История развития машинного обучения в ЛК
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-08-17 18:34
кибер безопасность, машинное обучение новости, большие данные big data

Автор статьи — Алексей Маланов, эксперт отдела развития антивирусных технологий «Лаборатории Касперского»
Я пришел в «Лабораторию Касперского» студентом четвертого курса в 2004 году. Тогда мы работали по сменам, ночами, чтобы обеспечить максимальную скорость реакции на новые угрозы в индустрии. Многие конкурирующие компании в то время выпускали обновления антивирусных баз раз в сутки, им круглосуточная работа была не так важна. Мы же гордились тем, что смогли перейти на ежечасные обновления.
К слову, сам Евгений Валентинович Касперский сидел в той же комнате офиса, что и другие вирусные аналитики. Он «долбил» вирусы как и все, просто быстрее. И еще жаловался, что пиар-команда постоянно выдергивает его в командировки и не дает поработать в свое удовольствие. В общем, можно смело утверждать, что в 2004 году машинное обучение при анализе и детектировании вредоносного кода в «Лаборатории Касперского» не использовалось.
Скорость моего анализа вредоносов была в то время на порядок ниже темпа работы других аналитиков, ведь тут огромную роль играет опыт, и только со временем ты начинаешь «узнавать» семейства зловредов, просто заглянув внутрь.

Характерный вид содержимого Backdoor.Win32.Bifrose, популярного бэкдора того времени
Напомню, что в тот момент я учился в институте и занимался цветовой сегментацией изображений. Я обратил внимание, что для поиска похожих изображений исследователи придумали много всяких методов и постоянно работали над совершенствованием подходов, а вот для поиска похожих файлов и даже определения степени схожести двух вариантов — ничего.
Поиск похожих файлов
Я решил попробовать покопать в этом направлении и в рамках курсовой работы поставил себе такую задачу: программа анализирует всю коллекцию вредоносов, потом ей на вход подается новый исследуемый файл, и она сообщает, на кого он похож больше всего.
Для этого исполняемые файлы я представил в виде картинок (чем ярче точка, тем больше значение байта в файле).

spoolsv.exe, версия 5.1.2600.2180, eng и Ipconfig.exe, версия 5.1.2600.2180, rus
Глядя на такие картинки, даже человек, далекий от вирусного анализа, способен различать и узнавать представителей различных вирусных семейств. Выходит, это верный путь. Осталось только формализовать его и запрограммировать.
Сначала я пытался сделать все «по науке», используя дискретное вейвлет-преобразование. Ведь при таком поиске кажется логичным сперва учитывать самое главное и потом постепенно добавлять больше деталей, сужая область запроса и обнаруживая самый похожий вариант.

An example of the 2D discrete wavelet transform that is used in JPEG2000
Но после ряда экспериментов оказалось, что лучший подход — самый простой, а именно использование кусочно-постоянной интерполяции. Иными словами, нужно просто разбить файл на кусочки и посчитать среднее по всем байтам в кусочке.

Процесс кусочно-постоянной интерполяции уменьшает количество деталей и позволяет легче увидеть похожие файлы
А название утилиты так и осталось от сложного метода — DWT (Discrete Wavelet Transform). Интересно, что параллельно другой наш сотрудник сделал по сути то же самое. Но в итоге, когда я продемонстрировал Евгению Валентиновичу работающую программу, он похвалил и сказал: «Всем пользоваться».
Фактически этот метод можно считать первым шагом «Лаборатории» к использованию машинного обучения, пусть сам подход и был довольно простым по современным меркам. Свое первенство «Лаборатория Касперского» застолбила с помощью патента.
Поиск похожих файлов 2.0
Впрочем, одно дело — просто подсказать вирусному аналитику, на какой известный зловред похож исследуемый файл, а другое — принять решение, что исследуемый файл надо задетектировать. Перед этим необходимо еще убедиться в том, что два конкретных файла действительно похожи. Иными словами, для автодетектирования нужен сначала поиск, а потом сравнение.
Задача сравнения файлов решалась с помощью сравнения функциональных строк.
