Подборка фреймворков для машинного обучения
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-01-29 17:27

В последние годы машинное обучение превратилось в мейнстрим небывалой силы. Эта тенденция подпитывается не только дешевизной облачных сред, но и доступностью мощнейших видеокарт, применяемых для подобных вычислений, — появилась ещё и масса фреймворков для машинного обучения. Почти все из них open source, но куда важнее то, что эти фреймворки проектируются таким образом, чтобы абстрагироваться от самых трудных частей машинного обучения, делая эти технологии более доступными широкому классу разработчиков. Под катом представлена подборка фреймворков для машинного обучения, как недавно созданных, так переработанных в уходящем году. Если у вас все хорошо с английским, то статья в оригинале доступна здесь.
Apache Spark больше всего известен благодаря своей причастности к семейству Hadoop. Но этот фреймворк для обработки данных внутри памяти (in-memory) появился вне Hadoop, и до сих пор продолжает зарабатывать себе репутацию за пределами этой экосистемы. Spark превратился в привычный инструмент для машинного обучения благодаря растущей библиотеке алгоритмов, которые можно быстро применять к находящимся в памяти данным.
Spark не застыл в своём развитии, его алгоритмы постоянно расширяются и пересматриваются. В релизе 1.5 добавлено много новых алгоритмов, улучшены существующие, а также в Python усилена поддержка MLlib, основной платформы для решения математических и статистических задач. В Spark 1.6, помимо прочего, благодаря непрерывным конвейерам (persistent pipelines) появилась возможность приостановки и продолжения выполнения задач Spark ML.

Фреймворки «глубинного обучения» используются для решения тяжёлых задач машинного обучения, вроде обработки естественных языков и распознавания изображений. Недавно в инкубатор Apache был принят open source-фреймворк Singa, предназначенный для облегчения тренировок моделей глубокого обучения на больших объёмах данных.
Singa обеспечивает простую программную модель для тренировки сетей на базе кластера машин, а также поддерживает многие стандартные виды тренировочных заданий: свёрточные нейронные сети, ограниченные машины Больцмана и рекуррентные нейронные сети. Модели можно тренировать синхронно (одну за другой) и асинхронно (совместно), в зависимости от того, что лучше подходит для данной проблемы. Также Singa облегчает процесс настройки кластера с помощью Apache Zookeeper.

Caffe — фреймворк глубинного обучения. Он сделан «с расчётом на выразительность, скорость и модульность». Изначально фреймворк создавался для проектов машинного зрения, но с тех пор развился и теперь применяется и для других задач, в том числе для распознавания речи и работы с мультимедиа.
Главное преимущество Caffe — скорость. Фреймворк целиком написан на С++, поддерживает CUDA, и при необходимости умеет переключать поток обработки между процессором и видеокартой. В пакет поставки входит набор бесплатных и open source референсных моделей для стандартных задач по классификации. Также немало моделей создано сообществом пользователей Caffe.

Учитывая огромный объём данных и вычислительной мощности, необходимый для машинного обучения, облака являются идеальной средой для ML-приложений. Microsoft оснастила Azure собственным сервисом машинного обучения, за который можно платить только по факту использования — Azure ML Studio. Доступны версии с помесячной и почасовой оплатой, а также бесплатная (free-tier). В частности, с помощью этой системы создан проект HowOldRobot.
Azure ML Studio позволяет создавать и тренировать модели, превращать их в API для предоставления другим сервисам. На один пользовательский аккаунт может выделяться до 10 Гб места ля хранения данных, хотя можно подключить и собственное Azure-хранилище. Доступен широкий спектр алгоритмов, созданных Microsoft и сторонними компаниями. Чтобы попробовать сервис, не надо даже создавать аккаунт, достаточно войти анонимно, и можно гонять Azure ML Studio в течение восьми часов.

У Amazon есть свой стандартный подход к предоставлению облачных сервисов: сначала заинтересованной аудитории предоставляется базовая функциональность, эта аудитория что-то из неё лепит, а компания выясняет, что же на самом деле нужно людям.
То же самое можно сказать и про Amazon Machine Learning. Сервис подключается к данным, хранящимся в Amazon S3, Redshift или RDS, он может выполнять двоичную классификацию, многоклассовую категоризацию, а также регрессию по указанным данным для создания модели. Однако этот сервис завязан на Amazon. Мало того, что он использует данные, лежащие в принадлежащих компании хранилищах, так ещё и модели нельзя импортировать или экспортировать, а выборки данных для тренировок не могут быть больше 100 Гб. Но всё же это хороший инструмент для начала, иллюстрирующий, что машинное обучение превращается из роскоши в практический инструмент.

