«Используй Силу машинного обучения, Люк!» или автоматическая классификация светильников по КСС
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-09-18 10:40

«Сила машинного обучения среди нас, методы её окружают нас и связывают. Сила вокруг меня, везде, между мной, тобой, решающим деревом, лассо, гребнем и вектором опорным»Так бы, наверное, мне сказал Йода если бы он учил меня пути Data Science.
К сожалению, пока среди моих знакомых зеленокожие морщинистые личности не наблюдаются, поэтому просто продолжим вместе с вами наш совместный путь обучения науке о данных от уровня абсолютного новика до …
В прошлых двух статьях мы решали задачу классификации источников света по их спектру (на Python и C# соответственно). В этот раз попробуем решить задачу классификации светильников по их кривой силе света (по тому пятну которым они светят на пол).
Если вы уже постигли путь силы, то можно сразу скачать dataset на Github и поиграться с этой задачей самостоятельно. А вот всех, как и я новичков прошу подкат.
Благо задачка в этот раз совсем несложная и много времени не займет.

Очень хотелось начать оглавление разделов статьи с четвертого эпизода, но его название никак не вписывалось по смыслу.
Эпизод I: Скрытая угроза или что вам грозит если вы еще не прочитали весь предыдущий цикл статей.
Ну в принципе ничего не грозит, но если вы совсем новичок в науке о данных (Data Science), то я советую Вам все же посмотреть первые статьи в правильном хронологическом порядке, потому что это в некотором роде ценный опыт взгляда на Data Science глазами новичка, если бы мне пришлось сейчас описать свой путь, то я бы уже не смог вспомнить тех ощущений и часть проблем мне бы казалось совсем смешными. Поэтому, если вы только начали, посмотрите, как я мучался (и до сих пор мучаюсь) осваивая самые азы и вы поймете, что вы такой не один и все ваши проблемы в освоении машинного обучения и анализа данных вполне решаемы.Итак, вот перечень статей в порядке появления (от первых к последним)
- «Ловись Data большая и маленькая!» — (Краткий обзор курсов по Data Science от Cognitive Class)
- «Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch)
- «Айсберг вместо Оскара!» или как я пробовал освоить азы DataScience на kaggle
- ««Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science
- “Восстание МашинLearning” или совмещаем хобби по Data Science и анализу спектров лампочек
- « «Как по нотам!» или Машинное обучение (Data science) на C# с помощью Accord.NET Framework
Также по просьбам трудящихся в частности пользователя GadPetrovich начиная с этой статьи буду делать оглавление к материалу.
Содержание:
Эпизод I: Скрытая угроза или что вам грозит если вы еще не прочитали весь предыдущий цикл статей.
Эпизод II: Атака клонов или похоже, что эта задача не сильно отличается от прошлой
Эпизод III: Месть ситхов или немного о сложностях добычи данных
Эпизод IV: Новая надежда на то, что все классифицируется легко и просто
Эпизод V: Империя наносит ответный удар или сложно в подготовке данных легко в «бою»
Эпизод VI: Возвращение джедая или почувствую силу заранее написанных кем-то за тебя моделей!
Эпизод VII: Пробуждение силы – вместо заключения
Эпизод II: Атака клонов или похоже, что эта задача не сильно отличается от прошлой.
Хм, всего второй заголовок, а я уже думаю, что тяжело будет и дальше придерживаться стиля.Итак, напомню, что в прошлый раз мы с вами рассмотрели вопросы: создания своего собственного набора данных для задачи машинного обучения, обучения моделей классификаторов этих данных на примере логистической регрессии и случайного леса, а также визуализации и классификации с помощью PCA, T-SNE и DBSCAN.
В этот раз задача кардинальным образом не будет отличаться, правда признаков будет поменьше.
Забегая чуть-чуть вперед скажу, что для того чтобы задача не выглядела ну совсем уж клоном прошлой, в этот раз в примере мы встретим SVC классификатор, а также наглядно убедимся в том, что масштабирование исходных данных может быть очень полезным.
Эпизод III: Месть ситхов или немного о сложностях добычи данных.