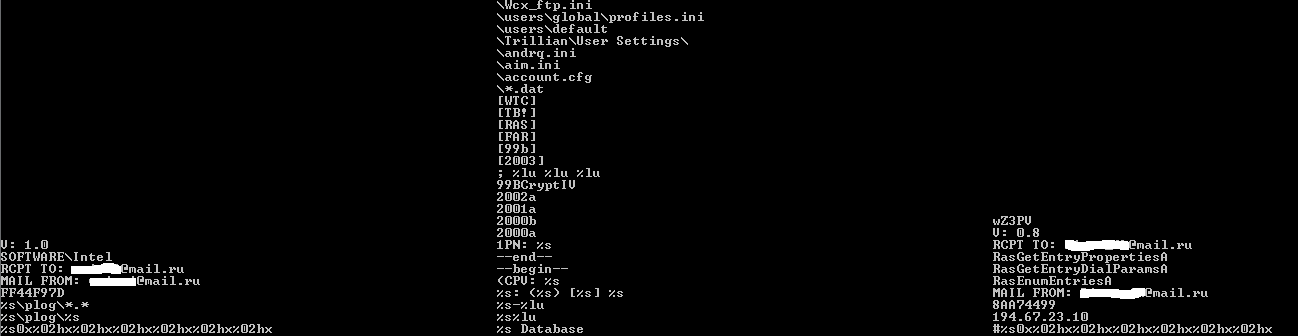
Строковое сравнение двух экземпляров Trojan-PSW.Win32.LdPinch. Посередине строки, которые есть в обоих экземплярах, слева — строки, которые есть только в первом, справа — только во втором
Если совпадающих строк (а следовательно, и функционала) больше, чем различающихся, то два файла считаются похожими, и, значит, можно добавлять детектирование. Однако на этом этапе меня беспокоило, что похожий файл мы ищем по его бинарному представлению, а сверяем с другими файлами уже по строкам. Это все равно что сначала преступника по фотографии опознавать, а только потом по отпечаткам пальцев проверять. Ведь в нашей задаче мы можем сразу искать по отпечаткам. Это позволит не передавать в «следственный отдел» тех «подозреваемых», на которых «свидетели» указали по ошибке.
Впрочем, не все так просто. Тогда предстояло решить еще и техническую задачу. Ведь файлов в нашей вирусной коллекции на тот момент было больше миллиона. Это сейчас миллион вредоносных файлов наши системы сбора загребают за три дня (а одних чистых экземпляров вообще только каждый день по миллиону прибывает). Тогда же, в 2006 году, когда деревья были маленькими, а трава — высокой, — уже тогда хотелось, чтобы прототип решения трудился на рабочей станции сотрудника и искал похожие файлы за секунды. Ведь промышленному решению надо будет обрабатывать весь входящий поток «Лаборатории».
Но не будем вдаваться в технические детали — скажем только, что задача была решена. Это позволило в 2,5 раза увеличить объем файлов, обрабатываемых и детектируемых автоматически. Помню, я тогда, засыпая, сильно переживал: «Как же так, вот мы сейчас нанимаем профессионалов для анализа вредоносов, а ведь когда мы автоматизируем процесс оперативной борьбы, эти спецы останутся без работы, так, что ли? Надо поскорее закончить реализацию, пока мы не наняли слишком много сотрудников!»
Но действительность все расставила по своим местам: с приходом автоматизации наши вирусные аналитики и эксперты смогли гораздо больше времени посвящать стратегической борьбе с вредоносами и разработке передовых технологий.
Ну и как водится, свое первенство «Лаборатория Касперского» застолбила тогда с помощью патента.
Системный подход
Довольно быстро, году в 2007-м, стало понятно, что нужно не просто автоматизировать детектирование и получать тем самым лучшую скорость реакции в индустрии, нужно перенести наработки на сторону продукта, чтобы решение принималось у клиента.
Внутри антивирусной лаборатории была создана Detection Methods Analysis Group. Интересно, что в настоящий момент только ее руководитель в прошлом вирусный аналитик, остальные сотрудники — это чистые Data Scientist’ы. Они сразу поставили задачу формально, выработали критерии похожести, ввели функцию потерь и начали применять математические методы. В общем, реализовали академический подход. Довольно быстро непосвященным стало ничего не понятно в их разговорах, я даже начал сомневаться, что из такого системного подхода что-нибудь выйдет, уж очень фундаментально они подошли. Я просто сам предпочитаю иной путь — «забабахать прототип на коленке — и готово». Но, несмотря на мой осторожный скепсис, с поставленной задачей команда отлично справилась.
Первый подход наших экспертов основывался на решающих деревьях.
