Поиск под капотом Глава 1. Сетевой паук
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-12-27 07:43
Умение искать информацию в Интернете является жизненно необходимым. Когда мы нажимаем на кнопку «искать» в нашей любимой поисковой системе, через доли секунды мы получаем ответ.
Большинство совершенно не задумывается о том, что же происходит «под капотом», а между тем поисковая система — это не только полезный инструмент, но еще и сложный технологический продукт. Современная поисковая система для своей работы использует практически все передовые достижения компьютерной индустрии: большие данные, теорию графов и сетей, анализ текстов на естественном языке, машинное обучение, персонализацию и ранжирование. Понимание того, как работает поисковая система, дает представление об уровне развития технологий, и поэтому разобраться в этом будет полезно любому инженеру.

В нескольких статьях я шаг за шагом расскажу о том, как работает поисковая система, и, кроме того, для иллюстрации я построю свой собственный небольшой поисковый движок, чтобы не быть голословным. Этот поисковый движок будет, конечно же, «учебным», с очень сильным упрощением того, что происходит внутри гугла или яндекса, но, с другой стороны, я не буду упрощать его слишком сильно.
Первый шаг — это сбор данных (или, как его еще называют, краулинг).
Веб — это граф
Та часть Интернета, которая нам интересна, состоит из веб-страниц. Для того чтобы поисковая система смогла найти ту или иную веб-страницу по запросу пользователя, она должна заранее знать, что такая страница существует и на ней содержится информация, релевантная запросу. Пользователь обычно узнает о существовании веб-страницы от поисковой системы. Каким же образом сама поисковая система узнает о существовании веб-страницы? Ведь никто ей не обязан явно сообщать об этом.
К счастью, веб-страницы не существуют сами по себе, они содержат ссылки друг на друга. Поисковый робот может переходить по этим ссылкам и открывать для себя все новые веб-страницы.
На самом деле структура страниц и ссылок между ними описывает структуру данных под названием «граф». Граф по определению состоит из вершин (веб-страниц в нашем случае) и ребер (связей между вершинами, в нашем случае — гиперссылок).
Другими примерами графов являются социальная сеть (люди — вершины, ребра — отношения дружбы), карта дорог (города — вершины, ребра — дороги между городами) и даже все возможные комбинации в шахматах (шахматная комбинация — вершина, ребро между вершинами существует, если из одной позиции в другую можно перейти за один ход).
Графы бывают ориентированными и неориентированными — в зависимости от того, указано ли на ребрах направление. Интернет представляет собой ориентированный граф, так как по гиперссылкам можно переходить только в одну сторону.
Для дальнейшего описания мы будем предполагать, что Интернет представляет собой сильно связный граф, то есть, начав в любой точке Интернета, можно добраться до любой другой точки. Это допущение — очевидно неверное (я могу легко создать новую веб-страницу, на которую не будет ссылок ниоткуда и соответственно до нее нельзя будет добраться), но для задачи проектирования поисковой системы его можно принять: как правило, веб-страницы, на которые нет ссылок, не представляют большого интереса для поиска.
Небольшая часть веб-графа:

Алгоритмы обхода графа: поиск в ширину и в глубину
Поиск в глубину
Существует два классических алгоритма обхода графов. Первый — простой и мощный — алгоритм называется поиск в глубину (Depth-first search, DFS). В его основе лежит рекурсия, и он представляет собой следующую последовательность действий:
- Помечаем текущую вершину обработанной.
- Обрабатываем текущую вершину (в случае поискового робота обработкой будет просто сохранение копии).
- Для всех вершин, в которые можно перейти из текущей: если вершина еще не обработана, рекурсивно обрабатываем и ее тоже.
Код на Python, имплементирующий данный подход буквально дословно:
seen_links = set() def dfs(url): seen_links.add(url) print('processing url ' + url) html = get(url) save_html(url, html) for link in get_filtered_links(url, html): if link not in seen_links: dfs(link) dfs(START_URL)Приблизительно таким же образом работает, например, стандартная линуксовая утилита wget с параметром -r, показывающим, что нужно выкачивать сайт рекурсивно:
wget -r habrahabr.ru Метод поиска в глубину целесообразно применять для того, чтобы обойти веб-страницы на небольшом сайте, однако для обхода всего Интернета он не очень удобен:
- Содержащийся в нем рекурсивный вызов не очень хорошо параллелится.
- При такой реализации алгоритм будет забираться все глубже и глубже по ссылкам, и в конце концов у него, скорее всего, не хватит места в стеке рекурсивных вызовов и мы получим ошибку stack overflow.
В целом обе эти проблемы можно решить, но мы вместо этого воспользуемся другим классическим алгоритмом — поиском в ширину.
