Как дела у CatBoost? Интервью с разработчиками
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-10-09 15:00


Накануне конференции SmartData 2017 Анна Вероника Дорогуш дала обзорное интервью о текущем положении дел в
CatBoost — относительно молодой библиотеке для машинного обучения на градиентном бустинге. Анна — руководитель группы, которая занимается развитием алгоритмов машинного обучения в Яндексе.В интервью обсуждается новый метод машинного обучения, основанный на градиентном бустинге. Он разработан в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Если вы еще не знакомы с этой технологией, рекомендуется прочитать анонс на Хабре.
— У CatBoost существует несколько прямых конкурентов: XGBoost, LightGBM, H20, … Расскажите, по каким признакам вы поняли, что пора делать собственный продукт, а не использовать существующие?
Анна: Матрикснет был создан раньше, чем перечисленные выше алгоритмы, кроме того, он на большинстве задач давал результаты лучше, чем у конкурентов. А CatBoost — это его следующая версия.
— Сколько времени заняла разработка CatBoost? Это было плавное внедрение новых идей или вы однажды запланировали один большой проект «CatBoost» и потом целенаправленно его реализовали? Как это примерно выглядело?
Анна: Изначально это был экспериментальный проект под руководством Андрея Гулина, главной задачей проекта было придумать, как можно лучше всего работать с категориальными факторами. Ведь такие факторы появляются естественным образом, а работать с ними градиентный бустинг не умел. Сначала над проектом несколько лет работала команда Андрея Гулина, они проверили огромное количество экспериментов и множество гипотез. В итоге пришли к тому, что есть несколько лучше всего работающих идей. Андрей Гулин написал первую реализацию алгоритма CatBoost, сейчас развитием этого алгоритма занимается наша команда и ведется активная разработка.
Биография: Андрей Гулин Изучал прикладную математику и физику в МИФИ. С 2000 года профессионально играл в игры в компании Нивал и параллельно создавал новые. В 2005 году перешел в компанию Яндекс и с тех пор занимается улучшением качества поиска. Один из вдохновителей создания и запуска алгоритма машинного обучения MatrixNet.
Изучал прикладную математику и физику в МИФИ. С 2000 года профессионально играл в игры в компании Нивал и параллельно создавал новые. В 2005 году перешел в компанию Яндекс и с тех пор занимается улучшением качества поиска. Один из вдохновителей создания и запуска алгоритма машинного обучения MatrixNet.
Изучал прикладную математику и физику в МИФИ. С 2000 года профессионально играл в игры в компании Нивал и параллельно создавал новые. В 2005 году перешел в компанию Яндекс и с тех пор занимается улучшением качества поиска. Один из вдохновителей создания и запуска алгоритма машинного обучения MatrixNet. — По данным бенчмарков видно повышение производительности от 0.12% до 18%. Это действительно так важно? При какой архитектуре приложения библиотека градиентного бустинга становится бутылочным горлышком? В каких реально работающих сервисах Яндекса это повышение производительности играет наибольшую роль?
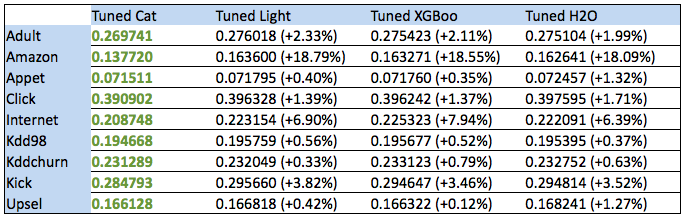 Анна: То, насколько большая разница будет значима, сильно зависит от данных. В каких-то случаях мы боремся за проценты, в каких-то — за доли процентов, это очень сильно зависит от задачи.
Анна: То, насколько большая разница будет значима, сильно зависит от данных. В каких-то случаях мы боремся за проценты, в каких-то — за доли процентов, это очень сильно зависит от задачи.Узкое место — по скорости приложения или по качеству?
Если по качеству, то тут узким местом бустинг будет в том случае, если узкое место — это точность и качество предсказания. Например, если у вас приложение предсказывает дождь, и там используется градиентный бустинг, то от точности модели будет напрямую зависеть точность предсказания приложения.
