Будущее веб-технологий: создаём интеллектуального чат-бота, который может слышать и говорить
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-08-22 16:01
алгоритмы распознавания речи, распознавание образов, компьютерная лингвистика, голосовые помощники, искусственный интеллект, разработка чат-ботов

Голосовые интерфейсы в наши дни вездесущи. Во-первых — всё больше пользователей мобильных телефонов используют голосовых помощников, таких как Siri и Cortana. Во-вторых — устройства, вроде Amazon Echo и Google Home, становятся привычным элементом интерьера. Эти системы построены на базе программного обеспечения для распознавания речи, которое позволяет пользователям общаться с машинами с помощью голосовых команд. Теперь же эстафета, в обличье Web Speech API, переходит к браузерам.
 В ходе разработки веб-приложения мы, для организации взаимодействия с пользователем, можем полагаться на различные графические элементы управления. Web Speech API позволяет интегрировать в приложения естественные для человека способы голосовой коммуникации при минимальном визуальном интерфейсе. В нашем распоряжении оказывается бесчисленное множество вариантов применения новой технологии, обогащающей возможности программ. Кроме того, Web Speech API способно сделать работу с веб-приложениями удобнее для людей с физическими или когнитивными ограничениями или травмами. Таким образом, веб-пространство будущего вполне может стать общительнее и доступнее.
В ходе разработки веб-приложения мы, для организации взаимодействия с пользователем, можем полагаться на различные графические элементы управления. Web Speech API позволяет интегрировать в приложения естественные для человека способы голосовой коммуникации при минимальном визуальном интерфейсе. В нашем распоряжении оказывается бесчисленное множество вариантов применения новой технологии, обогащающей возможности программ. Кроме того, Web Speech API способно сделать работу с веб-приложениями удобнее для людей с физическими или когнитивными ограничениями или травмами. Таким образом, веб-пространство будущего вполне может стать общительнее и доступнее.
Web Speech API позволяет веб-сайтам и веб-приложениям не только говорить с пользователем, но и воспринимать его речь. Взгляните хотя бы на несколько отличных примеров того, как это может быть использовано для расширения возможностей взаимодействия программ с человеком.
Сегодня мы расскажем о том, как используя Web Speech API создать интеллектуальный браузерный голосовой чат. Программа будет слушать пользователя и отвечать на его реплики синтезированным голосом. Так как Web Speech API всё ещё носит статус экспериментального, приложение будет работать лишь в тех браузерах, которые поддерживают это API.
Возможности, использованные в этом материале, и распознавание, и синтез речи, сейчас поддерживают только браузеры, основанные на Chromium, в том числе — Chrome 25+ и Opera 27+, в то время как Firefox, Edge и Safari поддерживают только синтез речи.

Поддержка синтеза и распознавания речи в различных браузерах
Вот видео, в котором показано, как то, что мы собираемся создать, работает в Chrome.
Работа над веб-приложением состоит из трёх основных шагов:

Схема взаимодействия приложения с пользователем и внешними службами
Полный исходный код того, что мы тут создадим, можно найти на GitHub.
Данное учебное руководство основано на Node.js. Для того, чтобы успешно с ним разобраться, вы должны знать JavaScript и иметь базовое понимание Node.js. Проверьте, установлен ли у вас Node и можете приступать к работе.
Затем выполните такую команду для инициализации приложения:
Ключ
Теперь нужно установить зависимости, необходимые для сборки программы:
Использование флага
Мы собираемся использовать Express — серверный фреймворк для Node.js-приложений, который будет работать на локальном сервере. Для того, чтобы организовать двунаправленный обмен данными между сервером и клиентом в реальном времени, применим Socket.IO. Кроме того, мы установим средство для взаимодействия со службой обработки естественного языка API.AI. Это позволит нам создать интеллектуального чат-бота, способного поддерживать беседу с человеком.
Socket.IO — это библиотека, упрощающая использование технологии WebSockets в Node.js. После установки соединения между клиентом и сервером, основанном на сокетах, сообщения между ними будут передаваться очень быстро. А именно, происходить это будет, со стороны клиента, в тот момент, когда Web Speech API преобразует фразу пользователя в текстовое сообщение, и, со стороны сервера, когда текст ответа искусственного интеллекта придёт от API.AI.
