Как работает нейронный машинный перевод?
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-07-28 15:02

Описание процессов машинного перевода основанного на базе правил (Rule-Based), машинного перевода на базе фраз (Phrase-Based) и нейронного перевода

В этой публикации нашего цикла step-by-step статей мы объясним, как работает нейронный машинный перевод и сравним его с другими методами: технологией перевода на базе правил и технологией фреймового перевода (PBMT, наиболее популярным подмножеством которого является статистический машинный перевод — SMT).
Результаты исследования, полученные Neural Machine Translation, удивительны в части того, что касается расшифровки нейросети. Создается впечатление, что сеть на самом деле «понимает» предложение, когда переводит его. В этой статье мы разберем вопрос семантического подхода, который используют нейронные сети для перевода.
Давайте начнем с того, что рассмотрим методы работы всех трех технологий на различных этапах процесса перевода, а также методы, которые используются в каждом из случаев. Далее мы познакомимся с некоторыми примерами и сравним, что каждая из технологий делает для того, чтобы выдать максимально правильный перевод.
Очень простой, но все же полезной информацией о процессе любого типа автоматического перевода является следующий треугольник, который был сформулирован французским исследователем Бернардом Вокуа (Bernard Vauquois) в 1968 году:
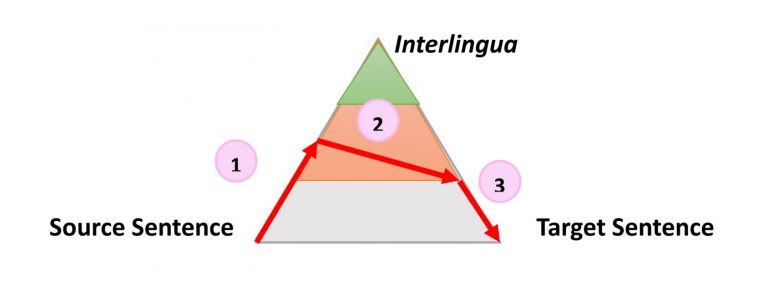
В этом треугольнике отображен процесс преобразования исходного предложения в целевое тремя разными путями.
Левая часть треугольника характеризует исходный язык, когда как правая — целевой. Разница в уровнях внутри треугольника представляет глубину процесса анализа исходного предложения, например синтаксического или семантического. Теперь мы знаем, что не можем отдельно проводить синтаксический или семантический анализ, но теория заключается в том, что мы можем углубиться на каждом из направлений. Первая красная стрелка обозначает анализ предложения на языке оригинала. Из данного нам предложения, которое является просто последовательностью слов, мы сможем получить представление о внутренней структуре и степени возможной глубины анализа.
Например, на одном уровне мы можем определить части речи каждого слова (существительное, глагол и т.д.), а на другом — взаимодействие между ними. Например, какое именно слово или фраза является подлежащим.
Когда анализ завершен, предложение «переносится» вторым процессом с равной или меньшей глубиной анализа на целевой язык. Затем третий процесс, называемый «генерацией», формирует фактическое целевое предложение из этой интерпретации, то есть создает последовательность слов на целевом языке. Идея использования треугольника заключается в том, что чем выше (глубже) вы анализируете исходное предложение, тем проще проходит фаза переноса. В конечном итоге, если бы мы могли преобразовать исходный язык в какой-то универсальный «интерлингвизм» во время этого анализа, нам вообще не нужно было бы выполнять процедуру переноса. Понадобился бы только анализатор и генератор для каждого переводимого языка на любой другой язык (прямой перевод прим. пер.)
