Методы оптимизации нейронных сетей
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-01-05 09:09

В подавляющем большинстве источников информации о нейронных сетях под «а теперь давайте обучим нашу сеть» понимается «скормим целевую функцию оптимизатору» лишь с минимальной настройкой скорости обучения. Иногда говорится, что обновлять веса сети можно не только стохастическим градиентным спуском, но безо всякого объяснения, чем же примечательны другие алгоритмы и что означают загадочные и
в их параметрах. Даже преподаватели на курсах машинного обучения зачастую не заостряют на этом внимание. Я бы хотел исправить недостаток информации в рунете о различных оптимизаторах, которые могут встретиться вам в современных пакетах машинного обучения. Надеюсь, моя статья будет полезна людям, которые хотят углубить своё понимание машинного обучения или даже изобрести что-то своё.
Статья ориентирована на знакомого с нейронными сетями читателя. Предполагается, что вы уже понимаете суть backpropagation и SGD. Я не буду вдаваться в строгое доказательство сходимости представленных ниже алгоритмов, а наоборот, постараюсь донести их идеи простым языком и показать, что формулы открыты для дальнейших экспериментов. В статье перечислены далеко не все сложности машинного обучения и далеко не все способы их преодолевать.
Зачем нужны ухищрения
Напомню, как выглядят формулы для обычного градиентного спуска:
где — параметры сети,
— целевая функция или функция потерь в случае машинного обучения, а
— скорость обучения. Выглядит удивительно просто, но много магии сокрыто в
— обновить параметры выходного слоя довольно просто, но чтобы добраться до параметров слоёв за ним, приходится проходить через нелинейности, производные от которых вносят свой вклад. Это знакомый вам принцип обратного распространения ошибки — backpropagation.
Явно расписанные формулы для обновления весов где-нибдуь в середине сети выглядят страшненько, ведь каждый нейрон зависит ото всех нейронов, с которымии он связан, а те — ото всех нейронов, с которыми связаны они, и так далее. При этом даже в «игрушечных» нейронных сетях может быть порядка 10 слоёв, а среди сетей, удерживающих олимп классифицирования современных датасетов — намного, намного больше. Каждый вес — переменная в . Такое невероятное количество степеней свободы позволяет строить очень сложные отображения, но приносит исследователям головную боль:
- Застревание в локальных минимумах или седловых точках, коих для функции от
переменных может быть очень много.
- Сложный ландшафт целевой функции: плато чередуются с регионами сильной нелинейности. Производная на плато практически равна нулю, а внезапный обрыв, наоборот, может отправить нас слишком далеко.
- Некоторые параметры обновляются значительно реже других, особенно когда в данных встречаются информативные, но редкие признаки, что плохо сказывается на нюансах обобщающего правила сети. С другой стороны, придание слишком большой значимости вообще всем редко встречающимся признакам может привести к переобучению.
- Слишком маленькая скорость обучения заставляет алгоритм сходиться очень долго и застревать в локальных минимумах, слишком большая — «пролетать» узкие глобальные минимумы или вовсе расходиться
Вычислительной математике известны продвинутые алгоритмы второго порядка, которым под силу найти хороший минимум и на сложном ландшафте, но тут удар снова наносит количество весов. Чтобы воспользоваться честным методом второго порядка «в лоб», придётся посчитать гессиан — матрицу производных по каждой паре параметров пары параметров (уже плохо) — а, скажем, для метода Ньютона, ещё и обратную к ней. Приходится изобретать всяческие ухищрения, чтобы справиться с проблемами, оставляя задачу вычислительно подъёмной. Рабочие оптимизаторы второго порядка существуют, но пока что давайте сконцентрируемся на том, что мы можем достигнуть, не рассматривая вторые производные.