Чем больше компьютеров вы можете задействовать для решения проблемы машинного обучения, тем лучше. Но объединение большого парка машин и создание ML-приложений, которые эффективно на них выполняются, может быть непростой задачей. Фреймворк DMTK (Distributed Machine Learning Toolkit) предназначен для решения проблемы распределения различных ML-операций по кластеру систем.
DMTK считается именно фреймворком, а не полномасштабным коробочным решением, поэтому с ним идёт небольшое количество алгоритмов. Но архитектура DMTK позволяет расширять его, а также выжимать всё возможное из кластеров с ограниченными ресурсами. Например, каждый узел кластера имеет собственный кэш, что уменьшает объём обмена данными с центральным узлом, предоставляющим по запросам параметры для выполнения задач.
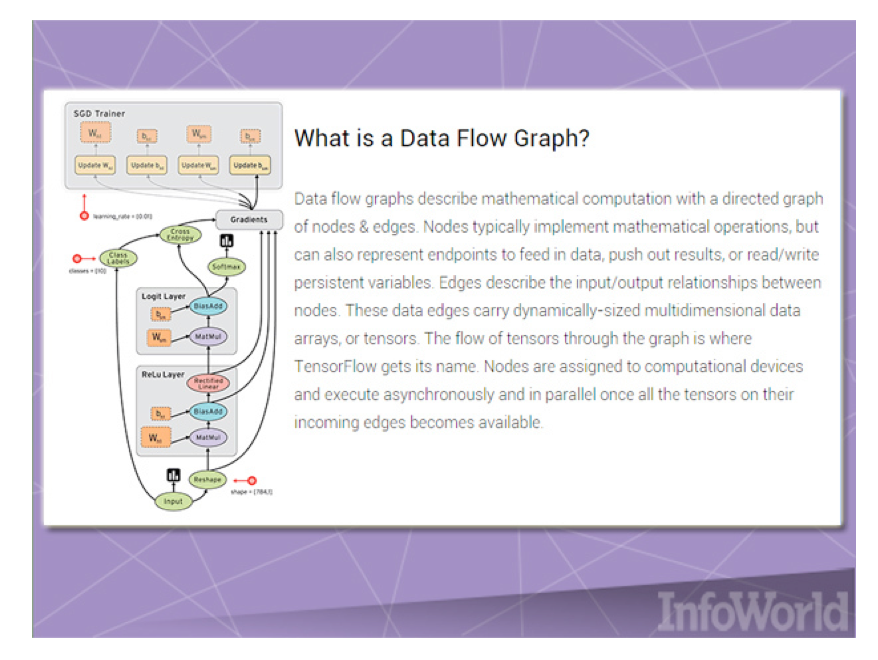
Как и Microsoft DMTK, Google TensorFlow — это фреймворк машинного обучения, созданный для распределения вычислений в рамках кластера. Наряду с Google Kubernetes этот фреймворк разрабатывался для решения внутренних проблем Google, но в конце концов компания выпустила его в открытое плавание в виде open source-продукта.
TensorFlow реализует графы потоков данных (data flow graphs), когда порции данных («тензоры») могут обрабатываться серией описанных графом алгоритмов. Перемещение данных по системе называется «потоками». Графы можно собираться с помощью С++ или Python, и обрабатывать процессором или видеокартой. У Google есть долгосрочные планы по развитию TensorFlow силами сторонних разработчиков.
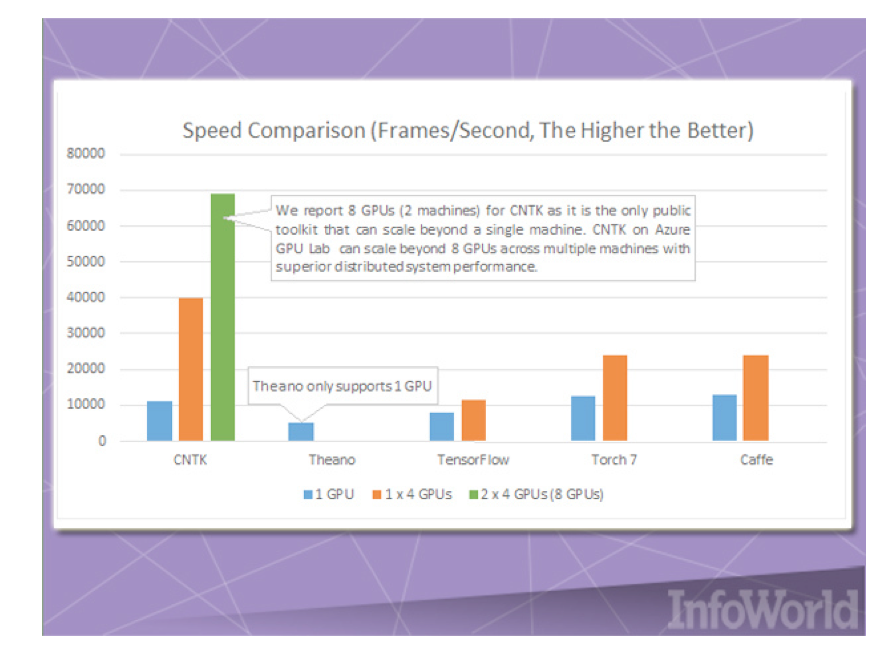