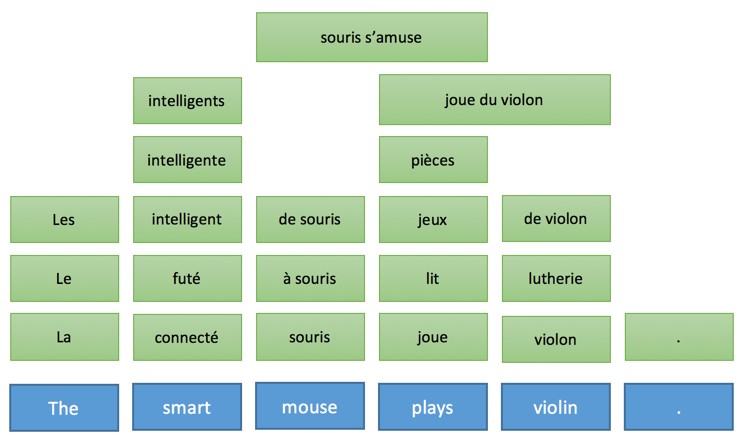
Эта общая идея и объясняет промежуточные этапы, когда машина переводит предложения пошагово. Что еще более важно, эта модель описывает характер действий во время перевода. Давайте проиллюстрируем, как эта идея работает для трех разных технологий, используя в качестве примера предложение «The smart mouse plays violin» (Выбранное авторами публикации предложение содержит небольшой подвох, так как слово «Smart» в английском языке, кроме самого распространенного смысла «умный», имеет по словарю в качестве прилагательного еще 17 значений, например «проворный» или «ловкий» прим. пер.)
Машинный перевод на базе правил
Машинный перевод на базе правил является самым старым подходом и охватывает самые разные технологии. Однако, в основе всех их обычно лежат следующие постулаты:- Процесс строго следует треугольнику Вокуа, анализ очень часто завышен, а процесс генерации сводится к минимальному;
- Все три этапа перевода используют базу данных правил и лексических элементов, на которые распространяются эти правила;
- Правила и лексические элементы заданы однозначно, но могут быть изменены лингвистом.
Например, внутреннее представление нашего предложения может быть следующим:
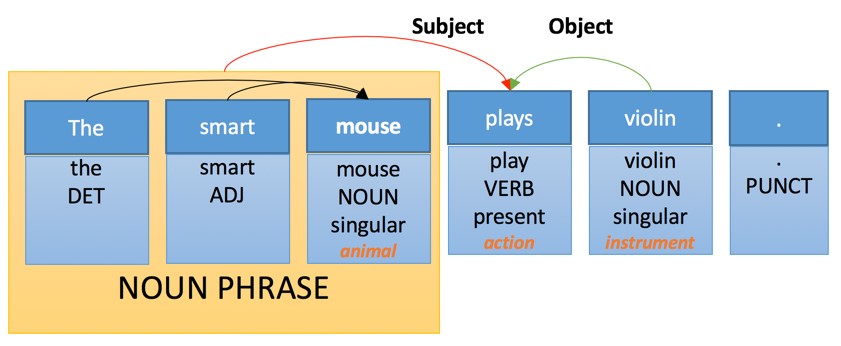
Тут мы видим несколько простых уровней анализа:
- Таргеритование частей речи. Каждому слову присваивается своя «часть речи», которая является грамматической категорией.
- Морфологический анализ: слово «plays» распознается как искажение от третьего лица и представляет форму глагола «Play».
- Семантический анализ: некоторым словам присваивается семантическая категория. Например, «Violin» — инструмент.
- Составной анализ: некоторые слова сгруппированы. «Smart mouse» — это существительное.
- Анализ зависимостей: слова и фразы связаны с «ссылками», при помощи которых происходит идентификация объекта и субъекта действия основного глагола «Plays».
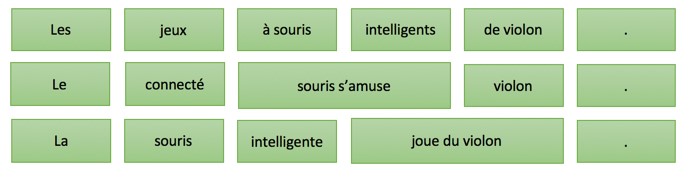
Перенос такой структуры будет подчинен следующим правилам лексического преобразования:

Применение этих правил приведет к следующей интерпретации на целевом языке перевода:
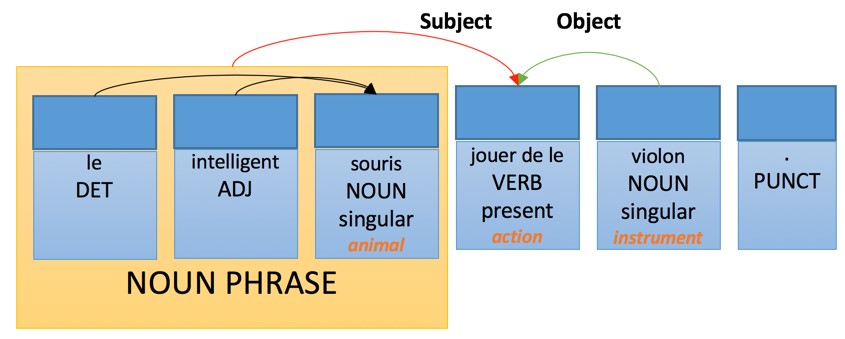
Тогда как правила генерации на французском будут иметь следующий вид:
- Прилагательное, выраженное словосочетанием, следует за существительным — с несколькими перечисленными исключениями.