Начнем с того что такое кривая силы света (КСС)?Ну это примерно вот это:
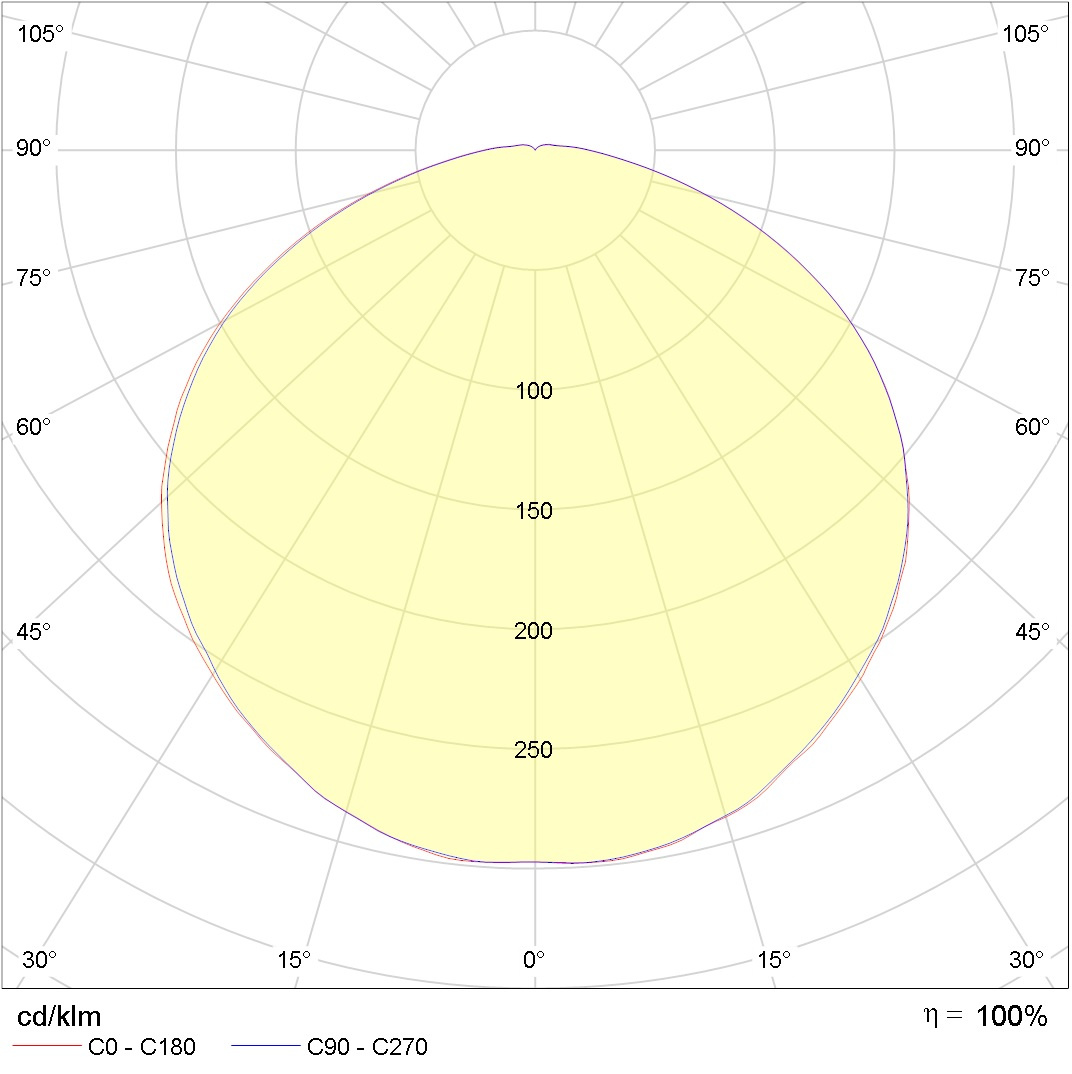
Что бы было чуть понятней представьте, что у вас над головой лампа и именно такой конус света падает вам под ноги если вы стоите под ней (как в пятне света от уличного фонаря).
На этой картинке показана сила света (значения на кругах) в разных полярных углах (представьте что это продольный разрез лампы накаливания), в разрыве двух азимутальных углов 0-180 и 90 – 270 (представьте, что это поперечный разрез лампы накаливания). Возможно я не очень, точно объяснил, За подробностями к Юлиану Борисовичу Айзенбергу в справочник по светотехнике страница 833 и далее
Но вернемся к исходным данным, не сочтите за рекламу, но все светильники, которые мы будем сегодня классифицировать будут от одного производителя, а именно фирмы Световые технологии. Я с ними никак не связан и мои карманы «звонкой монетой» от их упоминания не наполнятся
Тогда почему они? Все очень просто, ребята позаботились, о том, чтобы нам было удобно.
Необходимые картинки с КСС и .ies файлы для вытаскивания данных уже собраны ими в соответствующих архивах оставалось только скачать, согласитесь это намного удобней, чем рыскать по всей сети собирая данные по крупицам.
Возможно внимательный читатель, уже ждет с нетерпением, чтобы спросить причем тут все это и почему раздел называется месть ситхов? Где же жестокая месть?!
Ну видимо месть стихов заключалась в том, что на протяжении многих лет я занимался чем угодно, кроме математики, программирования, светотехники и машинного обучения и теперь за это расплачиваюсь нервными клетками.