По горячим следам DMTK Microsoft выпустила ещё один инструментарий для машинного обучения — CNTK.
CNTK аналогичен Google TensorFlow, он позволяет создавать нейронные сети посредством ориентированных графов. Microsoft сравнивает этот фреймворк с такими продуктами, как Caffe, Theano и Torch. Его главное преимущество — скорость, особенно когда речь идёт о параллельном использовании нескольких процессоров и видеокарт. Microsoft утверждает, что использование CNTK в сочетании с GPU-кластерами на базе Azure позволяет на порядок ускорить тренировку по распознаванию речи виртуальным помощником Cortana.
Изначально CNTK разрабатывался как часть исследовательской программы по распознаванию речи и предлагался в виде open source-проекта, но с тех пор компания перевыпустила его на GitHub под гораздо более либеральной лицензией.
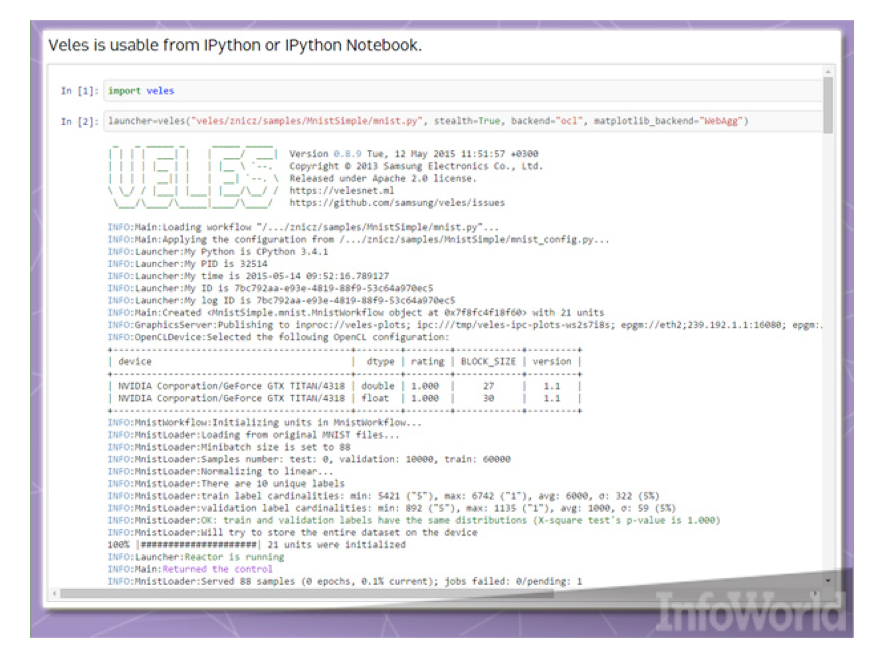
Veles — это распределённая платформа для создания приложения глубокого обучения. Как и TensorFlow и DMTK, она написана на С++, хотя для автоматизации и координации узлов используется Python. Прежде чем скармливаться кластеру выборки данных, их можно анализировать и автоматически нормализовать. REST API позволяет немедленно использовать натренированные модели в рабочих проектах (если у вас достаточно мощное оборудование).
Использование Python в Veles выходит за пределы «склеивающего кода». Например, IPython (теперь Jupyter), инструмент для визуализации и анализа данных, может выводить данные из кластера Veles. Samsung надеется, что статус open source поможет стимулировать дальнейшее развитие продукта, как и портирование под Windows и Mac OS X.