Поиск в ширину
Поиск в ширину (breadth-first search, BFS) работает схожим с поиском в глубину образом, однако он обходит вершины графа в порядке удаленности от начальной страницы. Для этого алгоритм использует структуру данных «очередь» — в очереди можно добавлять элементы в конец и забирать из начала.
- Алгоритм можно описать следующим образом:
- Добавляем в очередь первую вершину и в множество «увиденных».
- Если очередь не пуста, достаем из очереди следующую вершину для обработки.
- Обрабатываем вершину.
- Для всех ребер, исходящих из обрабатываемой вершины, не входящих в «увиденные»:
- Добавить в «увиденные»;
- Добавить в очередь.
- Перейти к пункту 2.
Код на python:
def bfs(start_url): queue = Queue() queue.put(start_url) seen_links = {start_url} while not (queue.empty()): url = queue.get() print('processing url ' + url) html = get(url) save_html(url, html) for link in get_filtered_links(url, html): if link not in seen_links: queue.put(link) seen_links.add(link) bfs(START_URL)![]()
Понятно, что в очереди сначала окажутся вершины, находящиеся на расстоянии одной ссылки от начальной, потом двух ссылок, потом трех ссылок и т. д., то есть алгоритм поиска в ширину всегда доходит до вершины кратчайшим путем.
Еще один важный момент: очередь и множество «увиденных» вершин в данном случае используют только простые интерфейсы (добавить, взять, проверить на вхождение) и легко могут быть вынесены в отдельный сервер, коммуницирующий с клиентом через эти интерфейсы. Эта особенность дает нам возможность реализовать многопоточный обход графа — мы можем запустить несколько одновременных обработчиков, использующих одну и ту же очередь.
Robots.txt
Прежде чем описать собственно имплементацию, хотелось бы отметить, что хорошо ведущий себя краулер учитывает запреты, установленные владельцем веб-сайта в файле robots.txt. Вот, например, содержимое robots.txt для сайта lenta.ru:
User-agent: YandexBot Allow: /rss/yandexfull/turbo User-agent: Yandex Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my Host: https://lenta.ru User-agent: GoogleBot Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my User-agent: * Disallow: /search Disallow: /check_ed Disallow: /auth Disallow: /my Sitemap: https://lenta.ru/sitemap.xml.gzВидно, что тут определены некоторые разделы сайта, которые запрещено посещать роботам яндекса, гугла и всем остальным. Для того чтобы учитывать содержимое robots.txt в языке python, можно воспользоваться реализацией фильтра, входящего в стандартную библиотеку:
In [1]: from urllib.robotparser import RobotFileParser ...: rp = RobotFileParser() ...: rp.set_url('https://lenta.ru/robots.txt') ...: rp.read() ...: In [3]: rp.can_fetch('*', 'https://lenta.ru/news/2017/12/17/vivalarevolucion/') Out[3]: True In [4]: rp.can_fetch('*', 'https://lenta.ru/search?query=big%20data#size=10|sort=2|domain=1 ...: |modified,format=yyyy-MM-dd') Out[4]: FalseИмплементация
Итак, мы хотим обойти Интернет и сохранить его для последующей обработки.
Конечно, в демонстрационных целях обойти и сохранить весь Интернет не выйдет — это стоило бы ОЧЕНЬ дорого, но разрабатывать код мы будем с оглядкой на то, что потенциально его можно было бы масштабировать до размеров всего Интернета.
Это означает, что работать мы должны на большом количестве серверов одновременно и сохранять результат в какое-то хранилище, из которого его можно будет легко обработать.
В качестве основы для работы своего решения я выбрал Amazon Web Services, так как там можно легко поднять определенное количество машин, обработать результат и сохранить его в распределенное хранилище Amazon S3. Похожие решения есть, например, у google, microsoft и у яндекса.
