В поисках разума: можно ли сделать “универсальный” чат-бот с помощью нейронных сетей?
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-10-12 08:12
создание чат-ботов, нейросети новости, реализация искусственного интеллекта

Я очень хорошо помню свои ощущения от чтения классической ныне работы [1] где исследователи Google обучили seq2seq нейросеть генерировать ответы, используя огромную базу субтитров к фильмам. Возможности казались неограниченными:
Ч: Меня зовут Джон, как меня зовут?
Н: Джон
Ч: Сколько ног у собаки?
Н: Четыре
Ч: Какого цвета небо?
Н: Голубого
Ч: Есть ли у кошки хвост?
Н: Да
Ч: Есть ли у кошки крылья?
Н: Нет
Диалоги переведены мной на русский. Ч — человек, Н- нейросеть
Разве не удивительно, что сеть, без всяких правил, на базе очень зашумленных данных умеет правильно отвечать на подобные вопросы (которые не встречаются в самих данных в таких формулировках)? Но вскоре, у такого подхода обнаружился ряд проблем:
- Невозможность обновлять долгосрочную память. Например, “Меня зовут Джон”, будет вскоре забыто, как только пропадет из контекста. Из этого следует невозможность запоминать новые факты и как-то с ними оперировать.
- Невозможность получать информацию из внешних источников
- Невозможность перенести знания на другие тематики. Нужно очень много данных для обучения новой модели.
- Невозможность производить какие-либо действия
- Тенденция давать короткие /частые ответы (например, на любой вопрос отвечать словом “да”)
В результате, большинство практических систем сейчас все еще базируется на заранее заготовленных ответах и ранжировании вариантов (с помощью правил и машинного обучения), а идея синтезировать ответы с нуля, по словам, отошла на второй план. Даже Google Smart Reply теперь использует ранжирование [2], хотя и с помощью нейросетей. Ранжирование же может быть эффективным и без понимания смысла — только за счет синтаксических преобразований и простых правил [7]. В наших опытах с ранжированием, даже если оно осуществляется нейросетью, поверхностный анализ доминирует, и только очень большие нейросети демонстрируют только некоторые зачатки общетематических знаний [8].
Также прагматично работают все популярные чат-боты, виртуальные ассистенты и тому подобные программы. Siri и Cortana кажуться высокоинтеллектуальными системами только за счет того, что каждая тематика, которую они понимают, тщательно настраивается вручную [6], что позволяет добиться высокого качества ответов. Но, с другой стороны, по данным некоторых исследований, при всех огромных усилиях, вложенных компаниями в разработку этих помощников, реально их применяют только 13% пользователей телефонов (при этом когда-либо пробовали, но отказались от использования 46% [11] ). К тому же, это технологии известные, поставленные на поток, и заниматься ими скучно. Хочется чего-то потенциально более интеллектуального, но одновременно, не совсем оторванного от практики.
Много лет назад, при чтении различных фантастических романов, мне понравилась идея “Планирующей машины”
— «Информация», — простучал Стив на его клавишах. — «Стивен Райленд, оп. АВС–38440, О.Б.Опорто, оп. ХУЗ–99942, прибыли на… — быстрый взгляд на табличку с кодом, прикрепленную к корпусу телетайпа, — станцию 3, радиус 4–261, Рейкьявик, Исландия. Запрос. Какие следуют указания?».
Через мгновение от Планирующей Машины пришел ответ — всего одна буква: «П». Это означало, что Машина приняла сообщение, поняла его и ввела в банк памяти. Приказы последуют.
Зазвенел сигнал телетайпа. Райленд прочел сообщение:
«Действия. Проследовать к поезду 667, путь 6, купе 93».
Рифы космоса. Фредерик Пол и Джек Уильямсон, 1964
Да, в романах, такая машина часто персонаж отрицательный. Но, как удобно было бы иметь подобную планирующую машину в фирме, чтобы она говорила кому и что делать. А также решала разные вопросы самостоятельно.