Создадим файл
Теперь займёмся работой над клиентской частью системы. На следующем этапе работы мы интегрируем Web Speech API в интерфейс приложения.
Пользовательский интерфейс этого приложения очень прост. Его главный элемент — кнопка, нажатие на которую запускает распознавание голоса. Настроим файл
Добавим в тело HTML-документа кнопку:
Для стилизации кнопки используется файл
Тут мы используем имена объектов с префиксом и без него, так как Chrome сейчас поддерживает нужное нам API только в варианте с префиксом
Кроме того, мы применяем синтаксис ECMAScript6. В него входит поддержка ключевого слова
При желании распознавание речи можно настроить, устанавливая различные свойства соответствующего объекта. Мы применяем следующие настройки:
Затем нам нужна ссылка на кнопку. Мы будем прослушивать событие нажатия на неё, которое используется для запуска процесса распознавания речи.
После запуска распознавания воспользуемся событием
Здесь нас интересует объект
Сейчас воспользуемся Socket.IO для передачи данных серверному коду.
Возможно, вы зададитесь вопросом о том, почему мы не используем простые HTTP или AJAX-запросы. Данные можно было бы отправить на сервер, например, используя POST-запрос. Однако, мы используем WebSockets посредством Socket.IO, так как это — наиболее удачное решение для организации двунаправленного обмена, в особенности для тех случаев, когда события передаются с сервера в браузер. Благодаря постоянному соединению на базе сокета, нам не нужно перезагружать данные в браузере или часто отправлять AJAX-запросы.
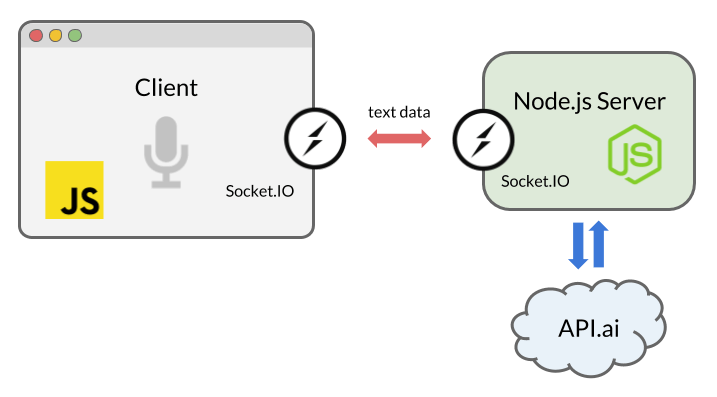
Схема взаимодействия клиента, сервера и стороннего сервиса обработки естественного языка
На клиенте, в файле
Затем добавим следующий код туда, где мы обрабатываем событие
Теперь перейдём к серверной части приложения. Она должна получить текст, переданный клиентом и передать его стороннему сервису, реализующему функции искусственного интеллекта. После получения ответа от сервиса, сервер должен передать его клиенту.
После того, как вы создали учётную запись, создайте агента. Почитать об этом можно в начале руководства по началу работы. Полная настройка подразумевает создание сущностей и настройку связей между фразами, сказанными пользователем, и действиями, выполняемыми системой. Мы не будем этим заниматься, воспользовавшись предустановкой Small Talk. Этот пункт надо выбрать в левом меню, а затем, с помощью переключателя, включить сервис.

Настройка Small Talk в API.AI
Тут же, используя интерфейс API.AI, настроим агента. Перейдите к странице General Settings, щёлкнув по значку шестерёнки рядом с именем агента и получите ключ API. Вам понадобится то, что называется здесь «client access token» — токен доступа к сервису. Этот токен мы будем использовать в Node.js SDK.