Если по скорости, то обучение модели вполне может быть узким местом. Но тут нужно просто понимать, сколько времени вы готовы потратить на обучение.
Еще узким местом по скорости бустинг, как и другие модели, может быть при применении. Если вам надо применять модель очень-очень быстро, то вам нужно быстрое применение. У CatBoost только что выложили быструю применялку, которая во многом это узкое место убирает.
— В бенчмарке «Amazon» результаты наиболее впечаляющие. Чем этот бенчмарк отличается от остальных и за счет чего получилось выиграть эти 18 процентов?
Анна: На этом датасете оказалось важным автоматически комбинировать разные категориальные факторы друг с другом, другие алгоритмы такого делать не умеют, а CatBoost умеет, поэтому и выиграл очень сильно.
— Что отличает CatBoost от других решений с точки зрения лежащей за ним теории?
Анна: В этом алгоритме есть более сложная обработка категориальных признаков, возможность использовать комбинации признаков, а также отличается схема вычисления значений в листьях.
— Какие интересные технологические фишки вы использовали в конкретной реализации на языке программирования? Может, какие-то особые структуры данных, алгоритмы или приемы кодирования, про поведение которых на специальных случаях можно рассказать подробней?
Анна: У нас в коде много всего интересного. Например, можно заглянуть в код бинаризации фичей. Там вы найдете очень нетривиальную динамику, написанную Алексеем Поярковым.
— Расскажите о какой-нибудь одной большой проблеме или задаче, возникшей по ходу реализации CatBoost. В чем было дело и как вы выкрутились?
Анна: Один из интересных вопросов — как считать счетчики для регрессионных режимов. Здесь таргет содержит в себе много информации, которую хочется эффективно использовать.
Решили так: много чего попробовали и выбрали лучше всего работающие способы. Это всегда так делается — приходится пробовать и экспериментировать и в итоге выбирать лучшее.
— С какими другими проектами из мира машинного обучения стоит попробовать интегрировать CatBoost? Например, можно ли объединить его с Tensorflow и как именно? Какие связки вы уже попробовали на практике?
Анна: У нас в туториалах есть пример совместного использования Tensorflow и CatBoost для решения контеста на каггле, в котором необходимо обрабатывать тексты. Вообще, это очень полезная практика — использовать нейросети для генерации факторов для градиентного бустинга, в Яндексе такой подход применяется во многих проектах, в том числе в поиске.
Кроме того, мы недавно реализовали интеграцию с TensorBoard, так что теперь графики ошибок во время обучения можно смотреть при помощи этой утилиты.
— Сейчас представлено три вида API: Python, R и командная строка. Планируется ли в ближайшем будущем расширить количество доступных языков программирования и API?
Анна: Мы не планируем сами делать поддержку новых языков, но будем очень рады, если новые обертки реализуют люди из опенсорс сообщества — проект на Гитхабе, так что кто угодно может этим заняться.
— Сейчас Python API выглядит как несколько классов:
Pool, CatBoost, CatBoostClassifier, CatBoostRegressor, плюс описана валидация и тренировочные параметры. Будет ли это API расширяться, и если да — какие возможности вы планируете добавить в ближайшем будущем? Есть ли какие-то фичи, которые клиенты очень хотят заполучить как можно скорее?Анна: Да, мы планируем добавлять новые фичи в обертку, но заранее их анонсировать не хочется.
Следите за новостями в нашем твиттере.
— Каким вы видите развитие CatBoost в общих чертах?
Анна: Мы активно развиваем алгоритм — добавляем в него новые фишки, новые режимы, активно работаем над ускорением применения, распределенным обучением и обучением на GPU, растим качество алгоритма. Так что у CatBoost еще будет много изменений.
— Вы будете спикером на конференции SmartData 2017. Можете сказать пару слов о вашем докладе, чего нам ждать?
Анна: На докладе будет рассказано об основных идеях алгоритма, а также о том, какие у алгоритма есть параметры и как правильно их использовать.
Источник: habrahabr.ru