 Принцип работы сводится к тому, что математическая модель (а именно ансамбль решающих деревьев) при анализе файла задает антивирусному движку вопросы:
Принцип работы сводится к тому, что математическая модель (а именно ансамбль решающих деревьев) при анализе файла задает антивирусному движку вопросы:
Ответив на все вопросы, антивирусный движок получает от матмодели вердикт «Файл чистый/вредоносный». «Как построить такое классное дерево? — спросите вы. — Принцип работы-то понятен, но что конкретно писать в вершинах решающего дерева?» Отвечу так: строится ансамбль деревьев с помощью алгоритма градиентного бустинга, и именно в этом заключаются компетенции Detection Methods Analysis Group и, я бы даже сказал, ноу-хау этой команды.
Второй подход строится на использовании локально устойчивых сверток.

Разноцветные точки (файлы) слева хэшируются традиционным способом — хэши не имеют ничего общего; справа сворачиваются в LSH-свертку — не сильно отличающиеся файлы получают близкие или одинаковые свертки
Опять-таки, принцип прост, а вот чтобы применить Orthogonal Projection Learning и построить математическую модель, нужны упомянутый системный подход и лучшие эксперты.

Формальная постановка задачи по построению набора локально устойчивых сверток
Подробнее об этих двух методах можно почитать тут и, конечно же, в патенте «Лаборатории».
Поведенческая математическая модель
Все, что описано выше, относится к статическому детектированию. Иными словами, антивирусу на вход подается файл, решение по которому принимает математическая модель. Однако специалисты по машинному обучению сходятся во мнении, что какой бы умной ни была матмодель, ее всегда при желании может обойти человек. Дело в том, что человек креативен, он может заглянуть внутрь, понять, как оно работает, и заточиться под это. Именно поэтому модель должна быть обновляемой по частям, а инфраструктура — работать как часы, для быстрой реакции.
Но есть и другой подход к решению этой проблемы — динамическое детектирование. В этом случае математическая модель может анализировать поведение исполняемого файла уже после запуска. Строить и обучать модель можно по тем же принципам, что и матмодели статического детектирования, но с определенными ограничениями. Ведь матмодель должна принять решение не после анализа всего поведения файла, а после минимального количества действий (сразу после старта), поскольку эти действия могут быть вредоносными.
Как раз сейчас команда Detection Methods Analysis Group пилотирует поведенческую модель, которая показывает отличные результаты. Как только все будет отлажено, модель будет выпущена и доставлена в рамках обновлений нашим пользователям.
Вывод
Я довольно давно работаю в «Лаборатории Касперского» и своими глазами видел, как компания развивалась и проходила все этапы становления. Конечно, были у нас и технологические прорывы, и «застойные» времена, когда было совершенно непонятно, куда двигаться, чтобы получить качественное улучшение. Бывало даже так, что новые технологии содержали ошибки, которые неминуемо вели бы к серьезным ложным срабатываниям, если бы не многоступенчатая система защиты. Но всегда оставалось неизменным одно: за каждой технологией и достижениями всегда стояли реальные люди, мои коллеги. Наверное, именно поэтому место в вершине треугольника нашей концепции HuMachine отдано нашим экспертам.
Я пришел в «Лабораторию Касперского» студентом четвертого курса в 2004 году. Тогда мы работали по сменам, ночами, чтобы обеспечить максимальную скорость реакции на новые угрозы в индустрии. Многие конкурирующие компании в то время выпускали обновления антивирусных баз раз в сутки, им круглосуточная работа была не так важна. Мы же гордились тем, что смогли перейти на ежечасные обновления.
К слову, сам Евгений Валентинович Касперский сидел в той же комнате офиса, что и другие вирусные аналитики. Он «долбил» вирусы как и все, просто быстрее. И еще жаловался, что пиар-команда постоянно выдергивает его в командировки и не дает поработать в свое удовольствие. В общем, можно смело утверждать, что в 2004 году машинное обучение при анализе и детектировании вредоносного кода в «Лаборатории Касперского» не использовалось.
Скорость моего анализа вредоносов была в то время на порядок ниже темпа работы других аналитиков, ведь тут огромную роль играет опыт, и только со временем ты начинаешь «узнавать» семейства зловредов, просто заглянув внутрь.
Характерный вид содержимого Backdoor.Win32.Bifrose, популярного бэкдора того времени
Напомню, что в тот момент я учился в институте и занимался цветовой сегментацией изображений. Я обратил внимание, что для поиска похожих изображений исследователи придумали много всяких методов и постоянно работали над совершенствованием подходов, а вот для поиска похожих файлов и даже определения степени схожести двух вариантов — ничего.