Проект Brainstorm разработан аспирантами из швейцарского института IDSIA (Institute Dalle Molle for Artificial Intelligence). Он создавался «для того, чтобы сделать нейронные сети глубокого обучения быстрее, гибче и интереснее». Уже есть поддержка различных рекуррентных нейронных сетей, например, LSTM.
В Brainstorm используется Python для реализации двух «обработчиков» — API управления данными: один для процессорных вычислений с помощью библиотеки Numpy, а второй для использования видеокарт с помощью CUDA. Большая часть работы выполняется в Python-скриптах, поэтому не ожидайте роскошного фронтенд-интерфейса, если только не прикрутите что-то своё. Но у авторов есть далеко идущие планы по «извлечению уроков из более ранних open source-проектов» и использованию «новых элементов дизайна, совместимых с различными платформами и вычислительными бэкендами».

Многие проекты по машинному обучению используют mlpack, написанную на С++ библиотеку, созданную в 2011 году и предназначенную для «масштабирования, ускорения и упрощения использования». Внедрить mlpack для выполнения сделанных на скорую руку операций типа «чёрный ящик» можно с помощью кэша файлов, исполняемых через командную строку, а для более сложных работ — с помощью API C++.
В mlpack 2.0 был проведён большой объём работы по рефакторингу и внедрению новых алгоритмов, переработке, ускорению и избавлению от неэффективных старых алгоритмов. Например, для нативных функций генерирования случайных чисел C++11 была исключён генератор библиотеки Boost.
Одним из давних недостатков mlpack является нехватка биндингов для любых других языков, за исключением С++. Поэтому программисты, пишущие на этих других языках, не могут использовать mlpack, пока кто-то не выкатит соответствующую обёртку. Была добавлена поддержка MATLAB, но подобные проекты больше всего выигрывают в тех случаях, когда они напрямую полезны в основных окружениях, где и используется машинное обучение.

Ещё один относительно свежий продукт. Marvin — это фреймворк для нейронных сетей, созданный в Princeton Vision Group. В его основе всего несколько файлов, написанных на С++, и CUDA-фреймворк. Несмотря на минимализм кода, Marvin поставляется с неплохим количеством предварительно натренированных моделей, которые можно использовать с надлежащим цитированием и внедрять с помощью pull request’ов, как и код самого проекта.

Компания Nervana создаёт программно-аппаратную платформу для глубокого обучения. И в качестве open source-проекта предлагает фреймворк Neon. С помощью подключаемых модулей он может выполнять тяжёлые вычисления на процессорах, видеокартах или оборудовании, созданном Nervana.
Neon написан на Python, с несколькими кусками на С++ и ассемблере. Так что если вы делаете научную работу на Python, или используете какой-то иной фреймворк, имеющий Python-биндинги, то можете сразу же использовать Neon.
В заключение хочется сказать, что конечно же это далеко не все популярные фреймворки. Наверняка в ваших закромах водится дюжина любимых инструментов. Не стесняйтесь, делитесь своими находками в комментариях к данной статье.

