Как создать расистский ИИ, даже не пытаясь. Часть 2
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-09-07 19:12
лингвистика, алгоритмы машинного обучения, разработка чат-ботов, примеры ии, ошибки нейронных сетей

В первой статье мы успели осознать, как легко и непринужденно ИИ впитывает человеческие предрассудки в логику своих моделей. Как я и обещала, выкладываю вторую часть перевода, в которой мы разберемся, как измерить и ослабить влияние расизма в ИИ с помощью простых методов.

Напомню: мы закончили на том, что наш классификатор считал идею пойти в итальянский ресторан в 5 раз лучше, чем в мексиканский.
Проводим количественный анализ проблемы
Хотелось бы понять, как избежать подобной ситуации в будущем. Давайте обработаем нашей системой дополнительные данные и статистически измерим величину предубеждения.
Составим четыре списка имен, которые ассоциируются с людьми (жителями США) различного этнического происхождения. Первые два списка — распространенные имена белых и чернокожих людей, взятых из статьи Принстонского университета. Добавляю испаноязычные имена и имена, распространенные в исламской культуре (преимущественно из арабского и языка урду), т. е. еще две группы имен, достаточно сильно связанных с их этнической группой.
Сейчас эти данные используют для проверки предубежденности в процессе формирования ConceptNet. Они содержатся в модуле conceptnet5.vectors.evaluation.bias. Мне хотелось бы добавить и другие этнические группы. Для этого может потребоваться учитывать не только имена, но и фамилии.
Вот списки
С помощью Pandas преобразуем эти данные (имена, наиболее характерное происхождение и получаемая для них оценка тональности) в таблицу.
def name_sentiment_table(): frames = [] for group, name_list in sorted(NAMES_BY_ETHNICITY.items()): lower_names = [name.lower() for name in name_list] sentiments = words_to_sentiment(lower_names) sentiments['group'] = group frames.append(sentiments) # Put together the data we got from each ethnic group into one big table return pd.concat(frames) name_sentiments = name_sentiment_table()
Теперь можно наглядно представить распределение оценок тональности, которую система выдает для каждой группы имен.
plot = seaborn.swarmplot(x='group', y='sentiment', data=name_sentiments) plot.set_ylim([-10, 10])
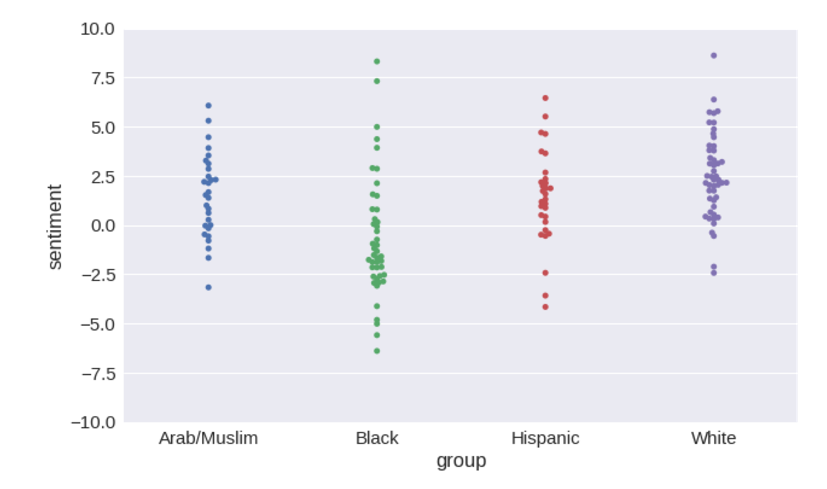 Распределения можно преобразовать в столбчатые диаграммы с доверительным интервалом в 95 % вокруг средних значений.
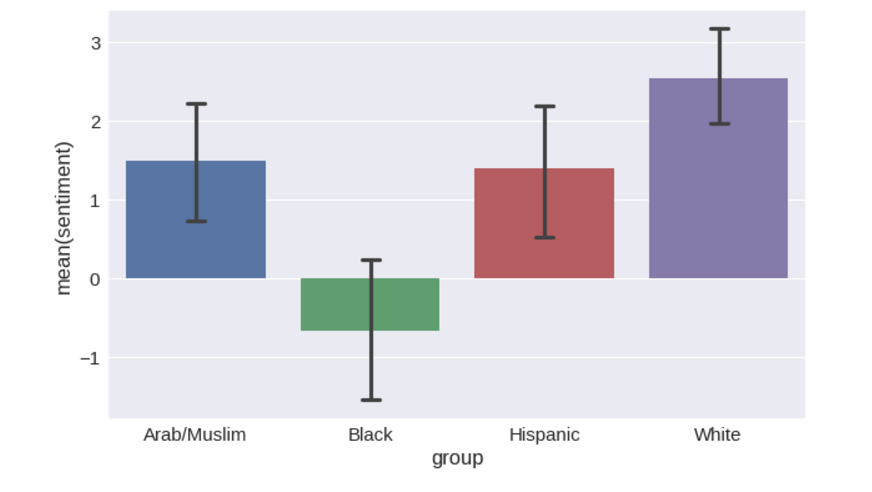
Распределения можно преобразовать в столбчатые диаграммы с доверительным интервалом в 95 % вокруг средних значений.