Nesterov Accelerated Gradient
Сама по себе идея методов с накоплением импульса до очевидности проста: «Если мы некоторое время движемся в определённом направлении, то, вероятно, нам следует туда двигаться некоторое время и в будущем». Для этого нужно уметь обращаться к недавней истории изменений каждого параметра. Можно хранить последние экземпляров
и на каждом шаге по-честному считать среднее, но такой подход занимает слишком много памяти для больших
. К счастью, нам и не нужно точное среднее, а лишь оценку, поэтому воспользуемся экспоненциальным скользящим средним.
Чтобы накопить что-нибудь, будем умножать уже накопленное значение на коэффициент сохранения и прибавлять очередную величину, умноженную на
. Чем ближе
к единице, тем больше окно накопления и сильнее сглаживание — история
начинает влиять сильнее, чем каждое очередное
. Если
c какого-то момента,
затухают по геометрической прогрессии, экспоненциально, отсюда и название. Применим экспоненциальное бегущее среднее, чтобы накапливать градиент целевой функции нашей сети:
Где обычно берётся порядка
. Обратите внимание, что
не пропало, а включилось в
; иногда можно встретить и вариант формулы с явным множителем. Чем меньше
, тем больше алгоритм ведёт себя как обычный SGD. Чтобы получить популярную физическую интерпретацию уравнений, представьте как шарик катится по холмистой поверхности. Если в момент
под шариком был ненулевой уклон (
), а затем он попал на плато, он всё равно продолжит катиться по этому плато. Более того, шарик продолжит двигаться пару обновлений в ту же сторону, даже если уклон изменился на противоположный. Тем не менее, на шарик действует вязкое трение и каждую секунду он теряет
своей скорости. Вот как выглядит накопленный импульс для разных
(здесь и далее по оси X отложены эпохи, а по Y — значение градиента и накопленные значения):
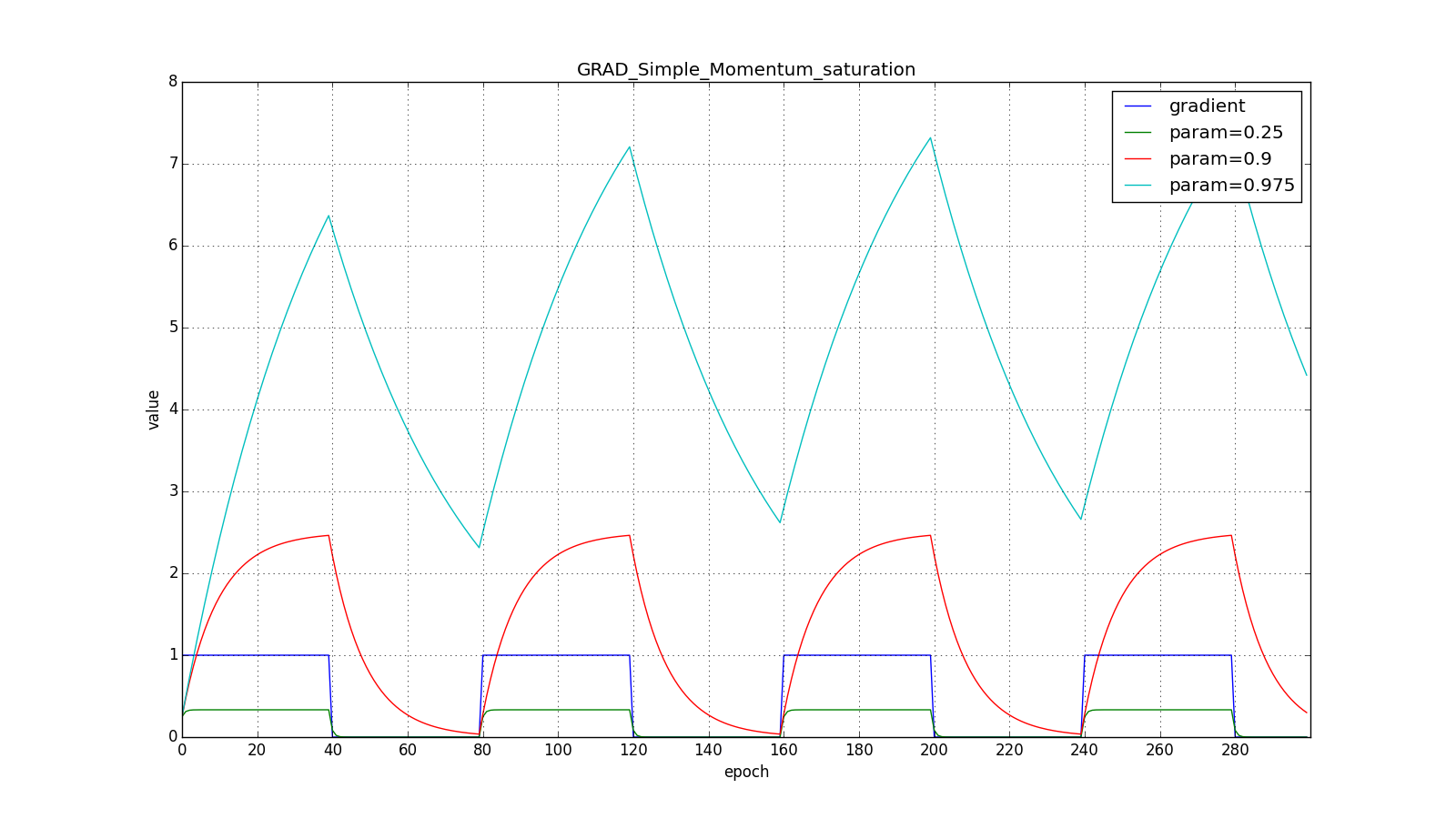
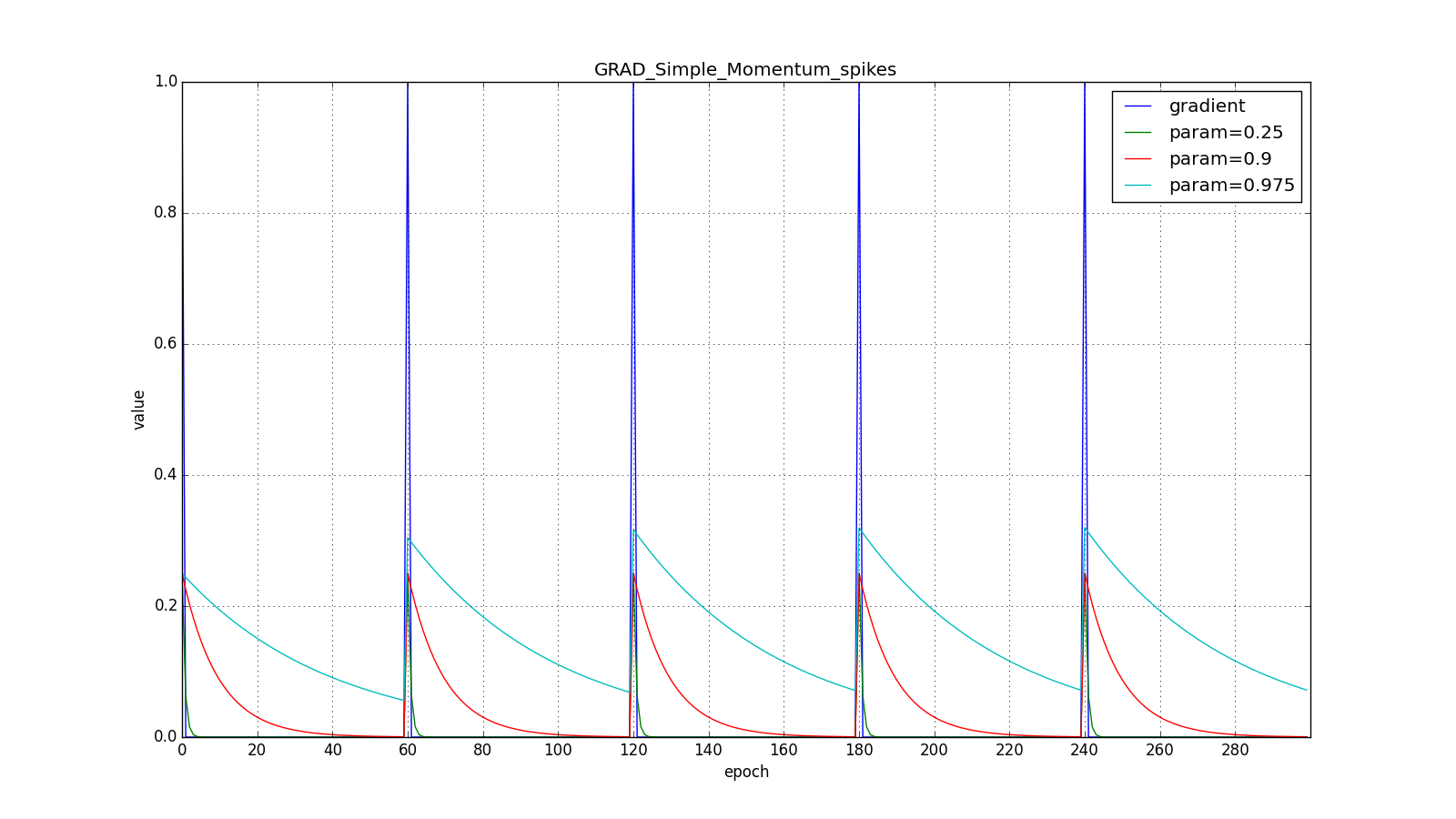
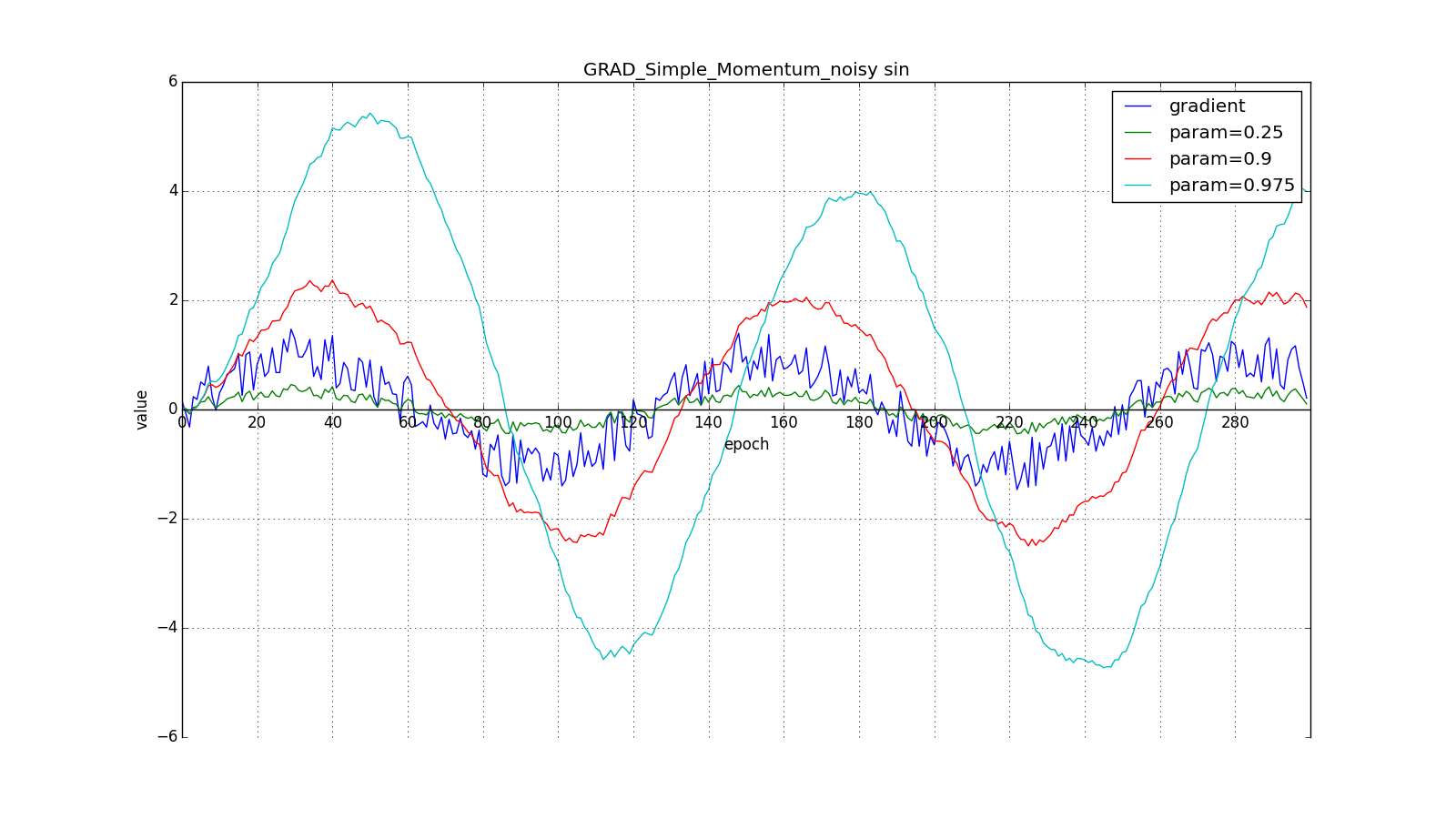
Заметьте, что накопленное в значение может очень сильно превышать значение каждого из
. Простое накопление импульса уже даёт хороший результат, но Нестеров идёт дальше и применяет хорошо известную в вычислительной математике идею: заглядывание вперёд по вектору обновления. Раз уж мы всё равно собираемся сместиться на
, то давайте посчитаем градиент функции потерь не в точке
, а в
. Отсюда:
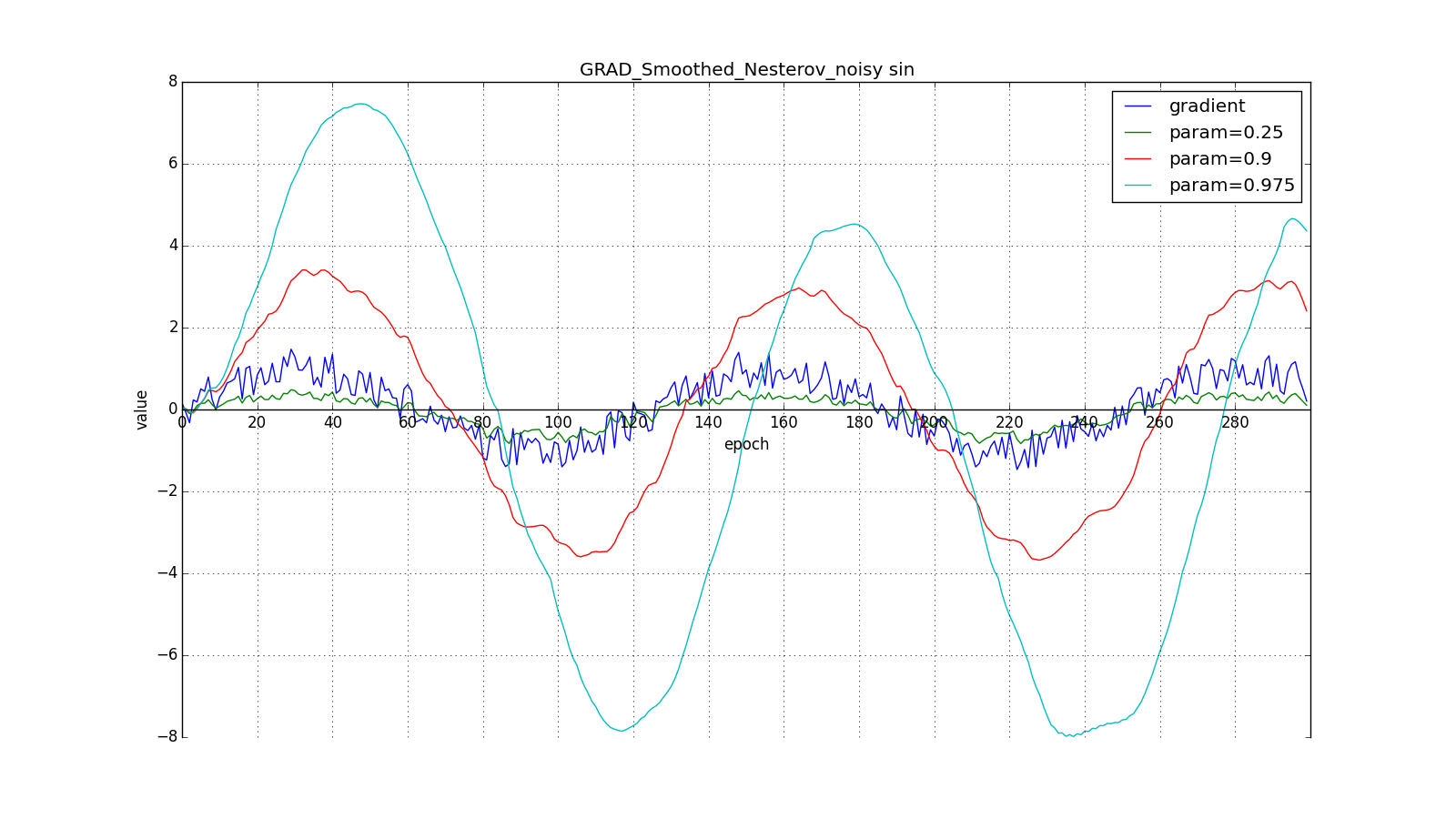
Такое изменение позволяет быстрее «катиться», если в стороне, куда мы направляемся, производная увеличивается, и медленнее, если наоборот. Особенно этого хорошо видно для для графика с синусом.
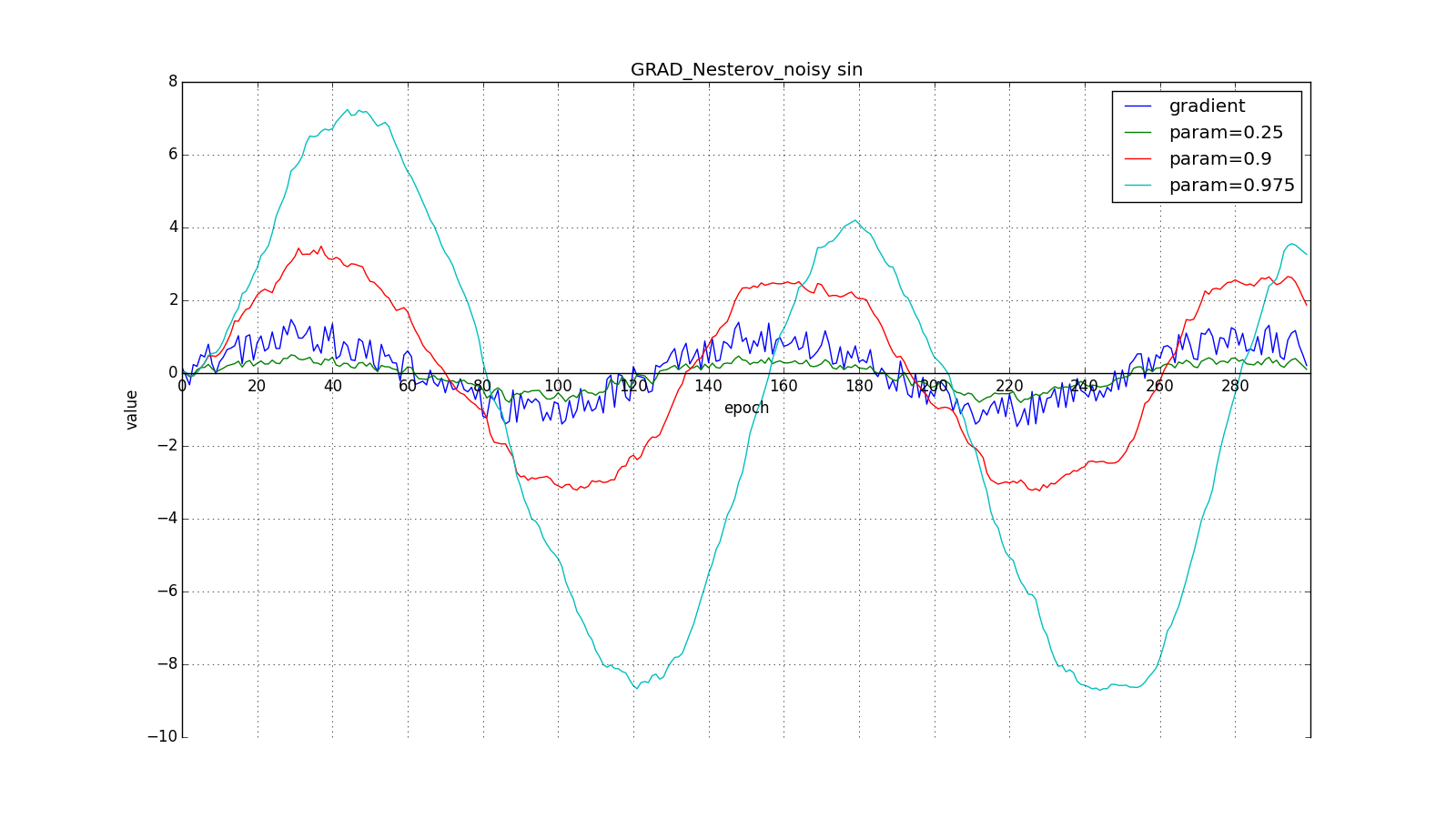
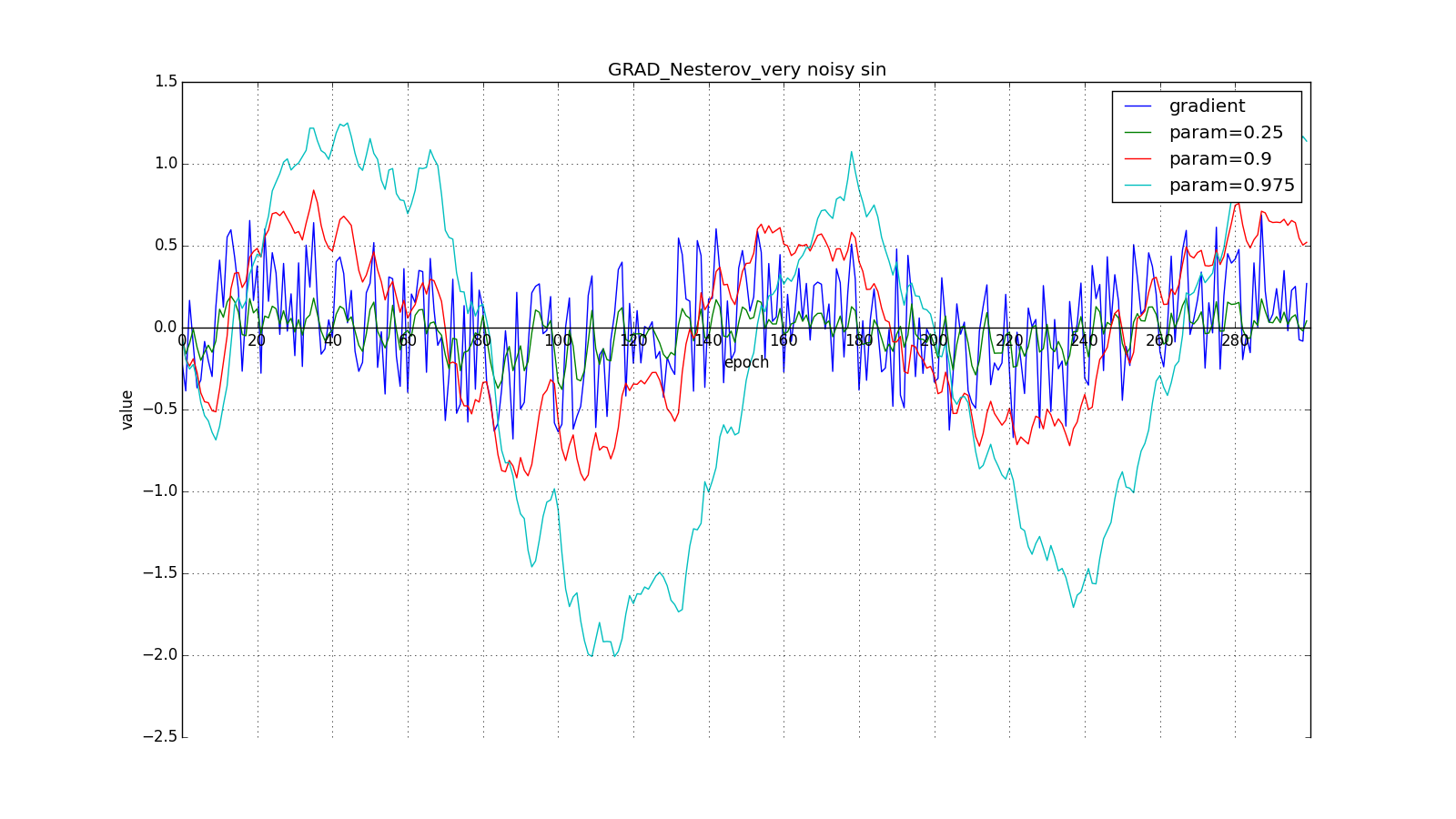
Заглядывание вперёд может сыграть с нами злую шутку, если установлены слишком большие и
: мы заглядываем настолько далеко, что промахиваемся мимо областей с противоположным знаком градиента:

Впрочем, иногда такое поведение может оказаться желательным. Ещё раз обращу ваше внимание на идею — заглядывание вперёд — а не на исполнение. Метод Нестерова (6) — самый очевидный вариант, но не единственный. Например, можно воспользоваться ещё одним приёмом из вычислительной математики — стабилизацией градиента усреднением по нескольким точкам вдоль прямой, по которой мы двигаемся. Скажем, так:
Или так:
Такой приём может помочь в случае шумных целевых функций.
