Как учится и отвечает на вопросы когнитивная система IBM Watson. Часть 1
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-05-30 23:11
 За последний десяток лет технологии шагнули далеко вперед. Интернет вещей, облачные системы, формы искусственного интеллекта, нейросети и когнитивные технологии. Все это появилось относительно недавно, но все это активно меняет нашу жизнь. IBM прикладывает значительные усилия, чтобы изменения были положительными. Делается все это не удовольствия ради, а с вполне практической целью. Дело в том, что потребности современной науки и бизнеса чрезвычайно велики. И для того, чтобы эти потребности удовлетворять, необходимы новые инструменты. Один из них — IBM Watson, когнитивная платформа, которая способная учиться, выявлять связи между отдельными элементами крупнейшего массива данных, а также взаимодействовать со своим окружением, включая пользователей.
За последний десяток лет технологии шагнули далеко вперед. Интернет вещей, облачные системы, формы искусственного интеллекта, нейросети и когнитивные технологии. Все это появилось относительно недавно, но все это активно меняет нашу жизнь. IBM прикладывает значительные усилия, чтобы изменения были положительными. Делается все это не удовольствия ради, а с вполне практической целью. Дело в том, что потребности современной науки и бизнеса чрезвычайно велики. И для того, чтобы эти потребности удовлетворять, необходимы новые инструменты. Один из них — IBM Watson, когнитивная платформа, которая способная учиться, выявлять связи между отдельными элементами крупнейшего массива данных, а также взаимодействовать со своим окружением, включая пользователей. На Habrahabr и Geektimes наша компания не раз рассказывала о том, какую пользу может принести IBM Watson. Но как работает система? В целом, ее возможности основаны на анализе окружающей среды и различных факторов. Благодаря этому платформа способна принимать определенные решения и давать ответы на задаваемые вопросы. Ниже – относительно краткое изложение принципов работы нескольких составляющих работы когнитивной системы. Это обучение, обработка языка и ответы на вопросы.
Как Watson обучается
Ключевые элементы работы когнитивной системы –эмулирование некоторых особенностей мышления человека, которые задействуются во время принятия решения и ответов на вопросы.Обучение Watson ведется в несколько этапов. Самый первый — это загрузка информации. Разработчики системы пытаются сделать ее пригодной для использования в любых областях науки, техники… да чего угодно.
Затем наступает очередь IBM Watson — начинается предварительная обработка данных с построением индексов и других метаданных, позволяющих более эффективно работать в дальнейшем. Создается «граф знаний» для представления ключевой концепции осваиваемого материала.
По завершению предварительной обработки данных снова начинают работать люди, которые помогают Watson интерпретировать полученные данные. Это делается при помощи машинного обучения, когда эксперт начинает работать с системой в форме вопрос-ответ. Такой метод помогает создавать лингвистические паттерны, относящиеся к изучаемой теме.
Еще один способ обработки и усвоения данных – постоянное взаимодействие Watson с пользователями. Эксперты регулярно оценивают эту активность и помогают Watson совершенствовать свои возможности, отвечать на все более сложные вопросы, обновлять ранее полученную информацию.Цель разработчиков — научить когнитивную систему Watson отвечать на вопросы примерно так, как это делает человек. То есть эмулировать принятие решений человеком. Это нужно как науке, медицине, так и бизнесу.
Речь, фактически, идет о «динамическом обучении», когда Watson становится умнее, получая обратную связь от пользователей и разработчиков, обучаясь на собственных ошибках.
Как Watson работает с естественным языком?