plot = seaborn.barplot(x='group', y='sentiment', data=name_sentiments, capsize=.1)
 И наконец, мы можем обработать эти данные мощными статистическими инструментами пакета
И наконец, мы можем обработать эти данные мощными статистическими инструментами пакета statsmodels, чтобы узнать в числе прочего, насколько выражен наблюдаемый эффект.
ols_model = statsmodels.formula.api.ols('sentiment ~ group', data=name_sentiments).fit() ols_model.fvalue # 13.041597745167659
F-мера (F-statistic) — это метрика, позволяющая одновременно оценить точность и полноту модели (подробнее тут). Ее можно использовать для оценки общей предубежденности в отношении различных этносов.
Наша задача — улучшить значение F-меры. Чем оно ниже, тем лучше.
Исправляем данные
Итак, мы научились измерять уровень предубежденности, который скрыт в наборе векторных значений слов. Попробуем улучшить эту величину. Для этого повторим ряд операций.
Если бы нам было важно написать хороший и удобный в поддержке код, то использовать глобальные переменные (например, model и embeddings) не стоило бы. Но необработанный исследовательский код имеет большое достоинство: он позволяет нам отследить результаты каждого этапа и сделать выводы. Постараемся не делать лишней работы, напишем функцию, которая будет повторять некоторые сделанные операции.
def retrain_model(new_embs): """ Repeat the steps above with a new set of word embeddings. """ global model, embeddings, name_sentiments embeddings = new_embs pos_vectors = embeddings.loc[pos_words].dropna() neg_vectors = embeddings.loc[neg_words].dropna() vectors = pd.concat([pos_vectors, neg_vectors]) targets = np.array([1 for entry in pos_vectors.index] + [-1 for entry in neg_vectors.index]) labels = list(pos_vectors.index) + list(neg_vectors.index) train_vectors, test_vectors, train_targets, test_targets, train_labels, test_labels = train_test_split(vectors, targets, labels, test_size=0.1, random_state=0) model = SGDClassifier(loss='log', random_state=0, n_iter=100) model.fit(train_vectors, train_targets) accuracy = accuracy_score(model.predict(test_vectors), test_targets) print("Accuracy of sentiment: {:.2%}".format(accuracy)) name_sentiments = name_sentiment_table() ols_model = statsmodels.formula.api.ols('sentiment ~ group', data=name_sentiments).fit() print("F-value of bias: {:.3f}".format(ols_model.fvalue)) print("Probability given null hypothesis: {:.3}".format(ols_model.f_pvalue)) # Show the results on a swarm plot, with a consistent Y-axis plot = seaborn.swarmplot(x='group', y='sentiment', data=name_sentiments) plot.set_ylim([-10, 10])
Проверка word2vec
Вы можете предположить, что проблема заключена в наборе данных GloVe. В основе этого архива — все сайты, которые обрабатывает робот Common Crawl (в том числе множество весьма сомнительных, а еще примерно 20 копий Urban Dictionary, словаря городского жаргона). Может быть, проблема в этом? Что, если взять старый добрый word2vec, результат обработки Google News?
Самый надежный источник файлов word2vec, который удалось найти, — вот этот файл в Google Drive. Скачаем и сохраним его как data/word2vec-googlenews-300.bin.gz.