Начнем немного из далека…
Вот так выглядит простенький .ies файл
IESNA:LM-63-1995
[TEST] SL20695
[MANUFAC] PHILIPS
[LUMCAT]
[LUMINAIRE] NA
[LAMP] 3 Step Switch A60 220-240V9.5W-60W 806lm 150D 3000K-6500K Non Dim
[BALLAST] NA
[OTHER] B-Angle = 0.00 B-Tilt = 0.00 2015-12-07
TILT=NONE
1 806.00 1 181 1 1 2 -0.060 -0.060 0.120
1.0 1.0 9.50
0.00 1.00 2.00 3.00 4.00 5.00 6.00 7.00 8.00 9.00
10.00 11.00 12.00 13.00 14.00 15.00 16.00 17.00 18.00 19.00
20.00 21.00 22.00 23.00 24.00 25.00 26.00 27.00 28.00 29.00
30.00 31.00 32.00 33.00 34.00 35.00 36.00 37.00 38.00 39.00
40.00 41.00 42.00 43.00 44.00 45.00 46.00 47.00 48.00 49.00
50.00 51.00 52.00 53.00 54.00 55.00 56.00 57.00 58.00 59.00
60.00 61.00 62.00 63.00 64.00 65.00 66.00 67.00 68.00 69.00
70.00 71.00 72.00 73.00 74.00 75.00 76.00 77.00 78.00 79.00
80.00 81.00 82.00 83.00 84.00 85.00 86.00 87.00 88.00 89.00
90.00 91.00 92.00 93.00 94.00 95.00 96.00 97.00 98.00 99.00
100.00 101.00 102.00 103.00 104.00 105.00 106.00 107.00 108.00 109.00
110.00 111.00 112.00 113.00 114.00 115.00 116.00 117.00 118.00 119.00
120.00 121.00 122.00 123.00 124.00 125.00 126.00 127.00 128.00 129.00
130.00 131.00 132.00 133.00 134.00 135.00 136.00 137.00 138.00 139.00
140.00 141.00 142.00 143.00 144.00 145.00 146.00 147.00 148.00 149.00
150.00 151.00 152.00 153.00 154.00 155.00 156.00 157.00 158.00 159.00
160.00 161.00 162.00 163.00 164.00 165.00 166.00 167.00 168.00 169.00
170.00 171.00 172.00 173.00 174.00 175.00 176.00 177.00 178.00 179.00
180.00
0.00
137.49 137.43 137.41 137.32 137.23 137.10 136.97
136.77 136.54 136.27 136.01 135.70 135.37 135.01
134.64 134.27 133.85 133.37 132.93 132.42 131.93
131.41 130.87 130.27 129.68 129.08 128.44 127.78
127.11 126.40 125.69 124.92 124.18 123.43 122.63
121.78 120.89 120.03 119.20 118.26 117.34 116.40
115.46 114.49 113.53 112.56 111.52 110.46 109.42
108.40 107.29 106.23 105.13 104.03 102.91 101.78
100.64 99.49 98.35 97.15 95.98 94.80 93.65
92.43 91.23 89.99 88.79 87.61 86.42 85.17
83.96 82.76 81.49 80.31 79.13 77.91 76.66
75.46 74.29 73.07 71.87 70.67 69.49 68.33
67.22 66.00 64.89 63.76 62.61 61.46 60.36
59.33 58.19 57.11 56.04 54.98 53.92 52.90
51.84 50.83 49.82 48.81 47.89 46.88 45.92
44.99 44.03 43.11 42.18 41.28 40.39 39.51
38.62 37.74 36.93 36.09 35.25 34.39 33.58
32.79 32.03 31.25 30.46 29.70 28.95 28.23
27.48 26.79 26.11 25.36 24.71 24.06 23.40
22.73 22.08 21.43 20.84 20.26 19.65 19.04
18.45 17.90 17.34 16.83 16.32 15.78 15.28
14.73 14.25 13.71 13.12 12.56 11.94 11.72
11.19 10.51 9.77 8.66 6.96 4.13 0.91
0.20 0.17 0.16 0.19 0.19 0.20 0.16
0.20 0.18 0.20 0.20 0.21 0.20 0.16
0.20 0.17 0.19 0.20 0.19 0.18Внутри зашиты данные о производителе и лаборатории измерителе, а также непосредственно данные о светильнике в том числе сила света в зависимости от полярных и азимутальных углов, данные о которой нам и нужны.
В сумме я отобрал для вас 193 файла, и вряд ли я бы стал даже пытаться обрабатывать их в ручную.
С одной стороны все просто есть ГОСТ в котором подробно описана структура .ies файла с другой стороны, автоматически распознать и вынуть нужные данные оказалось сложней чем я думал, это стоило мне пары тревожных и бессонных ночей.
Но для вас, как в лучших традициях синематографа все сложные и нудные вещи останутся «за кадром». Поэтому перейдем к непосредственному описанию данных.
Эпизод IV: Новая надежда… на то, что все классифицируется легко и просто.
Итак, вникнув в ключевые вопросы с помощью литературы на которую я выше сослался мы с вами придем ко мнению, что для того, чтобы классифицировать светильники в нашем учебно-демонстрационном примере, нам хватит вполне среза данных при каком-то одном азимутальном угле в данном случае равном нулю и в диапазоне полярных углов от 0 до 180, с шагом 10 (меньше шаг нет смысла брать на качество это сильно не повлияет).То есть в нашем случае, данные будут выглядеть не как на графике слева, а как на графике справа.