Вне зависимости от того, задается вопрос устно или письменно, системе необходимо уметь анализировать сложные смысловые конструкции, понимая не только смысловую, но и эмоциональную нагрузку текста. Для того, чтобы Watson мог правильно определять смысл текста, разработчики интегрировали в систему вопросно-ответную систему контентной аналитики (Deep Question*Answering, DeepQA). Это основа основ, на этой системе строится работа когнитивной платформы.Кроме всего прочего, система умеет распознавать и эмоциональное наполнение текста. Для этого в 2016 году были добавлены сразу три API: ToneAnalyzer, EmotionAnalysis и VisualRecognition. Обновлен сервис TexttoSpeech (TTS) с получением новых возможностей по эмоциям, а также открыт доступ к API речевого модуля Expressive TTS (работа над ним велась в течение 12 лет). В целом, модули и сервисы, которые помогают системе работать с естественным языком, разрабатываются и добавляются постоянно. Это – одна из составляющих динамического обучения, о чем говорилось выше. Постоянный прогресс, развитие – одна из задач проекта, которая вполне успешно выполняется.
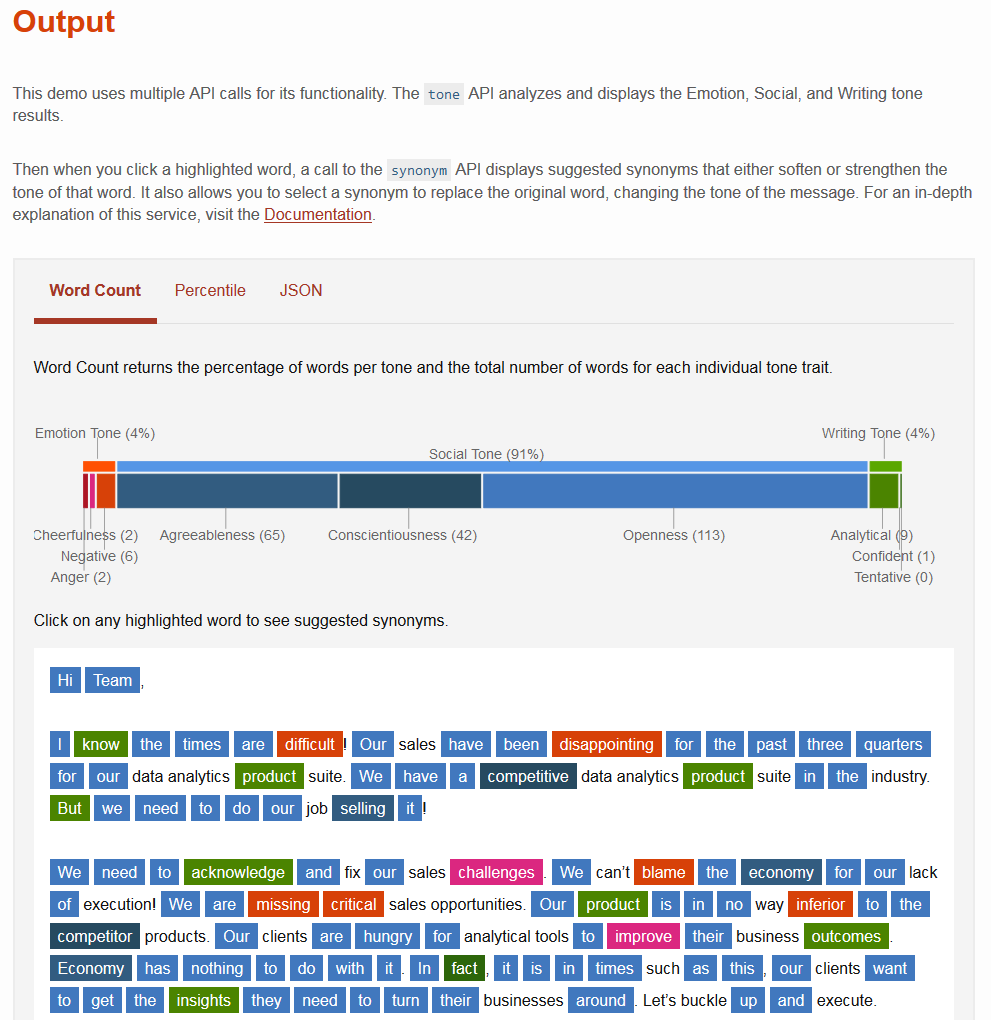 Один из примеров анализа смыслового и эмоционального наполнения письма системой IBM Watson
Один из примеров анализа смыслового и эмоционального наполнения письма системой IBM WatsonWatson теперь умеет определять стиль изложения в тексте, идентифицировать эмоции, включая позитивные и негативные, а также распознавать и классифицировать изображения.
