Когда лучше не использовать глубинное обучение
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-10-11 15:33
машинное обучение python, архитектура нейронных сетей, ошибки нейросетей

Я понимаю, что странно начинать блог с негатива, но за последние несколько дней поднялась волна дискуссий, которая хорошо соотносится с некоторыми темами, над которыми я думал в последнее время. Всё началось с поста Джеффа Лика в блоге Simply Stats с предостережением об использовании глубинного обучения на малом размере выборки. Он утверждает, что при малом размере выборки (что часто наблюдается в биологии), линейные модели с небольшим количеством параметров работают эффективнее, чем нейросети даже с минимумом слоёв и скрытых блоков.
Далее он показывает, что очень простой линейный предиктор с десятью самыми информативными признаками работает эффективнее простой нейросети в задаче классификации нулей и единиц в наборе данных MNIST, при использовании всего около 80 образцов. Эта статья сподвигла Эндрю Бима написать опровержение, в котором правильно обученная нейросеть сумела превзойти простую линейную модель, даже на очень малом количестве образцов.
Такие споры идут на фоне того, что всё больше и больше исследователей в области биомедицинской информатики применяют глубинное обучение на различных задачах. Оправдан ли ажиотаж, или нам достаточно линейных моделей? Как всегда, здесь нет однозначного ответа. В этой статье я хочу рассмотреть случаи применения машинного обучения, где использование глубоких нейросетей вообще не имеет смысла. А также поговорить о распространённых предрассудках, которые, на мой взгляд, мешают действительно эффективно применять глубинное обучение, особенно у новичков.
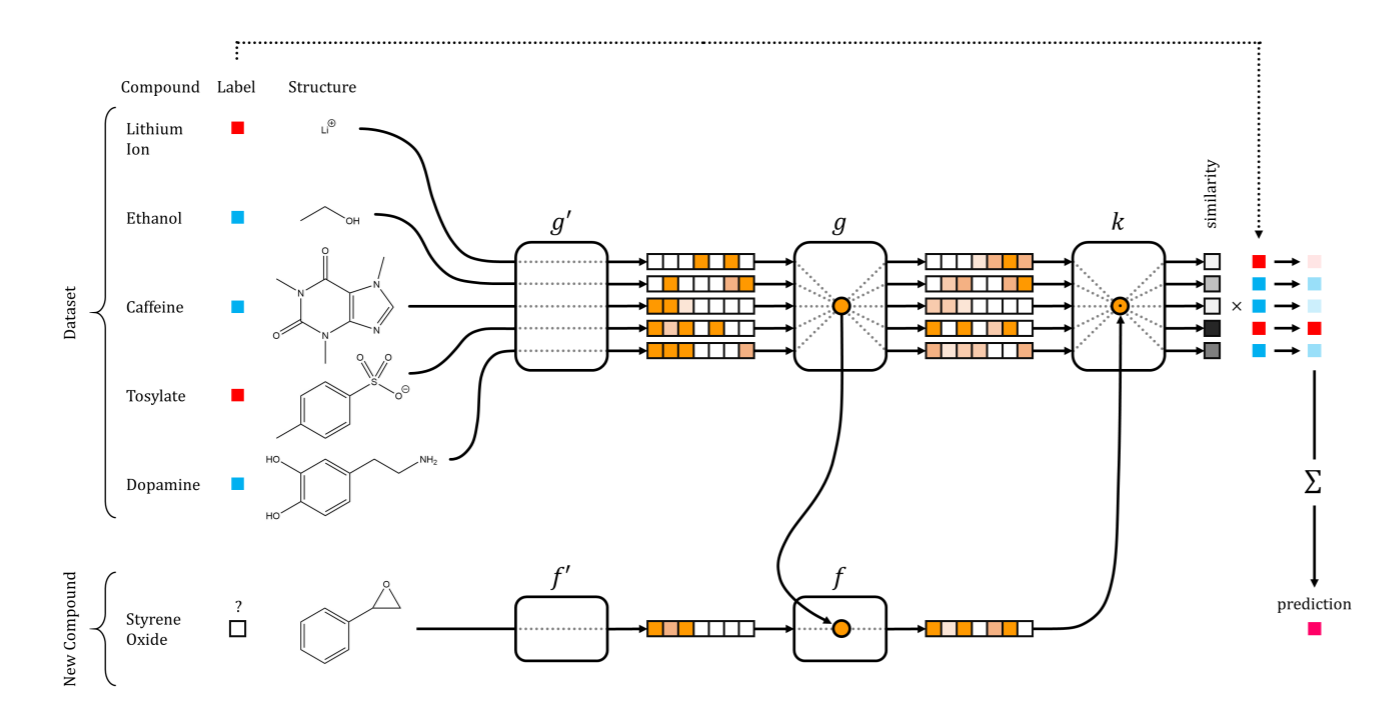 Сети обучения с первого раза в открытии новых лекарств. Иллюстрация из статьи Altae-Tran et al. ACS Cent. Sci. 2017
Сети обучения с первого раза в открытии новых лекарств. Иллюстрация из статьи Altae-Tran et al. ACS Cent. Sci. 2017
Стохастический градиентный спуск (SGD) ничем не отличается, а последние научные работы предполагают, что эта процедура на самом деле представляет собой цепь Маркова, которая при определённых допущениях демонстрирует стационарное распределение, а его можно рассматривать как разновидность вариационного приближения к апостериорной вероятности. Так что если вы остановите свой SGD и примете финальные параметры, то вы в реальности получаете образцы из этого приближённого распределения.