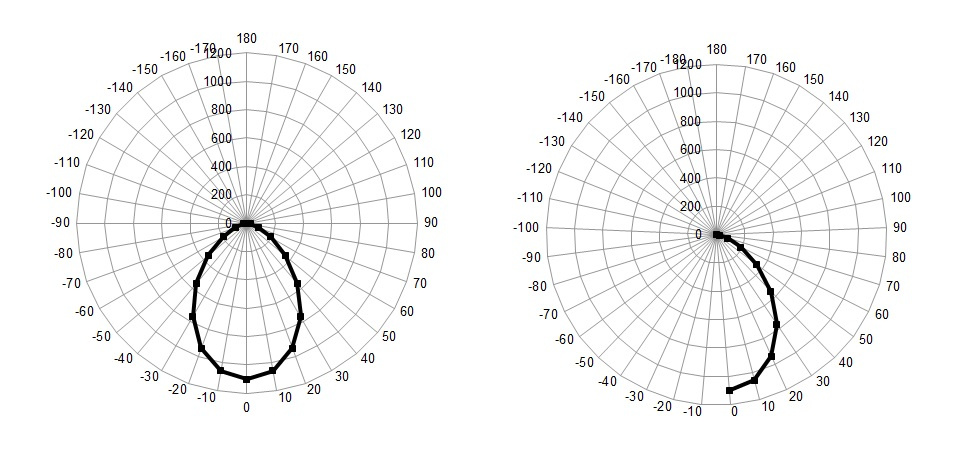
Кстати если кто не знал, то с помощью лепестковой диаграммы в MS Excel, можно удобно строить графики КСС.
Поскольку в архиве от Световых технологий светильникои с разными КСС распределены неравномерно, мы будем с вами анализировать 4 типа, которых больше всего в исходном наборе данных.
Итак, у нас есть следующие КСС:
Концентрированная (К), глубокая (Г), косинусная (Д) и полу-широкая (Л).
Их зоны направлений максимальной силы света находятся в следующиъх углах соответственно:
К = 0°-15°; Г = 0°-30°; Д = 0°-35°; Л = 35°-55°;
Метки им в наборе данных назначены соответствующие
К 1; Г = 2; Д = 3; Л = 4; (надо было с нуля начать, но теперь мне уже лень переделывать)
На самом деле, не будучи специалистом в области светотехники, трудно классифицировать светильники, например, светильник на рисунке выше я бы отнес к светильнику с глубокой КСС, но на 100% не уверен.
В принципе я старался избегать спорных моментов, смотреть в ГОСТ и на примеры, но вполне мог и ошибиться где-то, если найдете неточности в присвоении меток классов пишите, по возможности поправлю
Эпизод V: Империя наносит ответный удар или сложно в подготовке данных легко в «бою»
Ну что же похоже в эту игру могут играть двое если готовить данные было сложно, то анализировать как раз наоборот. Начнем потихоньку.Еще раз напомню, что файл со всем представленным ниже исходным кодом в формате .ipynb (Jupyter) можно скачать с GitHub
Итак, для начала импортируем библиотеки:
#import libraries import warnings warnings.filterwarnings('ignore') import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as mpatches from sklearn.model_selection import train_test_split from sklearn . svm import SVC from sklearn.metrics import f1_score from sklearn.ensemble import RandomForestClassifier from scipy.stats import uniform as sp_rand from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import MinMaxScaler from sklearn.manifold import TSNE from IPython.display import display from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split %matplotlib inline Затем обработаем данные <source lang="python"> #reading data train_df=pd.read_csv('lidc_data rain.csv',sep=' ',index_col=None) test_df=pd.read_csv('lidc_data est.csv',sep=' ',index_col=None) print('train shape {0}, test shape {1}]'. format(train_df.shape, test_df.shape)) display('train:',train_df.head(4),'test:',test_df.head(4)) #divide the data and labels X_train=np.array(train_df.iloc[:,1:-1]) X_test=np.array(test_df.iloc[:,1:-1]) y_train=np.array(train_df['label']) y_test=np.array(test_df['label']) Если вы читали предыдущие статьи или знакомы с машинным обучением на python, то весь представленный тут код не представит для вас сложности.