- Определяющее слово согласованно по числу и роду с существительным, которое оно модифицирует.
- Прилагательное согласовано по числу и полу с существительным, которое оно модифицирует.
- Глагол согласован с подлежащим.
В идеале этот анализ сгенерирует следующую версию перевода:
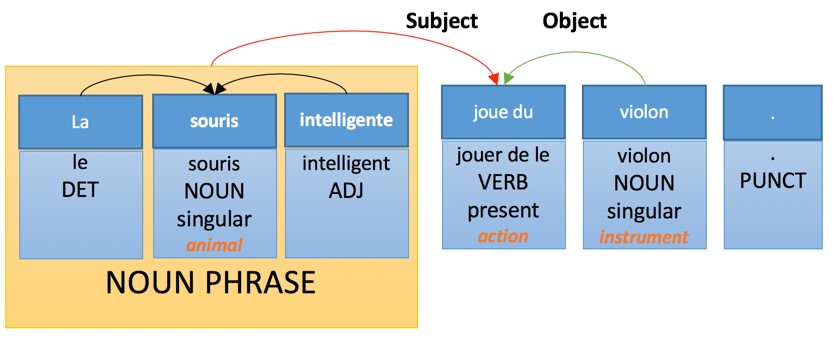
Машинный перевод на базе фраз
Машинный перевод на базе фраз — это самая простая и популярная версия статистического машинного перевода. Сегодня он по-прежнему является основной «рабочей лошадкой» и используется в крупных онлайн-сервисах по переводу. Выражаясь технически, машинный перевод на базе фраз не следует процессу, сформулированному Вокуа. Мало того, в процессе этого типа машинного перевода не проводится никакого анализа или генерации, но, что более важно, придаточная часть не является детерминированной. Это означает, что технология может генерировать несколько разных переводов одного и того же предложения из одного и того же источника, а суть подхода заключается в выборе наилучшего варианта.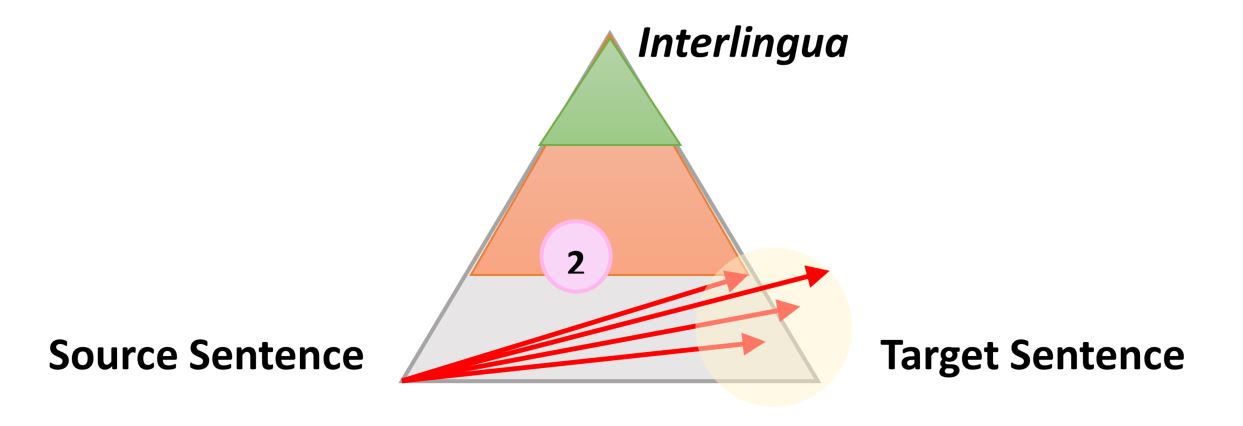
Эта модель перевода основана на трех базовых методах:
- Использование фразы-таблицы, которая дает варианты перевода и вероятность их употребления в этой последовательности на исходном языке.
