Обнаружение птиц с помощью Azure ML Workbench
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-11-13 18:52
 Статья является переводом материала Bird Detection with Azure ML Workbench.
Статья является переводом материала Bird Detection with Azure ML Workbench.Данные
Видеоролик ниже предоставлен Абрамом Флейшманом (Университет штата в Сан-Хосе) и компанией Conservation Metrics, Inc. В нем запечатлена естественная среда обитания красноногих моевок — вида птиц, для которого необходимо разработать средство обнаружения. Используя различное оборудование, в том числе альпинистское снаряжение, биологи устанавливают камеры на скалах, чтобы делать снимки как днем, так и ночью.Для обучения модели использовались фотографии, а разметка изображений выполнялась с помощью Visual Object Tagging Tool (VOTT). Разметка данных заняла примерно 20 часов, за это время было отмечено около 12 000 ограничивающих рамок.
 Размеченные данные доступны в репозитории на GitHub.
Размеченные данные доступны в репозитории на GitHub.Откуда данные
Эти данные были собраны доктором Рейчел Орбен (Университет штата Орегон), Абрамом Флейшманом (Университет штата в Сан-Хосе) и компанией Conservation Metrics, Inc. в рамках крупного проекта по исследованию раннего гнездового периода красноногой моевки, определению влияния фактора доступности пищи и анализу негнездового периода на Беринговом море (Аляска).Обнаружение объекта
Подробнее о технологиях обнаружения объекта можно узнать в записи блога о сверточных нейронных сетях (CNN). Faster R-CNN (Region proposals with Convolutional Neural Network) — сравнительно новый подход (первый документ о данном методе был опубликован в 2015 году). Он широко используется сообществом специалистов по машинному обучению и теперь внедрен в самые популярные фреймворки глубокой нейронной сети (DNN), включая PyTorch, CNTK, Tensorflow, Caffe и другие.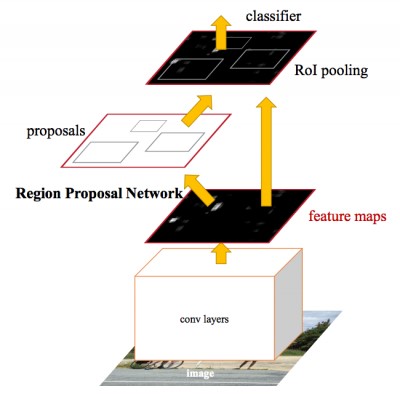 В этой статье мы рассмотрим API обнаружения объектов с помощью алгоритма Faster R-CNN во фреймворках CNTK и Tensorflow.
В этой статье мы рассмотрим API обнаружения объектов с помощью алгоритма Faster R-CNN во фреймворках CNTK и Tensorflow.Azure Machine Learning Workbench
Для обучения модели и создания веб-служб прогнозирования мы использовали недавно анонсированную платформу Azure Machine Learning Workbench. Она представляет собой набор аналитических инструментов и позволяет специалистам по работе с данными подготавливать данные, запускать эксперименты машинного обучения и развертывать модели в облачной среде (см. документацию в разделе «Установка и настройка»).Поскольку нам предстоит работа с изображениями, мы использовали образцы классификации рукописных цифр MNIST в CNTK и Tensorflow — инструмент для начала эксперимента.
 Как правило, обучение глубокой нейронной сети (DNN) выполняется эффективно при использовании графического процессора (GPU), который существенно ускоряет выполнение ряда операций над матрицами. Чтобы обучать модели, мы развернули виртуальные машины для обработки и анализа данных с GPU и использовали удаленную среду выполнения Docker, имеющуюся в Azure ML Workbench (см. раздел «Сведения» и дополнительную информацию о целевых платформах).