Если вы собираетесь запускать код только локально, можете просто ввести тут свой токен API. В противном случае лучше хранить его в переменной окружения. Есть множество способов настройки переменных окружения, обычно я записываю соответствующие данные в файл
Итак, мы, на сервере, используем Socket.IO для получения из браузера результата распознавания речи. Как только соединение будет установлено и сообщение будет доставлено на сервер, воспользуемся возможностями API.AI для получения ответа бота на высказывание пользователя:
Когда API.AI вернёт результат, используем метод
Создадим функцию для синтеза голоса. Тут мы будем использовать интерфейс контроллера
Функция принимает, в качестве аргумента, строку, после чего система произносит текст из этой строки:
В этой функции мы сначала создаём ссылку на входную точку API
Затем, с помощью конструктора, мы создаём новый объект SpeechSynthesisUtterance(). Далее, устанавливаем свойство
И, наконец, мы используем вызов
Теперь получим ответ от сервера, снова воспользовавшись Socket.IO. Как только сообщение будет получено, вызовем вышеописанную функцию:
Теперь с нашим интеллектуальным чат-ботом можно поболтать!
Если вы пообщаетесь с этим ботом какое-то время, вам наскучит его болтовня, так как использованный здесь ИИ очень прост. Однако, боты, созданные на базе API.AI, поддаются настройке и обучению. Вы можете сделать вашего бота умнее, почитав документацию к API.AI и поработав над его интеллектом.
Надо отметить, что в этом руководстве освещены лишь основные возможности нового API, однако оно, на самом деле, очень гибко и поддерживает множество настроек. Можно менять язык распознавания и синтеза речи, синтезированный голос, включая акцент (например — американский и британский английский), высоту голоса и скорость произнесения слов. Вот несколько полезных ссылок, которые помогут вам узнать больше о Web Speech API:
Вот — полезные материалы по Node.js и по библиотекам, которыми мы здесь пользовались:
И, наконец, взгляните на различные инструменты для обработки естественного языка и на платформы для организации общения с компьютерами:
Надеюсь, вам понравился наш рассказ о голосовых веб-технологиях и вы создали интересного виртуального собеседника.
Уважаемые читатели! Какие способы применения технологий распознавания и синтеза речи в веб-приложениях кажутся вам самыми интересными и перспективными?
Web Speech API позволяет веб-сайтам и веб-приложениям не только говорить с пользователем, но и воспринимать его речь. Взгляните хотя бы на несколько отличных примеров того, как это может быть использовано для расширения возможностей взаимодействия программ с человеком.
Сегодня мы расскажем о том, как используя Web Speech API создать интеллектуальный браузерный голосовой чат. Программа будет слушать пользователя и отвечать на его реплики синтезированным голосом. Так как Web Speech API всё ещё носит статус экспериментального, приложение будет работать лишь в тех браузерах, которые поддерживают это API.
Возможности, использованные в этом материале, и распознавание, и синтез речи, сейчас поддерживают только браузеры, основанные на Chromium, в том числе — Chrome 25+ и Opera 27+, в то время как Firefox, Edge и Safari поддерживают только синтез речи.
Поддержка синтеза и распознавания речи в различных браузерах
Вот видео, в котором показано, как то, что мы собираемся создать, работает в Chrome.
Работа над веб-приложением состоит из трёх основных шагов:
- Использование интерфейса
SpeechRecognitionиз Web Speech API для организации восприятия программой голоса пользователя. - Преобразование того, что сказал пользователь, в текст, и отправка запроса коммерческому API обработки естественного языка, в нашем случае — API.AI.
- Получение ответа от API.AI и озвучивание его с использованием интерфейса
SpeechSynthesis.
Схема взаимодействия приложения с пользователем и внешними службами
Полный исходный код того, что мы тут создадим, можно найти на GitHub.
Данное учебное руководство основано на Node.js. Для того, чтобы успешно с ним разобраться, вы должны знать JavaScript и иметь базовое понимание Node.js. Проверьте, установлен ли у вас Node и можете приступать к работе.
