Алгоритмы подсказки слов в телефонной клавиатуре vs. Защита персональных данных
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-02-13 14:36
искусственный интеллект, реализация нейронной сети, анализ социальных сетей

Языковые модели
В виртуальных клавиатурах мобильных телефонов повсеместно используются алгоритмы подсказки слов по первым введённым буквам и автоматического исправления опечаток в них. Функция нужная, так как печатать на телефоне неудобно. Однако она часто раздражает пользователей своей «глупостью».
В основе алгоритма подсказок лежит языковая модель, предсказывающая вероятность следующего слова в тексте относительно предыдущих слов. Обычно модель строится по статистике n-грамм — последовательностей из n слов, которые часто соседствуют друг с другом. При таком подходе хорошо угадываются только короткие распространённые словосочетания.
Нейронные сети с задачей предсказания слов справляются лучше. Например, нейросетевой алгоритм в состоянии понять, что после слов «Linus is the best» должно идти слово «programmer», а после «Shakespair is the best» — «writer». У n-граммной модели для этой задачи, скорее всего, не хватит статистики: даже если в обучающих текстах встречалась информация о Торвальдсе и Шекспире, скорее всего она не была сформулирована ровно этими же словами в том же порядке.
О рекуррентных нейронных сетях для языковых моделей пишут много. Например, с помощью простого туториала по TensorFlow можно посмотреть, при каких условиях какие слова будут предсказываться.