Как правило, обучение глубокой нейронной сети (DNN) выполняется эффективно при использовании графического процессора (GPU), который существенно ускоряет выполнение ряда операций над матрицами. Чтобы обучать модели, мы развернули виртуальные машины для обработки и анализа данных с GPU и использовали удаленную среду выполнения Docker, имеющуюся в Azure ML Workbench (см. раздел «Сведения» и дополнительную информацию о целевых платформах).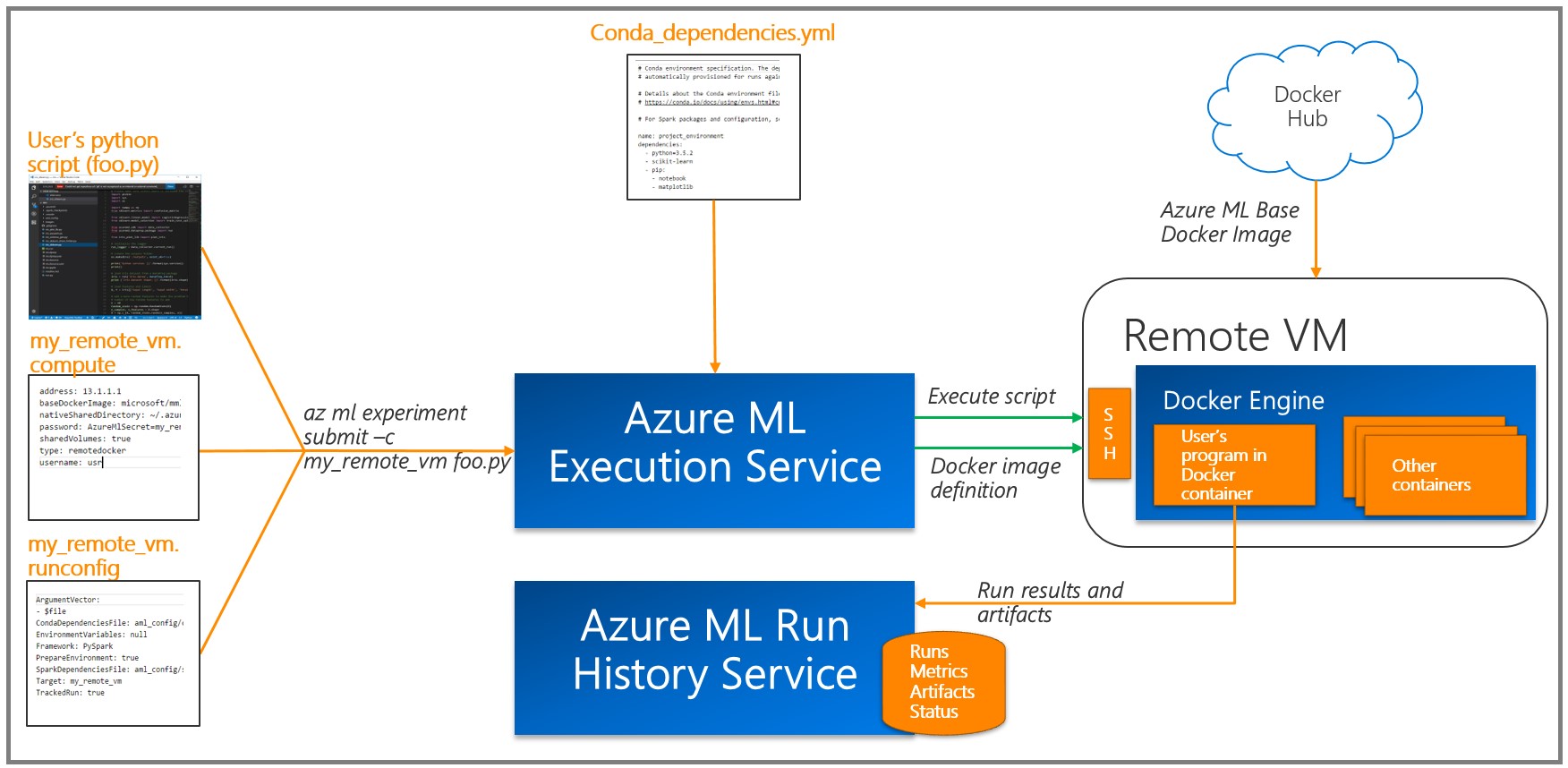 Azure ML записывает результаты каждого задания (эксперимента) в журнал выполнения. Поскольку в экспериментах использовались различные комбинации параметров модели, эта возможность оказалась весьма полезной: имеющиеся средства визуализации помогают выбрать модель с лучшей производительностью. Обратите внимание, что необходимо добавить инструмент с помощью API ведения журнала Azure ML к коду для обучения/оценки, чтобы отслеживать нужные метрики (например, точность классификации).
Azure ML записывает результаты каждого задания (эксперимента) в журнал выполнения. Поскольку в экспериментах использовались различные комбинации параметров модели, эта возможность оказалась весьма полезной: имеющиеся средства визуализации помогают выбрать модель с лучшей производительностью. Обратите внимание, что необходимо добавить инструмент с помощью API ведения журнала Azure ML к коду для обучения/оценки, чтобы отслеживать нужные метрики (например, точность классификации).Разметка изображений и экспорт
Мы использовали служебную программу VOTT (доступна для Windows и MacOS) для разметки и экспорта данных в CNTK и форматы Tensorflow Pascal соответственно.Это инструмент с удобным интерфейсом для идентификации, который позволяет разметить нужные области на изображениях и видео. Для работы с ним необходимо собрать изображения в папку, затем запустить VOTT, указать набор данных изображений и перейти к разметке областей.
 По окончании нажмите Object Detection (Обнаружение объектов), затем Export Tags (Экспортировать теги) для экспорта в CNTK и Tensorflow.
По окончании нажмите Object Detection (Обнаружение объектов), затем Export Tags (Экспортировать теги) для экспорта в CNTK и Tensorflow.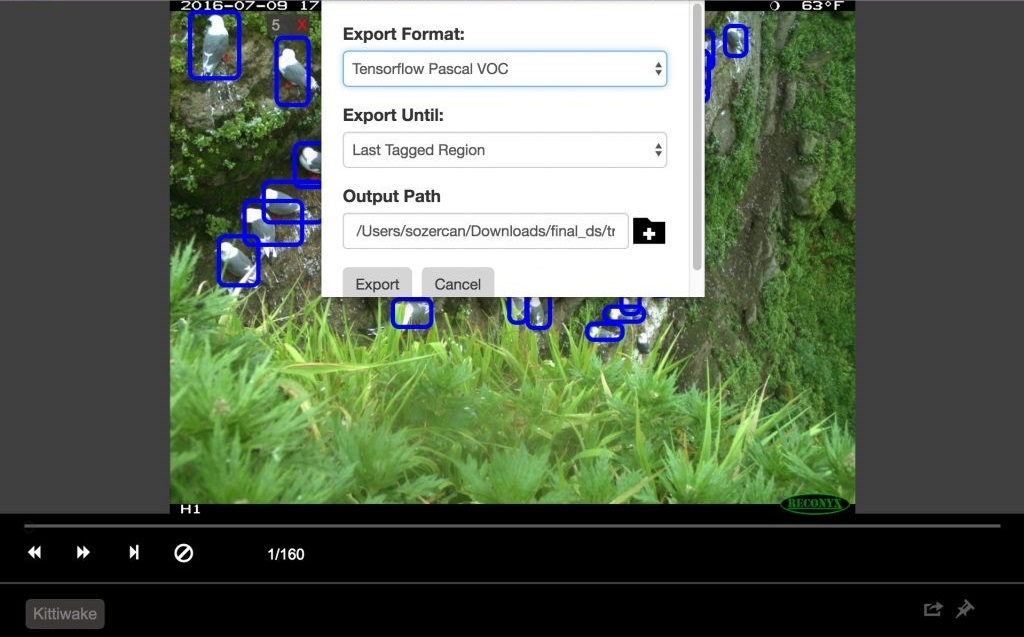 В Tensorflow форматом экспорта является VOC Pascal, поэтому мы преобразовали данные в формат TFRecords для использования при обучении и оценке. Подробнее мы расскажем ниже.
В Tensorflow форматом экспорта является VOC Pascal, поэтому мы преобразовали данные в формат TFRecords для использования при обучении и оценке. Подробнее мы расскажем ниже.Обучение модели обнаружения птиц с помощью CNTK
Как указано в предыдущем разделе, в модели обнаружения птиц мы использовали популярный алгоритм Faster R-CNN. В этом разделе мы сосредоточимся на двух аспектах нашего подхода:- Использование Azure ML Workbench для начала обучения на удаленных ВМ.