Подготовка Node.js-приложения
Для начала подготовим каркас Node.js-приложения. Создайте папку и разместите в ней следующее:. ??? index.js ??? public ? ??? css ? ? ??? style.css ? ??? js ? ??? script.js ??? views ??? index.htmlЗатем выполните такую команду для инициализации приложения:
$ npm init -fКлюч
-f позволяет применить настройки по умолчанию, но вы можете настроить приложение и вручную, не используя этот ключ. В ходе инициализации будет создан файл package.json, который содержит основные сведения о приложении.Теперь нужно установить зависимости, необходимые для сборки программы:
$ npm install express socket.io apiai --saveИспользование флага
--save ведёт к автоматическому обновлению файла package.json. В него будут добавлены сведения о зависимостях.Мы собираемся использовать Express — серверный фреймворк для Node.js-приложений, который будет работать на локальном сервере. Для того, чтобы организовать двунаправленный обмен данными между сервером и клиентом в реальном времени, применим Socket.IO. Кроме того, мы установим средство для взаимодействия со службой обработки естественного языка API.AI. Это позволит нам создать интеллектуального чат-бота, способного поддерживать беседу с человеком.
Socket.IO — это библиотека, упрощающая использование технологии WebSockets в Node.js. После установки соединения между клиентом и сервером, основанном на сокетах, сообщения между ними будут передаваться очень быстро. А именно, происходить это будет, со стороны клиента, в тот момент, когда Web Speech API преобразует фразу пользователя в текстовое сообщение, и, со стороны сервера, когда текст ответа искусственного интеллекта придёт от API.AI.
Создадим файл
index.js, подготовим экземпляр Express и будем ожидать соединений.const express = require('express'); const app = express(); app.use(express.static(__dirname + '/views')); // html app.use(express.static(__dirname + '/public')); // js, css, images const server = app.listen(5000); app.get('/', (req, res) => { res.sendFile('index.html'); });Теперь займёмся работой над клиентской частью системы. На следующем этапе работы мы интегрируем Web Speech API в интерфейс приложения.
Распознавание речи с помощью SpeechRecognition
В Web Speech API есть основной интерфейс контроллера, называемый SpeechRecognition. Он позволяет преобразовывать в текст то, что пользователь сказал в микрофон.Пользовательский интерфейс этого приложения очень прост. Его главный элемент — кнопка, нажатие на которую запускает распознавание голоса. Настроим файл
index.html, подключим к нему файл с клиентскими скриптами (script.js) и библиотеку Socket.IO, которую позже будем использовать для обмена данными с сервером:<html lang="en"> <head>…</head> <body> … <script src="https://cdnjs.cloudflare.com/ajax/libs/socket.io/2.0.1/socket.io.js"></script> <script src="js/script.js"></script> </body> </html>Добавим в тело HTML-документа кнопку:
<button>Talk</button>Для стилизации кнопки используется файл
style.css, его можно найти в коде примера.Захват голоса с использованием JavaScript
Вscript.js, для распознавания голоса, создадим экземпляр интерфейса контроллера сервисов распознавания речи SpeechRecognition из Web Speech API:const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition; const recognition = new SpeechRecognition();Тут мы используем имена объектов с префиксом и без него, так как Chrome сейчас поддерживает нужное нам API только в варианте с префиксом
webkit.Кроме того, мы применяем синтаксис ECMAScript6. В него входит поддержка ключевого слова
const и стрелочных функций. Всё это доступно в браузерах, которые поддерживают оба интерфейса Speech API — SpeechRecognition и SpeechSynthesis.При желании распознавание речи можно настроить, устанавливая различные свойства соответствующего объекта. Мы применяем следующие настройки:
recognition.lang = 'en-US'; recognition.interimResults = false;Затем нам нужна ссылка на кнопку. Мы будем прослушивать событие нажатия на неё, которое используется для запуска процесса распознавания речи.
После запуска распознавания воспользуемся событием
result для того, чтобы получить текстовое представление того, что сказал пользователь:recognition.addEventListener('result', (e) => { let last = e.results.length - 1; let text = e.results[last][0].transcript; console.log('Confidence: ' + e.results[0][0].confidence); // Позже здесь мы воспользуемся Socket.IO });Здесь нас интересует объект
SpeechRecognitionResultList, который содержит результат распознавания речи. Текст можно извлечь из соответствующего массива. Кроме того, как вы можете видеть, мы тут выводим в консоль показатель confidence для полученного текста.Сейчас воспользуемся Socket.IO для передачи данных серверному коду.