# Use a ConceptNet function to load word2vec into a Pandas frame from its binary format from conceptnet5.vectors.formats import load_word2vec_bin w2v = load_word2vec_bin('data/word2vec-googlenews-300.bin.gz', nrows=2000000) # word2vec is case-sensitive, so case-fold its labels w2v.index = [label.casefold() for label in w2v.index] # Now we have duplicate labels, so drop the later (lower-frequency) occurrences of the same label w2v = w2v.reset_index().drop_duplicates(subset='index', keep='first').set_index('index') retrain_model(w2v) # Accuracy of sentiment: 94.30% # F-value of bias: 15.573 # Probability given null hypothesis: 7.43e-09
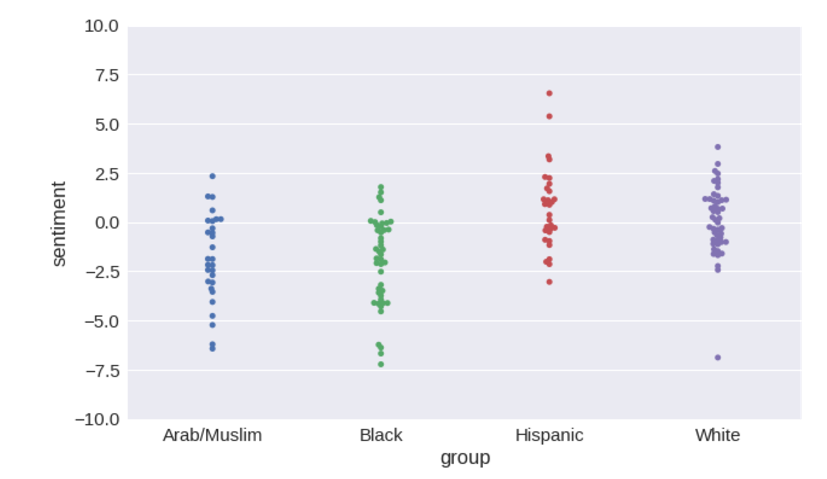 Так вот, результаты для
Так вот, результаты для word2vec еще хуже. F-мера для него превышает 15, различия в тональности для этнических групп выражены сильнее.
Если подумать, то набор данных, основанный на выпусках новостей, вряд ли может быть свободным от предубеждений.
Пробуем ConceptNet Numberbatch
Сейчас самое время представить вам мой собственный проект по созданию векторных значений слов.
ConceptNet — это граф знаний со встроенными функциями расчета векторных значений слов. В его процессе обучения используется специальный этап для выявления и устранения некоторых источников алгоритмического расизма и сексизма путем корректировки численных значений. Идея этого этапа основана на статье Debiasing Word Embeddings. Она обобщена таким образом, чтобы учитывать несколько форм предубеждений. Насколько мне известно, других семантических систем с аналогичной функцией пока не существует.
Время от времени мы экспортируем предварительно рассчитанные векторы ConceptNet и публикуем пакет под названием ConceptNet Numberbatch. Этап устранения человеческих предубеждений был добавлен в апреле 2017 г. Давайте загрузим векторные значения английских слов и переобучим на них нашу модель анализа тональности.
Скачиваем архив numberbatch-en-17.04b.txt.gz, сохраняем его в папке data/ и переобучаем модель.
retrain_model(load_embeddings('data/numberbatch-en-17.04b.txt')) # Accuracy of sentiment: 97.46% # F-value of bias: 3.805 # Probability given null hypothesis: 0.0118
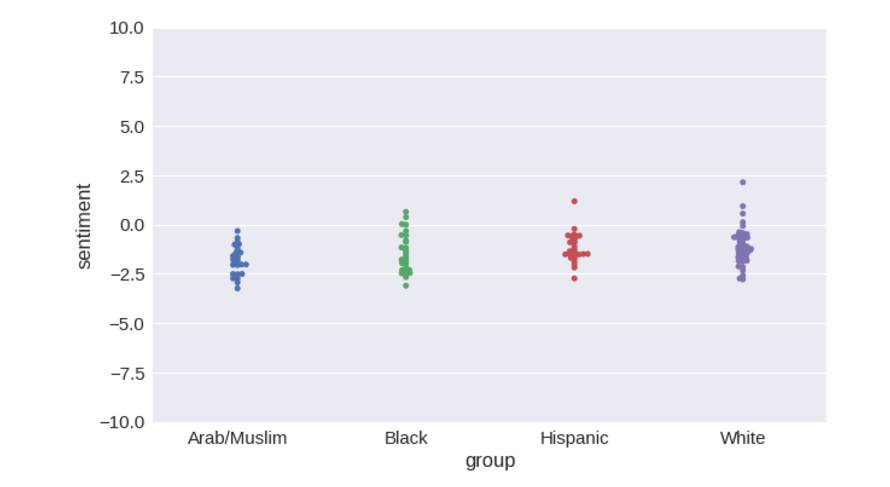
Удалось ли нам полностью решить проблему путем перехода на ConceptNet Numberbatch? Можно ли проблему алгоритмического расизма считать закрытой? Нет.