- Настройка гиперпараметров через Azure ML Workbench.
Использование Azure ML Workbench для обучения на удаленной ВМ
Настройка гиперпараметров — главный этап процесса построения готовых к использованию моделей машинного обучения (или глубокого обучения) при условии, что первый проект модели показал хорошие результаты. Здесь проблема заключается в эффективной реализации и упрощении процесса посредством Azure ML Workbench.Для настройки параметров требуется выполнение большого количества обучающих экспериментов, что обычно занимает очень много времени. В основе одного из подходов лежит обучение на мощном локальном компьютере или кластере. Однако наш подход направлен на обучение в облаке с помощью контейнеров Docker на удаленных (виртуальных) машинах. Главное преимущество состоит в том, что теперь мы можем выдавать необходимое число контейнеров для параллельной настройки параметров. В соответствии с этой документацией для Azure ML необходимо зарегистрировать каждую виртуальную машину в качестве целевого объекта вычислений для эксперимента. Обратите внимание, что существуют ограничения на символы пароля, например, использование символа «*» в пароле вызовет ошибку.
az ml computetarget attach --name "my_dsvm" --address "my_dsvm_ip_address" --username "my_name" --password "my_password" --type remotedockerПосле выполнения команды будут созданы файлы
myvm.compute и myvm.rucomfig в папке aml_config. Поскольку наша задача больше подходит для машины с GPU, необходимо внести следующие изменения:В myvm.compute
baseDockerImage: microsoft/mmlspark:plus-gpu-0.7.91 nvidiaDocker: trueВ myvm.runconfig
EnvironmentVariables: "STORAGE_ACCOUNT_NAME": "STORAGE_ACCOUNT_KEY": Framework: Python PrepareEnvironment: true Мы использовали хранилище Azure, чтобы сохранить данные для обучения, предварительно обученные модели и контрольные точки модели. Учетные данные хранилища приводятся как
EnvironmentVariables. Убедитесь, что в conda_dependencies.yml включены нужные пакеты.Теперь мы можем выполнить команду для запуска подготовки машины.
az ml experiment –c prepare myvmЗатем выполним обучение модели обнаружения объектов.
az ml experiment submit –c Detection/FasterRCNN/run_faster_rcnn.py .. .. .. Evaluating Faster R-CNN model for 53 images. Number of rois before non-maximum suppression: 8099 Number of rois after non-maximum suppression: 1871 AP for Kittiwake = 0.7544 Mean AP = 0.7544 Настройка гиперпараметров через Azure ML Workbench
С помощью Azure ML и Workbench можно легко записывать гиперпараметры и другие метрики производительности, параллельно запуская несколько контейнеров (подробную информацию см. в разделе «Сведения о ведении журнала» в документации).Первый подход, который следует попробовать, заключается в использовании разных предварительно обученных базовых моделей. На момент написания этой статьи метод CNTK Faster R-CNN API поддерживал две базовые модели: AlexNet и VGG16. Мы можем использовать эти обученные модели для выделения признаков изображения. Несмотря на то, что эти базовые модели обучались на других наборах данных, таких как ImageNet, на низком и среднем уровне признаки изображений одинаковы в различных приложениях и, следовательно, общедоступны. Это явление известно как «перенос обучения».
В AlexNet — пять сверточных CONV-слоев, в то время как VGG16 — двенадцать. Количество обучаемых параметров в VGG16 — 138 миллионов, что превосходит AlexNet почти в три раза; в качестве базовой модели мы использовали здесь VGG16. Ниже приводятся гиперпараметры VGG16, оптимизированные для достижения лучшей производительности на оценочном множестве.
В Detection/FasterRCNN/FasterRCNN_config.py:
# Learning parameters __C.CNTK.L2_REG_WEIGHT = 0.0005 __C.CNTK.MOMENTUM_PER_MB = 0.9 # The learning rate multiplier for all bias weights __C.CNTK.BIAS_LR_MULT = 2.0 В Detection/utils/configs/VGG16_config.py:
__C.MODEL.E2E_LR_FACTOR = 1.0 __C.MODEL.RPN_LR_FACTOR = 1.0 __C.MODEL.FRCN_LR_FACTOR = 1.0 Azure ML Workbench существенно упрощает визуализацию и сравнение разных конфигураций параметров.

mAP с использованием базовой модели VGG16
Evaluating Faster R-CNN model for 53 images. Number of rois before non-maximum suppression: 6998 Number of rois after non-maximum suppression: 2240 AP for Kittiwake = 0.8204 Mean AP = 0.8204 Инструкции по внедрению см. в репозитории GitHub.
Обучение модели обнаружения птиц с помощью Tensorflow
Недавно компания Google представила мощный набор API для обнаружения объектов. Мы использовали их документацию об обучении средств распознавания животных с помощью технологии облачного машинного обучения Google Cloud Machine Learning Engine, что послужило для нас вдохновением при разработке проекта по обучению модели обнаружения моевок на Azure ML Workbench. API обнаружения объектов Tensorflow содержит множество предварительно обученных моделей на наборе данных COCO. В наших экспериментах в качестве базовой модели мы использовали ResNet-101 (глубокая остаточная сеть, 101 слой) и применяли конфигурации примера по распознаванию животных для начала настройки обучения обнаружения объектов.Этот репозиторий содержит скрипты, используемые для обучения моделей обнаружения объектов посредством Azure ML Workbench и Tensorflow.