Можно, конечно, запрограммировать каждую подобную функцию в отдельности. Этим путем идут разработчики интеллектуальных функций в существующих CRM/BPM системах. Но тем самым мы лишим систему гибкости и обречем штат программистов на постоянное дописывание и переписывание этих функций. Можно ли пойти другим путем?
Основным направлением для преодоления вышеописанных недостатков является снабжение нейросети внешней памятью. Память эта бывает в основном двух видов — дифференцируемая, например в [3] и неифференцируемая. Дифференцируемая память предполагает, что механизмы записи и чтения из памяти сами являются нейросетями и обучаются совместно. Для моделирования диалога в основном используется вариант, где обучается только механизм чтения, а механизм записи содержит жестко запрограммированные элементы (например n слотов памяти, и запись идет как в стек) [4]. Такой механизм сложно масштабировать, т.к. чтобы найти элемент в памяти для каждого элемента надо выполнить вычисления с помощью нейросети. Кроме того, содержимое такой памяти невозможно интерпретировать, редактировать вручную, оно может быть не точным, что существенно осложняет использование системы на практике.
В идеале мы хотим, чтобы нейросеть работала с чем-то, напоминающим традиционную базу данных. Поэтому обратили внимание на работы, связанные с вопросно-ответными системами, сопрягаемыми с большими базами знаний. В частности, мне показалась интересной статья [6], где нейросеть генерирует запросы к графовой базе данных на языке LISP на основании вопросов, задаваемых пользователями. Т.е. нейросеть не прямо обращается к данным, а создает небольшую программу, выполнение которой приводит к получению нужного ответа.
Графовое представление знаний в качестве внешней памяти для нейросетей вообще является достаточно популярным решением, поскольку в него с одной стороны легче уложить разнородные знания о мире, а с другой считается, что эта схема напоминает способ хранения информации в головном мозге человека.
Применительно к нашей задаче, получается следующая схема:
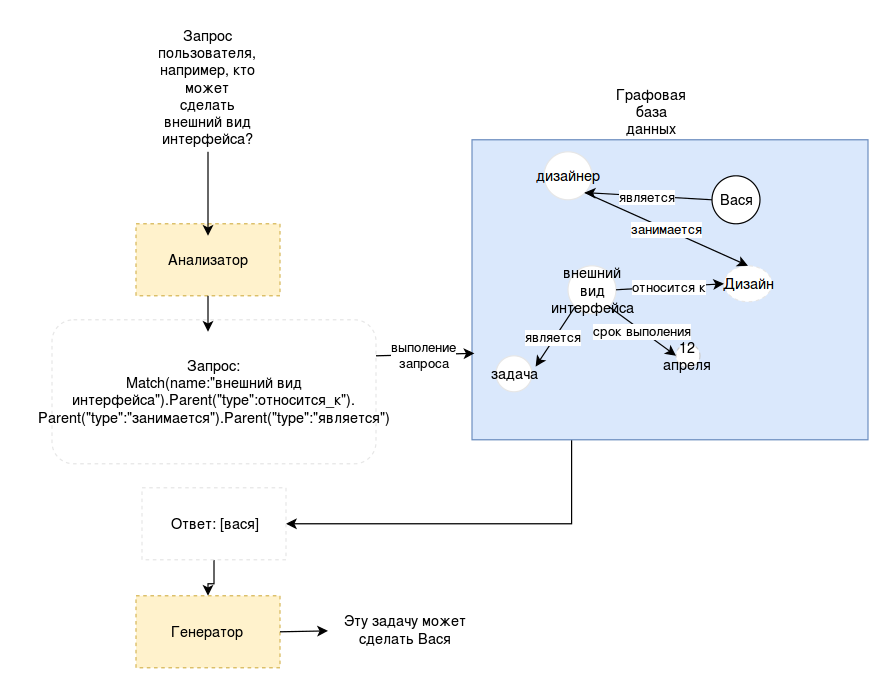 Конечно, мы имеем дело с более сложной проблемой. Во-первых, чтобы система работала, нейросеть должна уметь не только извлекать информацию, но и записывать новые сведения. Очевидно, что одну и ту информацию можно записать совершенно разными способами и, если мы хотим, чтобы система была гибкой, то не можем фиксировать все виды соотношений заранее. А значит, что программа должны будет сама выбирать правильный способ записи информации, и уметь потом достать то, что записала.