- Таблица изменения порядка, которая указывает, как могут быть переставлены слова при переносе с исходного на целевой язык.
- Языковая модель, которая показывает вероятность для каждой возможной последовательности слов на целевом языке.
Следовательно, на базе исходного предложения будет построена следующая таблица (это упрощенная форма, в реальности было бы еще множество вариантов, связанных с каждым словом):
Далее из этой таблицы генерируются тысячи возможных вариантов перевода предложения, например:
Однако благодаря интеллектуальным вычислениям вероятности и использованию более совершенных алгоритмов поиска, будет рассмотрен только наиболее вероятные варианты перевода, а лучший сохранится в качестве итогового.
В этом подходе целевая языковая модель крайне важна и мы можем получить представление о качестве результата, просто поискав в Интернете:

Поисковые алгоритмы интуитивно предпочитают использовать последовательности слов, которые являются наиболее вероятными переводами исходных с учетом таблицы изменения порядка. Это позволяет с высокой точностью генерировать правильную последовательность слов на целевом языке.
В этом подходе нет явного или неявного лингвистического или семантического анализа. Нам было предложено множество вариантов. Некоторые из них лучше, другие — хуже, но, на сколько нам известно, основные онлайн-сервисы перевода используют именно эту технологию.
Нейронный машинный перевод
Подход к организации нейронного машинного перевода кардинально отличается от предыдущего и, опираясь на треугольник Вокуа, его можно описать следующим образом: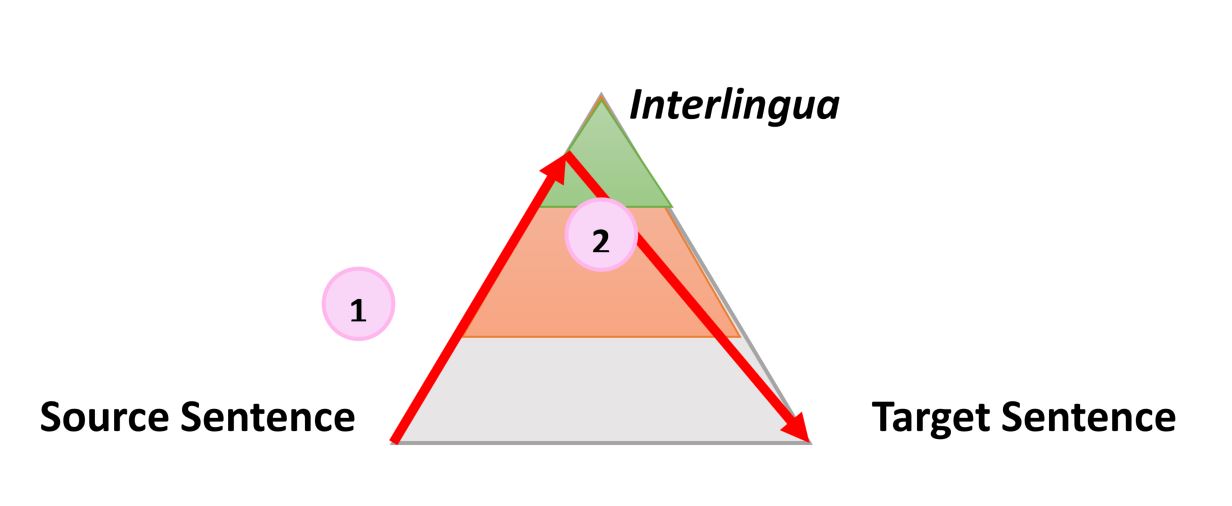
Нейронный машинный перевод имеет следующие особенности:
- «Анализ» называется кодированием, а его результатом является загадочная последовательность векторов.
- «Перенос» называется декодированием и непосредственно генерирует целевую форму без какой-либо фазы генерации. Это не строгое ограничение и, возможно, имеются вариации, но базовая технология работает именно так.
