R — значит регрессия
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-03-17 17:27
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.
Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость между переменными y и x, возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения называется регрессией y по x.
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция такая, что сумма квадратов разностей минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений вокруг регрессии является дисперсия.
k— число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x.
Линейная регрессия
Уравнения линейной регрессии можно записать в виде
В матричном виде это выгладит
- y — зависимая переменная;
- x — независимая переменная;
- ? — коэффициенты, которые необходимо найти с помощью МНК;
- ? — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;
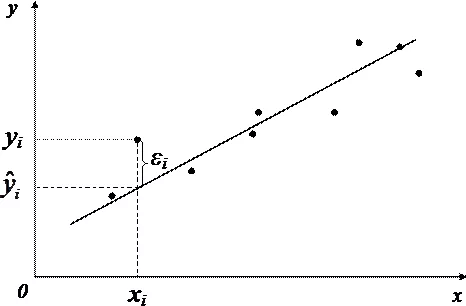
Случайная величина может быть интерпретирована как сумма из двух слагаемых:
- — полная дисперсия (TSS).
- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
Еще одно ключевое понятие — коэффициент корреляции R2.
Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая ?i обладает одинаковой и конечной дисперсией ?2 и не коррелирует с другой ?i. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии
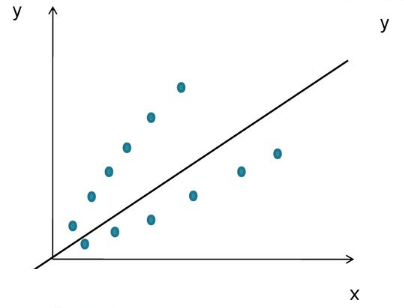
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.
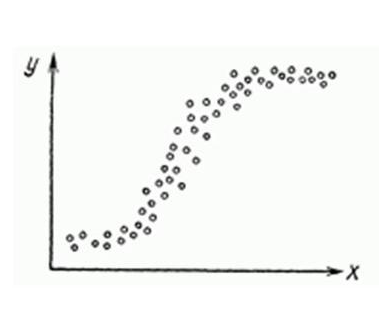
Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ? d ? 4). Если автокорреляции нет, то значения критерия d?2, при позитивной автокорреляции d?0, при отрицательной — d?4.
- Неоднородность дисперсии — Тест Уайта, , при нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
В этой формуле — коэффициент взаимной детерминации между и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма
ln. - Таким же способом возможно решить проблему неоднородной дисперсии, с помощью
ln, илиsqrtпреобразований зависимой переменной, либо же используя взвешенный МНК. - Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
> hist <- read.table("~/habr_hist.txt", header=TRUE) > histpoints reads comm faves fb bytes 31 11937 29 19 13 10265 93 34122 71 98 74 14995 32 12153 12 147 17 22476 30 16867 35 30 22 9571 27 13851 21 52 46 18824 12 16571 44 149 35 9972 18 9651 16 86 49 11370 59 29610 82 29 333 10131 26 8605 25 65 11 13050 20 11266 14 48 8 9884 ...- points — Рейтинг статьи
- reads — Число просмотров.
- comm — Число комментариев.
- faves — Добавлено в закладки.
- fb — Поделились в социальных сетях (fb + vk).
- bytes — Длина в байтах.
Проверка мультиколлинеарности.
> cor(hist) points reads comm faves fb bytes points 1.0000000 0.5641858 0.61489369 0.24104452 0.61696653 0.19502379 reads 0.5641858 1.0000000 0.54785197 0.57451189 0.57092464 0.24359202 comm 0.6148937 0.5478520 1.00000000 -0.01511207 0.51551030 0.08829029 faves 0.2410445 0.5745119 -0.01511207 1.00000000 0.23659894 0.14583018 fb 0.6169665 0.5709246 0.51551030 0.23659894 1.00000000 0.06782256 bytes 0.1950238 0.2435920 0.08829029 0.14583018 0.06782256 1.00000000Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
Теперь собственно сама модель, используем функцию lm.
regmodel <- lm(points ~., data = hist) summary(regmodel) Call: lm(formula = points ~ ., data = hist) Residuals: Min 1Q Median 3Q Max -26.920 -9.517 -0.559 7.276 52.851 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.029e+01 7.198e+00 1.430 0.1608 reads 8.832e-05 3.158e-04 0.280 0.7812 comm 1.356e-01 5.218e-02 2.598 0.0131 * faves 2.740e-02 3.492e-02 0.785 0.4374 fb 1.162e-01 4.691e-02 2.476 0.0177 * bytes 3.960e-04 4.219e-04 0.939 0.3537 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 16.65 on 39 degrees of freedom Multiple R-squared: 0.5384, Adjusted R-squared: 0.4792 F-statistic: 9.099 on 5 and 39 DF, p-value: 8.476e-06 В первой строке мы задаем параметры линейной регрессии. Строка points ~. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points ~ reads, набор переменных — points ~ reads + comm.
Перейдем теперь к расшифровке полученных результатов.
Intercept— Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, илиintercept.R-squared— Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.Adjusted R-squared— Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуманскорректированный коэффициент детерминации.F-statistic— Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.t value— Критерий, основанный наt распределении Стьюдента. Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что приt > 2фактор является значимым для модели.p value— Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значениеp valueниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
> hist$fb = hist$fb^(4/7) > hist$comm = hist$comm^(2/3)Проверим значения параметров линейной регрессии.
> regmodel <- lm(points ~., data = hist) > summary(regmodel) Call: lm(formula = points ~ ., data = hist) Residuals: Min 1Q Median 3Q Max -22.972 -11.362 -0.603 7.977 49.549 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 2.823e+00 7.305e+00 0.387 0.70123 reads -6.278e-05 3.227e-04 -0.195 0.84674 comm 1.010e+00 3.436e-01 2.938 0.00552 ** faves 2.753e-02 3.421e-02 0.805 0.42585 fb 1.601e+00 5.575e-01 2.872 0.00657 ** bytes 2.688e-04 4.108e-04 0.654 0.51677 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 16.21 on 39 degrees of freedom Multiple R-squared: 0.5624, Adjusted R-squared: 0.5062 F-statistic: 10.02 on 5 and 39 DF, p-value: 3.186e-06 Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми, F-статистика выросла, так же как и скорректированный коэффициент детерминации.
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
> dwtest(hist$points ~., data = hist) Durbin-Watson test data: hist$points ~ . DW = 1.585, p-value = 0.07078 alternative hypothesis: true autocorrelation is greater than 0И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
> bptest(hist$points ~., data = hist) studentized Breusch-Pagan test data: hist$points ~ . BP = 6.5315, df = 5, p-value = 0.2579В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
Использованные материалы
- Beginners Guide to Regression Analysis and Plot Interpretations
- Методы корреляционного и регрессионного анализа
- Кобзарь А. И. Прикладная математическая статистика. — М.: Физматлит, 2006.
- William H. Green Econometric Analysis
Источник: habrahabr.ru