Intel предлагает полный стек ПО для машинного обучения искусственного интеллекта
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-02-25 12:45
ИТ-гиганты, алгоритмы машинного обучения, искусственный интеллект

На прошедшем недавно в Мюнхене мероприятии Intel AI Day компания обнародовала подробное описание своих программных продуктов, связанных с машинным обучением и искусственным интеллектом в целом. Портфолио ПО Intel образовано двумя сферами, одна из которых представляет накопление данных путем машинного обучения, а другая — доступ к данными и их обработку.
На низком уровне стека Intel предлагает проприетарный набор математических библиотек MKL (Math Kernel Library), в который входят вычислительные примитивы для глубинного обучения. Функции библиотек оптимизированы под собственную аппаратуру Intel — процессоры Xeon и укорители Xeon Phi, в частности, с использованием 512-битных расширений AVX. Стандартные API на языках C и Fortran позволяют легко интегрировать Intel MKL в готовые приложения.
С другой стороны, существует библиотека с открытым исходным кодом Intel MKL-DNN (Math Kernel Library for Deep Neural Networks), предназначенная специально для глубинного обучения, в которую разработчики могут включать сторонние функции, отсутствующие в Intel MKL. Другая библиотека Intel DAAL (Data Analytics Acceleration Library) состоит из аналитических функций, совместимых с популярным статистическим ПО и платформами обработки данных — Hadoop, Spark, R и пр.
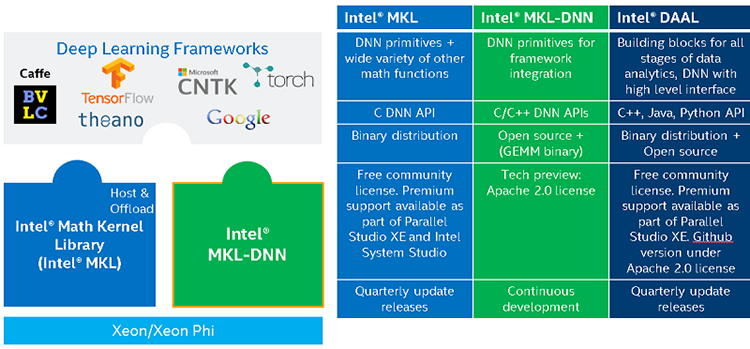
Все библиотеки рассчитаны на работу с популярными фреймворками глубинного обучения, среди которых есть версии Caffe и Theano, оптимизированные для чипов Xeon. Помимо прочего, Intel внедрила в эти платформы возможности эффективного распределения нагрузки между множественными узлами в кластере. Фреймворк глубинного обучения Neon, разработанный фирмой Nervana (создателем кремния Lake Crest и Knights Crest), также перешел в распоряжение Intel и в будущем будет дополнен ПО Nervana Graph Complier — прослойкой для масштабирования и оптимизации в задачах тренировки нейросетей. Intel также владеет собственным вариантом Python — Neon работает именно на этом языке.
Существует и отдельная библиотека для коммуникации между узлами (Intel Deep Learning Multi-node Scaling Library), а в будущем компания собирается выпустить полный API для масштабирования глубинного обучения (Machine Learning Scaling Library — MLSL).
Наконец, Intel выпустила собственную среду для обучения и внедрения глубинных нейросетей в виде Intel Deep Learning SDK. Пакет включает графический интерфейс, с помощью которого исследователь или администратор сможет установить оптимизированные для архитектуры Intel фреймворки глубинного обучения, запустить и наблюдать за процессом тренировки сети. Кроме того, есть инструмент командной строки для импорта готовых моделей, созданных в различных фреймворках, и runtime-библиотека для применения нейросети (inference). SDK совместим с операционными системами Linux и macOS, однако inference поддерживается только в Linux.
Другой подход к искусственному интеллекту воплощает Natural Intelligence Platform, разработанная компанией Saffron, которая также теперь входит в состав Intel. В основе NIP лежит база данных, построенная по принципам, сходным с человеческой ассоциативной памятью. В привычных реляционных СУБД данные хранятся в виде таблиц «строка-колонка». В системе Saffron основным форматом представления данных является матрица, принадлежащая каждой отдельной сущности. Если речь идет о базе заказов предприятия, то сущностями могут быть компания, регион, контактное лицо, номер заказа и пр.
В матрице, в свою очередь, отражены отношения между другими сущностями: например, в матрице страны это отношения между номером заказа и контактным лицом. При этом матрица компании содержит отношения между страной и номером заказа, а в целом подобные матрицы исчерпывают все возможные комбинации сущностей. Благодаря такой структуре Saffron позволяет разворачивать легко масштабируемые и гибкие базы, в которых изначально заложены функции анализа данных и принятия решений. А в качестве сырого материала могут выступать как данные, собранные вручную, так и полученные методом машинного обучения.
Материалы по теме:
Источник:
Источник: servernews.ru