Сам процесс разбит на две фазы. В первой каждое слово исходного предложения проходит через «кодер», который генерирует то, что мы называем «исходным контекстом», опираясь при этом на текущее слово и предыдущий контекст:
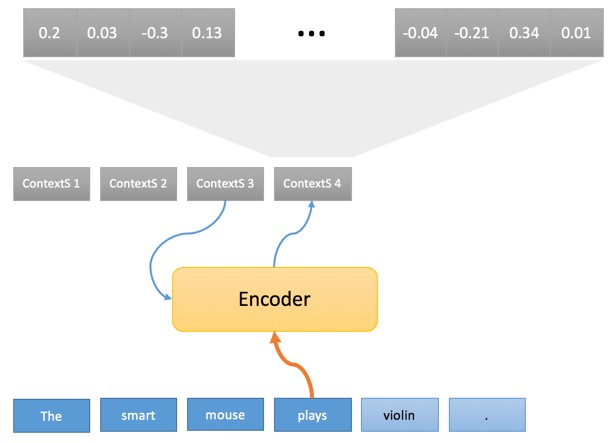
Последовательность исходных контекстов (ContextS 1,… ContextS 5) являет внутренней интерпретацией исходного предложения по треугольнику Вокуа и, как упоминалось выше, представляет из себя последовательность чисел с плавающей запятой (обычно 1000 чисел с плавающей запятой, связанных с каждым исходным словом). Пока мы не будем обсуждать, как кодировщик выполняет это преобразование, но хотелось бы отметить, что особенно любопытным является первоначальное преобразование слов в векторе «float».
На самом деле это технический блок, как и в случае с основанной на правилах системой перевода, где каждое слово сначала сравнивается со словарем, первым шагом кодера является поиск каждого исходного слова внутри таблицы.
Предположим, что вам нужно вообразить разные объекты с вариациями по форме и цвету в двумерном пространстве. При этом объекты, находящиеся ближе всего друг к другу должны быть похожи. Ниже приведен пример:
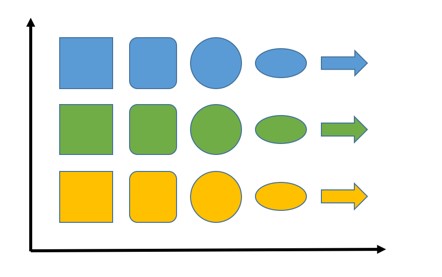
На оси абсцисс представлены фигуры и там мы стараемся поместить наиболее близкие по этому параметру объекты другой формы (нам нужно будет указать, что делает фигуры похожими, но в случае этого примера это кажется интуитивным). По оси ординат располагается цвет — зеленый между желтым и синим (расположено так, потому что зеленый является результатом смешения желтого и синего цветов, прим. пер.) Если бы у наших фигур были разные размеры, мы бы могли добавить этот третий параметр следующим образом:
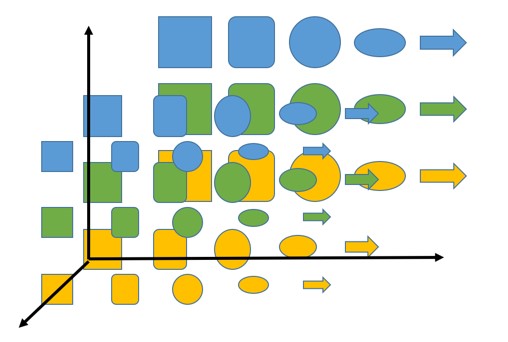
Если мы добавим больше цветов или фигур, мы также сможем увеличить и число измерений, чтобы любая точка могла представлять разные объекты и расстояние между ними, которое отражает степень их сходства.
Основная идея в том, что это работает и в случае размещения слов. Вместо фигур есть слова, пространство намного больше — например, мы используем 800 измерений, но идея заключается в том, что слова могут быть представлены в этих пространствах с теми же свойствами, что и фигуры.
Следовательно, слова, обладающие общими свойствами и признаками будут расположены близко друг к другу. Например, можно представить, что слова определенной части речи — это одно измерение, слова по признаку пола (если таковой имеется) — другое, может быть признак положительности или отрицательности значения и так далее.
Мы точно не знаем, как формируются эти вложения. В другой статье мы будем более подробно анализировать вложения, но сама идея также проста, как и организация фигур в пространстве.
