Нейросети без учителя переводят с языков, для которых нет параллельного корпуса текстов
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-12-01 12:35

Как известно, в основе нейронного переводчика механизм двунаправленных рекуррентных нейронных сетей (Bidirectional Recurrent Neural Networks), построенный на матричных вычислениях, который позволяет строить существенно более сложные вероятностные модели, чем статистические машинные переводчики. Однако всегда считалось, что нейронный перевод, как и статистический, требует для обучения параллельных корпусов текстов на двух языках. На этих корпусах обучается нейросеть, принимая человеческий перевод за эталонный.
Как теперь выяснилось, нейросети способны освоить новый язык для перевода даже без параллельного корпуса текстов! На сайте препринтов arXiv.org опубликованы сразу две работы на эту тему.
«Представьте, что вы даёте какому-то человеку много китайских книг и много арабских книг — среди них нет одинаковых — и этот человек обучается переводить с китайского на арабский. Это кажется невозможным, правда? Но мы показали, что компьютер способен на такое», — говорит Микель Артетксе (Mikel Artetxe), учёный, работающий в области компьютерных наук в Университете Страны Басков в Сан-Себастьяне (Испания).
Большинство нейросетей машинного перевода обучается «с учителем», в роли которого как раз выступает параллельный корпус текстов, переведённый человеком. В процессе обучения, грубо говоря, нейросеть делает предположение, сверяется с эталоном, и вносит необходимые настройки в свои системы, затем обучается дальше. Проблема в то, что для некоторых языков в мире нет большого количества параллельных текстов, поэтому они недоступны для традиционных нейросетей машинного перевода.
Две новые модели предлагают новый подход: обучение нейросети машинного перевода без учителя. Система сама пытается составить некое подобие параллельного корпуса текстов, выполняя кластеризацию слов друг вокруг друга. Дело в том, что в большинстве языков мира присутствуют одни и те же смыслы, которым просто соответствуют разные слова. Так вот, все эти смыслы группируются в одинаковые кластеры, то есть одни и те же смыслы-слова группируются вокруг одних и тех же смыслов-слов, практически независимо от языка (см. статью «Нейросеть Google Translate составила единую базу смыслов человеческих слов»).
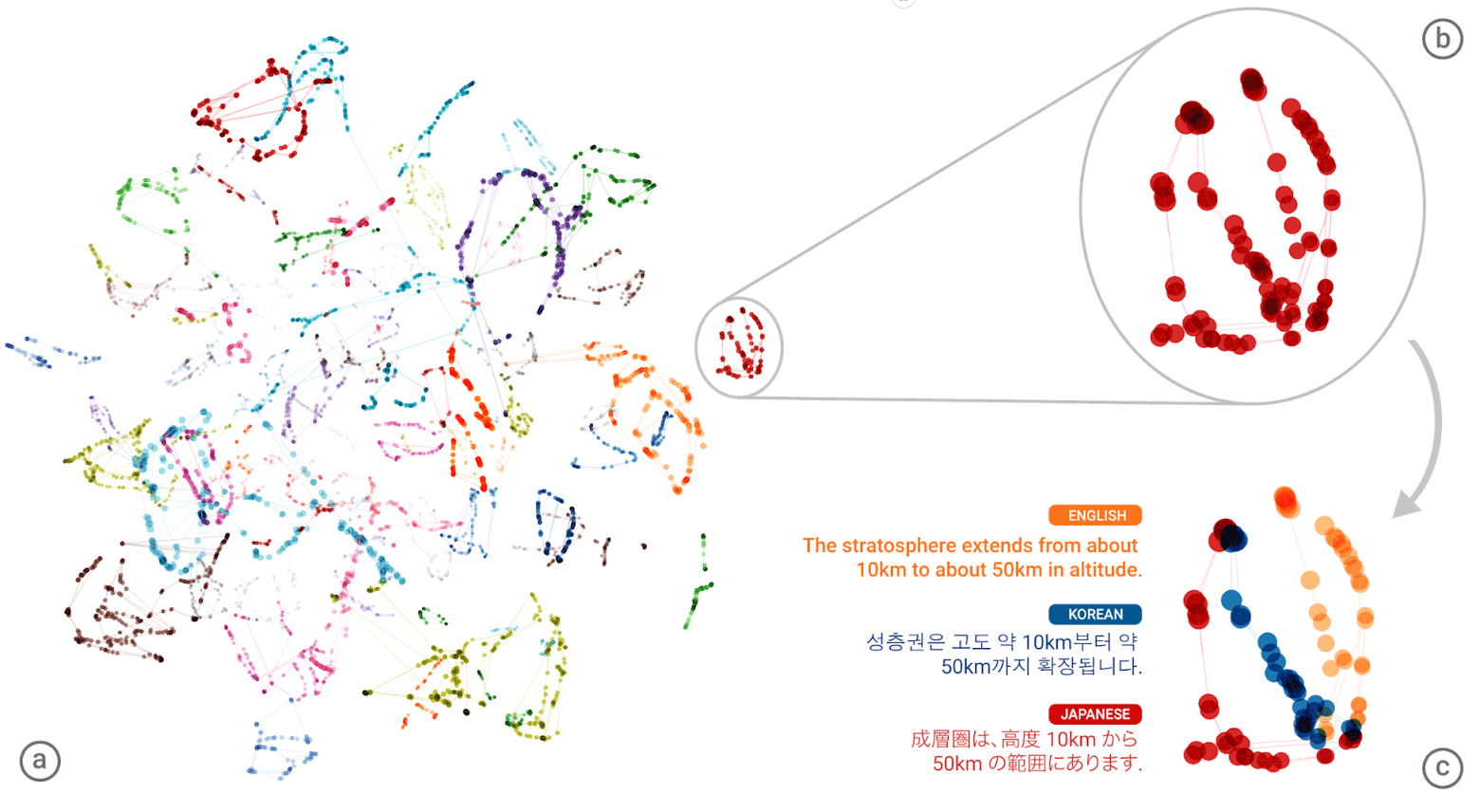
«Универсальный язык» нейронной сети Google Neural Machine Translation (GNMT). На левой иллюстрации разными цветами показаны кластеры значений каждого слова, справа внизу — смыслы слова, полученные для него из разных человеческих языков: английского, корейского и японского
Составив гигантский «атлас» для каждого языка, затем система пытается наложить один такой атлас на другой — и вот пожалуйста, у вас готово некое подобие параллельных текстовых корпусов!