Мне эта идея показалась очень яркой. Она многое объясняет, потому что параметры оптимизатора (в этом случае, скорость обучения) теперь получают гораздо больше смысла. Такой пример: как вы можете изменить параметр скорости обучения в стохастическом градиентном спуске, так и цепь Маркова становится нестабильной, пока не найдёт широкий локальный минимум, охватывающий образцы в большой области; таким образом, вы увеличиваете дисперсию процедуры. С другой стороны, если уменьшить скорость обучения, цепь Маркова медленно приближается к более узкому локальному минимуму, пока не сойдётся в очень узкой области; таким образом, вы увеличиваете перекос к определённой области.
Другой параметр в SGD, размер пакетов (batch size), тоже контролирует, в каком типе области алгоритм сойдётся: в более широких областях для маленьких пакетов или в более чётких областях с пакетами б?льшего размера.

SGD предпочитает широкий или узкий локальный минимум, в зависимости от скорости обучения или размера пакетов
Такая сложность означает, что на первый план выходят оптимизаторы глубинных нейросетей: это ядро модели, настолько же важное, как архитектура слоёв. Во многих других моделях машинного обучения такого нет. Линейные модели (даже регуляризацией, такой как LASSO) и SVM — это задачи выпуклой оптимизации, у которых нет таких тонкостей и имеется только одно решение. Вот почему специалисты, которые пришли из других областей и/или используют инструменты вроде scikit-learn, не могут понять, почему невозможно найти очень простой API с методом

Edward объединяет вероятностное программрование с TensorFlow, допуская создание моделей, которые одновременно используют глубинное обучение и байесовские методы. Иллюстрация: Tran et al. ICLR 2017
Далее он показывает, что очень простой линейный предиктор с десятью самыми информативными признаками работает эффективнее простой нейросети в задаче классификации нулей и единиц в наборе данных MNIST, при использовании всего около 80 образцов. Эта статья сподвигла Эндрю Бима написать опровержение, в котором правильно обученная нейросеть сумела превзойти простую линейную модель, даже на очень малом количестве образцов.
Такие споры идут на фоне того, что всё больше и больше исследователей в области биомедицинской информатики применяют глубинное обучение на различных задачах. Оправдан ли ажиотаж, или нам достаточно линейных моделей? Как всегда, здесь нет однозначного ответа. В этой статье я хочу рассмотреть случаи применения машинного обучения, где использование глубоких нейросетей вообще не имеет смысла. А также поговорить о распространённых предрассудках, которые, на мой взгляд, мешают действительно эффективно применять глубинное обучение, особенно у новичков.