Обмен данными в реальном времени с использованием Socket.IO
Socket.IO — это библиотека, предназначенная для веб-приложений реального времени. Она позволяет организовать двунаправленный обмен данными между клиентской и серверной частями системы. Мы собираемся использовать эту библиотеку для передачи текстового представления распознанной речи коду, работающему на Node.js-сервере, а затем — для передачи ответа сервера в браузер.Возможно, вы зададитесь вопросом о том, почему мы не используем простые HTTP или AJAX-запросы. Данные можно было бы отправить на сервер, например, используя POST-запрос. Однако, мы используем WebSockets посредством Socket.IO, так как это — наиболее удачное решение для организации двунаправленного обмена, в особенности для тех случаев, когда события передаются с сервера в браузер. Благодаря постоянному соединению на базе сокета, нам не нужно перезагружать данные в браузере или часто отправлять AJAX-запросы.
Схема взаимодействия клиента, сервера и стороннего сервиса обработки естественного языка
На клиенте, в файле
script.js, создадим экземпляр Socket.IO:const socket = io();Затем добавим следующий код туда, где мы обрабатываем событие
result от SpeechRecognition:socket.emit('chat message', text);Теперь перейдём к серверной части приложения. Она должна получить текст, переданный клиентом и передать его стороннему сервису, реализующему функции искусственного интеллекта. После получения ответа от сервиса, сервер должен передать его клиенту.
Получение ответа от внешнего сервиса
Множество платформ и сервисов позволяют интегрировать приложение с системой искусственного интеллекта с использованием преобразования речи в текст и с обработкой естественного языка. Среди них — IBM Watson, Microsoft LUIS, и Wit.ai. Для быстрого построения голосового интерфейса мы будем использовать API.AI. Здесь можно получить бесплатную учётную запись разработчика и быстро настроить ядро простого чат-бота, используя веб-интерфейс сервиса и библиотеку для Node.js.