Поиск похожих файлов
Я решил попробовать покопать в этом направлении и в рамках курсовой работы поставил себе такую задачу: программа анализирует всю коллекцию вредоносов, потом ей на вход подается новый исследуемый файл, и она сообщает, на кого он похож больше всего.
Для этого исполняемые файлы я представил в виде картинок (чем ярче точка, тем больше значение байта в файле).
spoolsv.exe, версия 5.1.2600.2180, eng и Ipconfig.exe, версия 5.1.2600.2180, rus
Глядя на такие картинки, даже человек, далекий от вирусного анализа, способен различать и узнавать представителей различных вирусных семейств. Выходит, это верный путь. Осталось только формализовать его и запрограммировать.
Сначала я пытался сделать все «по науке», используя дискретное вейвлет-преобразование. Ведь при таком поиске кажется логичным сперва учитывать самое главное и потом постепенно добавлять больше деталей, сужая область запроса и обнаруживая самый похожий вариант.
An example of the 2D discrete wavelet transform that is used in JPEG2000
Но после ряда экспериментов оказалось, что лучший подход — самый простой, а именно использование кусочно-постоянной интерполяции. Иными словами, нужно просто разбить файл на кусочки и посчитать среднее по всем байтам в кусочке.
Процесс кусочно-постоянной интерполяции уменьшает количество деталей и позволяет легче увидеть похожие файлы
А название утилиты так и осталось от сложного метода — DWT (Discrete Wavelet Transform). Интересно, что параллельно другой наш сотрудник сделал по сути то же самое. Но в итоге, когда я продемонстрировал Евгению Валентиновичу работающую программу, он похвалил и сказал: «Всем пользоваться».
Фактически этот метод можно считать первым шагом «Лаборатории» к использованию машинного обучения, пусть сам подход и был довольно простым по современным меркам. Свое первенство «Лаборатория Касперского» застолбила с помощью патента.
Поиск похожих файлов 2.0
Впрочем, одно дело — просто подсказать вирусному аналитику, на какой известный зловред похож исследуемый файл, а другое — принять решение, что исследуемый файл надо задетектировать. Перед этим необходимо еще убедиться в том, что два конкретных файла действительно похожи. Иными словами, для автодетектирования нужен сначала поиск, а потом сравнение.
Задача сравнения файлов решалась с помощью сравнения функциональных строк.
Строковое сравнение двух экземпляров Trojan-PSW.Win32.LdPinch. Посередине строки, которые есть в обоих экземплярах, слева — строки, которые есть только в первом, справа — только во втором
Если совпадающих строк (а следовательно, и функционала) больше, чем различающихся, то два файла считаются похожими, и, значит, можно добавлять детектирование. Однако на этом этапе меня беспокоило, что похожий файл мы ищем по его бинарному представлению, а сверяем с другими файлами уже по строкам. Это все равно что сначала преступника по фотографии опознавать, а только потом по отпечаткам пальцев проверять. Ведь в нашей задаче мы можем сразу искать по отпечаткам. Это позволит не передавать в «следственный отдел» тех «подозреваемых», на которых «свидетели» указали по ошибке.
Впрочем, не все так просто. Тогда предстояло решить еще и техническую задачу. Ведь файлов в нашей вирусной коллекции на тот момент было больше миллиона. Это сейчас миллион вредоносных файлов наши системы сбора загребают за три дня (а одних чистых экземпляров вообще только каждый день по миллиону прибывает). Тогда же, в 2006 году, когда деревья были маленькими, а трава — высокой, — уже тогда хотелось, чтобы прототип решения трудился на рабочей станции сотрудника и искал похожие файлы за секунды. Ведь промышленному решению надо будет обрабатывать весь входящий поток «Лаборатории».
Но не будем вдаваться в технические детали — скажем только, что задача была решена. Это позволило в 2,5 раза увеличить объем файлов, обрабатываемых и детектируемых автоматически. Помню, я тогда, засыпая, сильно переживал: «Как же так, вот мы сейчас нанимаем профессионалов для анализа вредоносов, а ведь когда мы автоматизируем процесс оперативной борьбы, эти спецы останутся без работы, так, что ли? Надо поскорее закончить реализацию, пока мы не наняли слишком много сотрудников!»
Но действительность все расставила по своим местам: с приходом автоматизации наши вирусные аналитики и эксперты смогли гораздо больше времени посвящать стратегической борьбе с вредоносами и разработке передовых технологий.