Мы не будем манипулировать аргументом целевой функции в последующих методах (хотя вам, разумеется, никто не мешает поэкспериментировать). Далее для краткости
Adagrad
Как работают методы с накоплением импульса представляют себе многие. Перейдём же к более интересным алгоритмам оптимизации. Начём со сравнительно простого Adagrad — adaptive gradient.
Некоторые признаки могут быть крайне информативными, но встречаться редко. Экзотическая высокооплачиваемая профессия, причудливое слово в спам-базе — они запросто потонут в шуме всех остальных обновлений. Речь идёт не только о редко встречающихся входных параметрах. Скажем, вам вполне могут встретиться редкие графические узоры, которые и в признак-то превращаются только после прохождения через несколько слоёв свёрточной сети. Хорошо бы уметь обновлять параметры с оглядкой на то, насколько типичный признак они фиксируют. Достичь этого несложно: давайте будем хранить для каждого параметра сети сумму квадратов его обновлений. Она будет выступать в качестве прокси для типичности: если параметр принадлежит цепочке часто активирующихся нейронов, его постоянно дёргают туда-сюда, а значит сумма быстро накапливается. Перепишем формулу обновления вот так:
Где — сумма квадратов обновлений, а
— сглаживающий параметр, необходимый, чтобы избежать деления на 0. У часто обновлявшегося в прошлом параметра большая
, значит большой знаменатель в (12). Параметр изменившийся всего раз или два обновится в полную силу.
берут порядка
или
для совсем агрессивного обновления, но, как видно из графиков, это играет роль только в начале, ближе к середине обучение начинает перевешивать
:
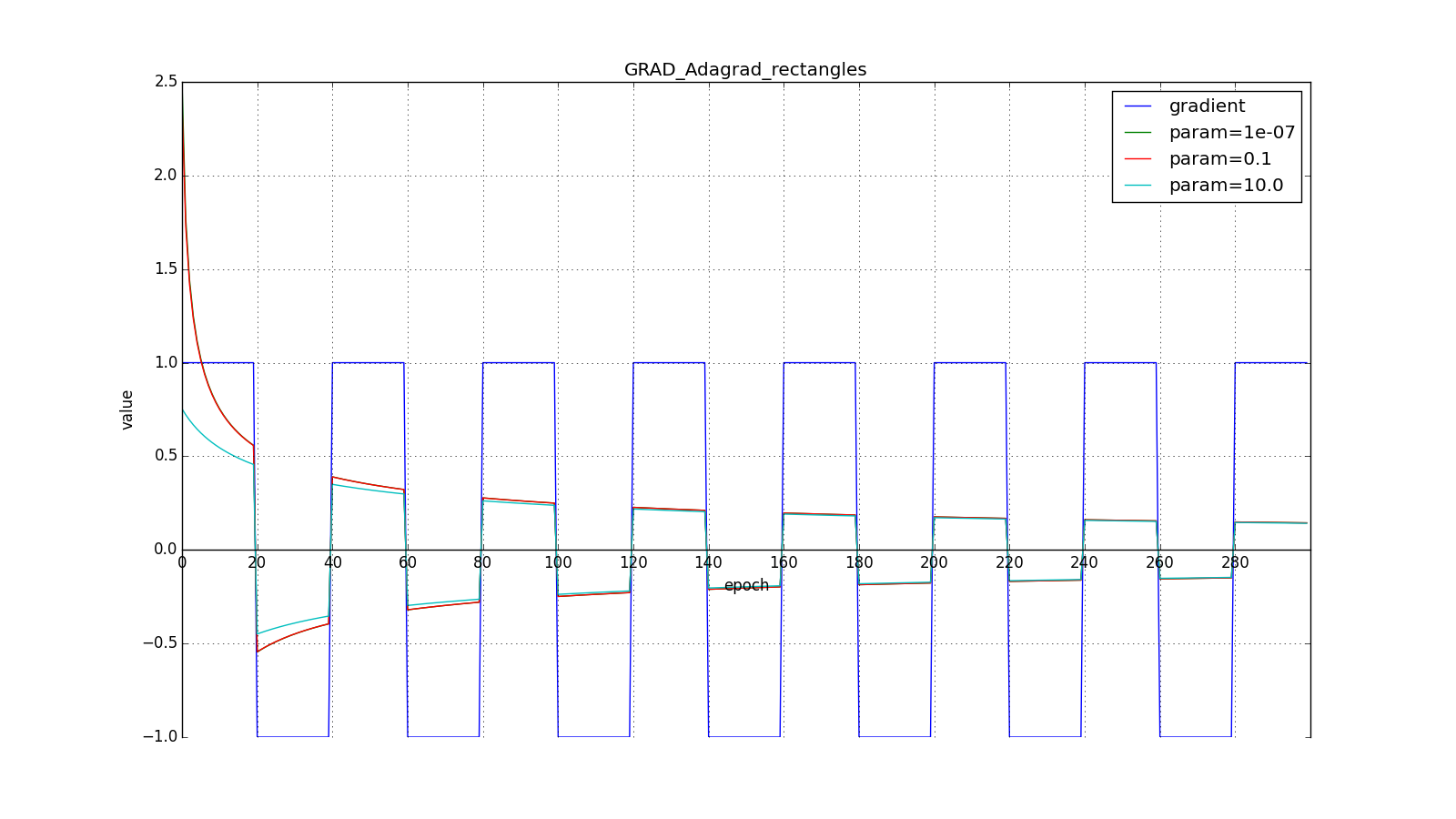
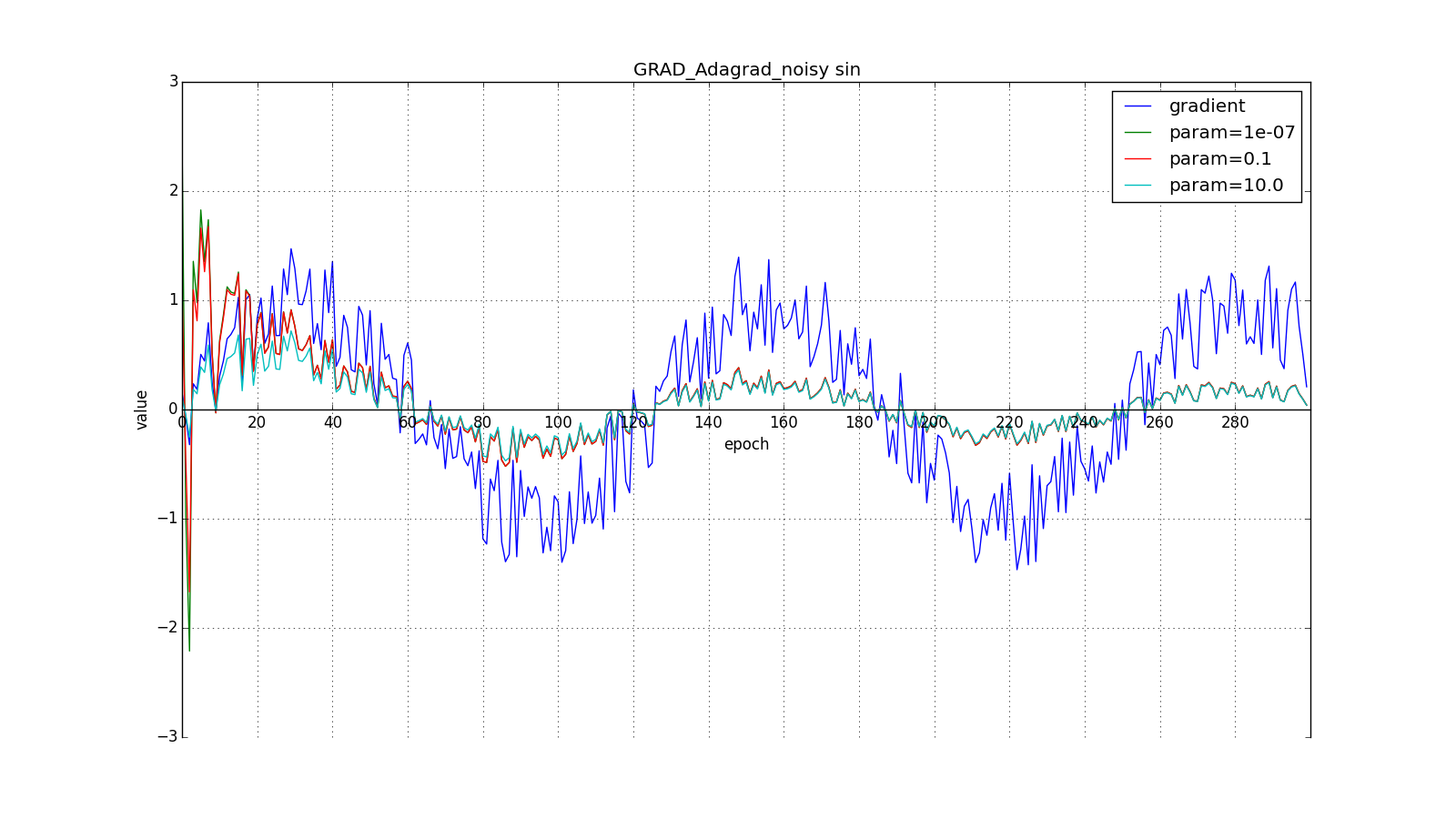
Итак, идея Adagrad в том, чтобы использовать что-нибудь, что бы уменьшало обновления для элементов, которые мы и так часто обновляем. Никто нас не заставляет использовать конкретно эту формулу, поэтому Adagrad иногда называют семейством алгоритмов. Скажем, мы можем убрать корень или накапливать не квадраты обновлений, а их модули, или вовсе заменить множитель на что-нибудь вроде .
(Другое дело, что это требует экспериментов. Если убрать корень, обновления начнут уменьшаться слишком быстро, и алгоритм ухудшится)
Ещё одно достоинство Adagrad — отсутствие необходимости точно подбирать скорость обучения. Достаточно выставить её в меру большой, чтобы обеспечить хороший запас, но не такой громадной, чтобы алгроритм расходился. По сути мы автоматически получаем затухание скорости обучения (learning rate decay).
RMSProp и Adadelta
Недостаток Adagrad в том, что в (12) может увеличиваться сколько угодно, что через некоторое время приводит к слишком маленьким обновлениям и параличу алгоритма. RMSProp и Adadelta призваны исправить этот недостаток.