После того, как вы создали учётную запись, создайте агента. Почитать об этом можно в начале руководства по началу работы. Полная настройка подразумевает создание сущностей и настройку связей между фразами, сказанными пользователем, и действиями, выполняемыми системой. Мы не будем этим заниматься, воспользовавшись предустановкой Small Talk. Этот пункт надо выбрать в левом меню, а затем, с помощью переключателя, включить сервис.
Настройка Small Talk в API.AI
Тут же, используя интерфейс API.AI, настроим агента. Перейдите к странице General Settings, щёлкнув по значку шестерёнки рядом с именем агента и получите ключ API. Вам понадобится то, что называется здесь «client access token» — токен доступа к сервису. Этот токен мы будем использовать в Node.js SDK.
Использование SDK API.AI для Node.js
Подключим наше Node.js-приложение к API.AI с использованием соответствующего SDK. В файлеindex.js инициализируем API.AI, используя токен доступа.const apiai = require('apiai')(APIAI_TOKEN);Если вы собираетесь запускать код только локально, можете просто ввести тут свой токен API. В противном случае лучше хранить его в переменной окружения. Есть множество способов настройки переменных окружения, обычно я записываю соответствующие данные в файл
.env. В коде, который выложен на GitHub, этого файла нет, так как он включён в .gitignore. Если вы хотите узнать, как устроены подобные файлы, взгляните на файл .env-test.Итак, мы, на сервере, используем Socket.IO для получения из браузера результата распознавания речи. Как только соединение будет установлено и сообщение будет доставлено на сервер, воспользуемся возможностями API.AI для получения ответа бота на высказывание пользователя:
io.on('connection', function(socket) { socket.on('chat message', (text) => { // Получим ответ от API.AI let apiaiReq = apiai.textRequest(text, { sessionId: APIAI_SESSION_ID }); apiaiReq.on('response', (response) => { let aiText = response.result.fulfillment.speech; socket.emit('bot reply', aiText); // Send the result back to the browser! }); apiaiReq.on('error', (error) => { console.log(error); }); apiaiReq.end(); }); });Когда API.AI вернёт результат, используем метод