Но на всякий случай, в начале мы считали данные по учебной и тестовой выборке в таблицы, а потом вырезали из них массивы содержащие признаки (силы света в полярных углах) и метки классов, ну и конечно же для наглядности распечатали по первые 4 строки из таблицы, вот что получилось:
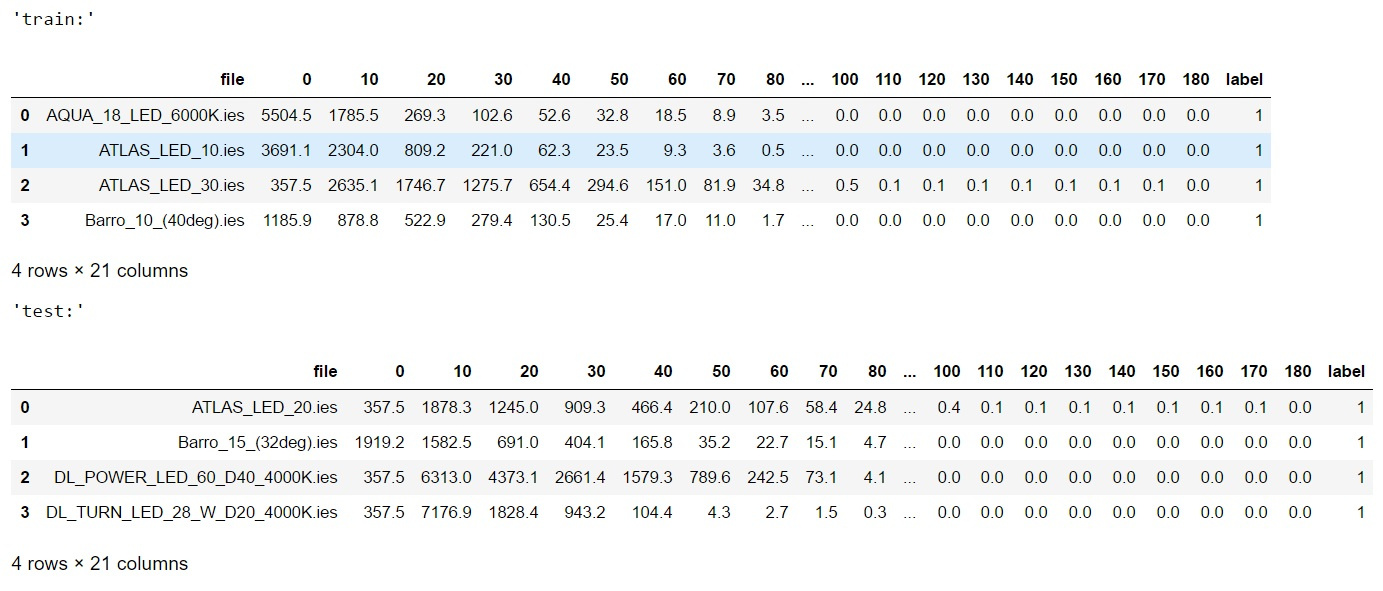 Можете мне поверить на слово, данные более мене сбалансированы за исключение класса №4( кривая Л) и в общем и целом для первых трех классов у нас соотношение — 40 образцов в учебной выборке и 12 в контрольной, для класса Л — 28 в учебной и 9 в контрольной в целом соотношение близкое к ? между учебной и контрольной выборкой сохраняется.
Можете мне поверить на слово, данные более мене сбалансированы за исключение класса №4( кривая Л) и в общем и целом для первых трех классов у нас соотношение — 40 образцов в учебной выборке и 12 в контрольной, для класса Л — 28 в учебной и 9 в контрольной в целом соотношение близкое к ? между учебной и контрольной выборкой сохраняется.Ну а если вы привыкли никому на слово не верить, то запустите код:
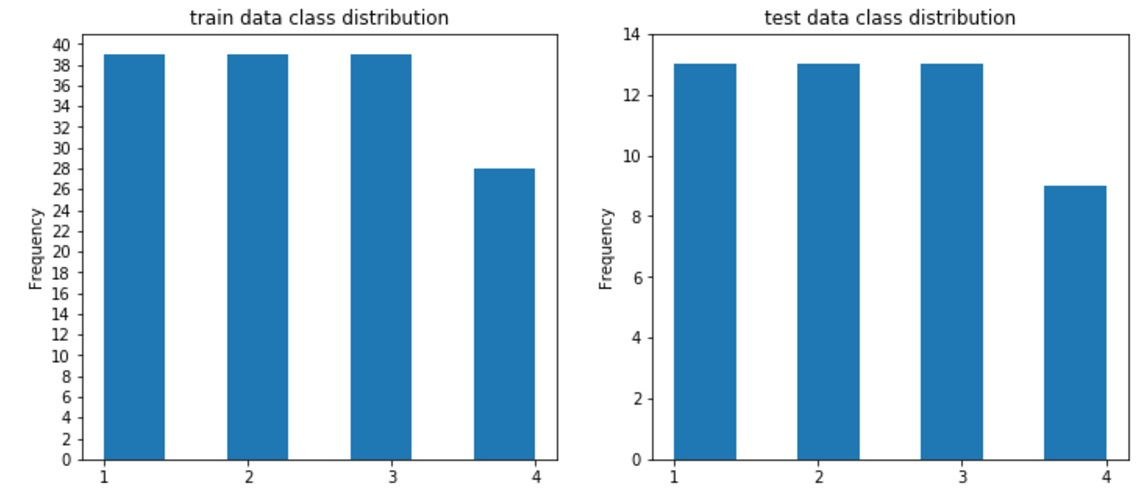
#draw classdistributions test_n_max=test_df.label.value_counts().max() train_n_max=train_df.label.value_counts().max() fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,5)) train_df.label.plot.hist(ax=axes[0],title='train data class distribution', bins=7,yticks=np.arange(0,train_n_max+2,2), xticks=np.unique(train_df.label.values)) test_df.label.plot.hist(ax=axes[1],ti И увидите следующее:
Давайте вернемся к нашим признакам, как вы понимаете с одной стороны все они отражают одну и туже величину, то есть грубо говоря мы не соотносим количество велосипедов и атмосферное давление, с другой стороны в отличие от прошлого раза , когда у нас все признаки имели примерно один уровень значений, в этот раз амплитуда значений может достигать десятков тысяч единиц.
Поэтому резонно отмасштабировать признаки. Однако, все модели масштабирования в scikit-learn похоже масштабируют по столбцам (или я не разобрался), а нам бессмысленно масштабировать по столбцам в данном случае, это не уравняет «богатые» и бедные» светильники, что приведёт так сказать к
Мы с вами будем вместо этого масштабировать данные по образцам (по строкам), чтобы сохранить характер распределения сил света по углам, но при этом загнать весь разброс в диапазон между 0 и 1.
