Язык программирования Python и пакеты для машинного обучения и Data Mining | РОБОТОША
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-11-27 00:58

Python является отличным языком программирования для реализации машинного обучения и алгоритмов data mining по множеству причин. Во-первых, Python имеет понятный синтаксис. Во-вторых, в Python очень просто производить манипуляции с текстом. Python используют большое число людей и организаций во всем мире, поэтому он развивается и хорошо документирован. Язык является кросс-платформенным и пользоваться им можно совершенно бесплатно.
Исполняемый псевдо-код
Интуитивно понятный синтаксис Python зачастую называют исполняемым псевдо-кодом. Установка Python по умолчанию уже включает высокоуровневые типы данных, такие как списки, кортежи, словари, наборы, последовательности и так далее, которые уже нет необходимости реализовывать пользователю. Эти типы данных высокого уровня делают простой реализацию абстрактных понятий. Python позволяет программировать в любом знакомом вам стиле: объектно-ориентированном, процедурном, функциональном и так далее.
В Python просто обрабатывать и манипулировать текстом, что делает его идеальным для обработки нечисловых данных. Есть ряд библиотек для использования Python для доступа к веб-страницам, а интуитивно понятные манипуляции с текстом позволяют легко извлекать данные из HTML-кода.
Python популярен
Язык программирования Python популярен и множество доступных примеров кода делает обучение ему простым и достаточно быстрым. Во-вторых, популярность означает, что есть множество модулей предназначенных для различных приложений.
Python является популярным языком программирования в научных, а также финансовых кругах. Ряд библиотек для научных вычислений, таких как SciPy и NumPy позволяют выполнять операции над векторами и матрицами. Это также делает код еще более читаемым и позволяет писать код, который выглядит как выражения линейной алгебры. Кроме того, научные библиотеки SciPy и NumPy скомпилированы, используя языки низкого уровня (С и Fortran), что делает делает вычисления при использовании этих инструментов значительно быстрее.
Научные инструменты Python отлично работают в связке с графическим инструментом под названием Matplotlib. Matplotlib может строить двухмерные и трехмерные графики и может работать с большинством типов построений, обычно используемых в научном сообществе.
Python также имеет интерактивную оболочку, которая позволяет просматривать и проверять элементы разрабатываемой программы.
Новый модуль Python, под называнием Pylab, стремится объединить возможности NumPy, SciPy, и Matplotlib в одной среде и установке. На сегодняшний день пакет Pylab пока еще находится в стадии разработки, но за ним большое будущее.
Преимущества и недостатки Python
Люди используют различные языки программирования. Но для многих, язык программирования является просто инструментом для решения какой-то задачи. Python является языком высшего уровня, что позволяет тратить больше времени на осмысление данных и меньше временных на обдумывание того, в каком же виде они должны быть представлены для компьютера.
Единственным реальным недостатком Python является то, что он не так быстро выполняет программный код как, например Java или C. Причиной тому является то, что Python — язык интерпретируемый. Однако существует возможность вызова скомпилированных C-программ из Python. Это позволяет использовать лучшее из различных языков программирования и пошагово разрабатывать программу. Если вы поэкспериментировали над идеей, используя Python и решили, что это именно то, что вы хотите, чтобы было реализовано в готовой системе, то легко можно будет реализовать этот переход от прототипа к рабочей программе. Если программа построена по модульному принципу, то можно сначала удостоверится что то, что вам нужно работает в коде, написанном на Python, а затем, чтобы улучшить скорость выполнения кода, переписать критичные участки на языке C. Библиотека C++ Boost позволяет это с легкостью сделать. Другие инструменты, такие как Cython и PyPy позволяют увеличить производительность работы программы по сравнению с обычным Python.
Если сама реализуемая программой идея является «плохой», то лучше понять это, затратив на написание кода минимум драгоценного времени. Если же идея работает, то всегда можно улучшить производительность, переписав частично критичные участки программного кода.
В последние годы большое число разработчиков, в том числе, имеющих ученые степени, работало над улучшением производительности языка и отдельных его пакетов. Поэтому, не факт, что вы напишите код на C, который будет работать быстрее, чем то, что уже имеется в Python.
Какую версию Python использовать?
В настоящее время одновременно широко применяются различные версии этого, а именно 2.x и 3.x. Третья версия пока еще находится в стадии активной разработки, большинство различных библиотек гарантированно работают на второй версии, поэтому я пользуюсь второй версией, а именно 2.7.8, чего и вам советую. Каких-то прямо уж кардинальных изменений в 3-й версии этого языка программирования нет, поэтому ваш код с минимальными изменениями в будущем, в случае необходимости, можно будет перенести и для использования с третьей версией.