Apache Spark MLlib
Apache Spark больше всего известен благодаря своей причастности к семейству Hadoop. Но этот фреймворк для обработки данных внутри памяти (in-memory) появился вне Hadoop, и до сих пор продолжает зарабатывать себе репутацию за пределами этой экосистемы. Spark превратился в привычный инструмент для машинного обучения благодаря растущей библиотеке алгоритмов, которые можно быстро применять к находящимся в памяти данным.
Spark не застыл в своём развитии, его алгоритмы постоянно расширяются и пересматриваются. В релизе 1.5 добавлено много новых алгоритмов, улучшены существующие, а также в Python усилена поддержка MLlib, основной платформы для решения математических и статистических задач. В Spark 1.6, помимо прочего, благодаря непрерывным конвейерам (persistent pipelines) появилась возможность приостановки и продолжения выполнения задач Spark ML.
Apache Singa
Фреймворки «глубинного обучения» используются для решения тяжёлых задач машинного обучения, вроде обработки естественных языков и распознавания изображений. Недавно в инкубатор Apache был принят open source-фреймворк Singa, предназначенный для облегчения тренировок моделей глубокого обучения на больших объёмах данных.
Singa обеспечивает простую программную модель для тренировки сетей на базе кластера машин, а также поддерживает многие стандартные виды тренировочных заданий: свёрточные нейронные сети, ограниченные машины Больцмана и рекуррентные нейронные сети. Модели можно тренировать синхронно (одну за другой) и асинхронно (совместно), в зависимости от того, что лучше подходит для данной проблемы. Также Singa облегчает процесс настройки кластера с помощью Apache Zookeeper.
Caffe
Caffe — фреймворк глубинного обучения. Он сделан «с расчётом на выразительность, скорость и модульность». Изначально фреймворк создавался для проектов машинного зрения, но с тех пор развился и теперь применяется и для других задач, в том числе для распознавания речи и работы с мультимедиа.
Главное преимущество Caffe — скорость. Фреймворк целиком написан на С++, поддерживает CUDA, и при необходимости умеет переключать поток обработки между процессором и видеокартой. В пакет поставки входит набор бесплатных и open source референсных моделей для стандартных задач по классификации. Также немало моделей создано сообществом пользователей Caffe.
Microsoft Azure ML Studio
Учитывая огромный объём данных и вычислительной мощности, необходимый для машинного обучения, облака являются идеальной средой для ML-приложений. Microsoft оснастила Azure собственным сервисом машинного обучения, за который можно платить только по факту использования — Azure ML Studio. Доступны версии с помесячной и почасовой оплатой, а также бесплатная (free-tier). В частности, с помощью этой системы создан проект HowOldRobot.
Azure ML Studio позволяет создавать и тренировать модели, превращать их в API для предоставления другим сервисам. На один пользовательский аккаунт может выделяться до 10 Гб места ля хранения данных, хотя можно подключить и собственное Azure-хранилище. Доступен широкий спектр алгоритмов, созданных Microsoft и сторонними компаниями. Чтобы попробовать сервис, не надо даже создавать аккаунт, достаточно войти анонимно, и можно гонять Azure ML Studio в течение восьми часов.
Amazon Machine Learning
У Amazon есть свой стандартный подход к предоставлению облачных сервисов: сначала заинтересованной аудитории предоставляется базовая функциональность, эта аудитория что-то из неё лепит, а компания выясняет, что же на самом деле нужно людям.
То же самое можно сказать и про Amazon Machine Learning. Сервис подключается к данным, хранящимся в Amazon S3, Redshift или RDS, он может выполнять двоичную классификацию, многоклассовую категоризацию, а также регрессию по указанным данным для создания модели. Однако этот сервис завязан на Amazon. Мало того, что он использует данные, лежащие в принадлежащих компании хранилищах, так ещё и модели нельзя импортировать или экспортировать, а выборки данных для тренировок не могут быть больше 100 Гб. Но всё же это хороший инструмент для начала, иллюстрирующий, что машинное обучение превращается из роскоши в практический инструмент.
Инструментарий для распределённого машинного обучения Microsoft (Microsoft Distributed Machine Learning Toolkit)
Чем больше компьютеров вы можете задействовать для решения проблемы машинного обучения, тем лучше. Но объединение большого парка машин и создание ML-приложений, которые эффективно на них выполняются, может быть непростой задачей. Фреймворк DMTK (Distributed Machine Learning Toolkit) предназначен для решения проблемы распределения различных ML-операций по кластеру систем.
DMTK считается именно фреймворком, а не полномасштабным коробочным решением, поэтому с ним идёт небольшое количество алгоритмов. Но архитектура DMTK позволяет расширять его, а также выжимать всё возможное из кластеров с ограниченными ресурсами. Например, каждый узел кластера имеет собственный кэш, что уменьшает объём обмена данными с центральным узлом, предоставляющим по запросам параметры для выполнения задач.
Google TensorFlow
Как и Microsoft DMTK, Google TensorFlow — это фреймворк машинного обучения, созданный для распределения вычислений в рамках кластера. Наряду с Google Kubernetes этот фреймворк разрабатывался для решения внутренних проблем Google, но в конце концов компания выпустила его в открытое плавание в виде open source-продукта.