По-хорошему в книгах, что я читал дают совет масштабировать обучающую выборку и контрольную одной моделью (обученной на обучающей выборке), но в нашем случае, так не получится из-за несовпадения числа признаков (в тестовой выборке меньше строк и транспонированная матрица будет иметь меньше столбцов), поэтому уравняем каждую выборку по своему.
Забегая в перед, применительно к данной задаче, в процессе классификации я ничего плохого в этом не обнаружил.
#scaled all data for final prediction scl=MinMaxScaler() X_train_scl=scl.fit_transform(X_train.T).T X_test_scl=scl.fit_transform(X_test.T).T #scaled part of data for test X_train_part, X_test_part, y_train_part, y_test_part = train_test_split(X_train, y_train, test_size=0.20, stratify=y_train, random_state=42) scl=MinMaxScaler() X_train_part_scl=scl.fit_transform(X_train_part.T).T X_test_part_scl=scl.fit_transform(X_test_part.T).T Даже если вы совсем новичок, то по ходу статьи вы заметите, что у всех моделей из набора scikit-learn схожий интерфейс, мы обучаем модель передавая данные в метод fit, если нам надо трансформировать данные, то вызываем метод transform (в нашем случае используем метод 2 в 1), а если надо будет позже предсказать данные вызываем метод predict и скармливаем ему наши новые (контрольные) образцы.
Ну и еще 1 маленький момент, давайте представим, что у нас нет меток для контрольной выборки, например, мы решаем задачу на kagle, как нам тогда оценить качество предсказания модели?
Думаю, для нашего случая, где не требуется решение бизнес задач одним из самых простых способов будет поделить обучающую выборку на еще одну обучающую (но поменьше) и тестовую (из состава обучающей), это нам пригодится чуть позже. А пока вернемся к масштабированию и посмотрим, как нам это помогло, верхняя картинка без масштабирования признаков, нижняя с масштабированием.
#not scaled x=np.arange(0,190,10) plt.figure(figsize=(17,10)) plt.plot(x,X_train[13]) plt.plot(x,X_train[109]) plt.plot(x,X_train[68]) plt.plot(x,X_train[127]) c1 = mpatches.Patch( color='blue', label='class 1') c2 = mpatches.Patch( color='green', label='class 2') c3 = mpatches.Patch(color='orange', label='class 3') c4 = mpatches.Patch( color='red',label='class 4') plt.legend(handles=[c1,c2,c3,c4]) plt.xlabel('полярный угол (polar angle)') plt.ylabel('Сила света излучения(luminous intensity)') plt.title(' Распределение силы света') “Забьем” это в разные ячейки (ну или сделаете subplot)