Подготовка обучения
Этап 1. Подготовьте данные в формате TF Records, который требуется для API обнаружения объектов Tensorflow. Для этого подхода необходимо преобразовать стандартные выходные данные инструмента VOTT. Подробные сведения смотрите в универсальном преобразователе create_pascal_tf_record.py.python create_pascal_tf_record.py --label_map_path=/data/pascal_label_map.pbtxt --data_dir=/data/ --output_path=/data/out/pascal_train.record --set=train python create_pascal_tf_record.py --label_map_path=/data/pascal_label_map.pbtxt --data_dir=/data/ --output_path=/data/out/pascal_val.record --set=val Этап 2. Создайте пакет кода Tensorflow Object Detection и Slim для дальнейшей установки в образе Docker, который используется для экспериментирования. Ниже приведены этапы из документации Tensorflow по обнаружению объектов:
# From tensorflow/models/research/ python setup.py sdist (cd slim && python setup.py sdist) Затем переместите созданные tar-файлы в доступное для экспериментирования место (например, в хранилище больших двоичных объектов) и разместите ссылку в
conda_dependancies.yaml для эксперимента.dependencies: -python=3.5.2 -tensorflow-gpu -pip: #... More dependencies here… #TF Object Detection -<a href="https://olgalidata.blob.core.windows.net/tfobj/object_detection-0.1_3.tar.gz">https:///object_detection-0.1.tar.gz</a> -<a href="https://olgalidata.blob.core.windows.net/tfobj/slim-0.1.tar.gz">https://</a><a href="https://olgalidata.blob.core.windows.net/tfobj/object_detection-0.1_3.tar.gz">/</a><a href="https://olgalidata.blob.core.windows.net/tfobj/slim-0.1.tar.gz">/slim-0.1.tar.gz</a> Этап 3. В скрипте эксперимента добавьте импорт.
from object_detection.train import main as training_moduleЗатем вызовите процедуру обучения в своем коде с помощью функции training_module(_).
Процесс обучения и оценки
Обнаружение объекта Tensorflow Object Detection API предполагает запуск обучения и оценки (проверки эффективности работы модели на текущий момент) путем выполнения двух отдельных команд из командной строки. При запуске нескольких экспериментов целесообразно периодически запускать оценку (например, каждые 100 итераций) для анализа способности модели распознавать объекты в скрытых данных.В случае Tensorflow Object Detection AP мы добавили train_eval.py, который демонстрирует подход к непрерывному обучению и оценке.
print("Total number of training steps {}".format(train_config.num_steps)) print("Evaluation will run every {} steps".format(FLAGS.eval_every_n_steps)) train_config.num_steps = current_step while current_step <= total_num_steps: print("Training steps # {0}".format(current_step)) trainer.train(create_input_dict_fn, model_fn, train_config, master, task, FLAGS.num_clones, worker_replicas, FLAGS.clone_on_cpu, ps_tasks, worker_job_name, is_chief, FLAGS.train_dir) tf.reset_default_graph() evaluate_step() tf.reset_default_graph() current_step = current_step + FLAGS.eval_every_n_steps train_config.num_steps = current_step Чтобы установить несколько гиперпараметров модели и оценить их влияние на модель, мы разделили данные на обучающее, валидационное (настраиваемое) и тестовое множества: 160 изображений, 54 и 55 изображений соответственно.
Сравнение прогонов
Фреймворк обнаружения объектов Tensorflow предоставляет пользователям разные настройки параметров, позволяя подобрать оптимальный вариант для определенного набора данных.В этом упражнении мы сделаем несколько прогонов и посмотрим, какой из них обеспечит лучшую производительность модели. В качестве целевой метрики мы будем использовать точность обнаружения объекта, которая обычно определяется как mAP (Mean Average Precision, усредненная величина средней точности). В каждом прогоне мы используем
azureml.logging для получения сведений о максимальном показателе mAP и выявления обучающих итераций. Кроме того, мы строим график «mAP и итерации» и затем сохраняем его в папку выходных данных для отображения в Azure ML Workbench.Интеграция событий TensorBoard с Azure ML Workbench
TensorBoard — мощный инструмент для отладки и визуализации глубоких нейронных сетей (DNN). Tensorflow Object Detection API уже предоставляет итоговые метрики для точности. В этом проекте мы интегрировали итоговые события Tensorflow, используемые TensorBoard для визуализации, с Azure ML Workbench.<span class="pl-k">from</span> tensorboard.backend.event_processing <span class="pl-k">import</span> event_accumulator <span class="pl-k">from</span> azureml.logging <span class="pl-k">import</span> get_azureml_logger ea = event_accumulator.EventAccumulator(eval_path, ...) df = pd.DataFrame(ea.Scalars('Precision/mAP@0.5IOU')) max_vals = df.loc[df["value"].idxmax()] #Plot chart of how mAP changers as training progresses fig = plt.figure(figsize=(6, 5), dpi=75) plt.plot(df["step"], df["value"]) plt.plot(max_vals["step"], max_vals["value"], "g+", mew=2, ms=10) fig.savefig("./outputs/mAP.png", bbox_inches='tight') # Log to AML Workbench best mAP of the run with corresponding iteration N run_logger = get_azureml_logger() run_logger.log("max_mAP", max_vals["value"]) run_logger.log("max_mAP_interation#", max_vals["step"]) Для получения подробных сведений см. код results_logger.py.
Здесь представлен анализ нескольких прогонов обучения, проведенных с помощью инфраструктуры для экспериментирования Azure ML Workbench.
Прогон №1 использует метод стохастического градиентного спуска, аугментация данных отключена (для обзора возможностей градиентной оптимизации см. эту запись блога).