Модифицируем идею Adagrad: мы всё так же собираемся обновлять меньше веса, которые слишком часто обновляются, но вместо полной суммы обновлений, будем использовать усреднённый по истории квадрат градиента. Снова используем экспоненциально затухающее бегущее среднее
(4). Пусть — бегущее среднее в момент
тогда вместо (12) получим
Знаменатель есть корень из среднего квадратов градиентов, отсюда RMSProp — root mean square propagation
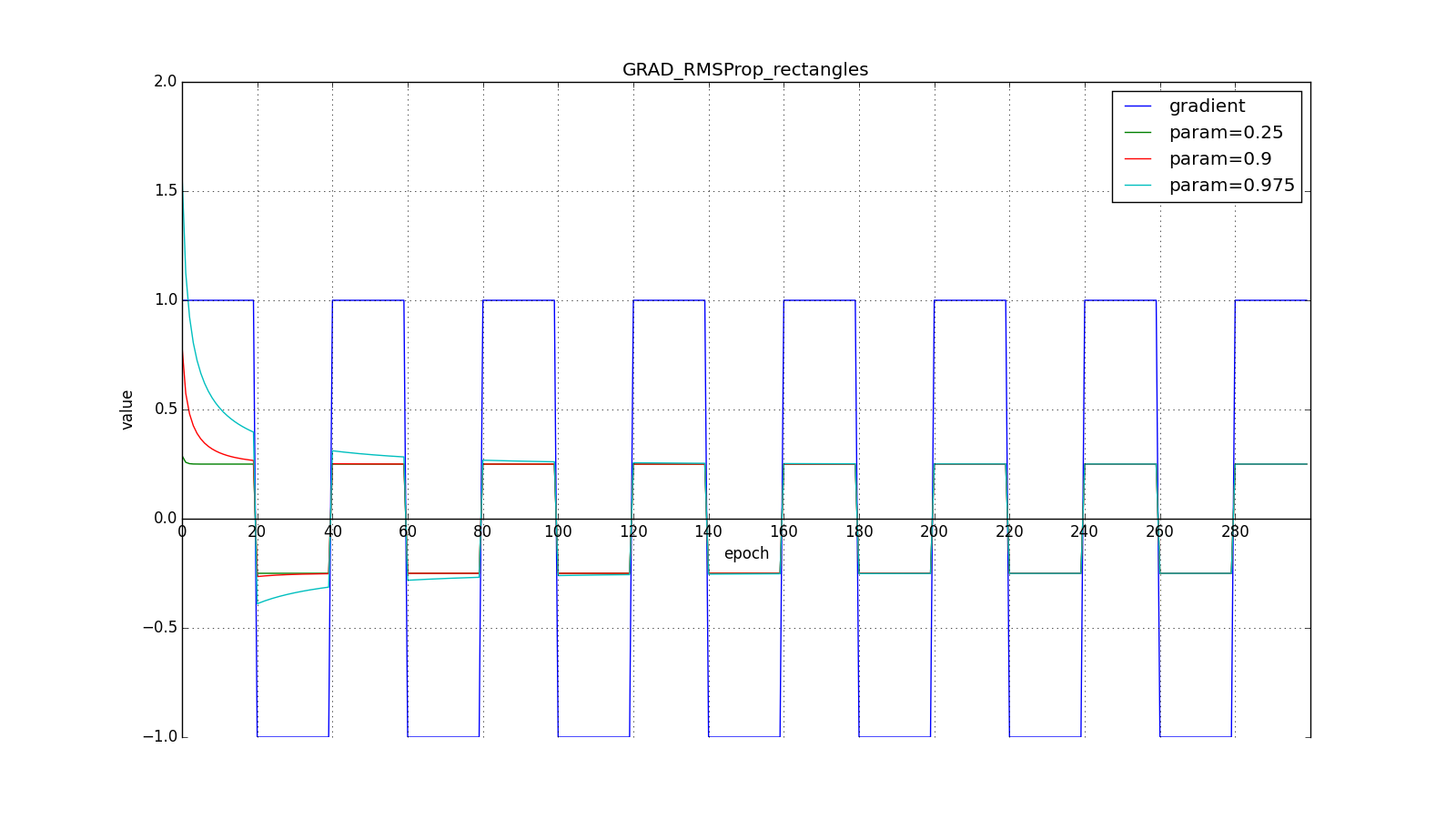
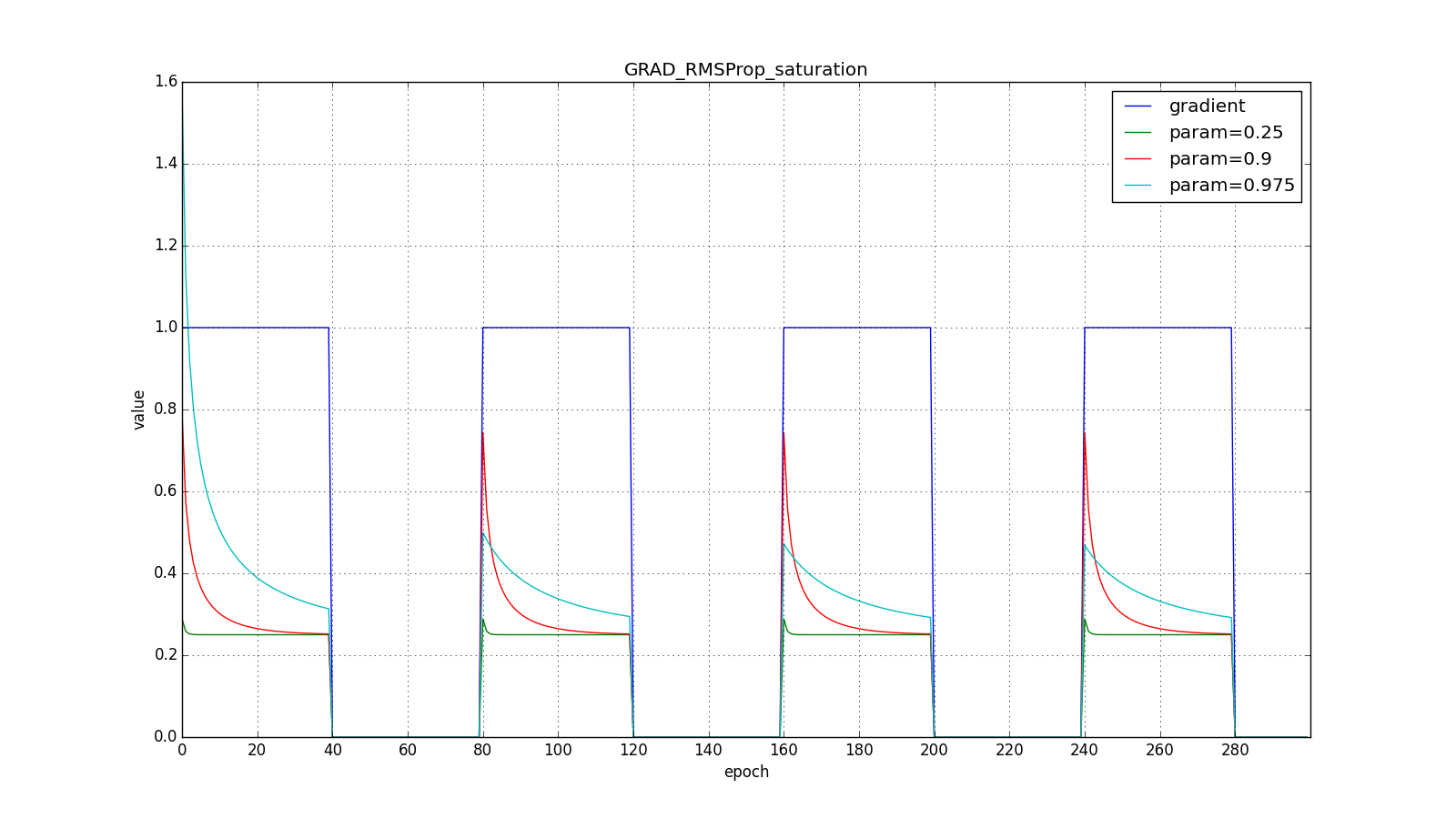

Обратите внимание, как восстанавливается скорость обновления на графике с длинными зубцами для разных . Также сравните графики с меандром для Adagrad и RMSProp: в первом случае обновления уменьшаются до нуля, а во втором — выходят на определённый уровень.
Вот и весь RMSProp. Adadelta от него отличается тем, что мы добавляем в числитель (14) стабилизирующий член пропорциональный от
. На шаге
мы ещё не знаем значение
, поэтому обновление параметров происходит в три этапа, а не в два: сначала накапливаем квадрат градиента, затем обновляем
, после чего обновляем
.
Такое изменение сделано из соображений, что размерности и
должны совпадать. Заметьте, что learning rate не имеет размерности, а значит во всех алгоритмах до этого мы складывали размерную величину с безразмерной. Физики в этом месте ужаснутся, а мы пожмём плечами: работает же.
Заметим, что нам нужен ненулевой для первого шага, иначе все последующие
, а значит и
будут равны нулю. Но эту проблему мы решили ещё раньше, добавив в
. Другое дело, что без явного большого
мы получим поведение, противоположное Adagrad и RMSProp: мы будем сильнее (до некоторого предела) обновлять веса, которые используются чаще. Ведь теперь чтобы
стал значимым, параметр должен накопить большую сумму в числителе дроби.
Вот графики для нулевого начального :

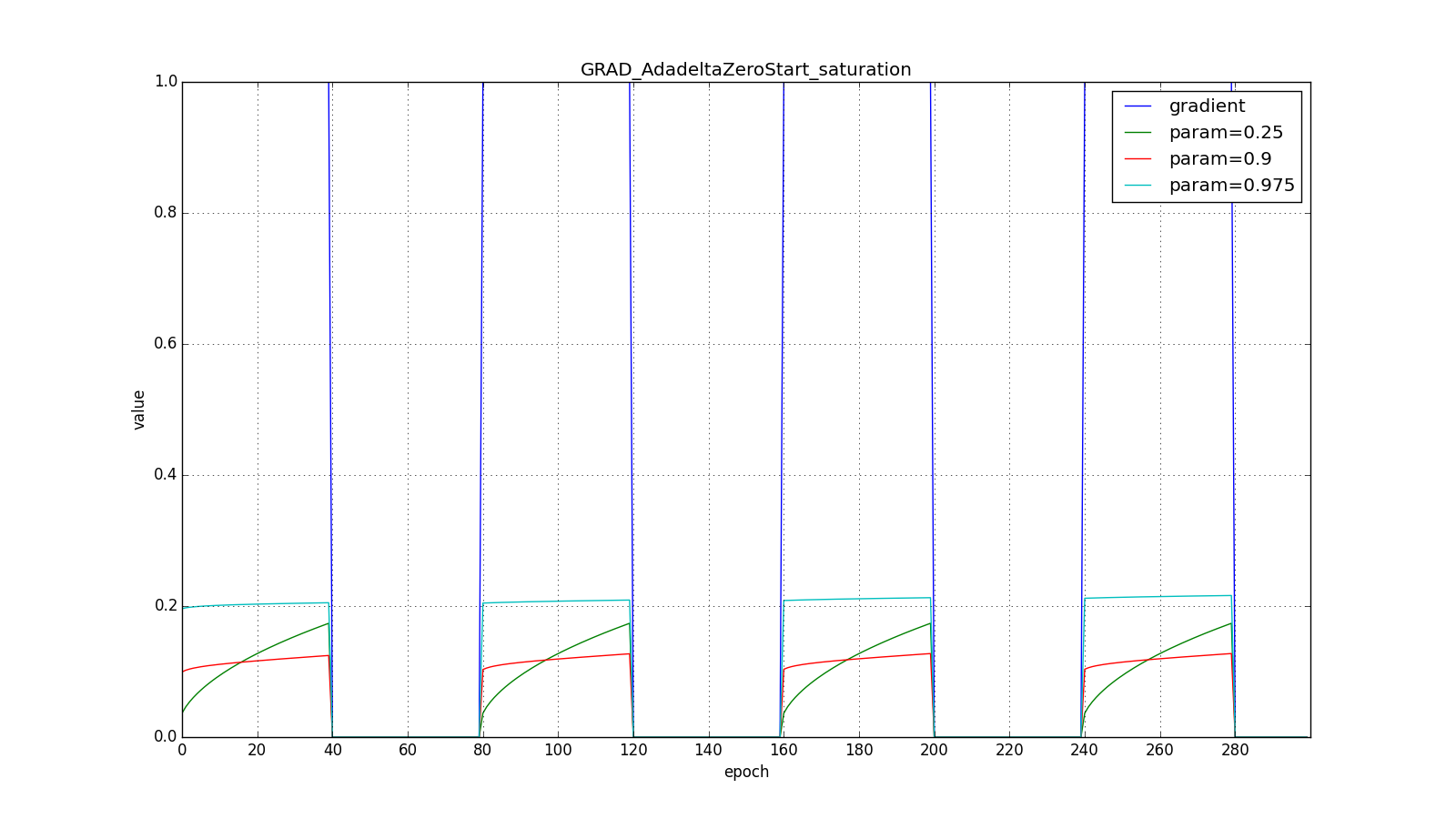
А вот для большого:
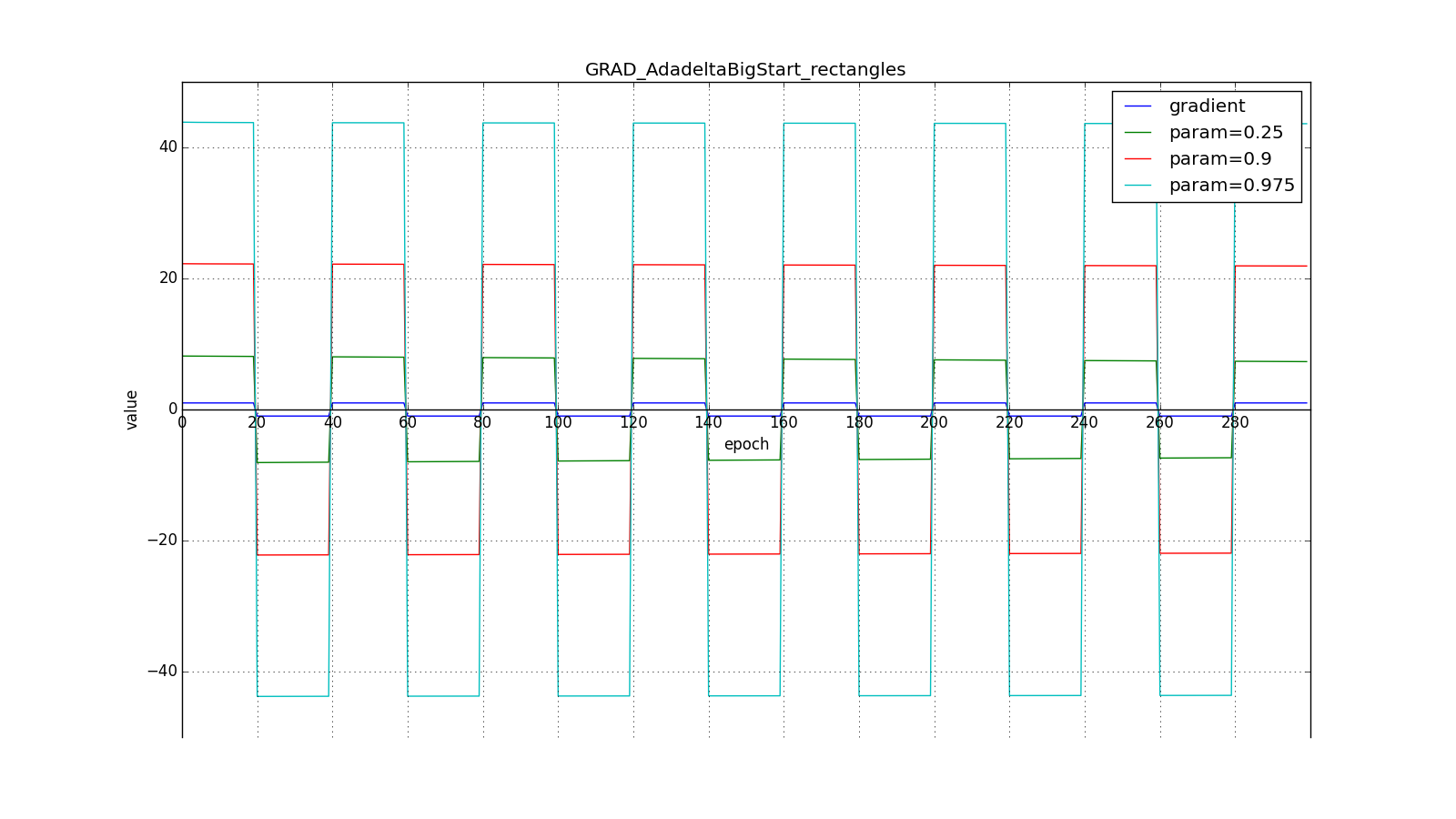
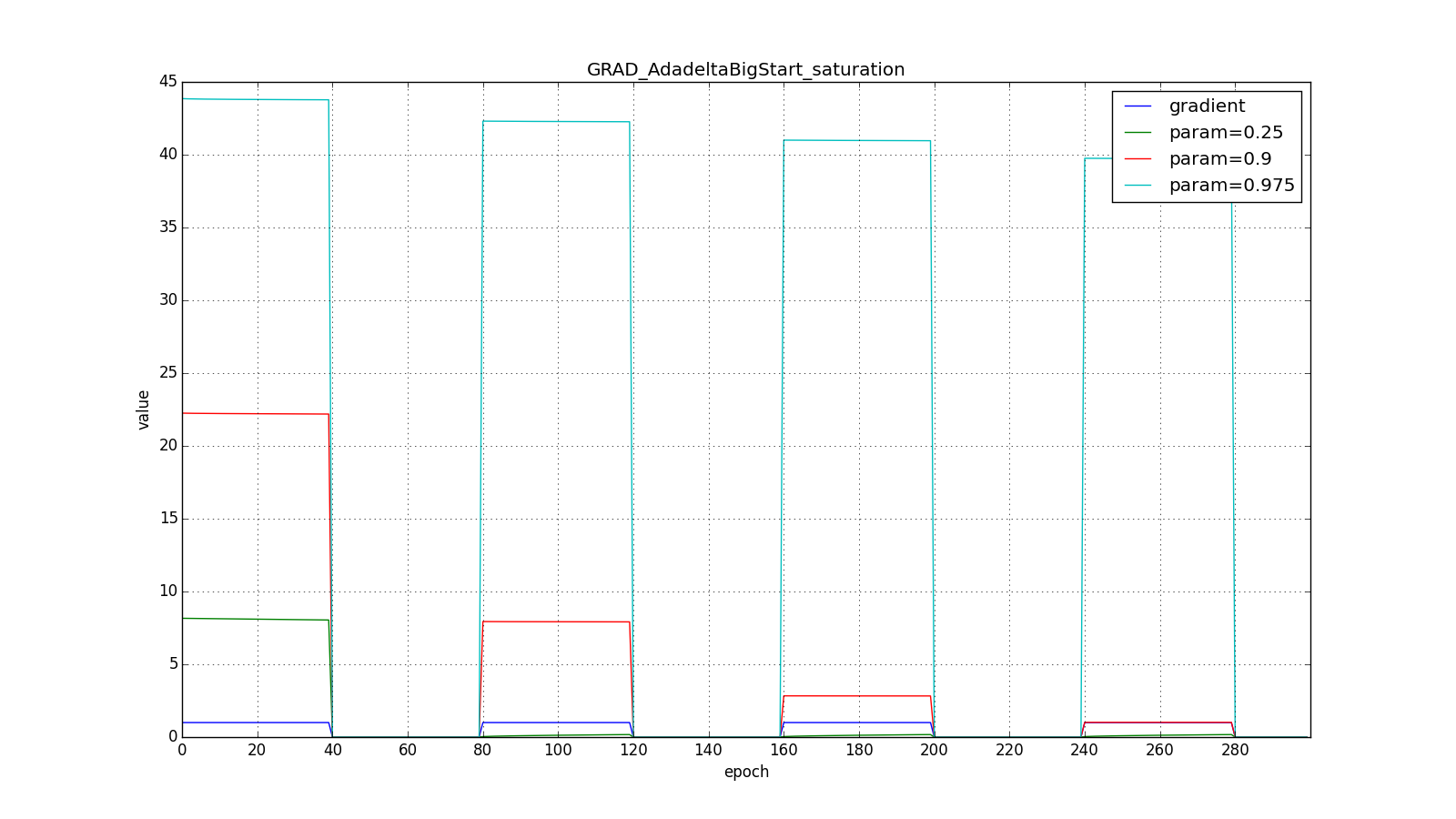
Впрочем, похоже, авторы алгоритма и добивались такого эффекта. Для RMSProp и Adadelta, как и для Adagrad не нужно очень точно подбирать скорость обучения — достаточно прикидочного значения. Обычно советуют начать подгон c
, a
так и оставить
. Чем ближе
к
, тем дольше RMSProp и Adadelta с большим
будут сильно обновлять мало используемые веса. Если же
и
, то Adadelta будет долго «с недоверием» относиться к редко используемым весам. Последнее может привести к параличу алгоритма, а может вызвать намеренно «жадное» поведение, когда алгоритм сначала обновляет нейроны, кодирующие самые лучшие признаки.