#scaled x=np.arange(0,190,10) plt.figure(figsize=(17,10)) plt.legend() plt.plot(x,X_train_scl[13],color='blue') plt.plot(x,X_train_scl[109],color='green') plt.plot(x,X_train_scl[68], color='orange') plt.plot(x,X_train_scl[127], color='red') c1 = mpatches.Patch( color='blue', label='class 1') c2 = mpatches.Patch( color='green', label='class 2') c3 = mpatches.Patch(color='orange', label='class 3') c4 = mpatches.Patch( color='red',label='class 4') plt.legend(handles=[c1,c2,c3,c4]) plt.xlabel('полярный угол (polar angle)') plt.ylabel('Сила света излучения(luminous intensity)') plt.title(' Распределение силы света (приведенное)') 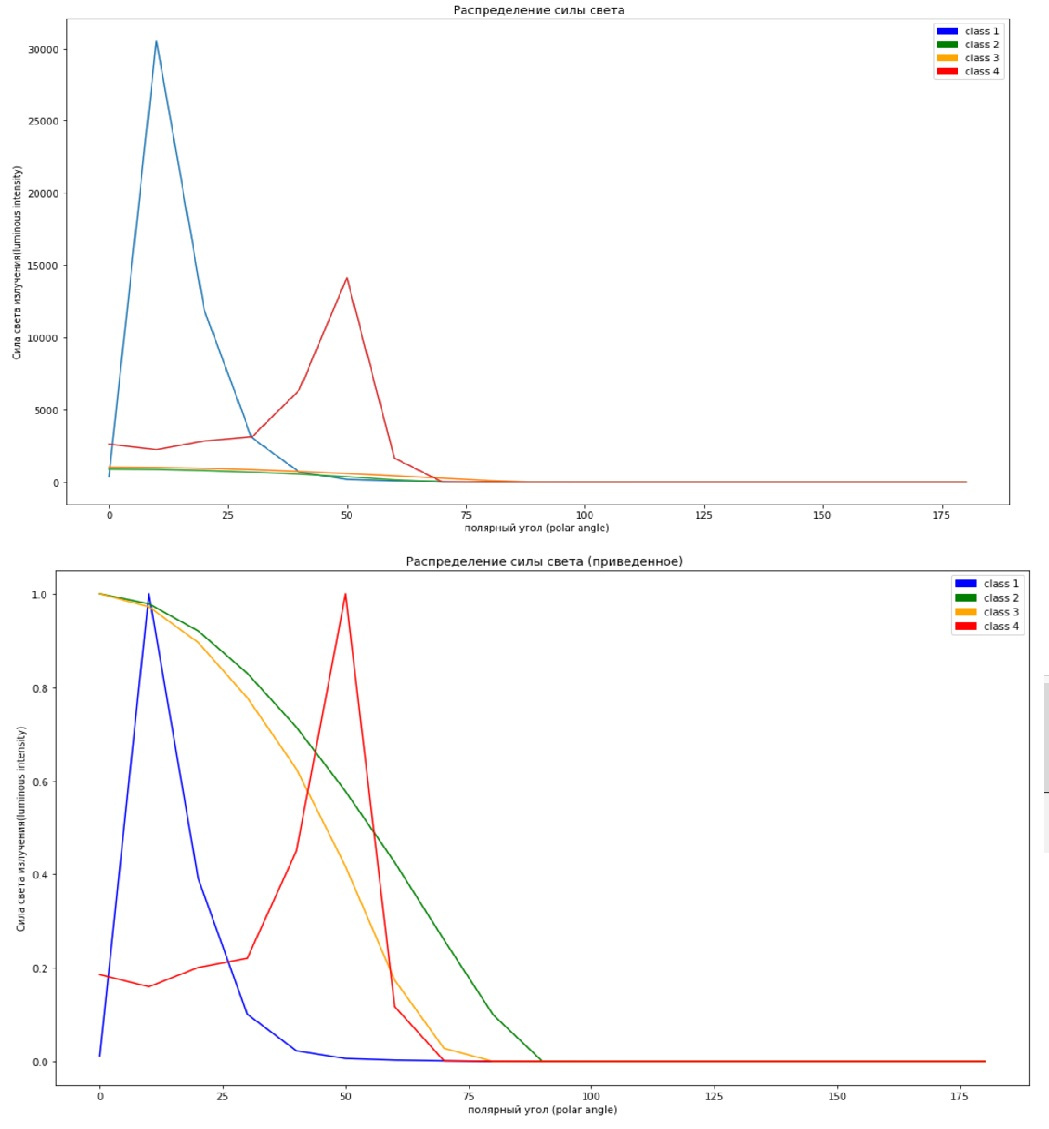
На графиках показано по одному образцу из каждого класса и как мы видим и нам и компьютеру будет проще что-то понять по масштабированному графику, ибо на верхнем некоторые графики просто сливаются с нулем из-за разницы масштабов.
Для того, чтобы окончательно убедится в нашей правоте, давайте попробуем снизить размерность признаков до двухмерной, чтобы отобразить наши данные на двухмерных графиках и посмотреть на сколько наши данные разделимы (мы воспользуемся для этого t-SNE)
Слева без масштабирования справа с масштабированием
#T-SNE colors = ["#190aff", "#0fff0f", "#ff641e" , "#ff3232"] tsne = TSNE(random_state=42) d_tsne = tsne.fit_transform(X_train) plt.figure(figsize=(10, 10)) plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10) plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10) for i in range(len(X_train)): # строим график, где цифры представлены символами вместо точек plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]), color = colors[y_train[i]-1], fontdict={'weight': 'bold', 'size': 10}) plt.xlabel("t-SNE feature 0") plt.ylabel("t-SNE feature 1") “Забьем” это в разные ячейки (ну или сделаете subplot)
#T-SNE for scaled data d_tsne = tsne.fit_transform(X_train_scl) plt.figure(figsize=(10, 10)) plt.xlim(d_tsne[:, 0].min(), d_tsne[:, 0].max() + 10) plt.ylim(d_tsne[:, 1].min(), d_tsne[:, 1].max() + 10) for i in range(len(X_train_scl)): # строим график, где цифры представлены символами вместо точек plt.text(d_tsne[i, 0], d_tsne[i, 1], str(y_train[i]), color = colors[y_train[i]-1], fontdict={'weight': 'bold', 'size': 10}) plt.xlabel("t-SNE feature 0") plt.ylabel("t-SNE feature 1") Вычитаем единицу, потому что я начал вести отсчет меток не с нуля.
 По рисункам видно, что на масштабированных данных, классы 1, 3, 4 более менее хорошо различимы, а класс 2 размазан между классами 1 и 3 (если вы скачаете и посмотрите КСС светильников, то вы поймете что так и должно быть)
По рисункам видно, что на масштабированных данных, классы 1, 3, 4 более менее хорошо различимы, а класс 2 размазан между классами 1 и 3 (если вы скачаете и посмотрите КСС светильников, то вы поймете что так и должно быть)Эпизод VI: Возвращение джедая или почувствую силу заранее написанных кем-то за тебя моделей!