Как Watson отвечает на вопросы?
Если упрощенно, то все выглядит следующим образом.1. Для того, чтобы система могла отвечать на какой-либо вопрос, в ее памяти должны быть релевантные данные. Об этом уже говорилось выше. Эксперты загружают различную информацию в систему, где эти данные индексируются для того, чтобы при необходимости ими можно было воспользоваться.
2. Далее вопросы отсылаются системе в текстовой или голосовой форме.
3. Вопросы анализируются системой, Watson выделяет поисковый запрос и начинает искать необходимую релевантную информацию в своей базе данных. Это можно сравнить с тем, как работает Google.
4. Генерируется ряд гипотез путем анализа фраз, которые с определенной долей вероятности могут содержать нужный ответ. Выполняется глубокое сравнение языка вопроса и языка каждого из возможных вариантов ответов. Формируется база результатов поискового запроса.
5. Каждый результат оценивается определенным образом, получая балл. При этом анализируется, в какой степени ответ релевантен области вопроса.
6. Чем выше балл одного из ответов, тем выше он ранжируется.
7. Если Watson после финального анализа считает своей ответ релевантным и актуальным, он предоставляется пользователю.
Реальный процесс поиска ответа на вопрос гораздо сложнее, поскольку каждая фраза прорабатывается при помощи нескольких алгоритмов, работающих, зачастую, в параллельном режиме. Для Watson разработаны сотни алгоритмов логического вывода. Некоторые из них выполняют поиск совпадающих терминов и синонимов, другие — рассматривают временные и пространственные особенности, а третьи — ищут и анализируют необходимые источники контекстуальной информации.
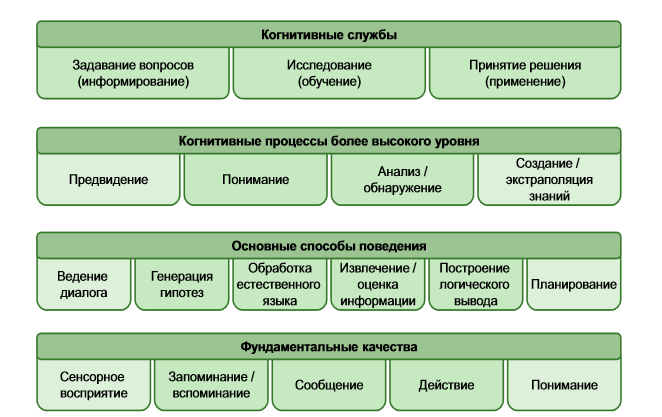 Для того, чтобы получить правильный ответ, система обращается и к дополнительным источникам данных. Например, новостям в интернете, технической литературе, справочникам. Все подряд материалы не копируются, а выверяются на актуальность с отсеиванием нерелевантной информации. Этот процесс занимает считанные секунды благодаря огромной производительности когнитивной платформы.
Для того, чтобы получить правильный ответ, система обращается и к дополнительным источникам данных. Например, новостям в интернете, технической литературе, справочникам. Все подряд материалы не копируются, а выверяются на актуальность с отсеиванием нерелевантной информации. Этот процесс занимает считанные секунды благодаря огромной производительности когнитивной платформы. Завершая этот материал, стоит отметить, что статья раскрывает далеко не все интересующие наших читателей вопросы. Пожалуйста, задавайте вопросы в комментариях, а мы будем собирать ответы наших специалистов и публиковать сборные материалы «по мотивам» комментариев. Это, наверное, один из лучших вариантов ответить на действительно интересующие вас вопросы.
Источник: habrahabr.ru