Важный момент: предсказания модели сильно зависят от обучающей выборки. На скриншотах ниже показаны примеры подсказок для обычной, профессиональной и неформальной лексик.
| Обычная модель | Молекулярная биология | Неформальная лексика |
|---|---|---|
 |  | 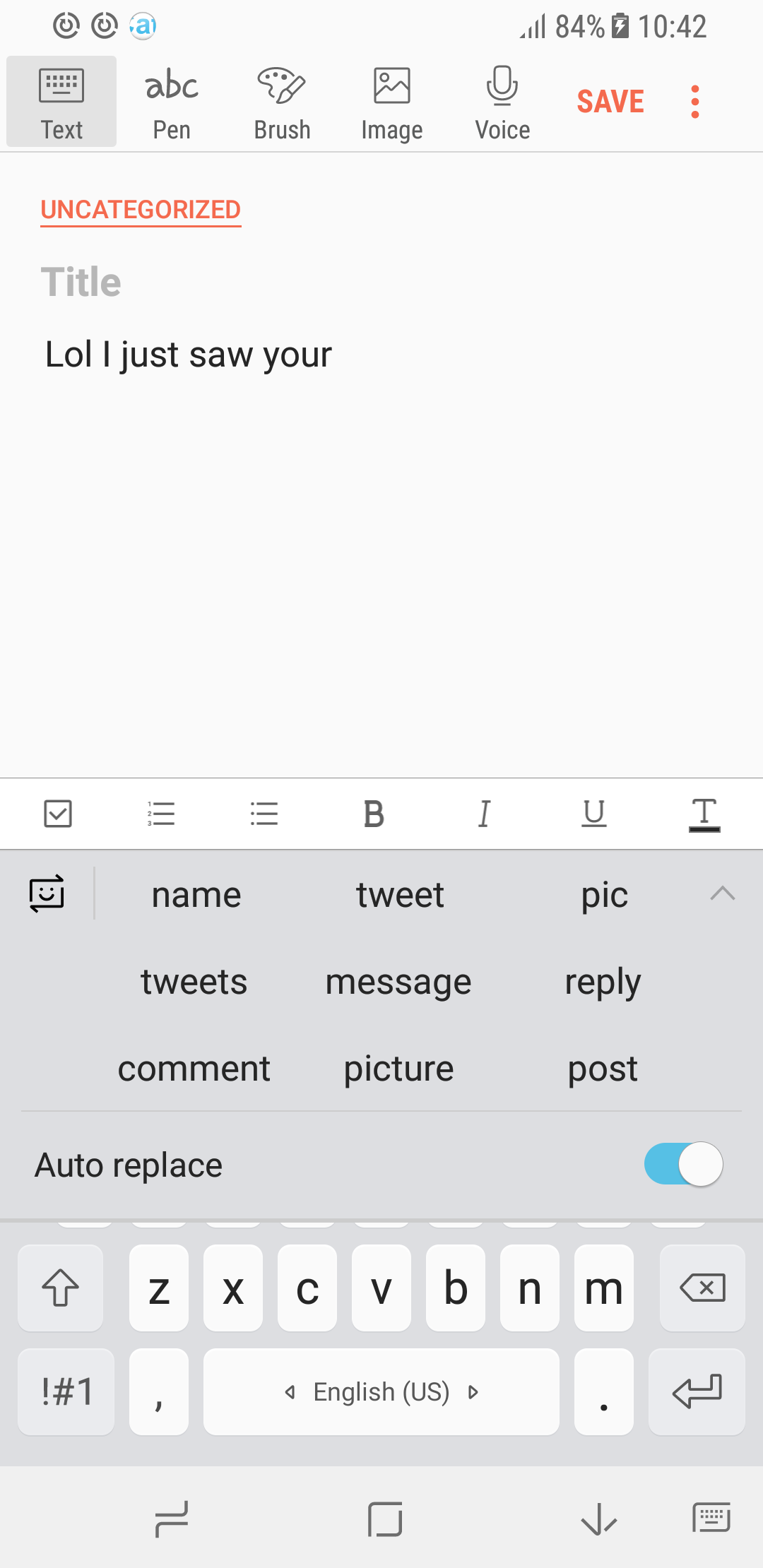 |
Ещё пример. Мы собрали большой объём текстов с форумов и обсуждений в Интернете на русском языке и обучили на них рекуррентную нейронную сеть. Из полученных предсказаний языковой модели хорошо выделяется портрет типичного пользователя рунета… хотя, скорее, это типичная пользовательница.
| Случай 1 | Случай 2 |
|---|---|
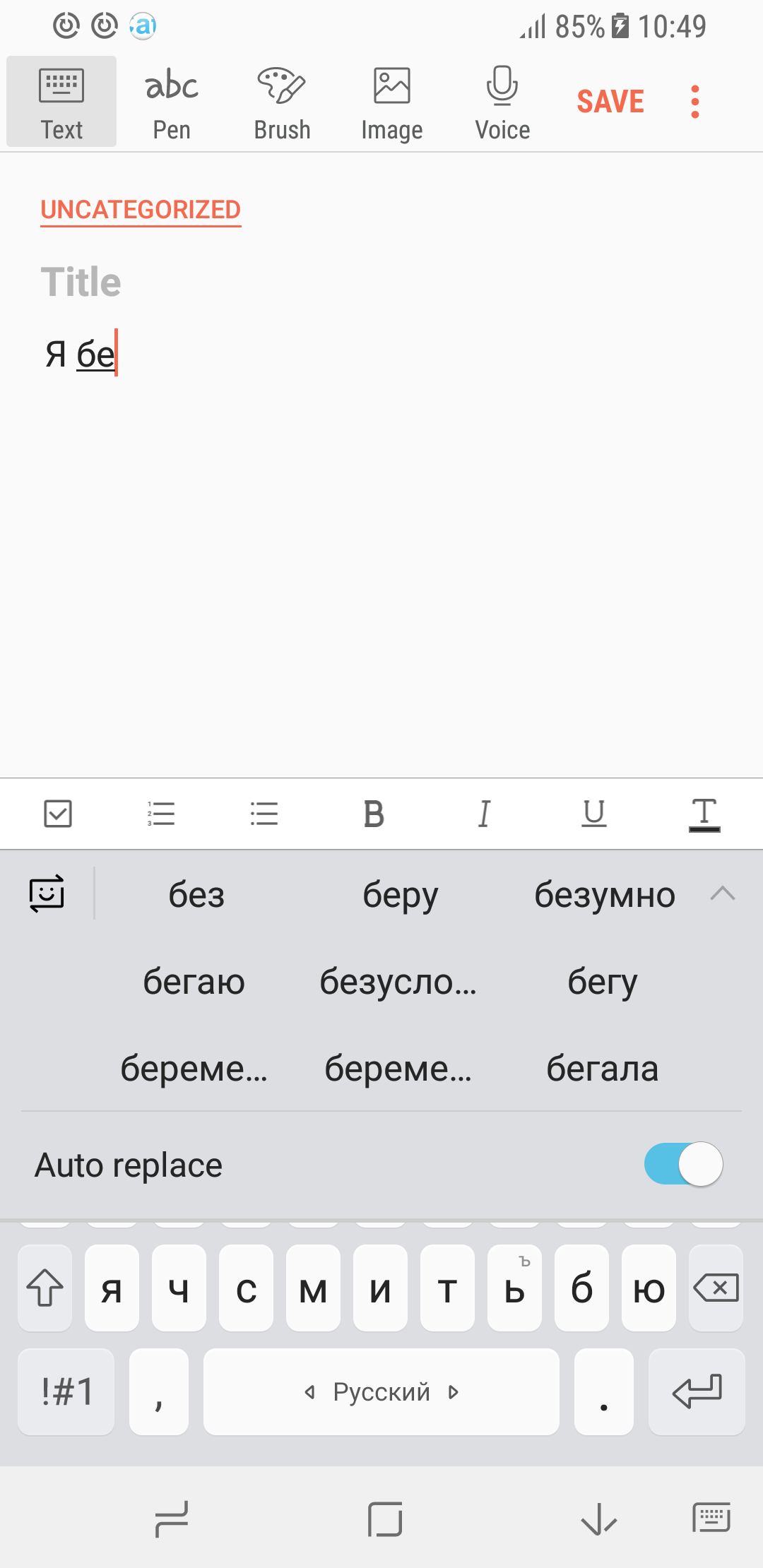 | 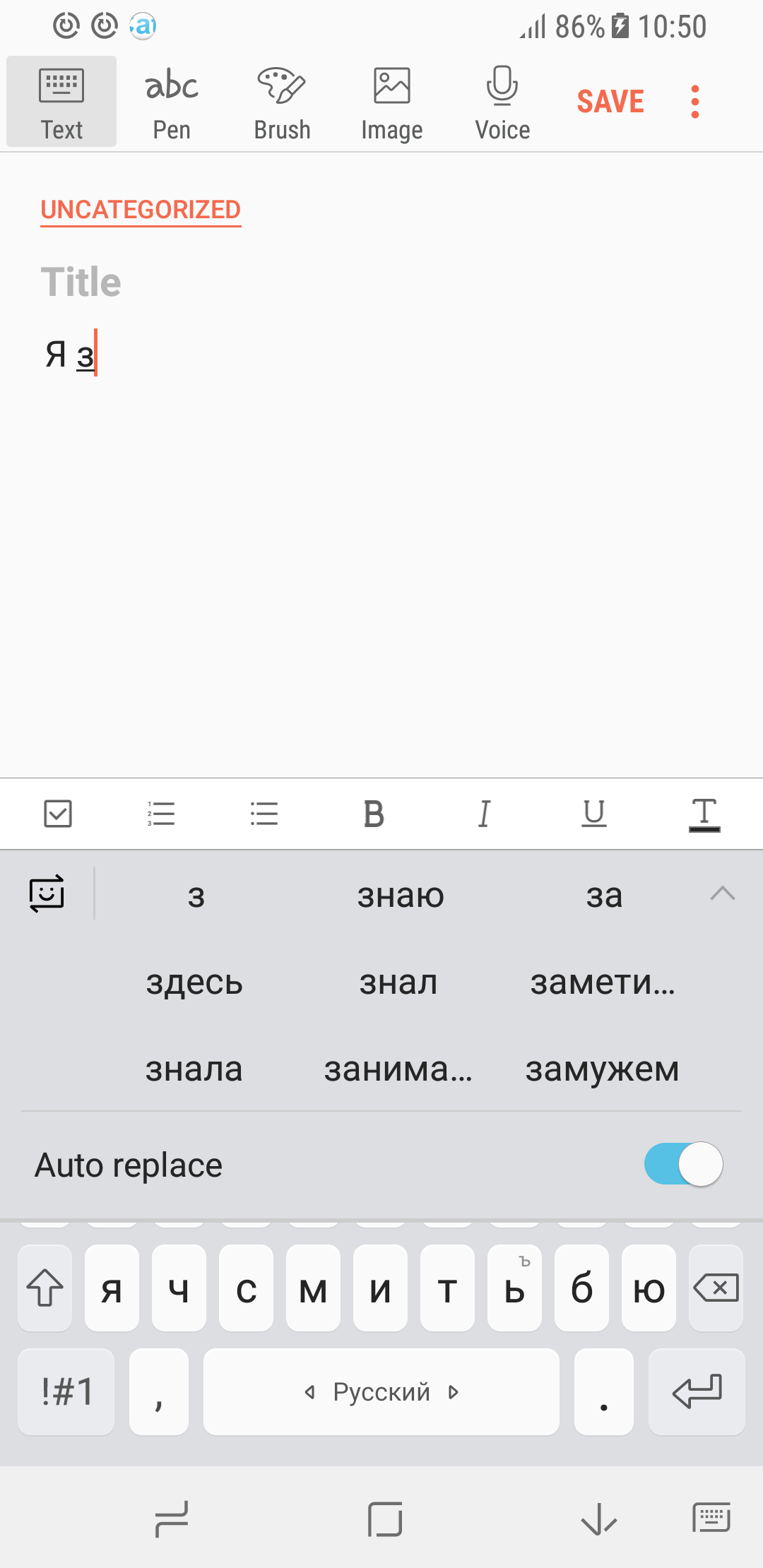 |
Как обучить модель на данных пользователя, если эти данные нельзя собирать?
