Добро пожаловать в эру глубокой нейроэволюции
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2018-01-08 14:12
реализация нейронной сети, алгоритмы машинного обучения, Теория эволюции

В области обучения глубоких нейронных сетей (DNN) с большим количеством слоев и миллионами соединений, для тренировки, как правило, применяется стохастический градиентный спуск (SGD). Многие полагают, что способность SGD эффективно вычислять градиенты является исключительной особенностью. Однако мы публикуем набор из пяти статей в поддержку нейроэволюции, когда нейронные сети оптимизируются с помощью эволюционных алгоритмов. Данный метод также является эффективным при обучении глубоких нейронных сетей для задач обучения с подкреплением (RL). Uber имеет множество областей, где машинное обучение может улучшить его работу, а разработка широкого спектра мощных подходов к обучению (включая нейроэволюцию), поможет разработать более безопасные и надежные транспортные решения.
Мне показалось более органичным сохранить сокращения в англоязычном варианте, как более узнаваемые для специалистов в данной предметной области. Кроме того, для некоторых мне не удалось быстро найти устоявшихся русскоязычных эквивалентов. Поэтому даю расшифровку примененных аббревиатур:
- A3C (Asynchronous Advantage Actor-Critic) — устоявшееся русскоязычное название мне не известно.
- DNN (Deep Neural Network) — глубокая нейронная сеть.
- DQN (Q-learning) — Q-обучение.
- ES (Evolution Strategies) — эволюционные стратегии.
- GA (Genetic Algorithm) — генетический алгоритм.
- MNIST (Modified National Institute of Standards and Technology database) — объёмная база данных образцов рукописного написания цифр.
- NS (Novelty Search algorithms) — алгоритмы поиска новизны.
- QD (Quality Diversity algorithms) — алгоритмы качественного разнообразия.
- RL (Reinforcement Learning) — обучение с подкреплением.
- SGD (Stochastic Gradient Descent) — стохастический градиентный спуск.
- SM-G (Safe Mutations through Gradients ) — безопасные мутации через градиенты.
- TRPO (Trust Region Policy Optimization) — устоявшееся русскоязычное название мне не известно.
Генетические алгоритмы как конкурентная альтернатива для обучения глубоких нейросетей
Используя новую технику, которую мы изобрели для эффективного развития DNN, мы с удивлением обнаружили, что чрезвычайно простой генетический алгоритм (GA) может обучать глубокие сверточные сети с более чем 4 миллионами параметров для игры в Atari из пикселей, и во многих играх превосходит современные алгоритмы глубокого обучения с подкреплением (RL) (например, DQN и A3C) или эволюционные стратегии (ES), а также является более быстрым из-за лучшего распараллеливания. Этот результат является неожиданным как из-за того, что не ожидалось, что GA, не основанный на градиенте, будет хорошо масштабироваться в таких больших пространствах параметров, а также потому, что достичь или превзойти передовые алгоритмы RL с использованием GA не считалось возможным. Далее, мы показываем, что современные усовершенствования GA, улучшающие возможности GA, такие как поиск новизны, также работают в масштабах DNN и могут способствовать поиску решений обманчивых задач (со сложными локальными экстремумами), опережая алгоритмы максимизации вознаграждения, такие как Q-learning (DQN), policy gradients (A3C), ES и GA.
Безопасные мутации с помощью градиентных вычислений
В отдельной статье мы показываем, как градиенты могут сочетаться с нейроэволюцией, улучшая способность к обучению рекуррентных и очень глубоких нейронных сетей, делая возможной эволюцию DNN с более чем сотней слоев – уровень, намного превышающий то, что ранее было возможно благодаря нейроэволюции. Мы делаем это, вычисляя градиент сетевых выходов относительно весов (т.е., не градиент ошибки, как в традиционном глубоком обучении), позволяя калибровке случайных мутаций более аккуратно обрабатывать наиболее чувствительные параметры, тем самым решая основную проблему случайной мутации в больших сетях.
Как ES соотносится с SGD
Наши статьи дополняют ранее сформированное понимание, которое было впервые отмечено командой из OpenAI (русский перевод: habrahabr.ru/post/330342), что разнообразные эволюционные стратегии нейроэволюции могут неплохо конкурировать в оптимизации глубоких нейронных сетей на задачах глубокого RL. Однако на сегодняшний день более широкие последствия этого результата остаются предметом обсуждения. Создавая предпосылки для дальнейших инноваций в ES, мы подробно изучаем их связь с SGD во всестороннем исследовании, в котором рассматривается, насколько близко приближение градиента с помощью ES фактически достигает оптимального градиента для каждого минибатча, вычисленного SGD на MNIST, а также насколько хорошо это можно сделать. Мы показываем, что ES может достичь 99-процентной точности в MNIST, если для улучшения приближения градиента будут обеспечены достаточные вычислительные мощности, указывая на то, почему ES будет все более и более серьезным соперником в глубоком RL, где ни один метод не имеет привилегированного доступа к идеальной информации о градиенте, поскольку увеличивается степень параллелизации вычислений.