Удалось ли нам существенно ее ослабить? Да, определенно.
Диапазоны значений тональности перекрываются намного сильнее, чем для векторных значений слов, взятых напрямую из GloVe или word2vec. Значение метрики уменьшилось более чем в 3 раза относительно GloVe и примерно в 4 раза относительно word2vec. В целом, колебания тональности при изменении в тексте имен существенно уменьшились, чего мы и хотели, потому что тональность текста вообще не должна зависеть от имен.
Однако небольшая корреляция сохраняется. Наверное, я мог бы найти какие-нибудь данные или параметры обучения, при которых проблема выглядела бы полностью решенной. Но это было бы очень некрасиво с моей стороны, потому что проблема не решена до конца. В ConceptNet учитывается и устраняется лишь часть источников алгоритмического расизма. Но это хорошее начало.
Плюсы без минусов
Обратите внимание: когда мы перешли на ConceptNet Numberbatch, точность прогноза тональности возросла.
Можно было бы предположить, что для противодействия алгоритмическому расизму пришлось бы чем-то пожертвовать. Но мы ничем не жертвуем. Оказывается, можно получить данные, которые будут одновременно лучше и менее расистскими. Данные могут быть лучше именно потому, что в них меньше выражен расизм. Те проявления расизма, которые отпечатались в данных word2vec и GloVe, не имеют ничего общего с точностью.
Другие подходы
Конечно, есть и другие методы анализа тональности текста. Все операции, которые мы здесь использовали, очень распространены, но вы можете делать что-то иначе. Если вы применяете собственный подход, проверьте, не добавляете ли вы в свою модель какие-либо предрассудки и предубеждения.
Вместо того (или вместе с тем) чтобы изменять источник векторных значений слов, вы можете попробовать решить проблему непосредственно на выходе, например, изменить модель так, чтобы она не приписывала какой-либо тональности именам и названиям групп людей, или вообще отказаться от экстраполяции тональности слов и учитывать только те слова, которые есть в списке. Это, пожалуй, самая распространенная форма анализа тональности, вообще не использующая машинного обучения. Тогда модель будет проявлять не больше предубежденности, чем отражено в списке. Однако если не использовать машинного обучения, то модель станет очень жесткой, а изменить набор данных можно будет только редактированием вручную.
Еще можно воспользоваться гибридным подходом: рассчитать для множества слов прогнозируемые значения тональности, а затем привлечь эксперта, который их тщательно проверит и составит список слов-исключений, для которых нужно задать значение 0. Минус такого подхода — дополнительная работа, плюс — возможность увидеть оценки, которые система дает на основе ваших данных. Мне кажется, в машинном обучении этому следует уделять большее внимание.
Итог (от переводчика)
В заключении мне бы хотелось разом высказаться на тему комментариев к прошлому посту (тема, ожидаемо, задела чувства многих читателей). Часто встречалась мысль, что расизм в данных — не зло, а правильная и достоверная их часть, с которой не нужно бороться, ведь это отражение общественного мнения, на которое нельзя закрывать глаза.
Я в корне не согласна с этой мыслью по нескольким причинам. Как верно подметил vedenin1980, алгоритмы не анализируют объективную реальность. Они анализируют тексты, написанные людьми. Для начала задумаемся о природе этих текстов — кто, когда и зачем их написал. Надеюсь, здесь очевиден перекос в выборке. Большинство текстов пишется белыми людьми. Это значит, что мы толком не учитываем мнение остальных. Большинство новостных текстов пишется про ужасы этого мира — значит, мы толком не учитываем то хорошее, что в нем есть.
Наконец, главная проблема — текст привязан к текущему общественному мнению на момент его написания, а ИИ, созданный на его основе, будет использоваться в будущем. То есть, он будет думать устаревшими взглядами. Если вам кажется, что я драматизириую — напомню, что афроамериканцам разрешили сидеть в автобусах на одних лавочках с остальными лишь 1955 году.
В масштабах истории это было пару часов назад. Тогда были длительные бунты, люди протестовали. Сегодня это кажется немыслимым, кому вообще могло прийти в голову делить лавки на белые и цветные. Как вы думаете, сколько таких же несправедливых мыслей существует в сегодняшнем мире? Тех, которые мы воспринимаем как должное, а лет через 50 будем ужасаться от них. Вы уверены, что стоит пытаться нарочно обучать ИИ на этих данных, даже не пытаясь улучшить ситуацию?
Я — нет.
Источник: habrahabr.ru