Adam
Adam — adaptive moment estimation, ещё один оптимизационный алгоритм. Он сочетает в себе и идею накопления движения и идею более слабого обновления весов для типичных признаков. Снова вспомним (4):
От Нестерова Adam отличается тем, что мы накапливаем не , а значения градиента, хотя это чисто косметическое изменение, см. (23). Кроме того, мы хотим знать, как часто градиент изменяется. Авторы алгоритма предложили для этого оценивать ещё и среднюю нецентрированную дисперсию:
Легко заметить, что это уже знакомый нам , так что по сути тут нет отличий от RMSProp.
Важное отличие состоит в начальной калибровке и
: они страдают от той же проблемы, что и
в RMSProp: если задать нулевое начальное значение, то они будут долго накапливаться, особенно при большом окне накопления (
,
), а какие-то изначальные значения — это ещё два гиперпараметра. Никто не хочет ещё два гиперпараметра, так что мы искусственно увеличиваем
и
на первых шагах (примерно
для
и
для
)
В итоге, правило обновления:
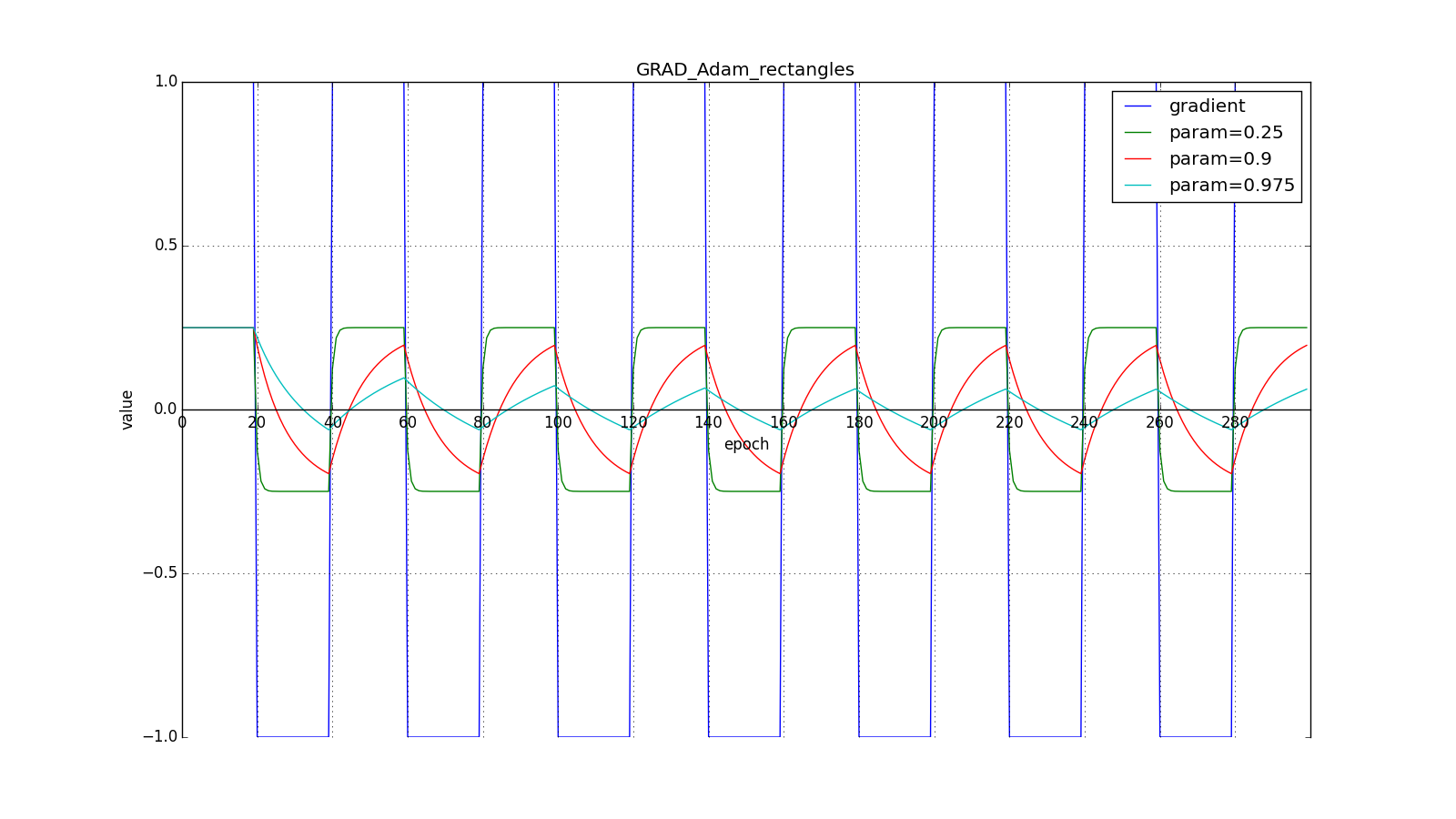
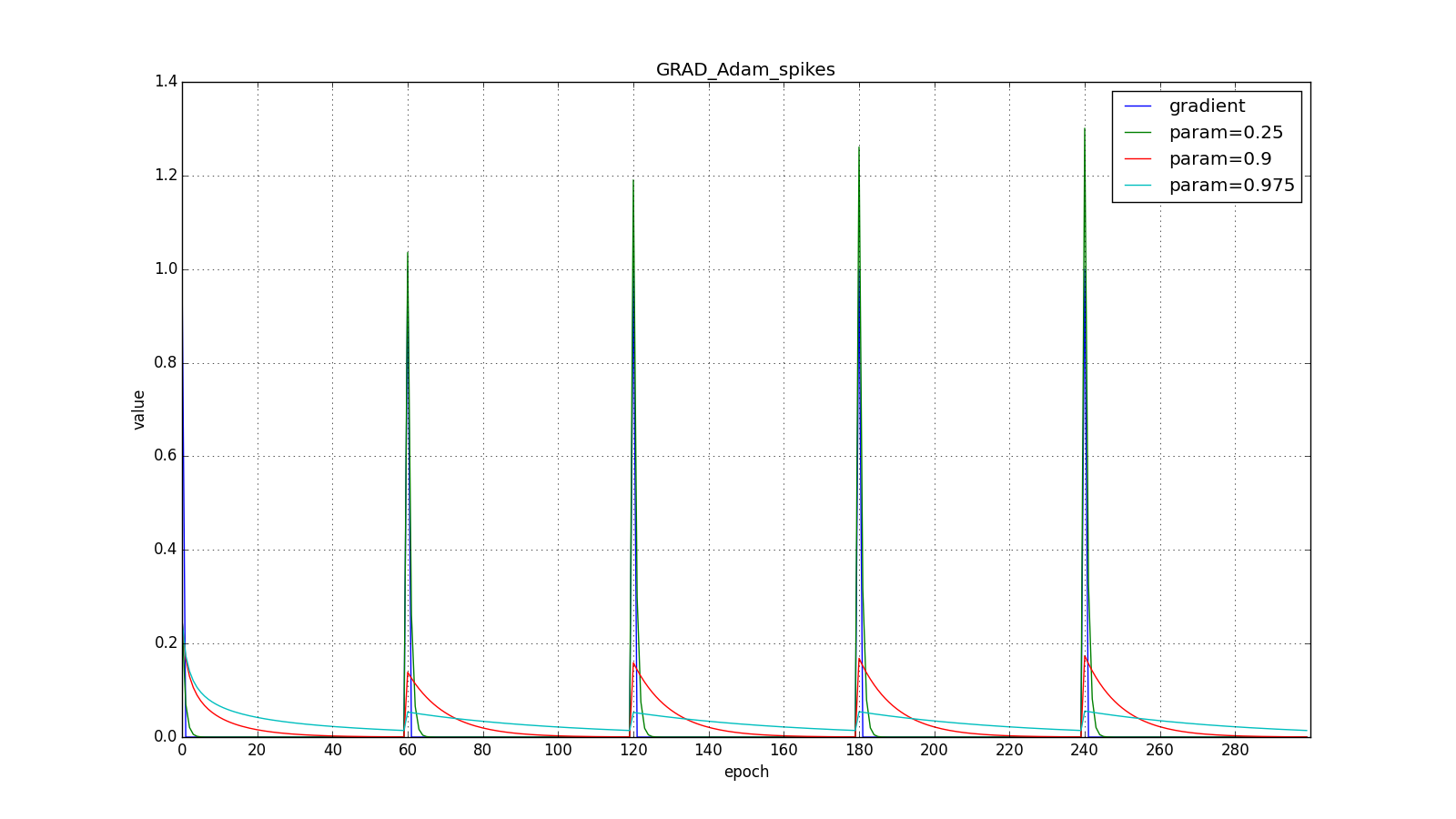
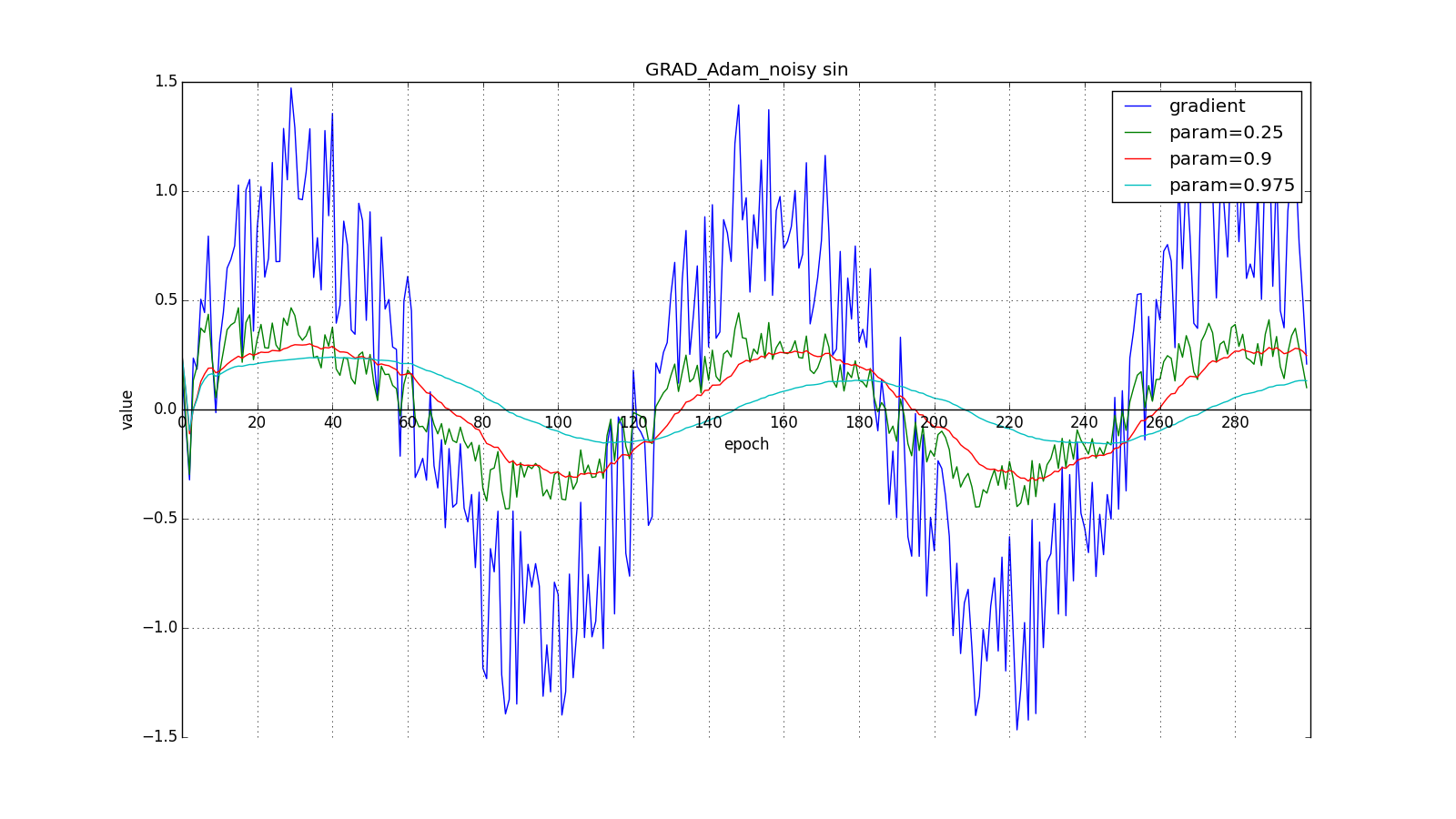
Здесь следует внимательно посмотреть на то, как быстро синхронизировались значения обновлений на первых зубцах графиков с прямоугольниками и на гладкость кривой обновлений на графике с синусом — её мы получили «бесплатно». При рекомендуемом параметре на графике с шипами видно, что резкие всплески градиента не вызывает мгновенного отклика в накопленном значении, поэтому хорошо настроенному Adam не нужен gradient clipping.