TensorFlow реализует графы потоков данных (data flow graphs), когда порции данных («тензоры») могут обрабатываться серией описанных графом алгоритмов. Перемещение данных по системе называется «потоками». Графы можно собираться с помощью С++ или Python, и обрабатывать процессором или видеокартой. У Google есть долгосрочные планы по развитию TensorFlow силами сторонних разработчиков.
Инструментарий для создания вычислительных сетей Microsoft (Microsoft Computational Network Toolkit)
По горячим следам DMTK Microsoft выпустила ещё один инструментарий для машинного обучения — CNTK.
CNTK аналогичен Google TensorFlow, он позволяет создавать нейронные сети посредством ориентированных графов. Microsoft сравнивает этот фреймворк с такими продуктами, как Caffe, Theano и Torch. Его главное преимущество — скорость, особенно когда речь идёт о параллельном использовании нескольких процессоров и видеокарт. Microsoft утверждает, что использование CNTK в сочетании с GPU-кластерами на базе Azure позволяет на порядок ускорить тренировку по распознаванию речи виртуальным помощником Cortana.
Изначально CNTK разрабатывался как часть исследовательской программы по распознаванию речи и предлагался в виде open source-проекта, но с тех пор компания перевыпустила его на GitHub под гораздо более либеральной лицензией.
Veles (Samsung)
Veles — это распределённая платформа для создания приложения глубокого обучения. Как и TensorFlow и DMTK, она написана на С++, хотя для автоматизации и координации узлов используется Python. Прежде чем скармливаться кластеру выборки данных, их можно анализировать и автоматически нормализовать. REST API позволяет немедленно использовать натренированные модели в рабочих проектах (если у вас достаточно мощное оборудование).
Использование Python в Veles выходит за пределы «склеивающего кода». Например, IPython (теперь Jupyter), инструмент для визуализации и анализа данных, может выводить данные из кластера Veles. Samsung надеется, что статус open source поможет стимулировать дальнейшее развитие продукта, как и портирование под Windows и Mac OS X.
Brainstorm
Проект Brainstorm разработан аспирантами из швейцарского института IDSIA (Institute Dalle Molle for Artificial Intelligence). Он создавался «для того, чтобы сделать нейронные сети глубокого обучения быстрее, гибче и интереснее». Уже есть поддержка различных рекуррентных нейронных сетей, например, LSTM.
В Brainstorm используется Python для реализации двух «обработчиков» — API управления данными: один для процессорных вычислений с помощью библиотеки Numpy, а второй для использования видеокарт с помощью CUDA. Большая часть работы выполняется в Python-скриптах, поэтому не ожидайте роскошного фронтенд-интерфейса, если только не прикрутите что-то своё. Но у авторов есть далеко идущие планы по «извлечению уроков из более ранних open source-проектов» и использованию «новых элементов дизайна, совместимых с различными платформами и вычислительными бэкендами».
mlpack 2
Многие проекты по машинному обучению используют mlpack, написанную на С++ библиотеку, созданную в 2011 году и предназначенную для «масштабирования, ускорения и упрощения использования». Внедрить mlpack для выполнения сделанных на скорую руку операций типа «чёрный ящик» можно с помощью кэша файлов, исполняемых через командную строку, а для более сложных работ — с помощью API C++.
В mlpack 2.0 был проведён большой объём работы по рефакторингу и внедрению новых алгоритмов, переработке, ускорению и избавлению от неэффективных старых алгоритмов. Например, для нативных функций генерирования случайных чисел C++11 была исключён генератор библиотеки Boost.
Одним из давних недостатков mlpack является нехватка биндингов для любых других языков, за исключением С++. Поэтому программисты, пишущие на этих других языках, не могут использовать mlpack, пока кто-то не выкатит соответствующую обёртку. Была добавлена поддержка MATLAB, но подобные проекты больше всего выигрывают в тех случаях, когда они напрямую полезны в основных окружениях, где и используется машинное обучение.
Marvin
Ещё один относительно свежий продукт. Marvin — это фреймворк для нейронных сетей, созданный в Princeton Vision Group. В его основе всего несколько файлов, написанных на С++, и CUDA-фреймворк. Несмотря на минимализм кода, Marvin поставляется с неплохим количеством предварительно натренированных моделей, которые можно использовать с надлежащим цитированием и внедрять с помощью pull request’ов, как и код самого проекта.
Neon
Компания Nervana создаёт программно-аппаратную платформу для глубокого обучения. И в качестве open source-проекта предлагает фреймворк Neon. С помощью подключаемых модулей он может выполнять тяжёлые вычисления на процессорах, видеокартах или оборудовании, созданном Nervana.
Neon написан на Python, с несколькими кусками на С++ и ассемблере. Так что если вы делаете научную работу на Python, или используете какой-то иной фреймворк, имеющий Python-биндинги, то можете сразу же использовать Neon.
В заключение хочется сказать, что конечно же это далеко не все популярные фреймворки. Наверняка в ваших закромах водится дюжина любимых инструментов. Не стесняйтесь, делитесь своими находками в комментариях к данной статье.
Источник: habrahabr.ru