Конечно, мы имеем дело с более сложной проблемой. Во-первых, чтобы система работала, нейросеть должна уметь не только извлекать информацию, но и записывать новые сведения. Очевидно, что одну и ту информацию можно записать совершенно разными способами и, если мы хотим, чтобы система была гибкой, то не можем фиксировать все виды соотношений заранее. А значит, что программа должны будет сама выбирать правильный способ записи информации, и уметь потом достать то, что записала. Кроме того, на практике возникнут и другие вопросы:
- Скорость работы. Достаточно ли эффективен такой механизм? Программисты тратят достаточно большие усилия, чтобы спроектировать эффективную структуру базы данных. Что будет, если данные будет организовывать нейросеть?
- Что случится, после нескольких месяцев/лет работы? Существует риск накопления неверной, бессмысленной и плохо организованной информации, которая замусорит систему и сделает работу невозможной.
- Безопасность. Не всем можно сообщать все, и не всем позволено изменять данные. Не вся сообщаемая системе информация может быть достоверной.
- Отсутствие обучающей выборки — где брать данные для обучения нейросети?
- Другие подводные камни
Ясно, что ответить на все вопросы сразу не получится, поэтому самым правильным подходом является постепенная реализация.
На первом этапе понадобиться графовая база данных и какой-то язык для выполнения запросов к ней. Существует довольно много реализаций графовых баз и несколько популярных языков, таких как SPARQL, Cypher и другие. Ясно, что структура языка будет сильно влиять на способность нейросети генерировать запросы на нем, поэтому мы решили сделать собственную надстройку над существующими движками графовых баз данных, включающую специальный язык, который можно будет в дальнейшим оптимизировать. Чтобы упростить разработку, изначально язык был реализован с помощью классов Python и представлял собой фактически подмножество Python
Пример (очень простой):
| Текст | Запрос |
| На склад поступило три подушки | MatchOne({«type»:«склад»}).Add(«name»:«подушки»,«количество»:«3») |
| есть ли на складе подушки ? | MatchOne({«type»:«склад»}).child({«имя»:«подушки»}).NotEmpty( ) |
Обратите внимание, язык описывает как-бы процесс навигации по графу. Есть другой способ посмотреть на тоже самое: представьте, что каждый узел в графе это отдельный нейрон. На вход ему приходит некоторая информация — вектор активации входных нейронов и вектор истории предыдущих активаций. Нейрон работает как классификатор — он выбирает, по какому пути (из имеющихся соединений) пойдет процесс дальше. Это гораздо больше похоже на процесс, который реально может происходить в мозге человека [9,10], по крайней мере на некоторые из существующих теорий работы памяти.
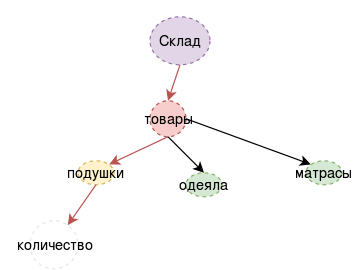
Поэтому, мы решили реализовать всю схему в модельной системе, заменив, временно, нейросеть, на систему правил. Такой подход вполне разумен, поскольку позволяет отладить работу важных компонентов, не утонув сразу в сложностях проблемы в целом, и при этом избежать “игрушечных” модельных задач.
В качестве предмета приложения мы выбрали систему управления проектами (с прицелом на получение когда-нибудь “планирующей машины”). Как выглядел процесс внедрения с точки зрения использования системы, можно прочитать в предыдущей статье (эмпирически, мы узнали кое-что интересное о том, насколько полезен голосовой интерфейс и как правильно организовывать работу над проектами, но это сейчас не основная тема повествования).