Авторы алгоритма выводят (22), разворачивая рекурсивные формулы (20) и (21). Например, для :
Слагаемое близко к
при стационарном распределении
, что неправда в практически интересующих нас случаях. но мы всё равно переносим скобку с
влево. Неформально, можно представить что при
у нас бесконечная история одинаковых обновлений:
Когда же мы получаем более близкое к правильному значение , мы заставляем «виртуальную» часть ряда затухать быстрее:
Авторы Adam предлагают в качестве значений по умолчанию и утверждают, что алгоритм выступает лучше или примерно так же, как и все предыдущие алгоритмы на широком наборе датасетов за счёт начальной калибровки. Заметьте, что опять-таки, уравнения (22) не высечены в камне. У нас есть некоторое теоретическое обоснование, почему затухание должно выглядеть именно так, но никто не запрещает поэкспериментировать с формулами калибровки. На мой взгляд, здесь просто напрашивается применить заглядывание вперёд, как в методе Нестерова.
Adamax
Adamax как раз и есть такой эксперимент, предложенный в той же статье. Вместо дисперсии в (21) можно считать инерционный момент распределения градиентов произвольной степени . Это может привести к нестабильности к вычислениям. Однако случай
, стремящейся к бесконечности, работает на удивление хорошо.
Заметьте, что вместо используется подходящий по размерности
. Кроме того, обратите внимание, чтобы использовать в формулах Adam значение, полученное в (27), требуется извлечь из него корень:
. Выведем решающее правило взамен (21), взяв
, развернув под корнем
при помощи (27):
Так получилось потому что при в сумме в (28) будет доминировать наибольший член. Неформально, можно интуитивно понять, почему так происходит, взяв простую сумму и большую
:
. Совсем не страшно.
Остальные шаги алгоритма такие же как и в Adam.
Эксперименты