Для установки заходим на официальный сайт: www.python.org/downloads/
выбираем свою операционную систему и скачиваем установщик. Подробно я останавливаться на вопросе установки не буду, поисковики вам с легкостью в этом помогут.
Я на MacOs устанавливал себе версию Python, отличную от той, что была установлена в системе и пакеты через менеджер пакетов Anaconda (кстати, там же есть варианты установки под Windows и Linux).
Далее варианты установки пакетов я приведу с использованием командной строки Linux.
Под Windows, говорят, Python ставится с бубном, но сам не пробовал, врать не буду.
NumPy

NumPy является основным пакетом для научных вычислений в Python. NumPy является расширением языка программирования Python, добавляющим поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых математических функций для работы с этими массивами. Предшественник NumPy, пакет Numeric, был первоначально создан Джимом Хаганином при участии ряда других разработчиков. В 2005 году Трэвис Олифант создал NumPy путем включения функций конкурирующего пакета Numarray в Numeric, произведя при этом обширные изменения.
Сайт пакета: www.numpy.org
Для установки в Терминале Linux выполняем:
1 2 | sudo apt-get update sudo apt-get install python-numpy |
Простенький код с использованием NumPy который формирует одномерный вектор из 12 чисел от 1 до 12 и преобразует его в трехмерную матрицу:
1 2 3 4 5 | fromnumpy import* a=arange(12) a=a.reshape(3,2,2) printa |
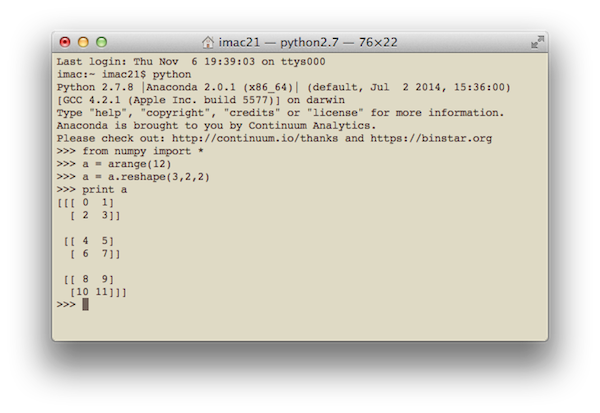
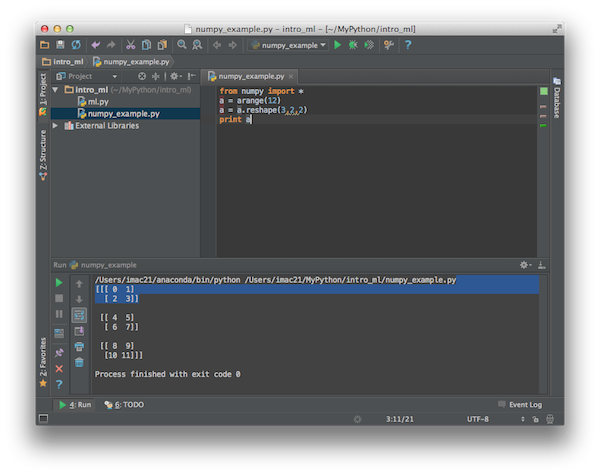
Вообще говоря, в Терминале код на Python я выполняю не очень часто, разве чтобы посчитать что-нибудь по-быстрому, как на калькуляторе. Мне нравится работать в IDE PyCharm. Вот так выглядит ее интерфейс при запуске вышеуказанного кода
SciPy
![]()
SciPy — это open-source библиотека с открытым исходным кодом для научных вычислений. Для работы SciPy требуется, чтобы предварительно был установлен NumPy, обеспечивающий удобные и быстрые операции с многомерными массивами. Библиотека SciPy работает с массивами NumPy, и предоставляет множество удобных и эффективных вычислительных процедур, например, для численного интегрирования и оптимизации. NumPy и SciPy просты в использовании, но достаточно мощные для проведения различных научных и технических вычислений.
Сайт библиотеки: www.scipy.org
Для установки библиотеки SciPy в Linux, выполняем в терминале:
1 2 | sudo apt-get update sudo apt-get install python-scipy |
Приведу пример кода для поиска экстремума функции. Результат отображается уже используя пакет matplotlib, рассматриваемый чуть ниже.
