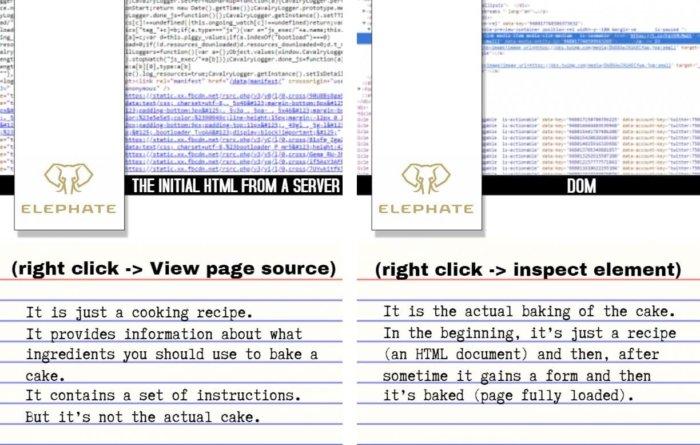
Обратите внимание на то, что если Google не удаётся сформировать страницу на основе загруженного HTML-кода, он может просто проиндексировать этот исходный HTML-код (который не содержит динамически обновляемого содержимого). Подробности об этом можно найти в данном материале Барри Адамса. Барри, кроме того, даёт советы, касающиеся того, как быстро сравнить исходный HTML и DOM.
Итоги
В этом материале мы поговорили о том, как Google обрабатывает сайты, которые созданы с применением JavaScript-технологий. В частности, огромное значение имеет то, что для анализа страниц в Google используется Chrome 41. Это накладывает определённые ограничения на применение JavaScript.
Во второй части перевода этого материала речь пойдёт о том, на что стоит обратить внимание для того, чтобы JS-сайты нормально индексировались поисковыми системами. Там же будут подняты ещё некоторые темы, касающиеся SEO и JavaScript.
Источник: habrahabr.ru