Ну и как водится, свое первенство «Лаборатория Касперского» застолбила тогда с помощью патента.
Системный подход
Довольно быстро, году в 2007-м, стало понятно, что нужно не просто автоматизировать детектирование и получать тем самым лучшую скорость реакции в индустрии, нужно перенести наработки на сторону продукта, чтобы решение принималось у клиента.
Внутри антивирусной лаборатории была создана Detection Methods Analysis Group. Интересно, что в настоящий момент только ее руководитель в прошлом вирусный аналитик, остальные сотрудники — это чистые Data Scientist’ы. Они сразу поставили задачу формально, выработали критерии похожести, ввели функцию потерь и начали применять математические методы. В общем, реализовали академический подход. Довольно быстро непосвященным стало ничего не понятно в их разговорах, я даже начал сомневаться, что из такого системного подхода что-нибудь выйдет, уж очень фундаментально они подошли. Я просто сам предпочитаю иной путь — «забабахать прототип на коленке — и готово». Но, несмотря на мой осторожный скепсис, с поставленной задачей команда отлично справилась.
Первый подход наших экспертов основывался на решающих деревьях.
Принцип работы сводится к тому, что математическая модель (а именно ансамбль решающих деревьев) при анализе файла задает антивирусному движку вопросы:- А файл больше 100 килобайт?
- А раз да, то файл упакован?
- А раз нет, то в файле имена секций человеческие или мусорные?
- А раз да, то… и так далее.
Ответив на все вопросы, антивирусный движок получает от матмодели вердикт «Файл чистый/вредоносный». «Как построить такое классное дерево? — спросите вы. — Принцип работы-то понятен, но что конкретно писать в вершинах решающего дерева?» Отвечу так: строится ансамбль деревьев с помощью алгоритма градиентного бустинга, и именно в этом заключаются компетенции Detection Methods Analysis Group и, я бы даже сказал, ноу-хау этой команды.
Второй подход строится на использовании локально устойчивых сверток.
Разноцветные точки (файлы) слева хэшируются традиционным способом — хэши не имеют ничего общего; справа сворачиваются в LSH-свертку — не сильно отличающиеся файлы получают близкие или одинаковые свертки
Опять-таки, принцип прост, а вот чтобы применить Orthogonal Projection Learning и построить математическую модель, нужны упомянутый системный подход и лучшие эксперты.
Формальная постановка задачи по построению набора локально устойчивых сверток
Подробнее об этих двух методах можно почитать тут и, конечно же, в патенте «Лаборатории».
Поведенческая математическая модель
Все, что описано выше, относится к статическому детектированию. Иными словами, антивирусу на вход подается файл, решение по которому принимает математическая модель. Однако специалисты по машинному обучению сходятся во мнении, что какой бы умной ни была матмодель, ее всегда при желании может обойти человек. Дело в том, что человек креативен, он может заглянуть внутрь, понять, как оно работает, и заточиться под это. Именно поэтому модель должна быть обновляемой по частям, а инфраструктура — работать как часы, для быстрой реакции.
Но есть и другой подход к решению этой проблемы — динамическое детектирование. В этом случае математическая модель может анализировать поведение исполняемого файла уже после запуска. Строить и обучать модель можно по тем же принципам, что и матмодели статического детектирования, но с определенными ограничениями. Ведь матмодель должна принять решение не после анализа всего поведения файла, а после минимального количества действий (сразу после старта), поскольку эти действия могут быть вредоносными.
Как раз сейчас команда Detection Methods Analysis Group пилотирует поведенческую модель, которая показывает отличные результаты. Как только все будет отлажено, модель будет выпущена и доставлена в рамках обновлений нашим пользователям.
Вывод
Я довольно давно работаю в «Лаборатории Касперского» и своими глазами видел, как компания развивалась и проходила все этапы становления. Конечно, были у нас и технологические прорывы, и «застойные» времена, когда было совершенно непонятно, куда двигаться, чтобы получить качественное улучшение. Бывало даже так, что новые технологии содержали ошибки, которые неминуемо вели бы к серьезным ложным срабатываниям, если бы не многоступенчатая система защиты. Но всегда оставалось неизменным одно: за каждой технологией и достижениями всегда стояли реальные люди, мои коллеги. Наверное, именно поэтому место в вершине треугольника нашей концепции HuMachine отдано нашим экспертам.
Источник: habrahabr.ru