Вернемся к процессу перевода. Второй шаг имеет следующий вид:
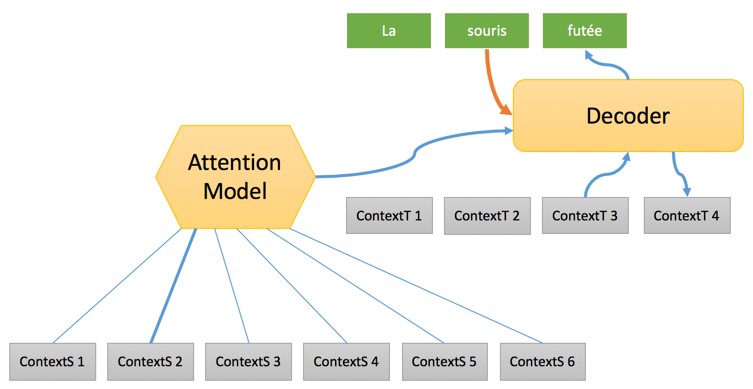
На этом этапе формируется полная последовательность с упором на «исходный контекст», после чего один за другим целевые слова генерируются с использованием:
- «Целевого контекста», сформированного в связке с предыдущим словом и предоставляющего некоторую информацию о состоянии процесса перевода.
- Значимости «контекстного источника», который представляет собой смесь различных «исходных контекстов» опираясь на конкретную модель под названием «Модель внимания» (Attention Model). Что это такое мы разберем в другой статье. Если кратко, то «Модели внимания» выбирают исходное слово для использование в переводе на любом этапе процесса.
- Ранее приведенного слова с использованием вложения слов для преобразования его в вектор, который будет обрабатываться декодером.
Перевод завершается, когда декодер доходит до этапа генерации фактически последнего слова в предложении.
Весь процесс, несомненно, весьма загадочен и нам потребуется несколько публикаций, чтобы рассмотреть работу его отдельных частей. Главное, о чем следует помнить — это то, что операции процесса нейронного машинного перевода выстроены в той же последовательности, что и в случае машинного перевода на базе правил, однако характер операций и обработка объектов полностью отличается. И начинаются эти отличия с преобразования слов в векторы через их вложение в таблицы. Понимания этого момента достаточно для того, чтобы осознать, что происходит в следующих примерах.
Примеры перевода для сравнения
Давайте разберем некоторые примеры перевода и обсудим, как и почему некоторые из предложенных вариантов не работают в случае разных технологий. Мы выбрали несколько полисемических (т.е. многозначных, прим. пер.) глаголов английского языка и изучим их перевод на французский.
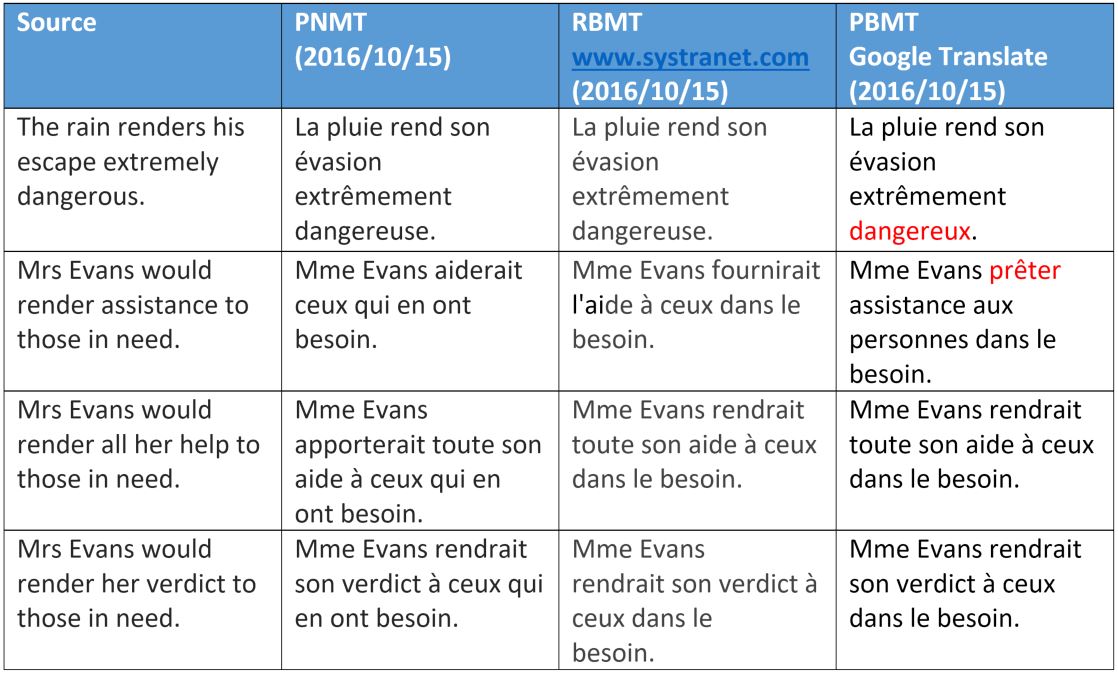
Мы видим, что машинный перевод на базе фраз, интерпретирует «render» как смысл — за исключением очень идиоматического варианта «оказание помощи». Это можно легко объяснить. Выбор значения зависит либо от проверки синтаксического значения структуре предложения, либо от семантической категории объекта.