Теперь давайте посмотрим на разные алгоритмы в деле. Чтобы было нагляднее, посмотрим на траекторию алгоритмов в задаче нахождения минимума функции двух переменных. Напомню, что обучение нейронной сети — это по сути то же самое, но переменных там значительно больше двух и вместо явно заданной функции у нас есть только набор точек, по котором мы хотим эту функцию построить. В нашем же случае функция потерь и есть целевая функция, по которой двигаются оптимизаторы. Конечно, на такой простой задаче невозможно почувствовать всю силу продвинутых алгоритмов, зато интуитивно понятно.
Для начала посмотрим на ускоренный градиент Нестерова с разными значениями . Поняв, почему выглядят именно так, проще понять и поведение всех остальных алгоритмов с накоплением импульса, включая Adam и Adamax.

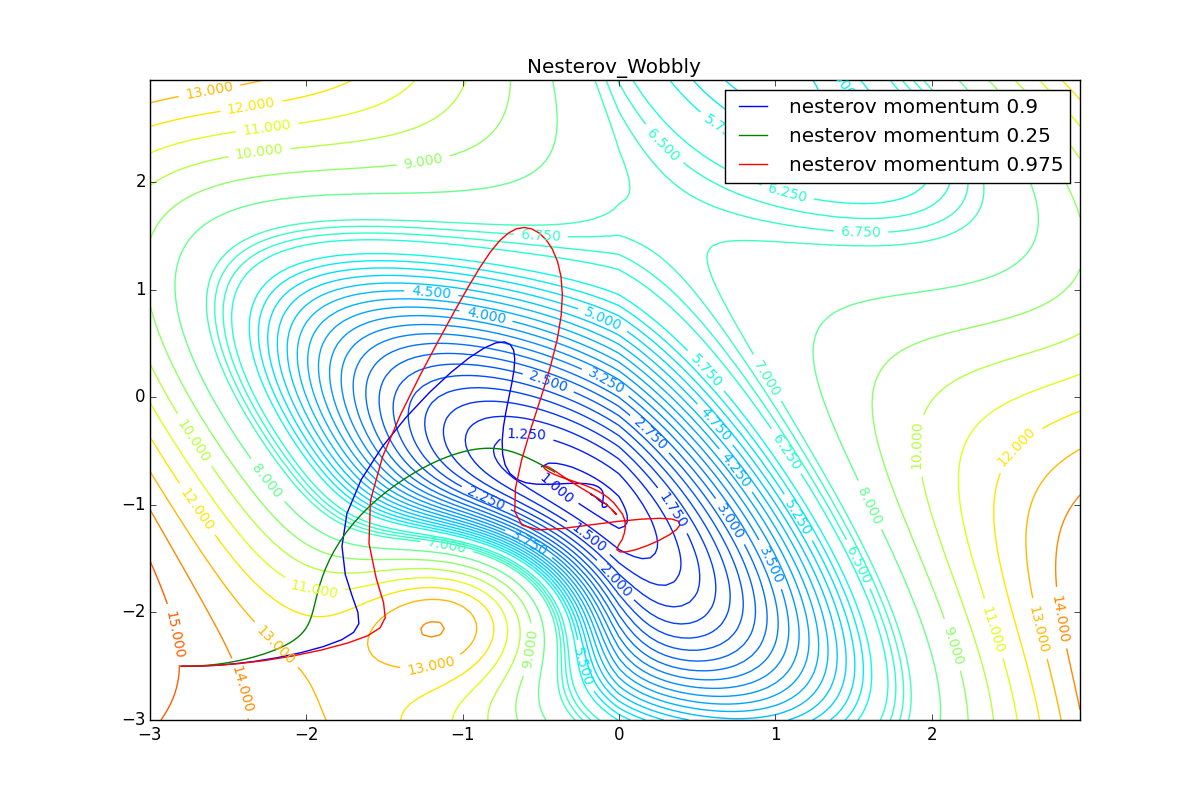
Все траектории оканчиваются в одном и том же бассейне, но делают они это по-разному. С маленьким алгоритм становится похож на обычный SGD, на каждом шаге спуск идёт в сторону убывающего градиента. Со слишком большим
, начинает сильно влиять предыстория изменений, и траектория может сильно «гулять». Иногда это хорошо: чем больше накопленный импульс, тем проще вырваться из впадин локальных минимумов на пути.
Иногда плохо: можно запросто растерять импульс, проскочив впадину глобального минимума и осесть в локальном. Поэтому при больших можно иногда увидеть, как потери на тренировочной выборке сначала достигают глобальный минимум, затем сильно возрастают, потом снова начинают опускаться, но так и не возвращаются в прошедший минимум.
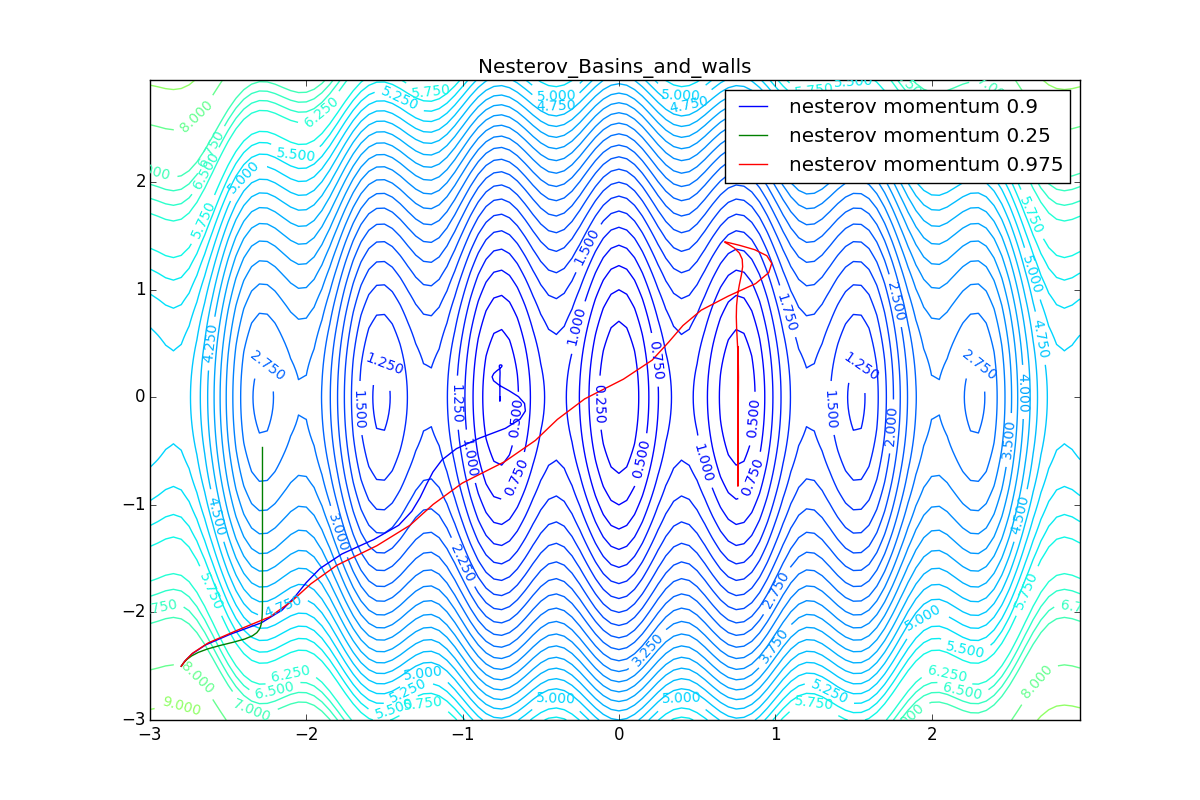
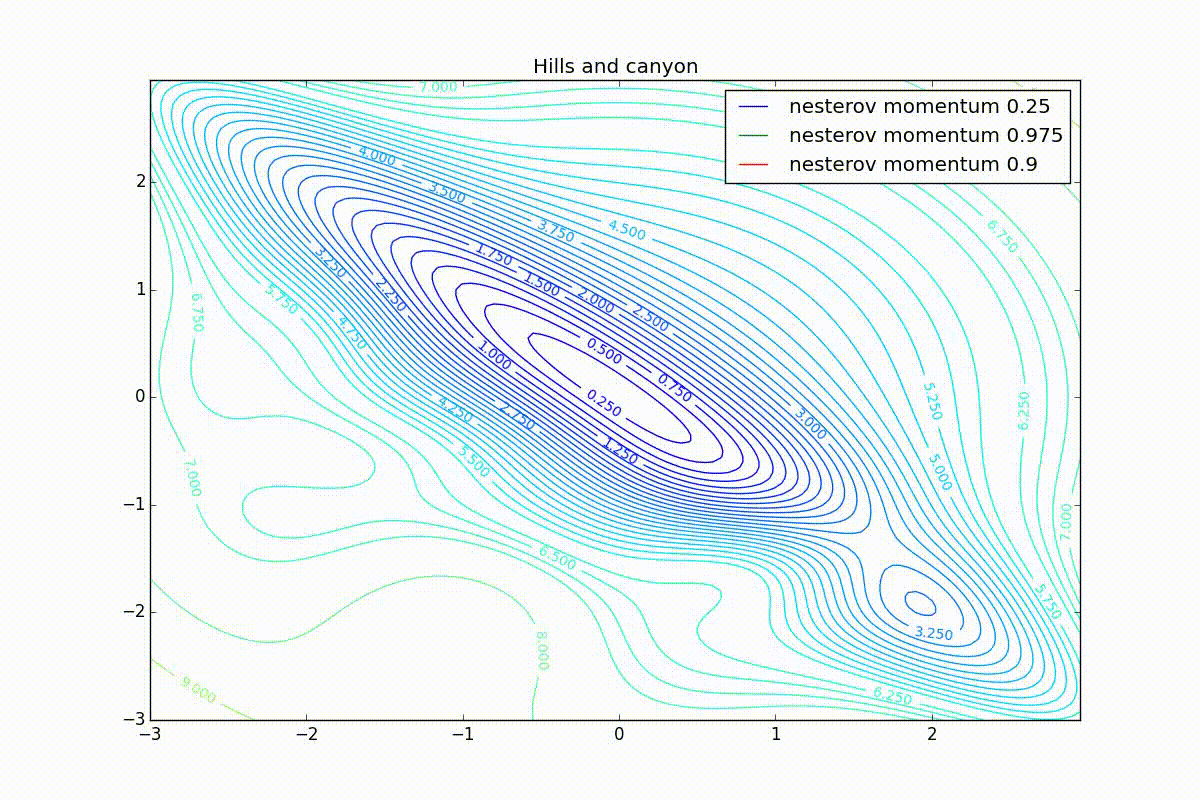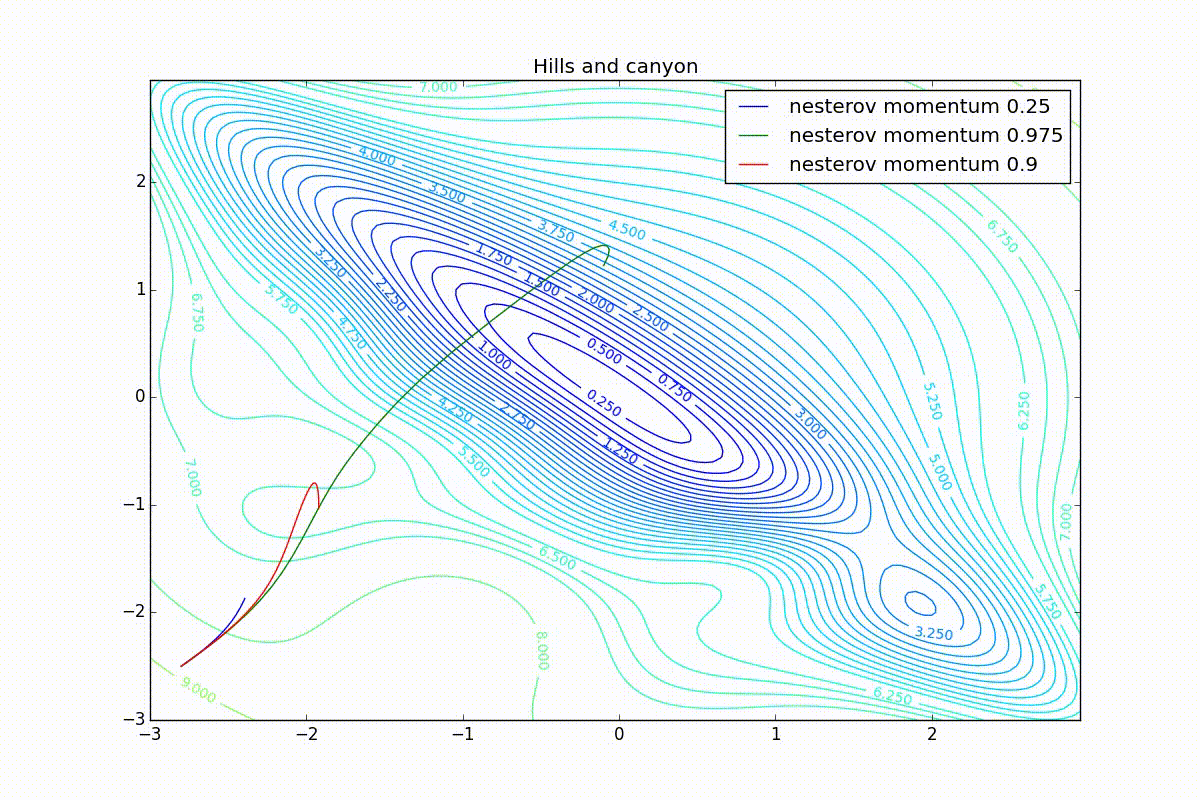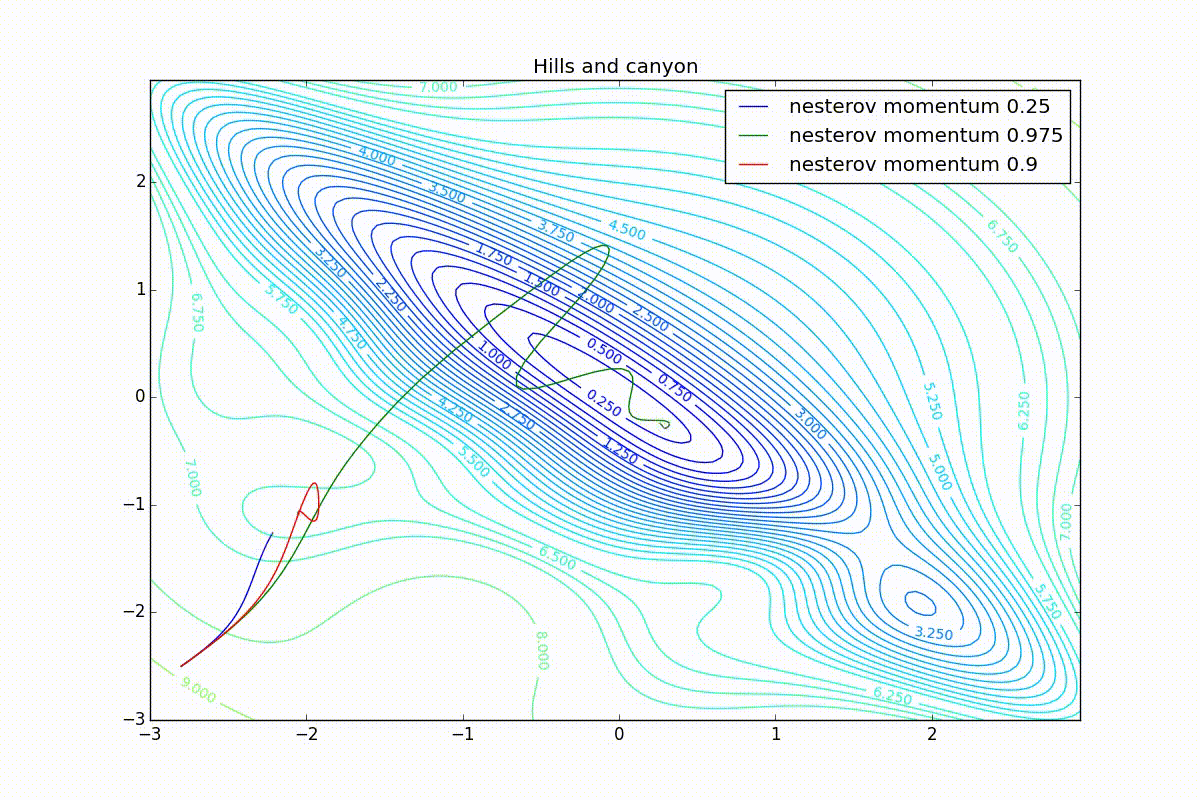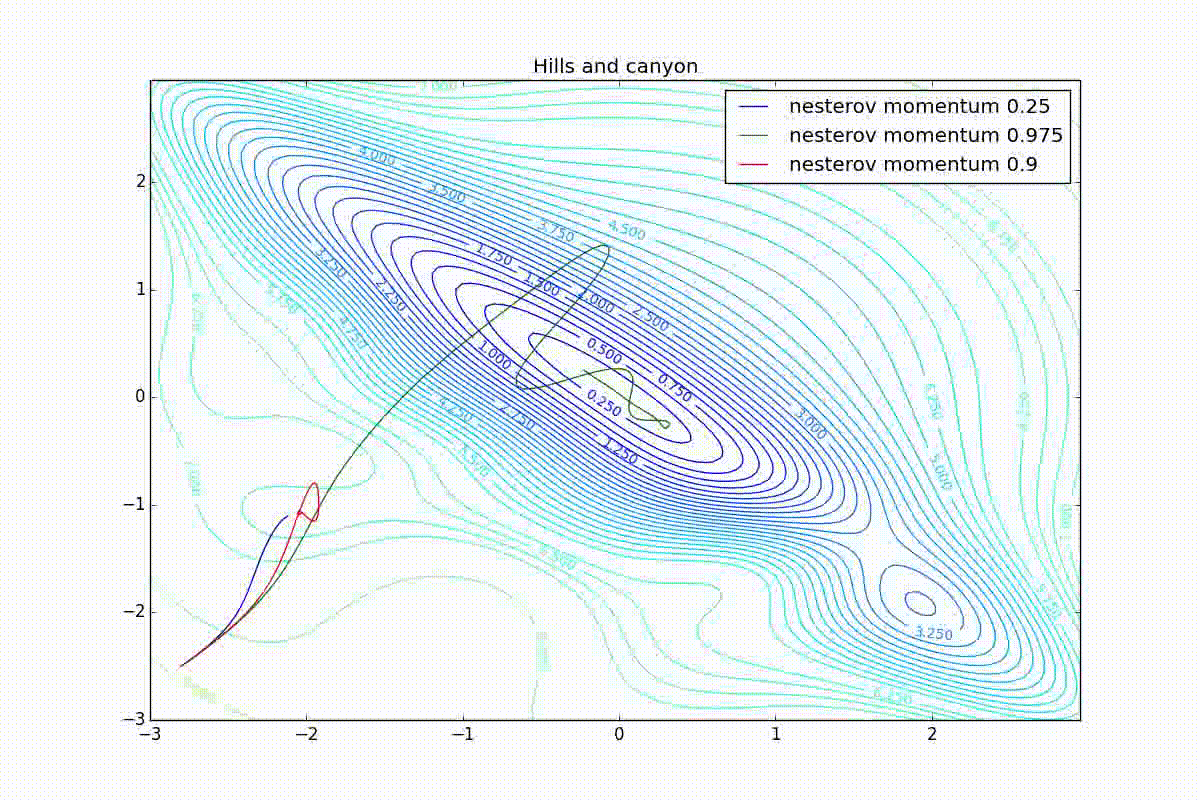
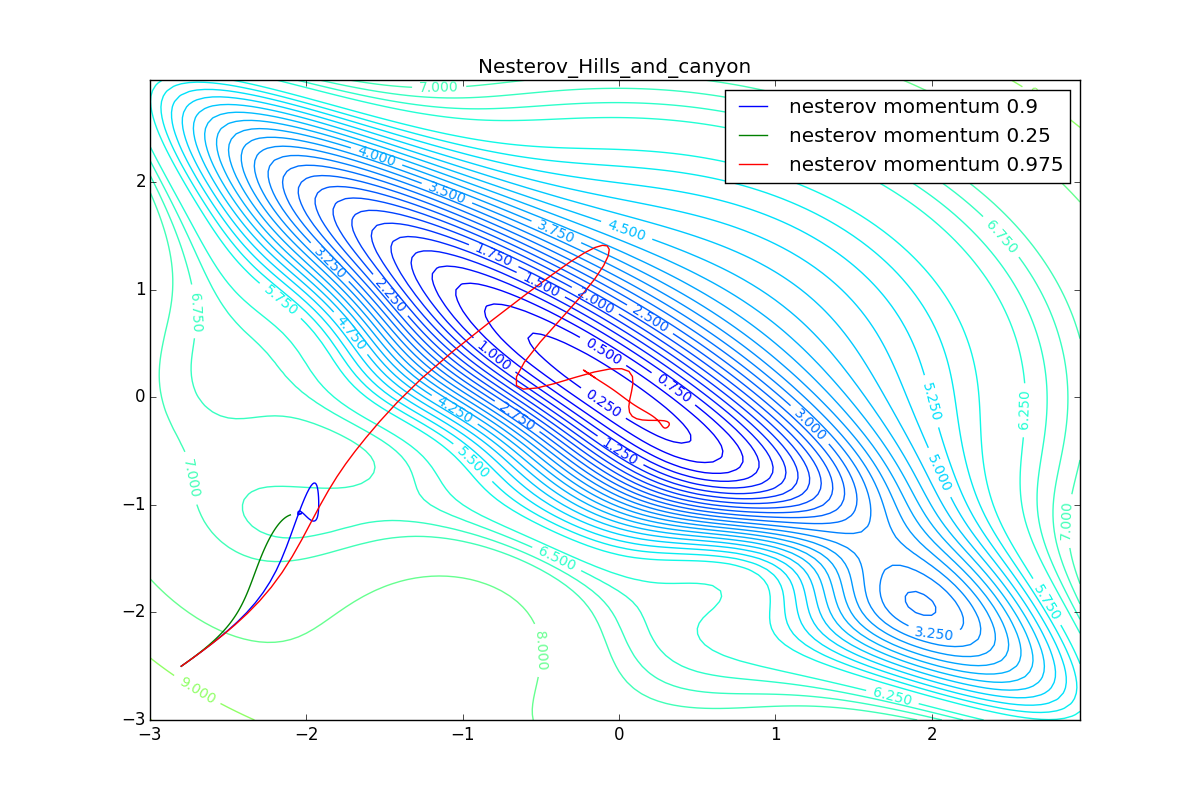
Теперь рассмотрим разные алгоритмы, запущенные из одной точки.