socket.emit() Socket.IO для отправки данных в браузер.SpeechSynthesis — голос для бота
Для того, чтобы завершить работу над приложением, вернёмся к клиентскому файлуscript.js.Создадим функцию для синтеза голоса. Тут мы будем использовать интерфейс контроллера
SpeechSynthesis из Web Speech API.Функция принимает, в качестве аргумента, строку, после чего система произносит текст из этой строки:
function synthVoice(text) { const synth = window.speechSynthesis; const utterance = new SpeechSynthesisUtterance(); utterance.text = text; synth.speak(utterance); }В этой функции мы сначала создаём ссылку на входную точку API
window.speechSynthesis. Можно заметить, что в этот раз мы не используем свойства с префиксами. Дело в том, что поддержка этого API шире, нежели у SpeechRecognition, и все браузеры, которые это API поддерживают, уже убрали префикс для SpeechSynthesis.Затем, с помощью конструктора, мы создаём новый объект SpeechSynthesisUtterance(). Далее, устанавливаем свойство
text объекта utterance. Именно то, что мы запишем в это свойство, и произнесёт машина. Тут можно устанавливать и другие свойства, например — свойство voice для выбора типа голоса.И, наконец, мы используем вызов
SpeechSynthesis.speak(), благодаря которой компьютер произносит фразу.Теперь получим ответ от сервера, снова воспользовавшись Socket.IO. Как только сообщение будет получено, вызовем вышеописанную функцию:
socket.on('bot reply', function(replyText) { synthVoice(replyText); });Теперь с нашим интеллектуальным чат-ботом можно поболтать!
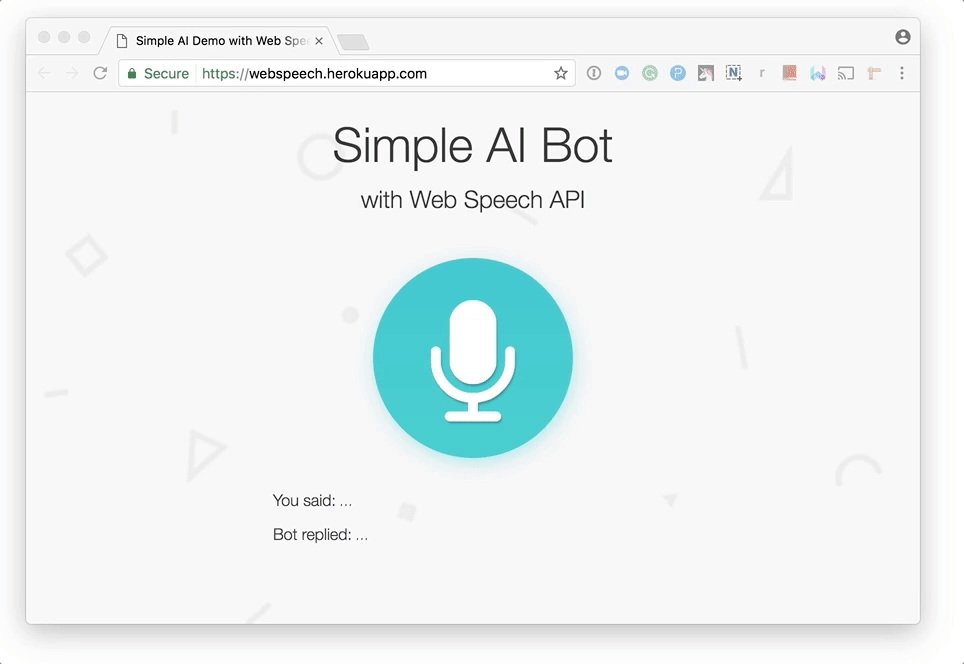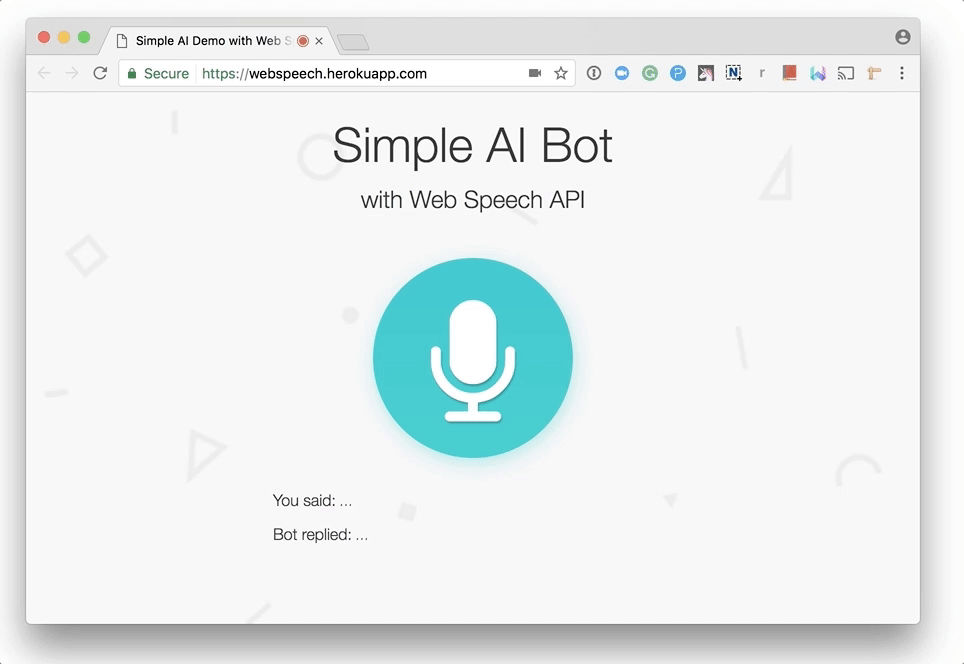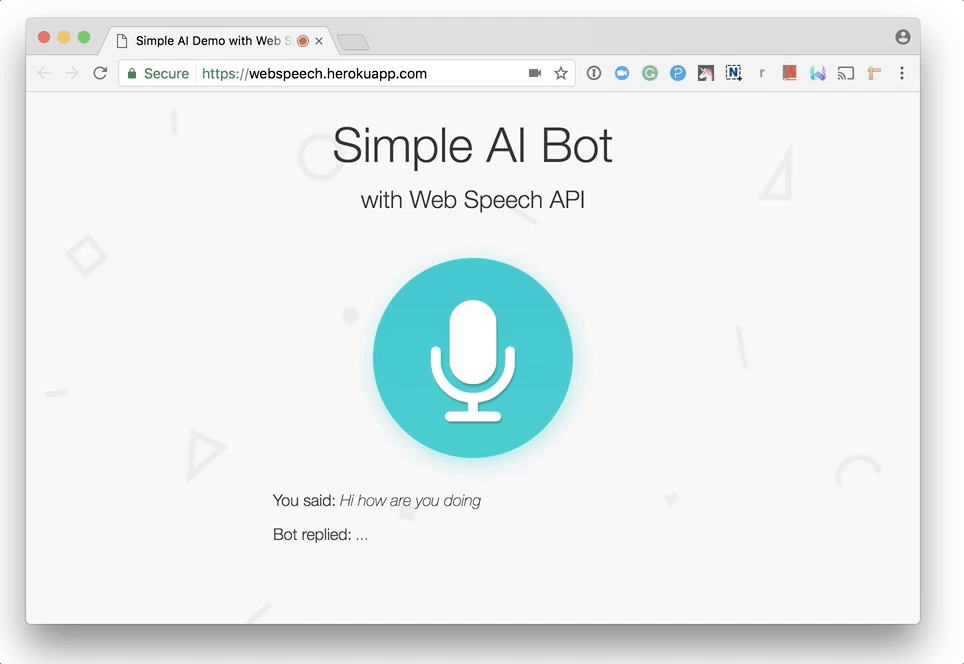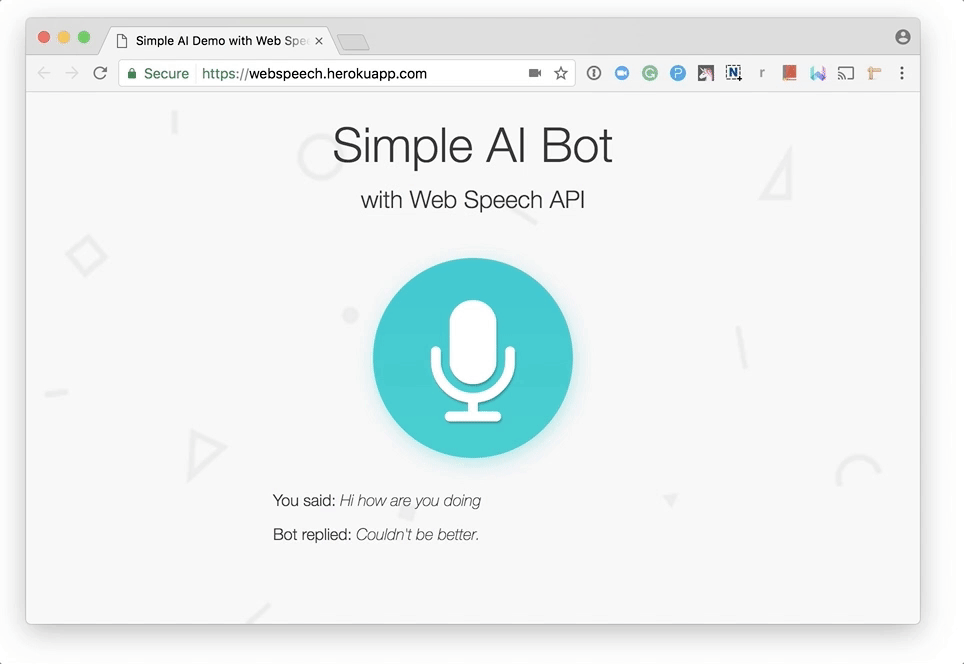
Общение с чат-ботом