ES – это не просто традиционные конечные разности
Сопутствующее исследование эмпирически подтверждает понимание, что ES (с достаточно большим значением параметра возмущения) действует иначе, чем SGD, потому что он оптимизирует ожидаемое вознаграждение от набора стратегий, описанных распределением вероятности (облако в пространстве поиска), тогда как SGD оптимизирует вознаграждение за одну стратегию (точку в пространстве поиска). Это изменение заставляет ES посещать разные области поискового пространства, к счастью или, к сожалению (проиллюстрированы оба случая). Дополнительным следствием оптимизации по популяции возмущений параметров является то, что ES приобретает робастность, не достижимую через SGD. Отмечая, что ES оптимизирует популяцию параметров, также подчеркивается интригующая связь между ES и байесовскими методами.
Улучшение поисковых способностей ES
Захватывающим следствием глубокой нейроэволюции является то, что набор инструментов, ранее разработанных для нейроэволюции, теперь становится кандидатом для улучшения обучения глубоких нейронных сетей. Мы изучаем эту возможность, внедряя новые алгоритмы, сочетающие в себе оптимизационную мощь и масштабируемость ES с методами, уникальными для нейроэволюции, которые способствуют поиску в доменах RL посредством популяций агентов, стимулируют друг друга действовать по-разному. Такие исследования, основанные на популяциях, отличаются от одноагентной традиции в RL, включая недавнюю работу по исследованиям в глубоких RL. Наши эксперименты показывают, что добавление этого нового стиля исследования улучшает производительность ES во многих областях, требующих обследования, для избегания обманных локальных оптимумов, включая некоторые игры Atari и задачу управления движением гуманоидов в симуляторе Mujoco.
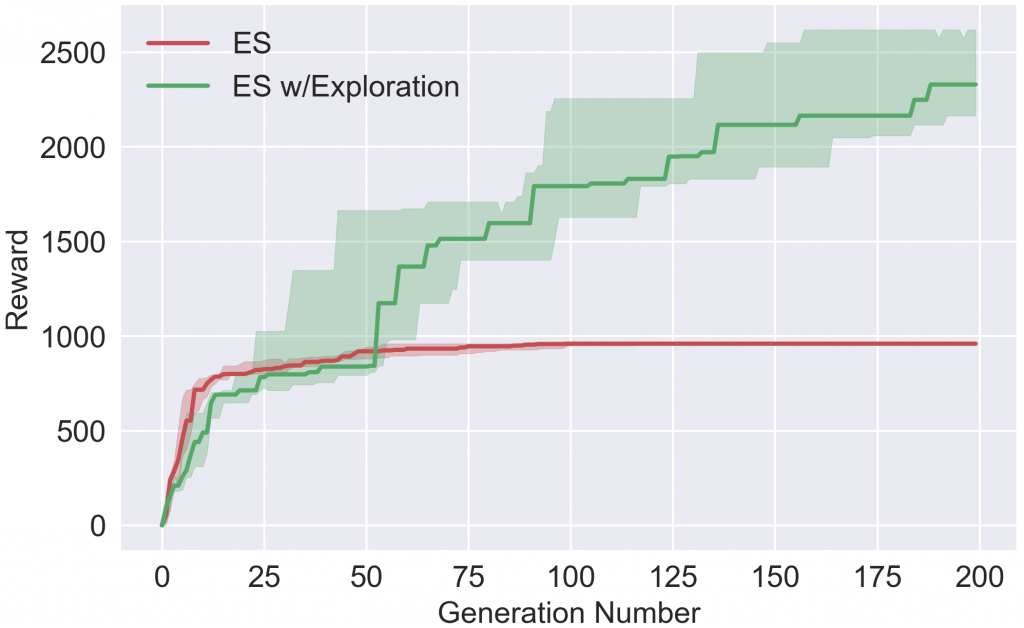 Награда на протяжении обучения
Награда на протяжении обученияС нашими гиперпараметрами ES быстро сходится к локальному оптимуму, который не включает подъем для пополнения запасов кислорода, потому что это временно отменяет вознаграждение. Однако, при зондировании, агент учится подниматься за кислородом и, таким образом, получает в будущем гораздо более высокое вознаграждение. Обратите внимание, что Salimans et al. 2017 не сообщают что их вариант ES, сталкивается с этими специфическими локальными оптимумами, но отмечают, что ES без зондирования может неопределенно блокироваться в некоторых локальных оптимумах (и что зондирование помогает его разблокировать) так же, как это показано и в нашей статье.