1 2 3 4 5 6 7 8 9 | importnumpy asnp fromscipy importspecial,optimize importmatplotlib.pyplot asplt f=lambdax:-special.jv(3,x) sol=optimize.minimize(f,1.0) x=np.linspace(,10,5000) plt.plot(x,special.jv(3,x),'-',sol.x,-sol.fun,'o') plt.show() |
Результатом является график с отмеченным экстремумом:
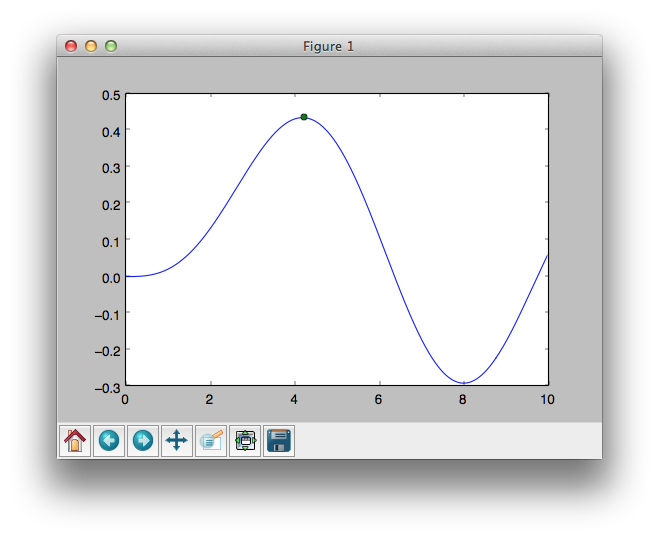
Ради интереса попробуйте реализовать тоже самое на языке C и сравните количество строк кода, требуемых для получения результата. Сколько у вас получилось строк? Сто? Пятьсот? Две тысячи? ![]()
Pandas
![]()
pandas — это пакет Python, предназначенный для обеспечения быстрыми, гибкими, и выразительными структурами данных, упрощающими работу с «относительными» или «помечеными» данными простым и интуитивно понятным способом. pandas стремится стать основным высокоуровневым строительным блоком для проведения в Python практического анализа данных, полученных из реального мира. Кроме того, этот пакет претендует стать самым мощным и гибким open-source инструментом для анализа/обработки данных, доступным в любом языке программирования.
Pandas хорошо подходит для работы с различными типами данных:
- Табличные данные со столбцами различных типов, как в таблицах SQL или Excel.
- Упорядоченными и неупорядоченными данными (не обязательно с постоянной частотой) временных рядов.
- Произвольными матричными данными (однородными или разнородными) с помеченными строками и столбцами.
- Любыми другими формами наборов данных наблюдений, либо статистических данных. Данные на самом деле не требуют обязательного наличия метки для того, чтобы быть помещенными в структуру данных pandas.
Для установки пакета pandas выполняем в Терминале Linux:
1 2 | sudo apt-get update sudo apt-get install python-pandas |
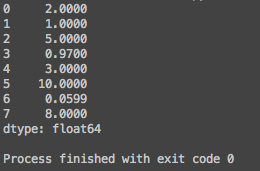
Простенький код, преобразующий одномерный массив в структуру данных pandas:
1 2 3 4 5 6 | importpandas aspd importnumpy asnp values=np.array([2.0,1.0,5.0,0.97,3.0,10.0,0.0599,8.0]) ser=pd.Series(values) printser |
Результатом будет:
matplotlib
![]()
matplotlib является библиотекой графических построений для языка программирования Python и его расширения вычислительной математики NumPy. Библиотека обеспечивает объектно-ориентированный API для встраивания графиков в приложения, используя инструменты GUI общего назначения, такие как WxPython, Qt, или GTK+. Существует также процедурный pylab-интерфейс напоминающий MATLAB. SciPy использует matplotlib.
Сайт библиотеки: matplotlib.org
Для установки библиотеки matpoltlib в Linux выполните следующие команды:
1 2 | sudo apt-get update sudo apt-get install python-matplotlib |
Пример кода, использующий библиотеку matplotlib для создания гистограмм:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | importnumpy asnp importmatplotlib.mlab asmlab importmatplotlib.pyplot asplt # example data mu=100# mean of distribution sigma=15# standard deviation of distribution x=mu+sigma*np.random.randn(10000) num_bins=50 # the histogram of the data n,bins,patches=plt.hist(x,num_bins,normed=1,facecolor='green',alpha=0.5) # add a 'best fit' line y=mlab.normpdf(bins,mu,sigma) plt.plot(bins,y,'r--') plt.xlabel('Smarts') plt.ylabel('Probability') plt.title(r'Histogram of IQ: $mu=100$, $sigma=15$') # Tweak spacing to prevent clipping of ylabel plt.subplots_adjust(left=0.15) plt.show() |
Результатом которого является:

По-моему, очень даже симпатично!