Разрушение предрассудков о глубинном обучении
Сначала поговорим о некоторых предрассудках. Мне кажется, они присутствуют у большинства специалистов, не слишком осведомлённых в теме глубинного обучения, а на самом деле являются полуправдой. Есть два очень распространённых и один немного более технический предрассудок — на них и остановимся подробнее. Это в каком-то роде продолжение великолепной главы «Заблуждения» в статье Эндрю Бима.Глубинное обучение действительно может работать на малых размерах выборки
Глубинное обучение прославилось эффективной обработкой большого количества входных данных (помните, что первый проект Google Brain предусматривал загрузку в нейросеть большого количества видеороликов YouTube), и с тех пор постоянно описывалось как сложные алгоритмы, работающие на большом объёме данных. К сожалению, эта пара big data и глубинного обучения как-то привела людей к противоположной мысли: миф, что глубинное обучение нельзя использовать на малых выборках. Если у вас всего несколько образцов, запуск нейросети высоким соотношением параметров на образец на первый взгляд может показаться прямой дорогой переобучению. Однако простой учёт объёма выборки и размерности для данной конкретной проблемы, при обучении с учителем или без учителя, — это нечто вроде моделирования данных в вакууме, без контекста. А ведь нужно учесть, что в таких случаях у вас есть релевантные источники данных или убедительные предварительные данные, которые может предоставить эксперт в данной области, или данные структурированы очень конкретным образом (например, в виде графа или изображения). Во всех этих случаях есть вероятность, что глубинное обучение принесёт пользу — например, вы можете закодировать полезные репрезентации более крупных родственных наборов данных и использовать их в своей задаче. Классический пример такой ситуации часто встречается в обработке естественного языка, где можно усвоить информацию о включении отдельных слов в большом словарном корпусе типа Википедии, а затем а затем использовать информацию о включениях слов на более маленьком, узком корпусе при обучении с учителем. В крайнем случае у вас может быть несколько нейросетей, которые совместно усваивают репрезентацию и эффективный способ её повторного использования на малых наборах образцов. Это называется обучением с первого раза (one-shot learning), и оно успешно применяется в разных областях с многомерными данными, в том числе в машинном зрении и открытии новых лекарств. Сети обучения с первого раза в открытии новых лекарств. Иллюстрация из статьи Altae-Tran et al. ACS Cent. Sci. 2017Глубинное обучение — не универсальное решение всех проблем
Второе заблуждение, которое приходится часто слышать, — это настоящий хайп. Многие начинающие практику специалисты рассчитывают, что глубинные сети дадут им сказочный скачок прирост производительности просто потому что так оно и происходит в других областях. Другие находятся под впечатлением потрясающих успехов глубинного обучения в моделировании и манипулировании изображениями, звука и в лингвистике — в трёх типах данных, наиболее близких человеку — и они с головой окунаются в эту область, пытаясь обучить самую модную последнюю архитектуру состязательных нейросетей. Такой ажиотаж проявляется по-разному. Глубинное обучение стало неоспоримой силой в машинном обучении и важным инструментом в арсенале любого разработчика моделей данных. Его популярность привела к созданию важных фреймворков, таких как TensorFlow и PyTorch, невероятно полезных даже за пределами глубинного обучения. История его превращения из андердога в суперзвезду вдохновила исследователей на пересмотр других методов, ранее считавшихся невразумительными, таких как эволюционные стратегии и обучение с подкреплением. Но это ни в коем случае не панацея. Помимо соображений об отсутствии халявы в принципе, могу сказать, что модели глубинного обучения могут иметь важные нюансы, требовать аккуратного обращения, а иногда очень затратного поиска гиперпараметров, настройки и тестирования (об этом подробнее см. далее в статье). Кроме того, есть много случаев, где глубинное обучение просто не имеет смысла с практической точки зрения, а более простые модели работают гораздо лучше.Глубинное обучение — это больше, чем .fit()
Есть ещё один аспект моделей глубинного обучения, который, по моим наблюдениям, неправильно воспринимается с точки зрения других областей машинного обучения. Большинство учебников и вводных материалов по глубинному обучению описывают эти модели как составленные из иерархически связанных слоёв узлов, где первый слой принимает входной сигнал, а последний слой выдаёт выходной сигнал, а вы можете обучить их, используя некую форму стохастического градиентного спуска. Иногда может вкратце упоминаться, как работает стохастический градиентный спуск и что такое обратное распространение ошибки. Но львиная часть объяснения посвящена богатому разнообразию типов нейросетей (свёрточные, рекуррентные и т.д.). Самим методам оптимизации уделяется мало внимания, и это очень плохо, потому что они представляют собой важную (если не самую важную) часть работы любой сети глубинного обучения и потому что знание этих конкретных методов (почитайте, к примеру, этот пост Ференца Хужара и его научную статью, которая там упоминается), и знание, как оптимизировать параметры этих методов и как разделить данные для их эффективного использования крайне важно для получения хорошей сходимости в разумное время. Почему именно стохастические градиенты настолько важны — пока неизвестно, но специалисты здесь и там высказывают разные предположения на этот счёт. Одно из моих любимых — интерпретация этих методов как часть расчёта байесовского вывода. По сути, каждый раз при осуществлении какой-нибудь численной оптимизации вы рассчитываете байсовский вывод с определёнными предположениями. В конце концов, есть целая область под названием вероятностная нумерика, которая буквально выросла из такой интерпретации.Стохастический градиентный спуск (SGD) ничем не отличается, а последние научные работы предполагают, что эта процедура на самом деле представляет собой цепь Маркова, которая при определённых допущениях демонстрирует стационарное распределение, а его можно рассматривать как разновидность вариационного приближения к апостериорной вероятности. Так что если вы остановите свой SGD и примете финальные параметры, то вы в реальности получаете образцы из этого приближённого распределения.