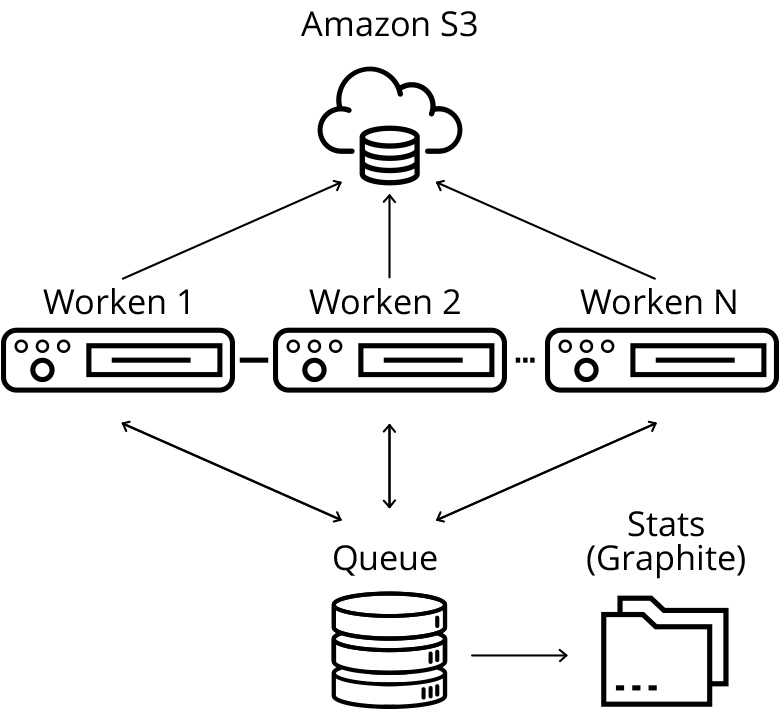
Архитектура разработанного решения
Центральным элементом в моей схеме сбора данных является сервер очереди, хранящий очередь URL, подлежащих скачиванию и обработке, а также множество URL, которые наши обработчики уже «видели». В моей имплементации это они основаны на простейших структурах данных Queue и set языка python.
В реальной продакшн-системе, скорее всего, вместо них стоило бы использовать какое-нибудь существующее решение для очередей (например, kafka) и для распределенного хранения множеств (например, подошли бы решения класса in-memory key-value баз данных типа aerospike). Это позволило бы достичь полной горизонтальной масштабируемости, но в целом нагрузка на сервер очереди оказывается не очень большой, поэтому в таком масштабировании в моем маленьком демо-проекте смысла нет.
Рабочие серверы периодически забирают новую группу URL для скачивания (забираем сразу помногу, чтобы не создавать лишнюю нагрузку на очередь), скачивают веб-страницу, сохраняют ее на s3 и добавляют новые найденные URL в очередь на скачивание.
Для того чтобы снизить нагрузку на добавление URL, добавление тоже происходит группами (добавляю сразу все новые URL, найденные на веб-странице). Еще я периодически синхронизирую множество «увиденных» URL с рабочими серверами, чтобы осуществлять предварительную фильтрацию уже добавленных страниц на стороне рабочей ноды.
Скачанные веб-страницы я сохраняю на распределенном облачном хранилище (S3) — это будет удобно впоследствии для распределенной обработки.
Очередь периодически отправляет статистику по количеству добавленных и обработанных запросов в сервер статистики. Статистику отправляем суммарно и в отдельности для каждой рабочей ноды — это необходимо для того, чтобы было понятно, что скачивание происходит в штатном режиме. Читать логи каждой отдельной рабочей машины невозможно, поэтому следить за поведением будем на графиках. В качестве решения для мониторинга скачивания я выбрал graphite.
Запуск краулера
Как я уже писал, для того чтобы скачать весь Интернет, нужно огромное количество ресурсов, поэтому я ограничился только маленькой его частью — а именно сайтами habrahabr.ru и geektimes.ru. Впрочем, ограничение это довольно условное, и расширение его на другие сайты — просто вопрос количества доступного железа. Для запуска я реализовал простенькие скрипты, которые поднимают новый кластер в облаке amazon, копируют туда исходный код и запускают соответствующий сервис:
#deploy_queue.py from deploy import * def main(): master_node = run_master_node() deploy_code(master_node) configure_python(master_node) setup_graphite(master_node) start_urlqueue(master_node) if __name__ == main(): main()#deploy_workers.py #run as: http://<queue_ip>:88889 from deploy import * def main(): master_node = run_master_node() deploy_code(master_node) configure_python(master_node) setup_graphite(master_node) start_urlqueue(master_node) if __name__ == main(): main()Код скрипта deploy.py, содержащего все вызываемые функции
Использование в качестве инструмента статистики graphite позволяет рисовать красивые графики:

Красный график — найденные URL, зеленый — скачанные, синий — URL в очереди. За все время скачано 5.5 миллионов страниц.
