Классификация музыкальных композиций по исполнителям с помощью Скрытых Марковских Моделей
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-03-19 13:33

После знакомства с этими возможностями появилось желание опробовать этот алгоритм распознавания в музыке. Так родилась идея задачи классификации музыкальных композиций по исполнителям. О попытках, какой-то магии и результатах будет рассказано в этом посте.
Мотивация
Желание познакомиться на практике со скрытыми марковскими моделями зародилось давно, и в прошлом году мне удалось привязать их практическое использование с курсовым проектом в магистратуре.
В течение предпроектного гугления была найдена интересная статья, повествующая об использовании HMM для классификации фолк музыки Ирландии, Германии и Франции. Используя большой архив песен (тысячи песен), авторы статьи пытаются выявить существование статистической разницы между композициями разных народов.
Во время изучения библиотек с HMM наткнулся на код из книги Python ML Cookbook, где на примере распознавания нескольких простых слов, использовалась библиотека hmmlearn, которую и решено было опробовать.
Постановка задачи
В наличии песни нескольких музыкальных исполнителей. Задача состоит в обучении классификатора, основанного на HMM, правильному распознаванию авторов поступающих в него песен.
Песни представлены в формате ".wav". Количество песен для разных групп разное. Качество, длительность композиций тоже различаются.
Теория
Для понимания работы алгоритма (какие параметры в каком обучении участвуют) необходимо хотя бы поверхностно ознакомиться с теорией мел-кепстральных коэффициентов и скрытых марковских моделей. Более детальную информацию можно получить в статьях по MFCC и HMM.
MFCC — это представление сигнала, грубо говоря, в виде особого спектра, из которого с помощью различных фильтраций и преобразований удалены незначительные для человеческого слуха компоненты. Спектр носит кратковременный характер, то есть изначально сигнал делится на пересекающиеся отрезки по 20-40 мс. Предполагается, что на таких отрезках частоты сигнала не меняются слишком сильно. И уже на этих отрезках и считаются волшебные коэффициенты.
Есть сигнал

Из него берутся отрезки по 25 мс

И для каждого из них рассчитываются мел-кепстральные коэффициенты

Преимущество этого представления в том, что для распознавания речи достаточно брать около 16 коэффициентов на каждый фрейм вместо сотен или тысяч, в случае обычного преобразования Фурье. Экспериментальным путем выяснено, что для выделения этих коэффициентов в песнях лучше брать по 30-40 компонент.
Для общего понимания работы скрытых марковских моделей можно посмотреть и описание на вики.
Смысл их в том, что есть неизвестный набор скрытых состояний , проявление которых в какой-то последовательности, определяемой вероятностями , с некоторыми вероятностями приводит к набору наблюдаемых результатов .
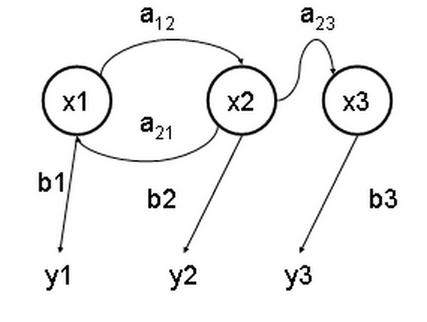
В качестве наблюдаемых результатов в нашем случае выступают mfcc для каждого фрейма.
Алгоритм Баума-Велша (частный случай более известного EM-алгоритма) используется для нахождения неизвестных параметров HMM. Именно он и занимается обучением модели.
Реализация
Приступим, наконец, к коду. Полная версия доступна здесь.
Для расчета MFCC была выбрана библиотека librosa. Также можно использовать библиотеку python_speech_features, в которой в отличие от librosa реализованы только функции, необходимые для расчета мел-кепстральных коэффициентов.