Обратите внимание на то, что при первой попытке общения с программой браузер запросит у вас разрешение на использование микрофона. Как и в случае с другими API (Geolocation, Notification), браузер, перед работой с конфиденциальными данными, запрашивает разрешение. В результате ваш голос не будет записываться без вашего ведома.Если вы пообщаетесь с этим ботом какое-то время, вам наскучит его болтовня, так как использованный здесь ИИ очень прост. Однако, боты, созданные на базе API.AI, поддаются настройке и обучению. Вы можете сделать вашего бота умнее, почитав документацию к API.AI и поработав над его интеллектом.
Надо отметить, что в этом руководстве освещены лишь основные возможности нового API, однако оно, на самом деле, очень гибко и поддерживает множество настроек. Можно менять язык распознавания и синтеза речи, синтезированный голос, включая акцент (например — американский и британский английский), высоту голоса и скорость произнесения слов. Вот несколько полезных ссылок, которые помогут вам узнать больше о Web Speech API:
- Web Speech API (Mozilla Developer Network)
- Web Speech API Specification (W3C)
- Web Speech API: Speech Synthesis (Microsoft)
Вот — полезные материалы по Node.js и по библиотекам, которыми мы здесь пользовались:
И, наконец, взгляните на различные инструменты для обработки естественного языка и на платформы для организации общения с компьютерами:
Итоги: шаг в будущее веба
Полагаем, в списке разработчиков платформ для обработки естественного языка далеко не случайно оказались Google, Facebook, Microsoft, IBM и Amazon. Значит ли это, что будущее веба однозначно за голосовыми интерфейсами? Нет, с полной уверенностью этого утверждать нельзя. Однако, это, а также то, что такие интерфейсы пользуются определённой популярностью на мобильных платформах, говорит о том, что им найдётся место и в веб-приложениях. Голосовые технологии и искусственный интеллект дополнят привычные способы работы с веб-содержимым, сделав интернет удобнее и доступнее.Надеюсь, вам понравился наш рассказ о голосовых веб-технологиях и вы создали интересного виртуального собеседника.
Уважаемые читатели! Какие способы применения технологий распознавания и синтеза речи в веб-приложениях кажутся вам самыми интересными и перспективными?
Источник: habrahabr.ru