В журнале выполнения в Azure ML Workbench приведены подробные сведения о каждом прогоне:
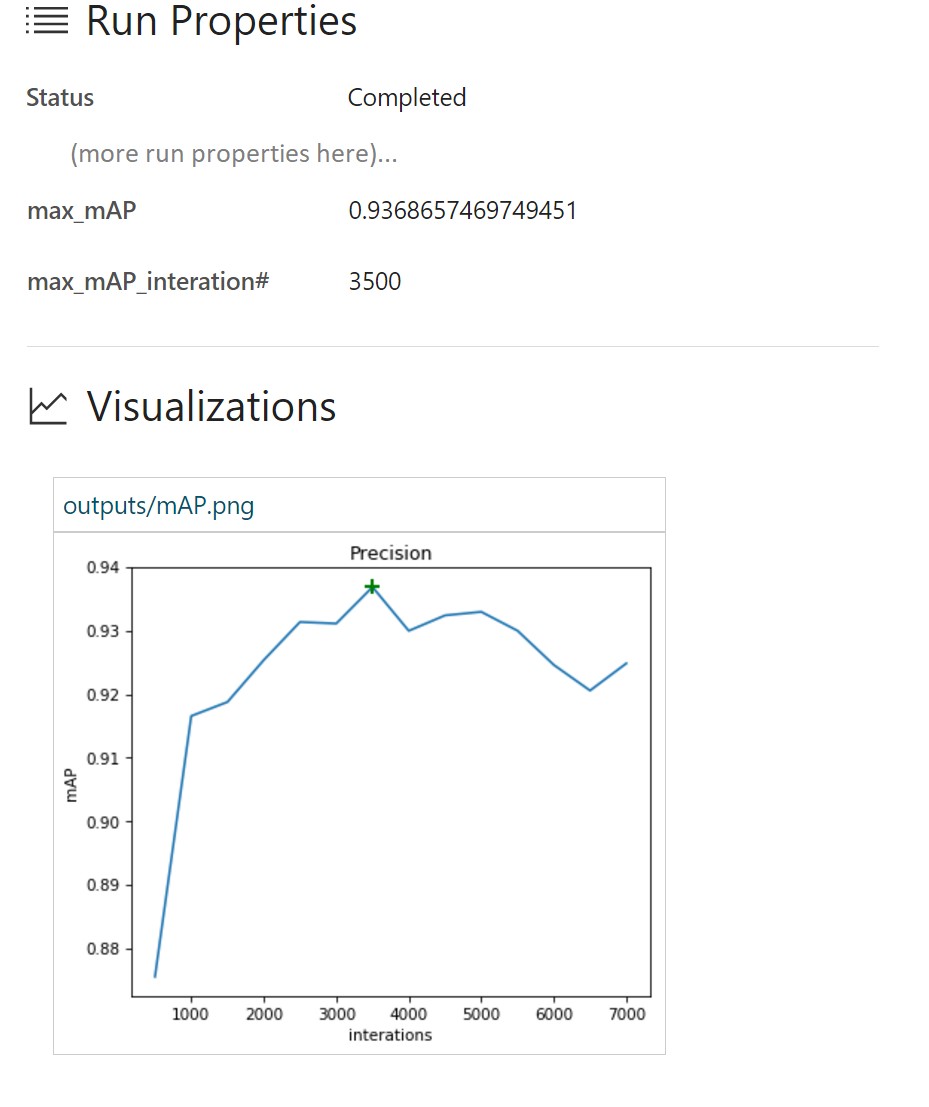 В данном случае мы видим, что максимальное значение mAP составило 93,37 % примерно при 3 500 итерациях. Соответственно происходит переобучение модели под данные обучения, и производительность на тестовом множестве начинает падать.
В данном случае мы видим, что максимальное значение mAP составило 93,37 % примерно при 3 500 итерациях. Соответственно происходит переобучение модели под данные обучения, и производительность на тестовом множестве начинает падать.Прогон № 2 использует усовершенствованный оптимизационный алгоритм Adam. Все остальные параметры такие же.
 Здесь значение mAP 93,6 % достигнуто намного быстрее, чем в прогоне №1. Судя по всему, переобучение модели наступает намного раньше, так как значение точности на оценочном множестве быстро уменьшается.
Здесь значение mAP 93,6 % достигнуто намного быстрее, чем в прогоне №1. Судя по всему, переобучение модели наступает намного раньше, так как значение точности на оценочном множестве быстро уменьшается.Прогон №3 добавляет аугментацию данных к конфигурации обучения. Для последующих прогонов мы оставим оптимизационный алгоритм Adam.
data_augmentation_options{ random_horizontal_flip{} } 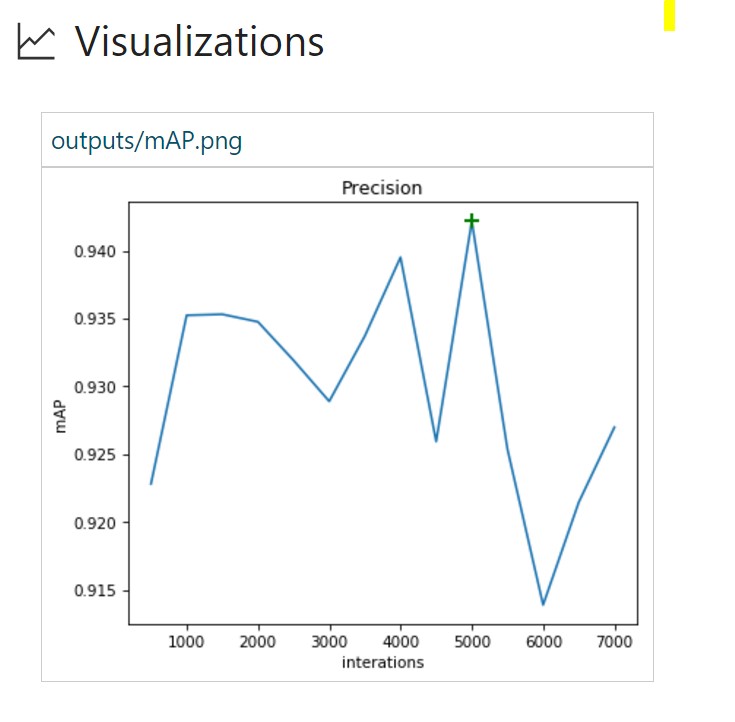
Случайное горизонтальное отображение изображений позволило улучшить показатели mAP с 93,6 в прогоне № 2 до 94,2%. Также требуется больше итераций для переобучения модели.
Прогон №4 содержит больше параметров аугментации данных.
data_augmentation_options{ random_horizontal_flip{} random_pixel_value_scale{} random_crop_image{} } Ниже представлены интересные результаты:
 Несмотря на то, что значение mAP не максимально (91,1%), после 7 000 итераций не происходит переобучение. При этом логично продолжить обучение этой модели, чтобы понять, можно ли повысить значение mAP.