Что касается главной схемы вещей, то приобретенный опыт оказался весьма важным. Главные изменения коснулись организации поиска и введению краткосрочной памяти.
Для процесса диалога (что известно давно) очень важен контекст беседы. В использовании нашей системы контекст оказался абсолютно необходимым. Схема с одним большим хранилищем данных возлагает отслеживание полностью на “анализатор”. Для правил эта задача была непосильной, и, для нейросетей, как известно из других исследований, она тоже сложна. Явное представление краткосрочной внешней памяти является сейчас распространенным подходом в диалоговых системах на базе нейросетей [4], и к тому же позволяет показывать содержимое рабочего контекста пользователю, что весьма важно. Поэтому в схеме появился дополнительный блок, хранящий узлы графа, к которым происходило недавнее обращение (либо недавно созданные).
Далее, на практике большинство узлов получало длинные названия (например, названия задач). Сопоставление задач по точному соответствию перестало быть эффективным, поэтому каждый узел графа был снабжен векторным представлением (для начала попробовали сумку слов и сумму word2vec векторов названия). Это позволило с одной стороны встроить в язык команды поиска по нечеткому совпадению, и с другой приблизило нас к структурам данных, которые используются в дифференцируемой внешней памяти. Это вид структуры ключ-значение, где ключ являются вектором, а значение — произвольного вида данные. Вектора значений могут быть обучаемыми, и также могут быть частью механизма адресации в нейронной модели внимания.
В целом, полученный набор компонентов оказался жизнеспособным и пригодным к применению в других проектах. Так что, дальше мы начали работать над заменой анализатора на правилах (который сильно ограничен в возможностях) на нейронную сеть, тем более, что определенный набор диалогов был накоплен в процессе внедрения версии на правилах. Однако, данная тема, похоже уже не укладывается в рамки одной статьи, так как текст уже получился довольно длинный, а про нейросеть придется написать еще как-минимум столько же. Поэтому, продолжение будет в нашем блоге одной из следующих статей, если, поднятая тема вызовет у читателей интерес.
Литература
- Vinyals, Oriol, and Quoc Le. «A neural conversational model.» arXiv preprint arXiv:1506.05869 (2015).
- Henderson, Matthew, et al. «Efficient Natural Language Response Suggestion for Smart Reply.» arXiv preprint arXiv:1705.00652 (2017).
- Kumar, Ankit, et al. «Ask me anything: Dynamic memory networks for natural language processing.» International Conference on Machine Learning. 2016.
- Chen, Yun-Nung, et al. «End-to-End Memory Networks with Knowledge Carryover for Multi-Turn Spoken Language Understanding.» INTERSPEECH. 2016.
- Liang, C., Berant, J., Le, Q., Forbus, K. D., & Lao, N.(2016). Neural symbolic machines: Learning semantic parsers on freebase with weak supervision. arXiv preprintarX iv:1611.0 0 020.
- Sarikaya, Ruhi, et al. «An overview of end-to-end language understanding and dialog management for personal digital assistants.» Spoken Language Technology Workshop (SLT), 2016 IEEE. IEEE, 2016.
- Ameixa, David, et al. «Luke, I am your father: dealing with out-of-domain requests by using movies subtitles.» International Conference on Intelligent Virtual Agents. Springer, Cham, 2014.
- Tarasov, D. S., and E. D. Izotova. «Common Sense Knowledge in Large Scale Neural Conversational Models.» International Conference on Neuroinformatics. Springer, Cham, 2017.
- Fuster,Joaqu?n M… «Network memory.» Trends in neurosciences 20.10 (1997): 451-459.
- Fuster, Joaqu?n M. «Cortex and memory: emergence of a new paradigm.» Cortex 21.11 (2009).
- Liao, S.-H. (2015). Awareness and Usage of Speech Technology. Masters thesis, Dept. Computer Science, University of Sheffield
Источник: habrahabr.ru