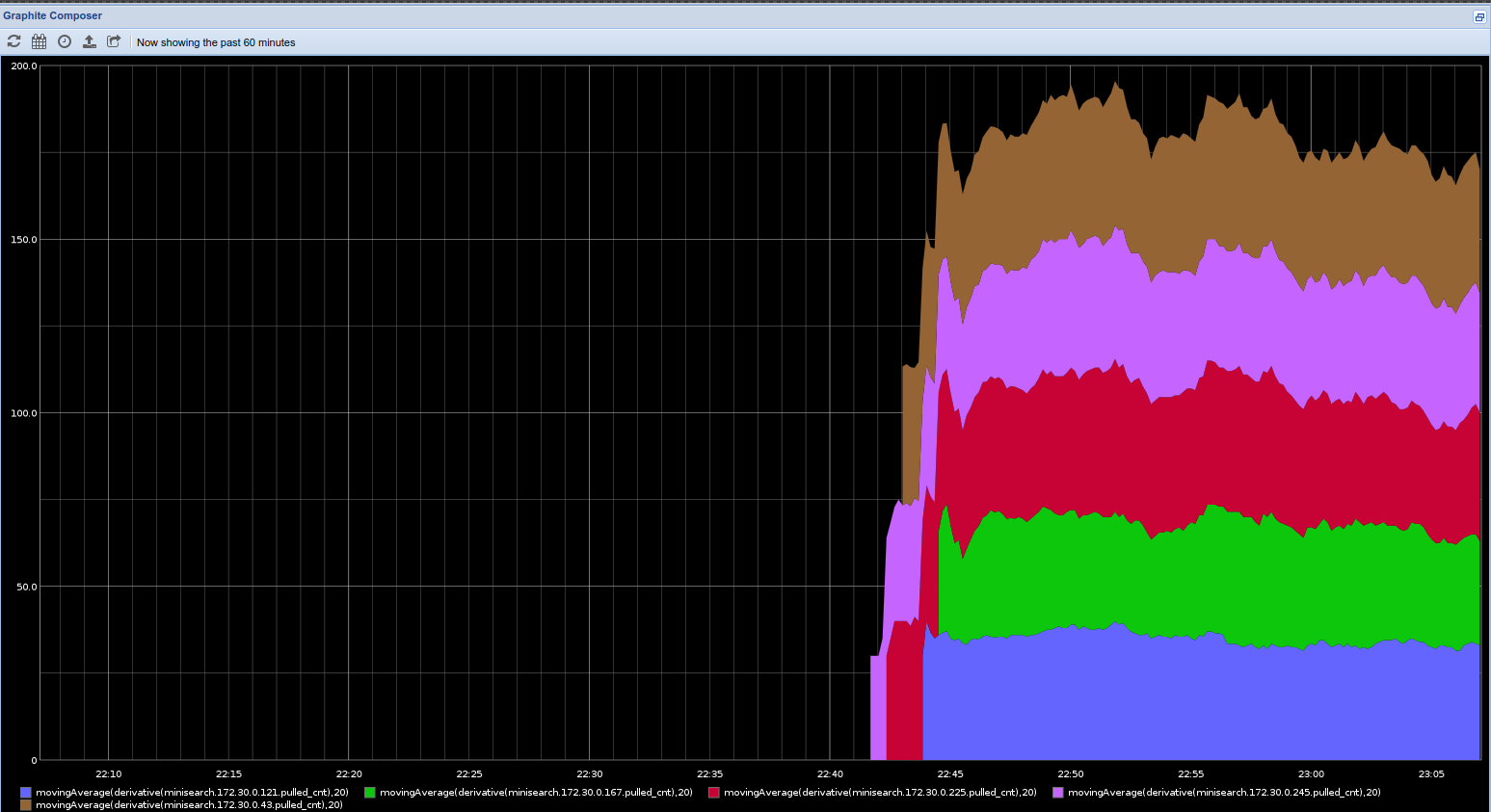 Количество скрауленных страниц в минуту в разбивке по рабочим нодам. Графики не прерываются, краулинг идет в штатном режиме.
Количество скрауленных страниц в минуту в разбивке по рабочим нодам. Графики не прерываются, краулинг идет в штатном режиме.
Результаты
Скачивание habrahabr и geektimes у меня заняло три дня.
Можно было бы скачать гораздо быстрее, увеличив количество экземпляров воркеров на каждой рабочей машине, а также увеличив количество воркеров, но тогда нагрузка на сам хабр была бы очень большой — зачем создавать проблемы любимому сайту?
В процессе работы я добавил пару фильтров в краулер, начав фильтровать некоторые явно мусорные страницы, нерелевантные для разработки поискового движка.
Разработанный краулер, хоть и является демонстрационным, но в целом масштабируется и может применяться для сбора больших объемов данных с большого количества сайтов одновременно (хотя, возможно, в продакшне есть смысл ориентироваться на существующие решения для краулинга, такие как heritrix. Реальный продакшн-краулер также должен запускаться периодически, а не разово, и реализовывать много дополнительного функционала, которым я пока пренебрег.
За время работы краулера я потратил примерно 60 $ на облако amazon. Всего скачано 5.5 млн страниц, суммарным объемом 668 гигабайт.
В следующей статье цикла я построю индекс по скачанным веб-страницам при помощи технологий больших данных и спроектирую простейший движок собственно поиска по скачанным страницам.
Код проекта доступен на github
Источник: habrahabr.ru