Песни будем принимать в формате ".wav". Ниже представлен функция для расчета MFCC, принимающая на вход имя ".wav" файла.
def getFeaturesFromWAV(self, filename): audio, sampling_freq = librosa.load( filename, sr=None, res_type=self._res_type) features = librosa.feature.mfcc( audio, sampling_freq, n_mfcc=self._nmfcc, n_fft=self._nfft, hop_length=self._hop_length) if self._scale: features = sklearn.preprocessing.scale(features) return features.T На первой строке проходит обычная загрузка ".wav" файла. Стерео файл приводится к одноканальному формату. librosa позволяет проводить разный ресемплинг, я остановился на
res_type=’scipy’. На расчет признаков я посчитал нужным указать три основных параметра:
n_mfcc — количество мел-кепстральных коэффициентов, n_fft — число точек для быстрого преобразования Фурье, hop_length — число сэмплов для фреймов (к примеру, 512 сэмплов для 22кГ и выдаст примерно 23мс).Масштабирование — шаг необязательный, но с ним мне удалось сделать классификатор более устойчивым.
Перейдем к классификатору. hmmlearn оказалась неустойчивой библиотекой, в которой с каждым обновлением что-то ломается. Тем не менее, ее совместимость с scikit не может не радовать. На данный момент (0.2.1), Hidden Markov Models with Gaussian emissions — наиболее рабочая модель.
Отдельно хочется отметить следующие параметры модели.
self._hmm = hmm.GaussianHMM(n_components=hmmParams.n_components, covariance_type=hmmParams.cov_type, n_iter=hmmParams.n_iter, tol=hmmParams.tol) Параметр
n_components — определяет число скрытых состояний. Относительно неплохие модели можно строить, используя 6-8 скрытых состояний. Обучаются они довольно быстро: 10 песен занимает порядка 7 минут на моем Core i5-7300HQ 2.50GHz. Но для получения более интересных моделей я предпочел использовать около 20 скрытых состояний. Пробовал больше, но на моих тестах результаты несильно менялись, а время обучения увеличилось до нескольких дней при том же количестве песен.Остальные параметры отвечают за сходимость EM-алгоритма, ограничивая число итераций, точность и определяя тип ковариационных параметров состояний.
hmmlearn используется для обучения без учителя. Поэтому процесс обучения строится следующим образом. Для каждого класса обучается своя модель. Далее тестовый сигнал прогоняется через каждую модель, где по нему рассчитывается логарифмическая вероятность
score каждой модели. Класс, которому соответствует модель, выдавшая наибольшую вероятность, и является владельцем этого тестового сигнала.Обучение в коде одной модели выглядит так:
featureMatrix = np.array([]) for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')]: filepath = os.path.join(subfolder, filename) features = self.getFeaturesFromWAV(filepath) featureMatrix = np.append(featureMatrix, features, axis=0) if len( featureMatrix) != 0 else features hmm_trainer = HMMTrainer(hmmParams=self._hmmParams) hmm_trainer.train(featureMatrix) Код бегает по папке
subfolder находит все ".wav" файлы, и для каждой из них считает MFCC, которые в последствии просто добавляет в матрицу признаков. В матрице признаков строка соответствует фрейму, столбец соответствует номеру коэффициента из MFCC.После заполнения матрицы создается скрытая марковская модель для этого класса, и признаки передаются в EM-алгоритм для обучения.
Классификация выглядит так.
features = self.getFeaturesFromWAV(filepath) #label is the name of class corresponding to model scores = {} for hmm_model, label in self._models: score = hmm_model.get_score(features) scores[label] = score similarity = sorted(scores.items(), key=lambda t: t[1], reverse=True) Бродим по всем моделям и считаем логарифмические вероятности. Получаем сортированный по вероятностям набор классов. Первый элемент и покажет, кто наиболее вероятный исполнитель данной песни.
Результаты и улучшения
В обучающую выборку были выбраны песни семи исполнителей: Anathema, Hollywood Undead, Metallica, Motorhead, Nirvana, Pink Floyd, The XX. Количество песен для каждой из них, как и сами песни, выбирались из соображений, какие именно тесты хочется провести.
К примеру, стиль группы Anathema сильно менялся в течение их карьеры, начиная с тяжелого дум-метала и заканчивая спокойным прогрессивным роком. Решено было композиции из первого альбома отправить в тестовую выборку, а более в обучение — более мягкие песни.