Можно сравнить схемы двух предлагаемых архитектур обучения без учителя.
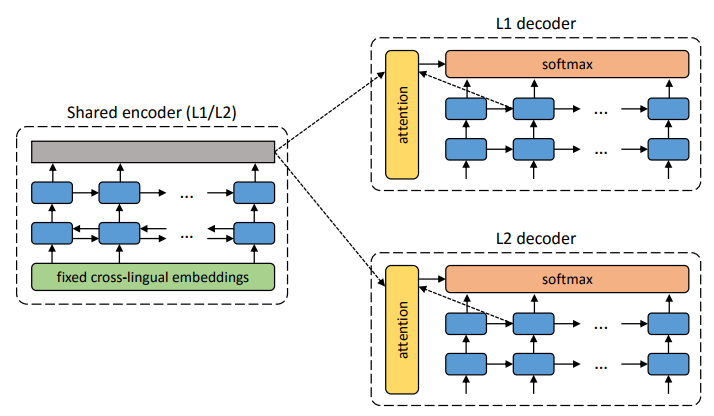
Архитектура предлагаемой системы. Для каждого предложения на языке L1 система учится чередованию двух шагов: 1) шумоподавление (denoising), которое оптимизирует вероятность кодирования зашумлённой версии предложения с общим энкодером и его реконструкции декодером L1; 2) обратный перевод (back-translation), когда предложение переводится в режиме вывода (то есть кодируется общим энкодером и декодируется декодером L2), а затем оптимизируется вероятность кодирования этого переведённого предложения с общим энкодером и восстановления оригинального предложения декодером L1. Иллюстрация: научная статья Микеля Артетксе и др.
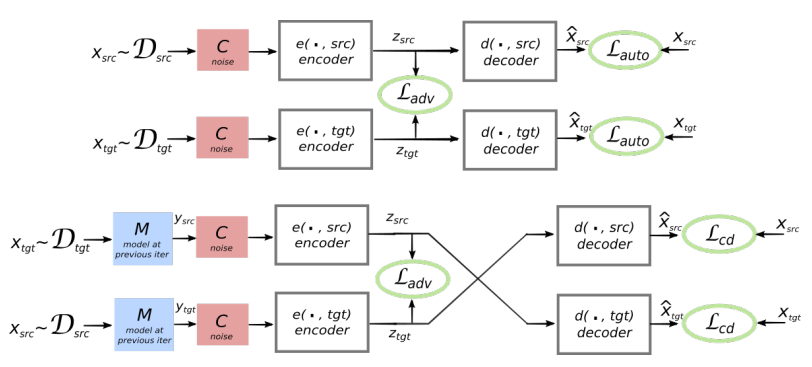
Предлагаемая архитектура и цели обучения системы (из второй научной работы). Архитектура представляет собой модель перевода по предложениям, где и энкодер, и декодер работают на двух языках, в зависимости от идентификатора входного языка, который меняет местами поисковые таблицы. Вверху (автокодирование): модель обучается выполнять шумоподавление в каждом домене. Внизу (перевод): как и прежде, плюс мы кодируем с другого языка, используя в качестве входных данных перевод, произведённый моделью в предыдущей итерации (голубой прямоугольник). Зелёные эллипсы указывают термины в функции потерь. Иллюстрация: научная статья Гильома Лампла и др.
Обе научные работы используют заметно схожую методику с небольшими отличиями. Но в обоих случаях перевод осуществляется через некий промежуточный «язык» или, лучше сказать, промежуточное измерение или пространство. Пока что нейросети без учителя показывают не очень высокое качество перевода, но авторы говорят, что его легко повысить, если использовать небольшую помощь учителя, просто сейчас ради чистоты эксперимента этого не делали.
Отметим, что вторую научную работу опубликовали исследователи из подразделения Facebook AI.
Работы представлены для Международной конференции по обучающим представлениям 2018 года (International Conference on Learning Representations). Ни одна из статей ещё не опубликована в научной прессе.
Источник: geektimes.ru