Xception: компактная глубокая нейронная сеть
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-01-26 11:12

Чтобы улучшить качество распознавания своих сетей, исследователи старались добавлять в сети больше слоёв, однако со временем пришло понимание, что иногда ограничения производительности попросту не позволяют обучать и использовать настолько глубокие сети. Это стало мотивацией для использования depthwise separable convolutions и создания архитектуры Xception.
Если вы хотите узнать, что это такое, и посмотреть, как использовать такую сеть на практике, чтобы научиться отличать котов от собак, добро пожаловать под кат.
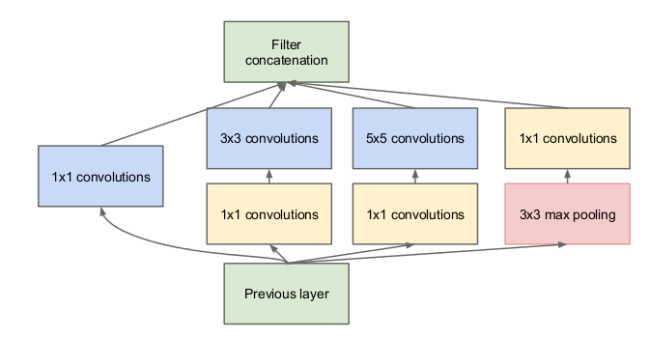
Модуль Inception
Каждый раз, когда мы добавляем очередной слой в свёрточную сеть, нам нужно принимать стратегическое решение про его характеристики. Какой размер ядра свёртки нам использовать? 3х3? 5х5? А может быть, поставить max pooling?

Получившаяся на рисунке снизу конструкция и составляет полный модуль Inception.
Depthwise separable convolution
Представим, что мы взяли стандартный свёрточный слой с фильтрами размера 3х3, на вход которому подается тензор размерности , где — это ширина и высота тензора, а — количество каналов.
Что делает такой слой? Он сворачивает одновременно все каналы исходного сигнала разными свёртками. На выходе у такого слоя получается тензор размерности .
Давайте вместо этого сделаем последовательно два шага:

- Свернём исходный тензор 1х1 свёрткой, подобно тому как мы делали в блоке Inception, получив тензор . Эта операция называется pointwise convolution
- Свернём каждый канал по отдельности 3х3 свёрткой (при этом размерность не изменится, так как мы сворачиваем не все каналы вместе, как в обычном свёрточном слое). Эта операция называется depthwise spatial convolution
На самом деле, обычно когда речь идёт о depthwise separable convolution, подразумевается, что сначала делают свёртку по каналам, а потом 1х1 свёртку, однако я привожу именно тот порядок операций, который указан в оригинальной статье. В целом, как утверждает автор, порядок этих операций не влияет на конечный результат.
Почему это делает сеть компактнее?
Давайте разберём конкретный пример. Пусть мы сворачиваем изображение с 16 каналами свёрточным слоем с 32 фильтрами. Суммарно этот свёрточный слой будет иметь весов, так как у нас будет свёрток 3х3.
Сколько же весов будет в аналогичном depthwise separable convolution блоке? Во-первых, у нас будет весов у pointwise convolution. Во-вторых, у нас будет весов у depthwise convolution. В сумме получим 800 весов, что намного меньше, чем у обычного свёрточного слоя.
Почему это вообще работает?
Обычный свёрточный слой одновременно обрабатывает как пространственную информацию (корреляцию соседних точек внутри одного канала), так и межканальную информацию, так как свёртка применяется ко всем каналам сразу. Архитектура Xception базируется на предположении о том, что эти два вида информации можно обрабатывать последовательно без потери качества работы сети, и раскладывает обычную свёртку на pointwise convolution (которая обрабатывает только межканальную корреляцию) и spatial convolution (которая обрабатывает только пространственную корреляцию в рамках отдельного канала).
Посмотрим на реальный эффект. Для сравнения возьмём две по-настоящему глубоких архитектуры свёрточных сетей — ResNet50 и InceptionResNetV2.
ResNet50 имеет 25 636 712 весов, а предобученная модель в Keras весит 99 Мб. Точность, которая достигается этой моделью на датасете ImageNet, составляет 75.9%.
InceptionResNetV2 имеет 55 873 736 обучаемых параметров и весит 215 Мб, достигая точности 80.4%.
Что же получается с архитектурой Xception? Сеть имеет 22 910 480 весов и весит 88 Мб. При этом точность классификации на ImageNet составляет 79%.
Таким образом, мы получаем архитектуру сети, которая превосходит по точности ResNet50 и лишь чуть-чуть уступает InceptionResNetV2, при этом существенно выигрывая по размерам, а значит по требуемым ресурсам как для обучения, так и для использования этой модели.
Меньше слов, больше кода
Разберём на коротком примере, как применить эту архитектуру к реальной задаче. Для этих целей возьмём датасет Dogs vs Cats с Kaggle и за полчаса научим нашу сеть отличать котиков от собачек.
Разобьем датасет на три части: train (4000 изображений), validation (2000 изображений) и test (10000 изображений).
 Так как Франсуа Шолле, автор архитектуры Xception, по совместительству является создателем Keras, он любезно предоставил веса этой сети, обученной на ImageNet, в своём фреймворке, чем мы и воспользуемся, чтобы дотюнить сеть под нашу задачу с помощью transfer learning.
Так как Франсуа Шолле, автор архитектуры Xception, по совместительству является создателем Keras, он любезно предоставил веса этой сети, обученной на ImageNet, в своём фреймворке, чем мы и воспользуемся, чтобы дотюнить сеть под нашу задачу с помощью transfer learning.
Загрузим веса с ImageNet в Xception, из которой убраны последние полносвязные слои. Прогоним наш датасет через эту сеть, чтобы получить признаки, которые свёрточная сеть может извлечь из изображений (так называемые bottleneck features):
input_tensor = Input(shape=(img_height,img_width,3)) base_model = xception.Xception(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg') data_generator = image.ImageDataGenerator(rescale=1. / 255) train_generator = data_generator.flow_from_directory( train_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode=None, shuffle=False) bottleneck_features_train = base_model.predict_generator( train_generator, nb_train_samples // batch_size) np.save(open('bottleneck_features_train.npy', 'wb'), bottleneck_features_train)Создадим полносвязную сеть и обучим её на признаках, полученных из свёрточных слоёв, используя для валидации специально отложенную часть исходного набора данных:
model = Sequential() model.add(Dense(256, activation='relu', input_shape=base_model.output_shape[1:])) model.add(Dropout(0.5)) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=SGD(lr=0.01), loss='binary_crossentropy', metrics=['accuracy']) checkpointer = ModelCheckpoint(filepath='top-weights.hdf5', verbose=1, save_best_only=True) history = model.fit(train_data, train_labels, epochs=epochs, batch_size=batch_size, callbacks=[checkpointer], validation_data=(validation_data, validation_labels))Уже после этой стадии, которая занимает пару минут на видеокарте GeForce GTX 1060, мы получаем accuracy около 99.4% на валидационном датасете.
Теперь попробуем дообучить сеть с аугментацией входных данных, загрузив в свёрточные слои веса с ImageNet, а в полносвязные слои — веса, которые наша сеть выучила только что:
input_tensor = Input(shape=(img_height,img_width,3)) base_model = xception.Xception(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg') top_model = Sequential() top_model.add(Dense(256, activation='relu', input_shape=base_model.output_shape[1:])) top_model.add(Dropout(0.5)) top_model.add(Dense(128, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(1, activation='sigmoid')) top_model.load_weights('top-weights.hdf5') model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) model.compile(optimizer=SGD(lr=0.005, momentum=0.1, nesterov=True), loss='binary_crossentropy', metrics=['accuracy'])Обучив сеть в таком режиме, ещё за пять эпох (около двадцати минут) мы достигнем точности в 99.5% на валидационном датасете.
Проверив модель на данных, которых она никогда не видела, и которые не использовались для настройки гиперпараметров (тестовый датасет), увидим точность около 96.9%, что выглядит довольно приемлемо.

Полный код для этого эксперимента можно найти на GitHub.
Что дальше?
В 2017 году Google добавили в TensorFlow предобученные сети архитектуры MobileNet, использующие принципы, похожие на Xception, для того, чтобы сделать модели ещё меньше. Эти модели пригодны для выполнения задач компьютерного зрения прямо на мобильных телефонах или IoT-устройствах, обладающих крайне ограниченными запасами памяти и слабым процессором.
Таким образом, мы незаметно подошли к той точке в истории computer science, когда написать приложение, определяющее, изображена ли на фото птица, можно за пятнадцать минут, причём это приложение будет выполняться прямо на вашем смартфоне.
Источник: habrahabr.ru