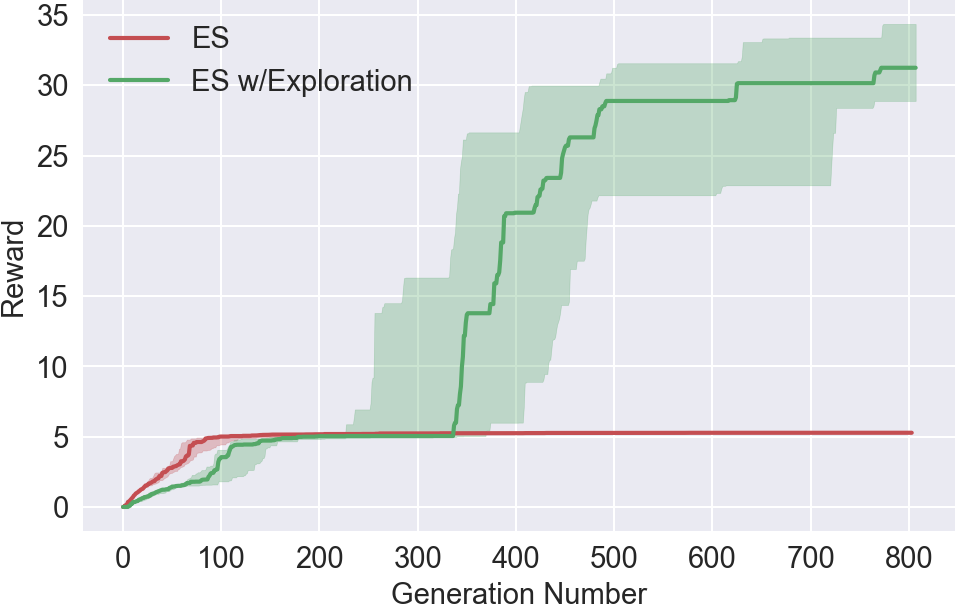 Награда на протяжении обучения
Награда на протяжении обученияЗаданием агента является бежать как можно дальше. ES никогда не обучается избегать ловушку. Однако, получив возможность зондирования, один из агентов обучается обходить ловушку.
Заключение
Для исследователей нейроэволюции, заинтересованных в продвижении к глубоким сетям, есть несколько важных мыслей: прежде всего, такие эксперименты требуют большей вычислительной мощи, чем в прошлом; для экспериментов, описанных в этих новых статьях мы часто использовали одновременно сотни или даже тысячи процессоров за прогон. Однако такая вычислительная прожорливость не должна рассматриваться как помеха; в конце концов, простота масштабирования эволюции в массивных параллельных вычислительных центрах означает, что нейроэволюция, пожалуй, лучше всего подходит для использования в мире, который к нам приходит.
Новые результаты настолько отличаются от того, что ранее наблюдалось в нейроэволюции низкой размерности, что они эффективно опровергают годы предположений, в частности, о последствиях поиска в пространствах с высокой размерностью. Как было обнаружено в глубоком обучении, выше некоторого порога сложности, кажется, что поиск фактически становится более простым в высоких размерностях в том смысле, что он менее восприимчив к локальным оптимумам. Хотя направление глубокого обучения хорошо знакомо с этим способом мышления, его последствия только начинают усваиваться в нейроэволюции.
Повторное появление нейроэволюции является еще одним примером того, что старые алгоритмы в сочетании с современными объемами вычислений могут работать на удивление хорошо. Жизнеспособность нейроэволюции интересна тем, что многие методы, разработанные в сообществе нейроэволюции, сразу становятся доступными на DNN-масштабах, каждый из которых предлагает различные инструменты для решения сложных задач. Более того, как показывают наши работы, нейроэволюция ищет не так, как это делает SGD, следовательно, предлагает интересный альтернативный подход к инструментарию для машинного обучения. Мы задаемся вопросом, будет ли глубокая нейроэволюция переживать ренессанс так же, как глубокое обучение. Если это так, 2017 год может означать начало эры, и мы будем рады увидеть, что будет развиваться в последующие годы!
Ниже приведены пять статей, которые мы опубликовали на сегодняшний день вместе с аннотацией их ключевых моментов:
- Глубокая Нейроэволюция: Генетический алгоритм является конкурентной альтернативой для обучения глубокий нейросетей в обучении с подкреплением
- Развивает DNN с помощью простого и традиционного, базирующегося на популяции генетического алгоритма, который хорошо работает со сложными проблемами RL. На Atari, GA работает так же хорошо, как и эволюционные стратегии и алгоритмы для глубокого обучения с подкреплением, базирующиеся на Q-обучение (DQN) и градиентных стратегиях.
- «Глубокий GA» успешно производит сеть с более чем 4 миллионами свободных параметров, наибольшая нейросеть, которая была получена ранее с помощью традиционных эволюционных алгоритмов.