Мне эта идея показалась очень яркой. Она многое объясняет, потому что параметры оптимизатора (в этом случае, скорость обучения) теперь получают гораздо больше смысла. Такой пример: как вы можете изменить параметр скорости обучения в стохастическом градиентном спуске, так и цепь Маркова становится нестабильной, пока не найдёт широкий локальный минимум, охватывающий образцы в большой области; таким образом, вы увеличиваете дисперсию процедуры. С другой стороны, если уменьшить скорость обучения, цепь Маркова медленно приближается к более узкому локальному минимуму, пока не сойдётся в очень узкой области; таким образом, вы увеличиваете перекос к определённой области.
Другой параметр в SGD, размер пакетов (batch size), тоже контролирует, в каком типе области алгоритм сойдётся: в более широких областях для маленьких пакетов или в более чётких областях с пакетами б?льшего размера.
Такая сложность означает, что на первый план выходят оптимизаторы глубинных нейросетей: это ядро модели, настолько же важное, как архитектура слоёв. Во многих других моделях машинного обучения такого нет. Линейные модели (даже регуляризацией, такой как LASSO) и SVM — это задачи выпуклой оптимизации, у которых нет таких тонкостей и имеется только одно решение. Вот почему специалисты, которые пришли из других областей и/или используют инструменты вроде scikit-learn, не могут понять, почему невозможно найти очень простой API с методом
.fit() (хотя имеются некоторые инструменты вроде skflow, которые пытаются свести простые нейросети к сигнатуре .fit(), но мне такой подход кажется немного неправильным, потому что смысл глубинного обучения в его гибкости).Когда не следует использовать глубинное обучение
Итак, когда же глубинное обучение не является самым оптимальным способом решения задачи? С моей точки зрения, вот основные сценарии, где глубинное обучение будет скорее помехой.Низкобюджетные или малозначительные проблемы
Нейросети представляют собой очень гибкие модели, с множеством архитектур и типов узлов, оптимизаторами и стратегиями регуляризации. В зависимости от приложения, у вашей модели могут быть свёрточные слои (насколько широкие? с каким пулингом?) или рекуррентная структура (с вентилями или без?). Она может быть действительно глубокой (Hourglass, Siamese или одна из множества других архитектур) или всего с несколькими скрытыми слоями (сколько блоков использовать?). В ней могут быть блоки линейной ректификации или другие функции активации. Она может выключать часть нейронов во время обучения через дропаут (в каких слоях? сколько нейронов выключать?) и следует, пожалуй, упорядочить веса (l1, l2 или что-то более странное?). Это далеко не полный список, есть ещё много других видов узлов, связей и даже функций потерь — всё это можно опробовать. Понадобится очень много времени, чтобы испытать такое большое количество возможных гиперпараметров и архитектур даже при обучении одного экземпляра крупной нейросети. Google недавно похвасталась, что её конвейер AutoML способен автоматически подбирать самую оптимальную архитектуру, что олчень впечатляет, но при этом требует круглосуточной работы более 800 GPU в течение нескольких недель, а такое не каждому доступно. Суть в том, что обучение глубоких нейросетей дорого стоит, как при вычислении, так и при отладке. Такие расходы не имеют смысла для решения повседневных проблем прогнозирования, так что ROI настройки нейросети для таких проблем может оказаться слишком маленьким, даже при настройке маленьких нейросетей. Даже если у вас большой бюджет и важная задача, нет причин не испытать сначала альтернативные методв как исходный уровень. Вы можете быть приятно удивлены, что линейная SVM — это всё, что вам действительно нужно.Интерпретация и объяснение широкой аудитории параметров и признаков модели
Глубинные нейросети также печально известны как «чёрные ящики» с высокой эффективностью предсказаний, но низкой интерпретируемостью. Хотя в последнее время создано много инструментов вроде карт салиентности и различий в активации. Они хорошо работают в некоторых областях, но применимы не во всех приложениях. В основном, эти инструменты полезны, когда вы хотите проверить, что нейросеть не обманывает вас, запомнив набор данных или обрабатывая определённые фиктивные признаки. Но по-прежнему сложно интерпретировать вклад каждого признака в общее решение нейросети. В таких условиях ничто не может сравниться с линейными моделями, поскольку там усвоенные коэффициенты напрямую связаны с результатом. Это особенно важно, когда нужно объяснить такие интерпретации широкой аудитории, которая будет принимать на их основании важные решения. Например, медикам нужно интегрировать все виды различных данных для получения диагноза. Чем проще и яснее связь между переменной и результатом, тем лучше медик может учитывать эту переменную, исключив вероятность недооценки или переоценки её значения. Более того, есть случаи, когда интерпретируемость важнее, чем точность модели (обычно глубинное обучение не имеет себе равных по точности). Так, законодателей может заинтересовать, какой эффект оказывают некоторые демографические переменные, например, на смертность. И их может больше интересовать прямая аппроксимация, а не точность предсказания. В обоих случаях глубинное обучение уступает более простым, более прозрачным сетям.Определение причинно-следственных связей