Ну что же пора уже приступить к непосредственной классификацииДля начала обучим SVC на наших «урезанных данных»
#predict part of full data (test labels the part of X_train) #not scaled svm = SVC(kernel= 'rbf', random_state=42 , gamma=2, C=1.1) svm.fit (X_train_part, y_train_part) pred=svm.predict(X_test_part) print("
not scaled:
results (pred, real):
",list(zip(pred,y_test_part))) print('not scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test_part,pred), f1_score(y_test_part,pred, average='macro'))) #scaled svm = SVC(kernel= 'rbf', random_state=42 , gamma=2, C=1.1) svm.fit (X_train_part_scl, y_train_part) pred=svm.predict(X_test_part_scl) print("
scaled:
results (pred, real):
",list(zip(pred,y_test_part))) print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test_part,pred), f1_score(y_test_part,pred, average='macro'))) Получим следующий вывод
Не масштабированное
not scaled:
results (pred, real):
[(2, 3), (2, 3), (2, 2), (3, 3), (2, 1), (2, 3), (2, 3), (2, 2), (2, 1), (2, 2), (1, 1), (3, 3), (2, 2), (2, 1), (2, 4), (3, 3), (2, 2), (2, 4), (2, 1), (2, 2), (4, 4), (2, 2), (4, 4), (2, 4), (2, 3), (2, 1), (2, 1), (2, 1), (2, 2)]
not scaled: accuracy = 0.4827586206896552, f1-score= 0.46380859284085096Масштабированное
scaled:
results (pred, real):
[(3, 3), (3, 3), (2, 2), (3, 3), (1, 1), (3, 3), (3, 3), (2, 2), (1, 1), (2, 2), (1, 1), (3, 3), (2, 2), (1, 1), (4, 4), (3, 3), (2, 2), (4, 4), (1, 1), (2, 2), (4, 4), (2, 2), (4, 4), (4, 4), (3, 3), (1, 1), (1, 1), (1, 1), (2, 2)]
scaled: accuracy = 1.0, f1-score= 1.0Как видите разница более чем существенна, если в первом случае нам удалось достичь
результатов только немногим лучше чем случайное предсказание, то во втором случае мы получили 100% попадание.
Обучим нашу модель на полном наборе данных и убедимся, что и там будет 100% результат
#final predict full data svm.fit (X_train_scl, y_train) pred=svm.predict(X_test_scl) print("
results (pred, real):
",list(zip(pred,y_test))) print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test,pred), f1_score(y_test,pred, average='macro'))) Посмотрим на вывод
results (pred, real):
[(1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4)]
scaled: accuracy = 1.0, f1-score= 1.0Идеально! Надо отметить, что наряду с метрикой accuracy я решил использовать f1-score, которая нам бы пригодилась если бы наши классы имели существенно больший дисбаланс, а вот в нашем случае разницы между метриками почти никакой (но зато мы в этом убедились наглядно)
Ну и последнее, что мы с вами проверим это уже знакомый нам классификатор RandomForest
В книгах и в других материалах, я читал, что для RandomForest не критично масштабирование признаков, посмотрим так ли это.
rfc=RandomForestClassifier(random_state=42,n_jobs=-1, n_estimators=100) rfc=rfc.fit(X_train, y_train) rpred=rfc.predict(X_test) print("
not scaled:
results (pred, real):
",list(zip(rpred,y_test))) print('not scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test,rpred), f1_score(y_test,rpred, average='macro'))) rfc=rfc.fit(X_train_scl, y_train) rpred=rfc.predict(X_test_scl) print("
scaled:
results (pred, real):
",list(zip(rpred,y_test))) print('scaled: accuracy = {}, f1-score= {}'.format( accuracy_score(y_test,rpred), f1_score(y_test,rpred, average='macro'))) Получим следующий вывод:
not scaled:
results (pred, real):
[(1, 1), (1, 1), (2, 1), (1, 1), (1, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (1, 2), (2, 2), (2, 2), (2, 2), (2, 2), (3, 2), (2, 2), (3, 2), (2, 2), (4, 2), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (4, 3), (3, 3), (3, 3), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4)]
not scaled: accuracy = 0.8541666666666666, f1-score= 0.8547222222222222
scaled:
results (pred, real):
[(1, 1), (1, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (3, 3), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4), (4, 4)]
scaled: accuracy = 0.9791666666666666, f1-score= 0.9807407407407408Итак, можем сделать 2 заключения:
1. Иногда полезно масштабировать признаки даже для решающих деревьев.
2. SVC показал лучшую точность.
Надо отметить, что в этот раз я параметры подбирал вручную и если для scv я со второй по пытки подобрал нужный вариант, то для Random Forest не подобрал и с 10-го раза, плюнул и оставил по умолчанию (за исключением числа деревьев). Возможно есть параметры, которые доведут точность до 100%, попробуйте подобрать и обязательно расскажите в комментариях.
Ну вот вроде и все, но думаю, что фанаты Звездных войн, мне не простят, что я не упомянул седьмой фильм саги, поэтому…
Эпизод VII: Пробуждение силы – вместо заключения.
Машинное обучение оказалось, чертовски увлекательной штукой, я по-прежнему советую каждому попробовать придумать и решить задачу близкую именно вам.Ну а если сразу что-то не получится, то не вешайте нос как на картинке снизу.
Да-да! Чтобы вы не подумали это именно «не вешай нос» и никаких других скрытых помыслов ;)
И да прибудет с Вами сила!
Источник: habrahabr.ru