Несмотря на то, что значение mAP не максимально (91,1%), после 7 000 итераций не происходит переобучение. При этом логично продолжить обучение этой модели, чтобы понять, можно ли повысить значение mAP.Здесь представлен краткий обзор процесса обучения с использованием Azure ML Workbench:
 Azure ML Workbench позволяет пользователям параллельно сравнивать прогоны (ниже приведены прогоны №№ 1, 3 и 4):
Azure ML Workbench позволяет пользователям параллельно сравнивать прогоны (ниже приведены прогоны №№ 1, 3 и 4): Кроме того, мы можем строить графики с результатами оценок на нужном изображении (изображениях) и также использовать их при сравнении значений. События TensorBoard уже содержат все необходимые данные.
Кроме того, мы можем строить графики с результатами оценок на нужном изображении (изображениях) и также использовать их при сравнении значений. События TensorBoard уже содержат все необходимые данные.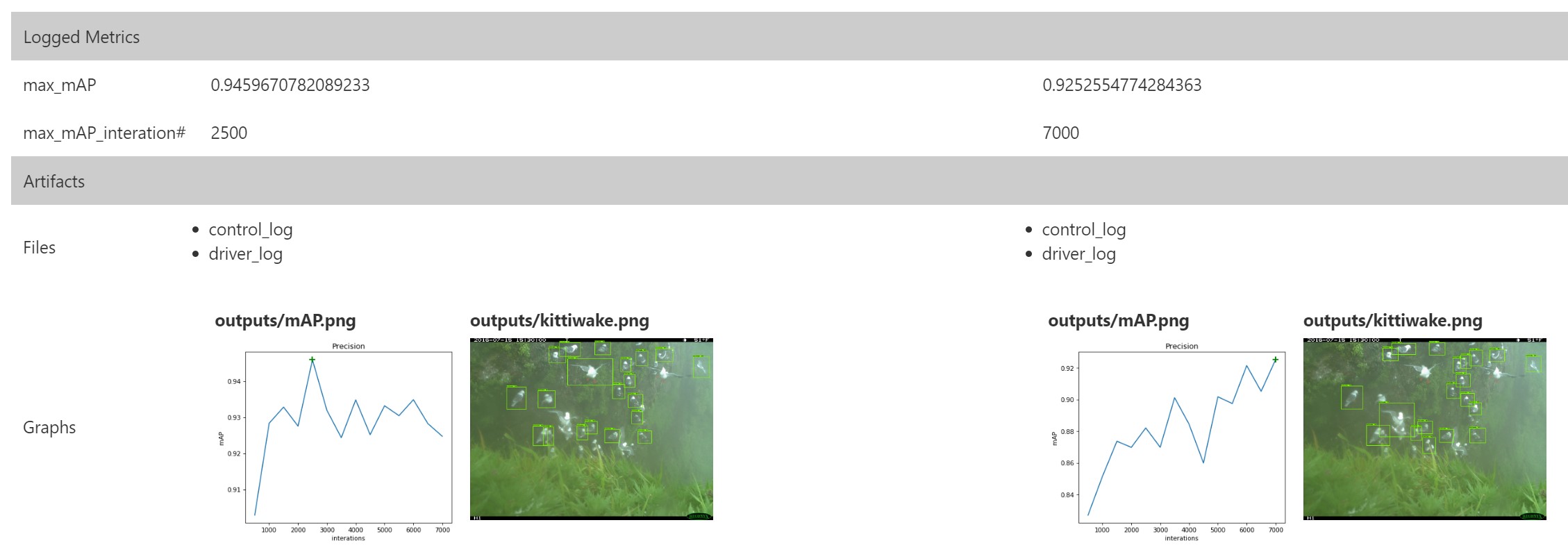 Таким образом, обнаружение объектов на основе ResNet позволяет нам добиться лучших результатов даже на небольших наборах данных. Azure ML Workbench имеет полезную инфраструктуру, которая предоставляет единую область для выполнения экспериментов и сравнения результатов.
Таким образом, обнаружение объектов на основе ResNet позволяет нам добиться лучших результатов даже на небольших наборах данных. Azure ML Workbench имеет полезную инфраструктуру, которая предоставляет единую область для выполнения экспериментов и сравнения результатов.Развертывание оценивающей веб-службы
После разработки модели обнаружения объекта и классификации с достаточной производительностью приступаем к развертыванию модели в виде размещенной веб-службы таким образом, чтобы получить возможность подключиться к приложению для наблюдения за птицами. Мы покажем, как это можно сделать с помощью встроенных средств Azure ML, и как выполнить настраиваемое развертывание.Веб-службы, использующие Azure ML CLI
Azure ML предоставляет расширенную поддержку операционализации модели на локальных компьютерах или облачной платформе Azure.Установка Azure ML CLI
Перед развертыванием модели в виде веб-службы, необходимо выполнить SSH на используемой ВМ.ssh @В этом примере мы используем ВМ для обработки и анализа данных Azure, на которой установлен Azure CLI. При использовании другой ВМ установите Azure CLI с помощью:
pip install azure-cli pip install azure-cli-ml Выполните вход, используя:
az loginПодготовка среды
Сначала выполните регистрацию поставщика среды с помощью:az provider register -n Microsoft.MachineLearningComputeПри развертывании веб-службы на локальном компьютере в первую очередь нужно подготовить среду:
az ml env setup -l [Azure region, e.g. eastus2] -n [environment name] -g [resource group]Этот этап позволит создать группу ресурсов, учетную запись хранения, реестр контейнеров Azure (ACR) и учетную запись Application Insights.
Настройте среду, как было показано:
az ml env set -n [environment name] -g [resource group]Создайте учетную запись управления моделью:
az ml account modelmanagement create -l [Azure region, e.g. eastus2] -n [your account name] -g [resource group name] --sku-instances [number of instances, e.g. 1] --sku-name [Pricing tier for example S1]Теперь можно приступить к развертыванию модели! Вы можете создать службу с помощью:
az ml service create realtime --model-file [model file/folder path] -f [scoring file e.g. score.py] -n [your service name] -r [runtime for the Docker container e.g. spark-py or python] -c [conda dependencies file for additional python packages]Обратите внимание, что на данный момент nvidia-docker не доступен для прогнозирования. Убедитесь, что изменили зависимости Conda, чтобы удалить любые ссылки, относящиеся к GPU, такие как tensorflow-gpu.