Крайний случай интерпретируемости модели — когда мы пытаемся определить механистическую модель, то есть модель, которая действительно фиксирует феномен, стоящий за данными. Хорошим примером будет попытка предсказать, как две молекулы (например, лекарства, белки, нуклеиновые кислоты и проч.) среагируют в определённой клеточной среде. Или выдвижение гипотезы, как определённая стратегия маркетинга отразится на продажах. По мнению экспертов в данной области, в реальности тут ничто не может конкурировать со старыми добрыми байесовскими методами. Это лучший (хотя и не идеальный) способ представить и сделать выводы о причинно-следственных связях. Компания Vicarious недавно опубликовала хорошую научную работу. Она показывает, почему в задачах с видеоиграми такой более принципиальный подход выдаёт лучшие обобщения, чем глубинное обучение.Обучение на «неструктурированных» признаках
Возможно, это спорный пункт. Я выяснил, что есть одна область, в которой глубинное обучение великолепно себя проявляет. Это поиск полезных представлений данных для конкретной задачи. Очень хорошая иллюстрация — вышеупомянутые включения слов. У естественного языка богатая и сложная структура, её можно аппроксимировать с помощью нейросетей, которые учитывают контекст: каждое слово представляется в виде вектора, кодирующего контекст, в котором слово употребляется чаще всего. Используя информацию о включениях слов, полученную в результате обучения на большом корпусе слов, обработка естественного языка иногда может показать значительно б?льшую эффективность в конкретной задаче на другом корпусе слов. Однако эта модель может оказаться полностью бесполезной, если корпус совершенно не структурирован. Скажем, вы пытаетесь классифицировать объекты, изучая неструктурированные списки ключевых слов. Поскольку ключевые слова не используются ни в какой определённой структуре (вроде предложений), то маловероятно, что включения слов тут сильно помогут. В данном случае данные представляют собой модель типа «мешок слов». Такого представления, вероятно, будет вполне достаточно для выполнения поставленной задачи. Впрочем, здесь можно возразить, что включения слов вычисляются относительно просто, если использовать предобученные модели, и они могут лучше фиксировать сходство ключевых слов. Однако я всё равно предпочёл бы начать с представления в виде мешка слов и посмотреть, может ли она делать хорошие предсказания. В конце концов, каждое измерение мешка слов проще интерпретировать, чем соответствующий слой включения слова.Будущее за глубиной
Область глубинного обучения находится на подъёме, хорошо финансируется и ошеломительно быстро развивается. К тому времени, пока вы прочитаете научную статью, опубликованную на конференции, вероятно, выйдет две или три итерации улучшенных моделей на базе этой статьи, которую уже можно считать устаревшей. С этим связано важное предостережение ко всем аргументам, которые я высказал выше: на самом деле в ближайшем будущем глубинное обучение может оказаться сверхполезным для всех упомянутых сценариев. Инструменты для интерпретации моделей глубинного обучения для изображений и отдельных предложений становятся всё лучше. Последний софт вроде Edward объединяет байесовское моделирование и фреймворки глубоких нейросетей, позволяя количественно оценивать неопределённость параметров нейросетей и осуществлять простой байесовский вывод с помощью вероятностного программирования и автоматизированноого вариационного вывода. В более дальней перспективе можно ожидать сокращения словаря для моделирования: он будет улавливать салиентные свойства, которые могут быть у нейросети, и таким образом сокращать пространство тех параметров, которые следует попробовать. Так что не забываете посматривать в свой фид arXiv, эта моя статья через месяц-другой может устареть. Edward объединяет вероятностное программрование с TensorFlow, допуская создание моделей, которые одновременно используют глубинное обучение и байесовские методы. Иллюстрация: Tran et al. ICLR 2017
Источник: habrahabr.ru