Anathema:
Deep
Pressure
Untouchable Part 1
Lost Control
Underworld
One Last Goodbye
Panic
A Fine Day To Exit
Judgement
Hollywood Undead:
Been To Hell
S.C.A.V.A
We Are
Undead
Glory
Young
Coming Back Down
Metallica:
Enter Sandman
Nothing Else Matters
Sad But True
Of Wolf And Man
The Unforgiven
The God That Failed
Wherever I May Room
My Friend Of Misery
Don't Tread On Me
The Struggle Within
Through The Never
Motorhead:
Victory Or Die
The Devil.mp3
Thunder & Lightning
Electricity
Fire Storm Hotel
Evil Eye
Shoot Out All Of Your Lights
Nirvana:
Sappy
About A Girl
Something In The Way
Come As You Are
Endless Nameless
Heart Shaped Box
Lithium
Pink Floyd:
Another Brick In The Wall pt 1
Comfortably Numb
The Dogs Of War
Empty Spaces
Time
Wish You Were Here
Money
On The Turning Away
The XX:
Angels
Fiction
Basic Space
Crystalised
Fantasy
Unfold
Master Of Puppets to Metallica (True)
Master Of Puppets (Cut 00:00 — 00:35) to Metallica (True)
Master Of Puppets (Cut 00:20 — 00:55) to Anathema (False, Metallica)
The Unforgiven (Cut 01:10 — 01:35) to Anathema (False, Metallica)
Heart Shaped Box to Nirvana (True)
Heart Shaped Box (Cut 01:00 — 01:40) to Hollywood Undead (False, Nirvana)
featureMatrix = np.array([]) for filename in [x for x in os.listdir(subfolder) if x.endswith('.wav')]: filepath = os.path.join(subfolder, filename) features = self.getFeaturesFromWAV(filepath) featureMatrix = np.append(featureMatrix, features, axis=0) if len( featureMatrix) != 0 else features hmm_trainer = HMMTrainer(hmmParams=self._hmmParams) np.random.shuffle(featureMatrix) #shuffle it hmm_trainer.train(featureMatrix) Ниже представлены результаты теста модели с параметрами: 20 скрытых состояний, 40 MFCC, с маcштабированием компонент и shuffle.
The Man Who Sold The World to Anathema (False, Nirvana)
We Are Mot?rhead to Motorhead (True)
Master Of Puppets to Metallica (True)
Empty to Anathema (True)
Keep Talking to Pink Floyd (True)
Tell Me Who To Kill to Motorhead (True)
Smells Like Teen Spirit to Nirvana (True)
Orion (Instrumental) to Metallica (True)
The Silent Enigma to Anathema (True)
Nirvana — School to Nirvana (True)
A Natural Disaster to Anathema (True)
Islands to The XX (True)
High Hopes to Pink Floyd (True)
Have A Cigar to Pink Floyd (True)
Lovelorn Rhapsody to Pink Floyd (False, Anathema)
Holier Than Thou to Metallica (True)
Master Of Puppets to Metallica (True)
Master Of Puppets (Cut 00:00 — 00:35) to Metallica (True)
Master Of Puppets (Cut 00:20 — 00:55) to Metallica (True)
The Unforgiven (Cut 01:10 — 01:35) to Metallica (True)
Heart Shaped Box to Nirvana (True)
Heart Shaped Box (Cut 01:00 — 01:40) to Nirvana (True)
Заключение
Построенный классификатор на основе скрытых марковских моделей показывает удовлетворительные результаты, правильно определяя исполнителей для большинства композиций.
Весь код доступен здесь. Кому интересно, может сам попробовать обучить модели на своих композициях. По результатам можно также попытаться выявить общее в музыке разных групп.
Для быстрого теста на обученных композициях, можно посмотреть на крутящийся на Heroku сайт (принимает на вход небольшие ".wav" файлы). Список композиций, на которых обучалась модель с сайта, представлен выше в пункте выше под спойлером.
Источник: habrahabr.ru