После развертывания службы вы можете просмотреть сведения о том, как использовать веб-службу с:
az ml service usage realtime -i [your service name]Например, вы можете протестировать службу с помощью команды
curl:curl -X POST -H "Content-Type:application/json" --data !! YOUR DATA HERE !! http://127.0.0.1:32769/scoreАльтернативный вариант развертывания оценивающей веб-службы
Другой способ развертывания веб-службы для прогнозирования — это создание собственного экземпляра веб-сервера Sanic. Sanic — это веб-сервер Python 3.5+, похожий на Flask, который позволяет создавать и запускать веб-приложения. Мы можем использовать модель, обученную с использованием CNTK и Faster R-CNN в предыдущем разделе, чтобы выполнять прогнозирование для идентификации местоположения птицы на изображении.Сначала нужно создать веб-приложение Sanic. Вы можете использовать следующий фрагмент кода (и app.py), чтобы создать веб-приложение и определить, где на сервере оно будет выполняться. Для каждого нужного API можно задать маршруты, методы HTTP и способы обработки каждого запроса.
app = Sanic(__name__) Config.KEEP_ALIVE = False server = Server() server.set_model() @app.route('/') async def test(request): return text(server.server_running()) @app.route('/predict', methods=["POST",]) def post_json(request): return json(server.predict(request)) app.run(host= '0.0.0.0', port=80) print ('exiting...') sys.exit(0) Как только будет определено веб-приложение, необходимо реализовать логику, чтобы использовать путь изображения и возвращать прогнозируемые результаты пользователю.
Используя predict.py, мы сначала загружаем изображение, для которого нужно построить прогноз, затем оцениваем его относительно предварительно обученной модели для возврата прогнозируемых данных в JSON.
regressed_rois, cls_probs = evaluate_single_image(eval_model, img_path, cfg) bboxes, labels, scores = filter_results(regressed_rois, cls_probs, cfg) Возвращаемый JSON — это массив прогнозируемых меток и ограничивающих рамок для каждой птицы, обнаруженной на изображении:
[{"label": "Kittiwake", "score": "0.963", "box": [246, 414, 285, 466]},...]Теперь, когда мы внедрили логику прогнозирования и веб-службу, мы можем разместить приложение на сервере. Мы будем использовать Docker, чтобы зависимости развертывания и сам процесс были простыми и воспроизводимыми.
cd CNTK_faster-rcnn/DetectionСоздайте образ Docker с помощью Dockerfile, чтобы можно было запустить приложение в качестве контейнера Docker:
FROM hsienting/dl_az COPY ./ /app ADD run.sh /app/ RUN chmod +x /app/run.sh ENV STORAGE_ACCOUNT_NAME ENV STORAGE_ACCOUNT_KEY ENV AZUREML_NATIVE_SHARE_DIRECTORY /cmcntk ENV TESTIMAGESCONTAINER data EXPOSE 80 ENTRYPOINT ["/app/run.sh"] Теперь мы можем построить образ Docker, запустив:
docker build -t cmcntk .Когда образ Docker cmcntk будет доступен локально, мы сможем запускать его экземпляры в виде контейнеров. С помощью команды ниже мы подключаем узел-том к cmcntk в контейнере для обеспечения устойчивости данных (это касается предыдущего этапа, когда мы обучали модель). Затем мы сопоставим порт узла 80 с портом контейнера 80 и запустим последний образ Docker cncntk.
docker run -v /:/cmcntk -p 80:80 -it cmcntk:latestТеперь мы можем протестировать веб-службу с помощью команды curl:
curl -X POST http://localhost/predict -H 'content-type: application/json' -d '{"filename": ""}' Доступ к службам
Теперь наши службы запущены. Что дальше? Как клиент взаимодействует с ними? Как унифицировать их под одним API? Во время нашей работы с Conservation Metrics мы создали приложение в качестве экспериментального решения для выполнения всего процесса классификации.Проблема
Мы знаем, какие операции нужны для приложения, но из-за ряда ограничений текущих служб возможны проблемы с взаимодействием. В том числе:- Многие службы имеют общие цели функционирования (вывод данных разметки), но не имеют общей конечной точки.
- Для непосредственного доступа к этим службам клиенту требуются права CORS (общий доступ к ресурсам независимо от источника), которые должны управляться на всех серверах/балансировщиках нагрузок.
Решение
Чтобы создать универсальную конечную точку API, настроим службу управления Azure API. Таким образом мы можем настроить и выставить конечные точки с поддержкой CORS для наших API.Службы управления Azure API
Начало работы:- Посетите веб-сайт https://ms.portal.azure.com/#create/hub
- Выполните поиск и выберите пункт «API management» (Управление API).
- Создайте и настройте свой экземпляр.
Конфигурация:
- Создайте новый API.

Начальная конфигурация API:
 Выполнив подготовку, перейдите в API. Нажмите кнопку «+Add API» (+Добавить API), затем выберите параметр «Blank API» (Новый API). Настройте API так, чтобы Web service URL был API на внешнем сервере, API URL suffix представлен суффиксом, который будет добавлен к URL-адресу для управления API, и на вкладке Products был отмечен нужный тип API-продукта, под которым вы хотите зарегистрировать эту конечную точку.
Выполнив подготовку, перейдите в API. Нажмите кнопку «+Add API» (+Добавить API), затем выберите параметр «Blank API» (Новый API). Настройте API так, чтобы Web service URL был API на внешнем сервере, API URL suffix представлен суффиксом, который будет добавлен к URL-адресу для управления API, и на вкладке Products был отмечен нужный тип API-продукта, под которым вы хотите зарегистрировать эту конечную точку.В созданном API настройте пункт «Inbound processing» (Обработка входящего трафика) с помощью пункта «Code View» (Просмотр кода) и установите следующие значения для политик (чтобы активировать поддержку CORS для всех внешних URL-адресов):
* * Вы можете работать с API URL Suffix, который вы настроили в разделе управления API, как при непосредственной проверке связи на нашем API.