IPython
![]()
IPython является командной оболочкой для интерактивных вычислений на нескольких языках программирования, первоначально разработанной для языка программирования Python. IPython позволяет расширить возможности представления, добавляет синтаксис оболочке, автодополнение и обширную историю команд. IPython в настоящее время предоставляет следующие возможности:
- Мощные интерактивные оболочки (терминального типа и основанную на Qt).
- Браузерный редактор с поддержкой кода, текста, математических выражений, встроенных графиков и других возможностей представления.
- Поддерживает интерактивную визуализацию данных и использование инструментов GUI.
- Гибкие, встраиваемые интерпретаторы для работы в собственных проектах.
- Простые в использовании, высокопроизводительные инструменты для параллельных вычислений.
Сайт IPython: www.ipython.org
Для установки IPython в Linux, выполняем следующие команды в терминале:
1 2 | sudo apt-get update sudo pip install ipython |
Замечательное видео, демонстрирующее возможности IPython:
[youtube width="600"]http://www.youtube.com/watch?v=H6dLGQw9yFQ#t=149[/youtube]
scikit-learn
Пакет, в котором находятся реализации множества различных алгоритмов машинного обучения и data mining.
Сайт пакета: scikit-learn.org
Для установки выполняем в Терминале Linux:
1 2 | sudo apt-get update sudo apt-get install python-sklearn |
Приведу пример кода, строящего линейную регрессию для некоторого набора данных, имеющихся в пакете scikit-learn:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | importmatplotlib.pyplot asplt importnumpy asnp fromsklearn importdatasets,linear_model # Load the diabetes dataset diabetes=datasets.load_diabetes() # Use only one feature diabetes_X=diabetes.data[:,np.newaxis] diabetes_X_temp=diabetes_X[:,:,2] # Split the data into training/testing sets diabetes_X_train=diabetes_X_temp[:-20] diabetes_X_test=diabetes_X_temp[-20:] # Split the targets into training/testing sets diabetes_y_train=diabetes.target[:-20] diabetes_y_test=diabetes.target[-20:] # Create linear regression object regr=linear_model.LinearRegression() # Train the model using the training sets regr.fit(diabetes_X_train,diabetes_y_train) # The coefficients print('Coefficients: ',regr.coef_) # The mean square error print("Residual sum of squares: %.2f" %np.mean((regr.predict(diabetes_X_test)-diabetes_y_test)**2)) # Explained variance score: 1 is perfect prediction print('Variance score: %.2f'%regr.score(diabetes_X_test,diabetes_y_test)) # Plot outputs plt.scatter(diabetes_X_test,diabetes_y_test,color='black') plt.plot(diabetes_X_test,regr.predict(diabetes_X_test),color='blue', linewidth=3) plt.xticks(()) plt.yticks(()) plt.show() |
Результатом работы будет график:
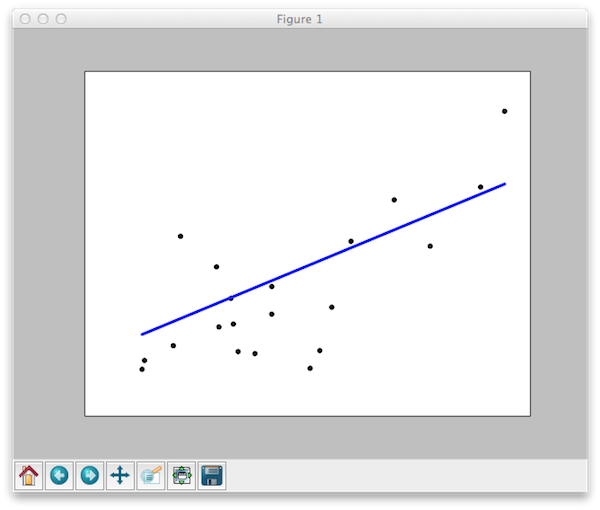
и параметры полученной регрессии:
1 2 3 | ('Coefficients: ',array([938.23786125])) Residual sum of squares:2548.07 Variance score:0.47 |
Источник: robotosha.ru