Сформулируем проблему. Тексты, доступные в Интернете — не совсем то, что обычно печатается на клавиатуре мобильного устройства. Чаще всего с телефона пишутся короткие сообщения в духе:
- Привет, как дела? Когда приедешь?
- Встречаемся в 7 на Белорусской.
- Купи хлеба.
- Иван Васильевич! Я не успеваю закончить работу в срок, так как у меня сломался компьютер...
- Урааааа еду к вам.
В сообщениях содержится много личной информации, и вряд ли найдутся пользователи, готовые предоставить свою переписку разработчикам языковых моделей «для опытов».
Но чтобы на должном уровне подсказывать пользователям слова, необходим доступ к тому, что они пишут; однако, это частная информация, которую нельзя куда-либо передавать. Из этого следует, что необходим алгоритм для обучения языковой модели, «не подглядывающий» в пользовательские данные.
Для решения обозначенной проблемы обратимся к распределённому дообучению моделей. Основная идея подхода такова:
- На сервере обучается базовая модель на большом количестве данных (книги, статьи, форумы). Эта модель умеет генерировать связные гладкие предложения, то есть, в целом, выучила язык. Однако, её «стиль общения» отличается от стиля, используемого в SMS и мессенджерах, и подсказки могут оказаться слишком литературными.
- Эта модель немного дообучается на телефоне на текстах, набранных пользователем. Важно, что в этом случае данные не отправляются на сервер, и ни один человек, кроме пользователя, не получает к ним доступа. Также стоит отметить, что дообучение модели занимает менее трёх минут (тестировалось на Samsung S8) и несильно влияет на заряд батареи телефона.
- Дообученные модели разных пользователей собираются на сервере и объединяются в одну. Имеются различные методы объединения моделей. В нашем подходе веса моделей просто усредняются. Затем обновлённая модель отправляется пользователям.
Собирать модели от нескольких пользователей важно из-за того, что каждый человек знает гораздо больше слов, чем успевает напечатать на своём устройстве, например, за месяц. Следовательно, для хорошего моделирования языка нужна информация от многих пользователей.
Хорошо. Данные пользователя не отправляются на сервер. Но ведь пользовательские модели собираются. Можно ли из этих моделей выудить частную информацию? Может быть она там есть, но в «зашифрованном» виде?
Ответ: нет. Во-первых, модели усредняются по большому количеству пользователей. Соответственно, личная информация, характерная только для одного человека, теряется на фоне информации, общей для группы людей. Во-вторых, при обучении нейронных сетей используются различные методы защиты модели от переобучения, направленные, в том числе, на то, чтобы минимизировать влияние нетипичных примеров. Таким образом, в итоговой модели содержится информация о «среднем» пользователе.
Для заинтересованных читателей
Больше подробностей, конкретные формулировки, эксперименты и прочее опубликованы в статье на arXiv, которая будет представлена на ICLR 2018. Кроме того, в ней представлено математическое доказательство того, что усреднённая общая модель хорошо оберегает данные каждого конкретного пользователя.
Источник: habrahabr.ru