Несмотря на то что примеры взяты со старого портала управления Azure, возможно, вы захотите ознакомиться с более подробным руководством по началу работы (службы управления API и политика CORS).
Образец приложения
Наш образец клиентского веб-приложения выполняет следующие действия:- Считывает данные с контейнеров/больших двоичных объектов непосредственно из хранилища больших двоичных объектов Azure.
- Проверяет связь новой службы управления Azure API с изображениями в хранилище больших двоичных объектов.
- Отображает возвращаемые данные прогнозирования (ограничивающие рамки для птиц) на изображении.
Код на GitHub.
Проверка связи службы управления API
Единственное отличие проверки связи служб управления API от «родных» API, заключается в том, что во все запросы необходимо добавлять дополнительный заголовок Ocp-Apim-Subscription-Key. Этот ключ подписки привязан к продукту управления API, которые содержит заданные конечные точки API.Чтобы получить ключ подписки:
- Перейдите на «Publisher Portal» (Портал издателя) API.
- Выберите пользователя в соответствующем пункте меню.
- Запишите ключ подписки, который вы хотите использовать.
В этом же образце приложения добавьте этот ключ подписки в качестве значения для прикрепленного заголовка
Ocp-Apim-Subscription-Key:<span class="hljs-keyword">export</span> <span class="hljs-keyword">async</span> <span class="hljs-function"><span class="hljs-keyword">function</span> <span class="hljs-title">cntk</span>(<span class="hljs-params">filename</span>) </span>{ <span class="hljs-keyword">return</span> fetch(<span class="hljs-string">'/tensorflow/'</span>, { method: <span class="hljs-string">'post'</span>, headers: { Accept: <span class="hljs-string">'application/json'</span>, <span class="hljs-string">'Content-Type'</span>: <span class="hljs-string">'application/json'</span>, <span class="hljs-string">'Cache-Control'</span>: <span class="hljs-string">'no-cache'</span>, <span class="hljs-string">'Ocp-Apim-Trace'</span>: <span class="hljs-string">'true'</span>, <span class="hljs-string">'Ocp-Apim-Subscription-Key'</span>: , }, body: <span class="hljs-built_in">JSON</span>.stringify({ filename, }), }) } Использование данных
Теперь вы можете проверять связь служб с изображением и получать список возвращаемых ограничивающих рамок.Базовый вариант использования состоит в дорисовке рамок на изображении. Один простой способ сделать это на веб-клиенте — отобразить изображение и применить наложение рамок, используя:
<span class="xml"><span class="hljs-tag"><<span class="hljs-title">body</span>></span> <span class="hljs-tag"><<span class="hljs-title">canvas</span> <span class="hljs-attribute">id</span>=<span class="hljs-value">'myCanvas'</span>></span><span class="hljs-tag"></<span class="hljs-title">canvas</span>></span> <span class="hljs-tag"><<span class="hljs-title">script</span>></span><span class="javascript"> <span class="hljs-keyword">const</span> imageUrl = <span class="hljs-string">"some image URL"</span>; cntk(imageUrl).then(labels => { <span class="hljs-keyword">const</span> canvas = <span class="hljs-built_in">document</span>.getElementById(<span class="hljs-string">'myCanvas'</span>) <span class="hljs-keyword">const</span> image = <span class="hljs-built_in">document</span>.createElement(<span class="hljs-string">'img'</span>); image.setAttribute(<span class="hljs-string">'crossOrigin'</span>, <span class="hljs-string">'Anonymous'</span>); image.onload = () => { <span class="hljs-keyword">if</span> (canvas) { <span class="hljs-keyword">const</span> canvasWidth = <span class="hljs-number">850</span>; <span class="hljs-keyword">const</span> scale = canvasWidth / image.width; <span class="hljs-keyword">const</span> canvasHeight = image.height * scale; canvas.width = canvasWidth; canvas.height = canvasHeight; <span class="hljs-keyword">const</span> ctx = canvas.getContext(<span class="hljs-string">'2d'</span>); <span class="hljs-comment">// render image on convas and draw the square labels</span> ctx.drawImage(image, <span class="hljs-number">0</span>, <span class="hljs-number">0</span>, canvasWidth, canvasHeight); ctx.lineWidth = <span class="hljs-number">5</span>; labels.forEach((label) => { ctx.strokeStyle = label.color || <span class="hljs-string">'black'</span>; ctx.strokeRect(label.x, label.y, label.width, label.height); }); } }; image.src = imageUrl; }); </span><span class="hljs-tag"></<span class="hljs-title">script</span>></span> <span class="hljs-tag"></<span class="hljs-title">body</span>></span> <span class="hljs-tag"></<span class="hljs-title">html</span>></span> </span> Этот код будет передан на полотно, почти указано как на рисунке ниже:
 Теперь вы можете взаимодействовать с обученной моделью и демонстрационными результатами прогнозирования. Подробные сведения о коде смотрите в этом репозитории на GitHub.
Теперь вы можете взаимодействовать с обученной моделью и демонстрационными результатами прогнозирования. Подробные сведения о коде смотрите в этом репозитории на GitHub.Заключение
В этой статье мы рассмотрели комплексный процесс обнаружения объектов, включая:- разметку данных;
- обучение модели обнаружения объектов CNTK/Tensorflow с использованием Azure ML Workbench;
- сравнение прогонов экспериментов в Azure ML Workbench;
- операционализацию модели и развертывание веб-службы прогнозирования;
- обзор демонстрационного приложения для построения прогнозов.
Ресурсы
- Проектный репозиторий GitHub.
- Документация по машинному обучению Azure Machine Learning Workbench.
- Репозиторий GitHub: обнаружение объектов с Microsoft Cognitive Toolkit.
- Репозиторий GitHub: обнаружение объектов с Tensorflow Object Detection API.
- Полезные курсы: Analyzing Big Data with Microsoft R (и экзамен), Perform Cloud Data Science with Azure Machine Learning (и экзамен) и Performing Data Engineering on Microsoft HD Insight (и экзамен).
Напоминаем, что Azure можно попробовать бесплатно.
Источник: habrahabr.ru