Для нейронного машинного перевода видно, что слова «help» и «assistance» обрабатываются правильно, что показывает некоторое превосходство, а также очевидную способность этого метода получать синтаксические данные на большом расстоянии между словами, что мы более детально рассмотрим в другой публикации.

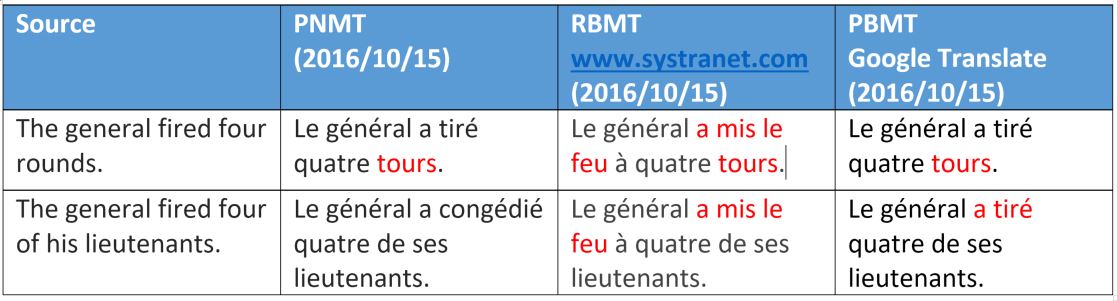
На этом примере опять видно, что нейронный машинный перевод имеет семантические различия с двумя другими способами (в основном они касаются одушевленности, обозначает слово человека или нет).
Однако отметим, что было неправильно переведено слово «rounds», которое в данном контексте имеет значение слова «bullet». Мы объясним этот типа интерпретации в другой статье, посвященной тренировке нейронных сетей. Что касается перевода на базе правил, то он распознал только третий смысл слова «rounds», который применяется в отношении ракет, а не пуль.

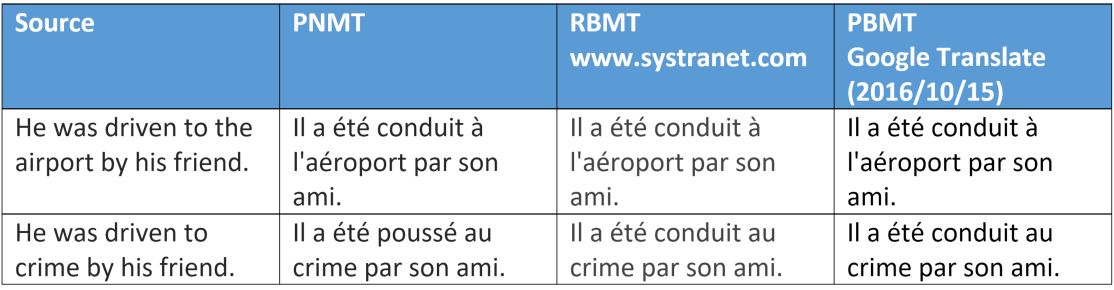
Выше еще один интересный пример того, как смысловые вариации глагола в ходе нейронного перевода взаимодействуют с объектом в случае однозначного употребления предлагаемого к переводу слова (crime или destination).
Другие варианты со словом «crime» показали тот же результат…
Переводчики работающие на базе слов и фраз так же не ошиблись, так как использовали те же глаголы, приемлемые в обоих контекстах.
Источник: habrahabr.ru