- Интригует, что в некоторых случаях, следование градиенту не является лучшим выбором для оптимизации производительности.
- Объединение DNN с поиском новизны – зондирующий алгоритм, созданный для задач с обманчивыми и разреженными функциями подкрепления, для решения сложных проблем в пространствах большой размерности, где стратегии максимизации подкрепления (GA и ES) терпят неудачу.
- Показывает, что Глубокий GA параллелится лучше и работает быстрее, чем ES, A3C и DQN, а также позволяет использовать современную технику компактного кодирования, которая представляет DNN с миллионами параметров тысячами байт.
- Включает в себя результаты случайного поиска на Atari. Удивительно, но в некоторых играх случайный поиск стабильно опережает DQN, A3C и ES, хотя и никогда не превосходит ГА.
Поразительно, однако DNN, найденная с помощью случайного поиска, хорошо играет во Frostbite, превосходя DQN, A3C и ES, но не ГА. - Безопасные мутации для глубоких и рекуррентных нейросетей через выходные градиенты
- Безопасные мутации через градиенты (SM-G), существенно улучшают эффективность мутации в больших, глубоких и рекуррентных сетях за счет измерения чувствительности сети к изменениям в определенных весах соединений.
- Вычисляет градиенты выходов относительно весов вместо градиентов ошибок или потерь, как при обычном глубоком обучении, позволяя случайные, но безопасные зондирующие шаги.
- Оба типа безопасной мутации не требуют дополнительных попыток или откатов в области определения.
- Результат: глубокие сети (более 100 слоев) и большие рекуррентные сети в настоящее время могут быть сгенерированы эффективно только с помощью вариантов SM-G.
- О взаимосвязи между OpenAI эволюционной стратегией и стохастическим градиентным спуском
- Открывает взаимосвязь между ES и SGD, сравнивая приближенный градиент, вычисленный ES с точным градиентом, вычисленным SGD в наборе MNIST в разных условиях.
- Разрабатывает быстрые прокси, которые предсказывают ожидаемую от ES производительность при различных размерах популяции.
- Представляет и демонстрирует различные пути ускорения и улучшения производительности ES.
- Ограниченные возмущения ES существенно ускоряют выполнение в параллельной инфраструктуре.
- ES без мини-батча улучшает оценку градиента, заменяя мини-батч подход, разработанный под SGD на другой подход, настроенный на ES: случайное подмножество полной обучающей последовательности назначается каждому члену ES-популяции на каждой итерации алгоритма. Этот ES-специализированный подход обеспечивает лучшую точность для ES по сравнению с первым подходом, а кривая обучения получается намного более гладкая, чем даже для SGD.
- Версия ES без минибатча достигает 99-процентной точности на тестовом прогоне, что является наилучшей заявленной производительностью эволюционного подхода в данной задаче обучения с учителем.
- В общем, помогает показать, почему ES способен конкурировать с RL, где информация о градиенте, полученная в ходе испытаний в домене, менее информативна по сравнению с полученной при обучении с учителем.
- ES это больше, чем просто традиционный конечный разностный аппроксиматор
- Подчеркиваются важные отличия между ES и традиционными конечно-разностными методами, а именно то, что ES оптимизирует оптимальное распределение решений (в отличие от одного оптимального решения).
- Одно интересное следствие: решения, найденные ES, имеют тенденцию быть устойчивыми к возмущению параметров. Например, мы показываем, что модели гуманоидного шагателя существенно более устойчивы к возмущению параметров, чем найденные с помощью GA или TRPO.
- Еще одно важное следствие: ожидается, что ES решит некоторые задачи, в которых традиционные методы попадают в ловушку и наоборот. Простые примеры иллюстрируют эти различия в динамике между ES и традиционным следованием за градиентом.
- Улучшение исследования в Эволюционных Стратегиях для глубокого обучения с подкреплением посредством популяции агентов, ищущих новизну
- Добавляет возможность поощрять глубокое исследование в ES
- Показывает, что алгоритмы, которые были изобретены для содействия обследованию в небольших эволюционных нейросетях посредством популяции агентов-исследователей – в частности, это алгоритмы поиска новизны (NS) и качества (QD) – могут быть гибридизованы с ES для повышения эффективности работы на разреженных или обманных задачах RL, сохраняя при этом масштабируемость.
- Подтверждает, что результирующие новые алгоритмы, NS-ES и версия QD-ES, называемая NSR-ES, избегает локальных оптимумов, с которыми сталкивается ES, достигая более высокой производительности на задачах, начиная от моделируемых роботов, которые учатся обходить ловушку до высоко-размерных задач пиксельных игр Atari.
- Добавляет это новое семейство алгоритмов поиска в популяции в набор инструментов для глубокого RL.
Источник: habrahabr.ru