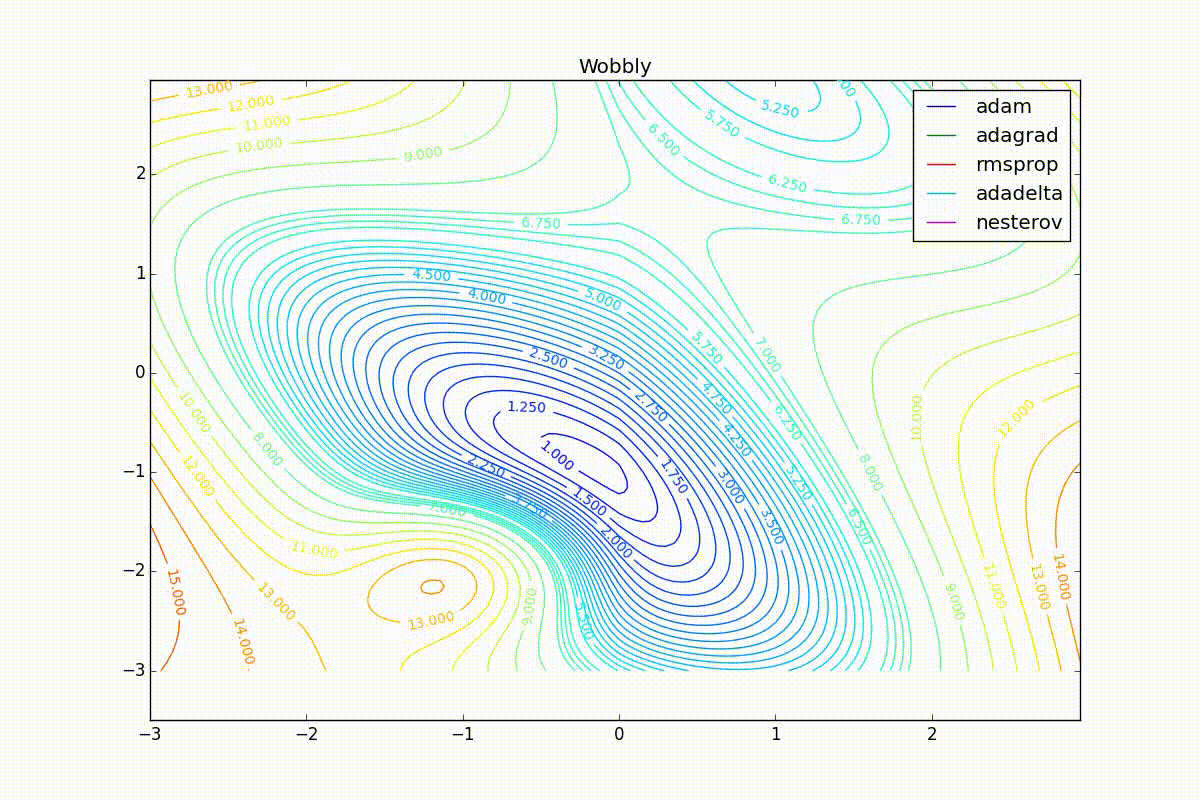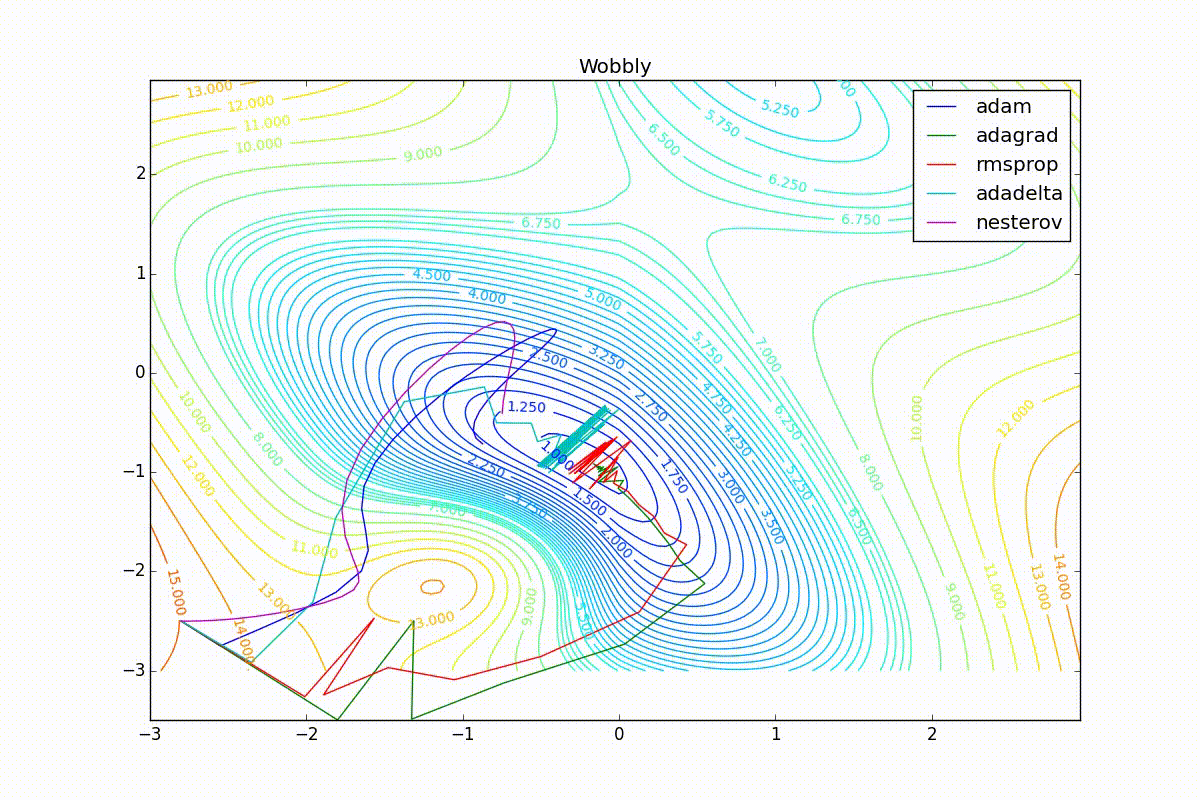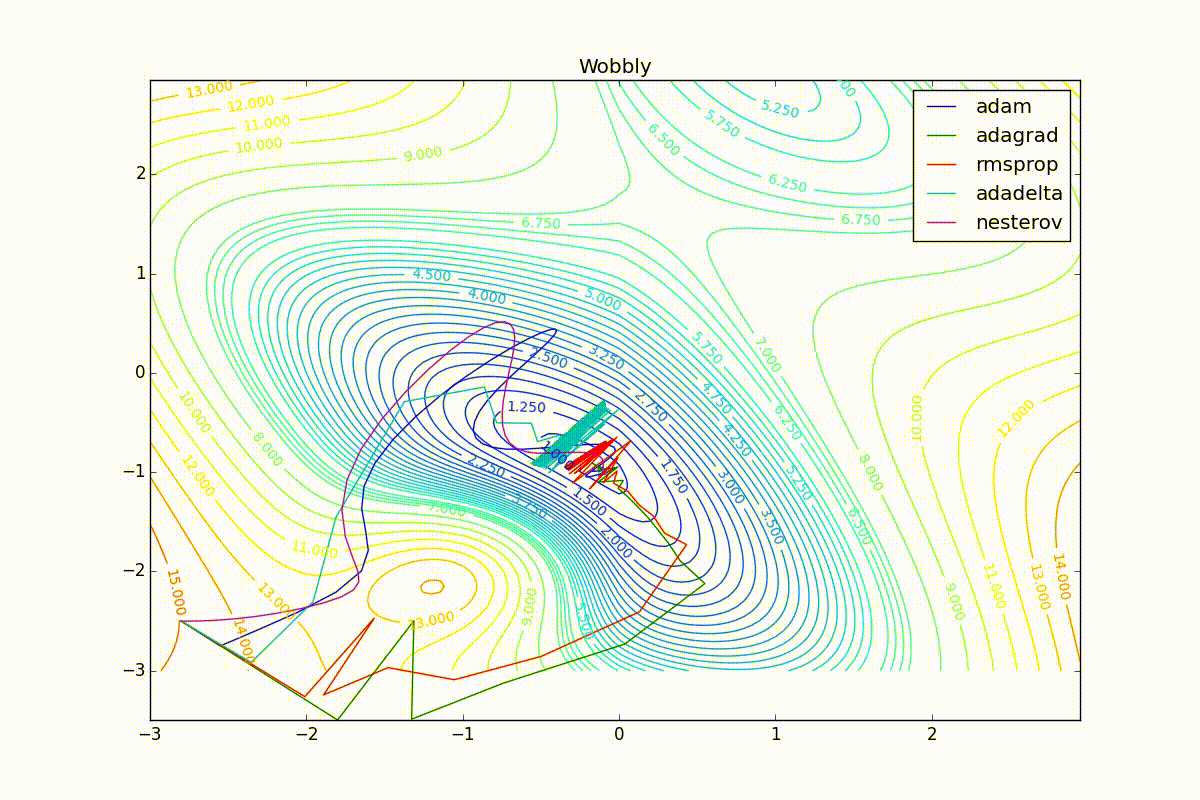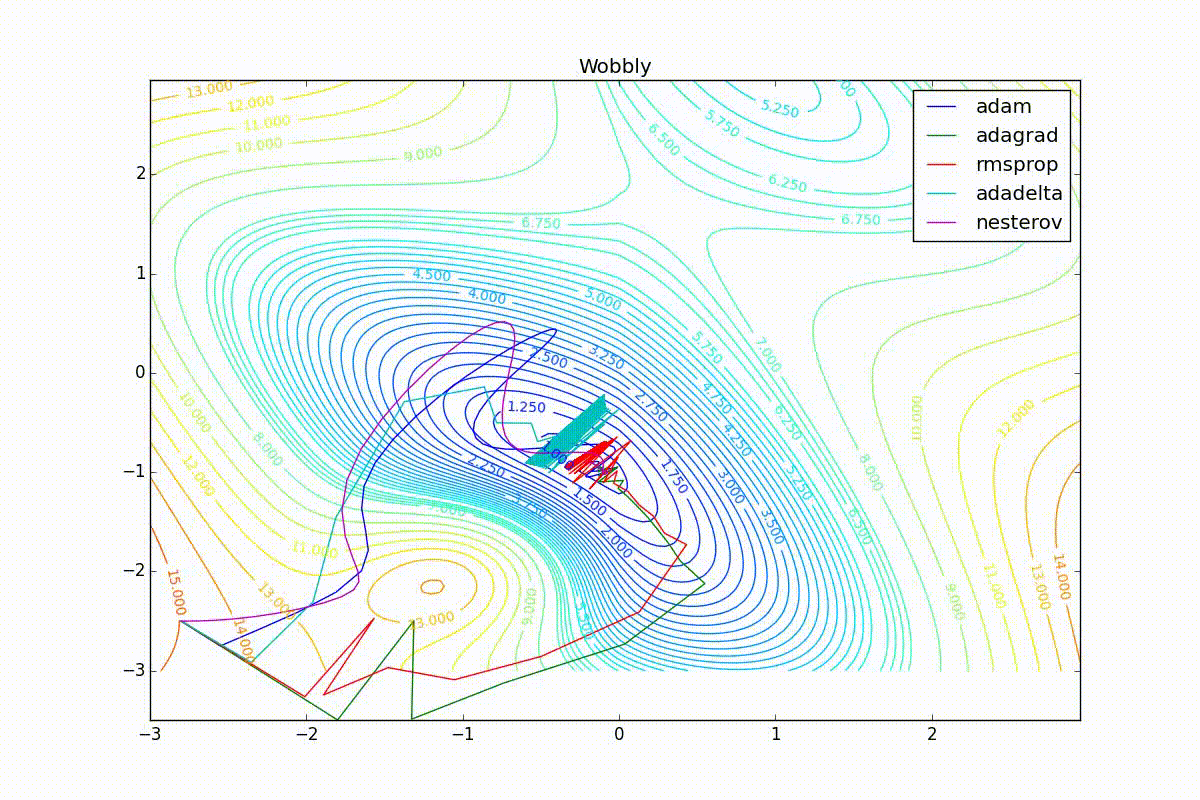
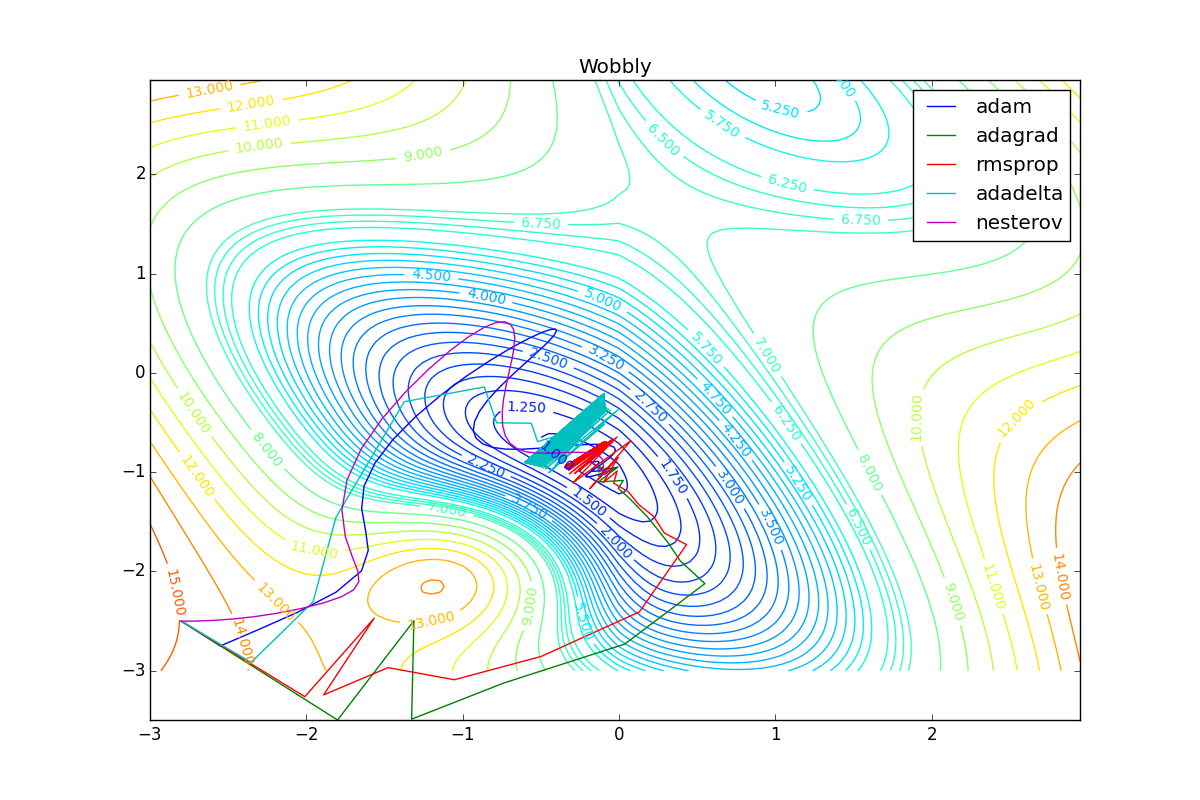
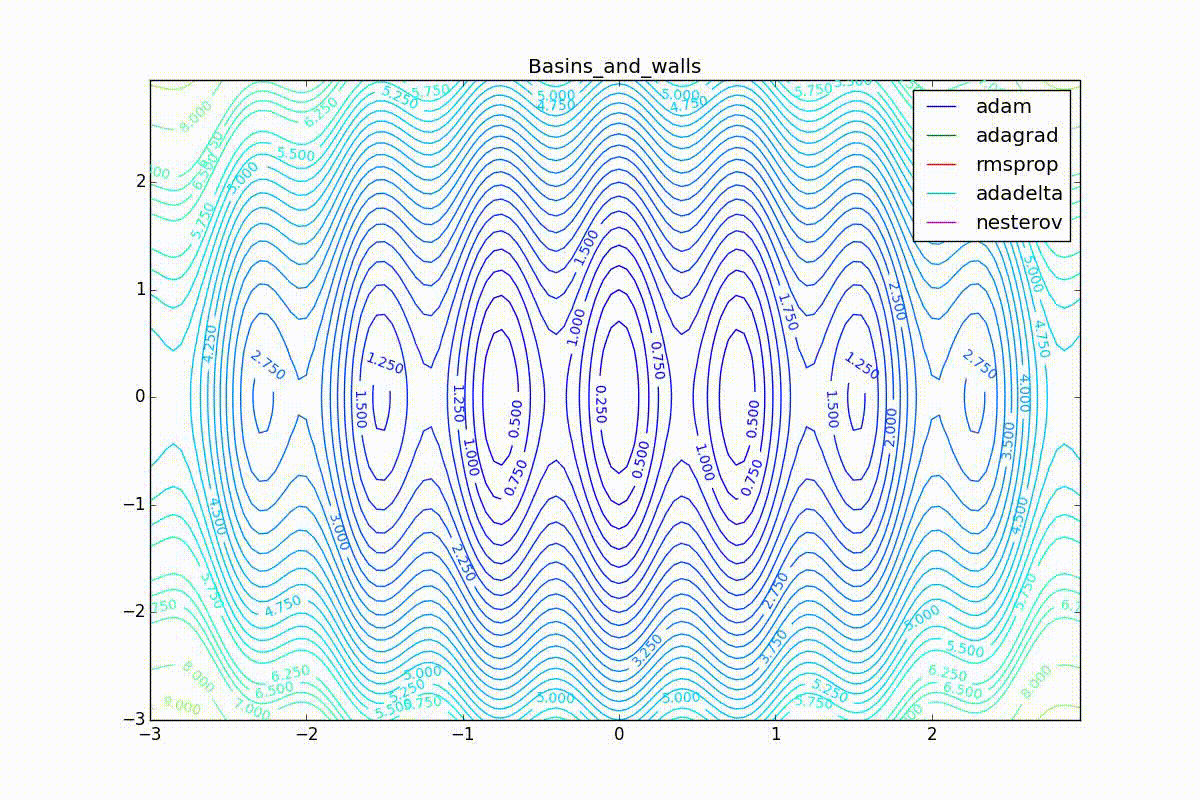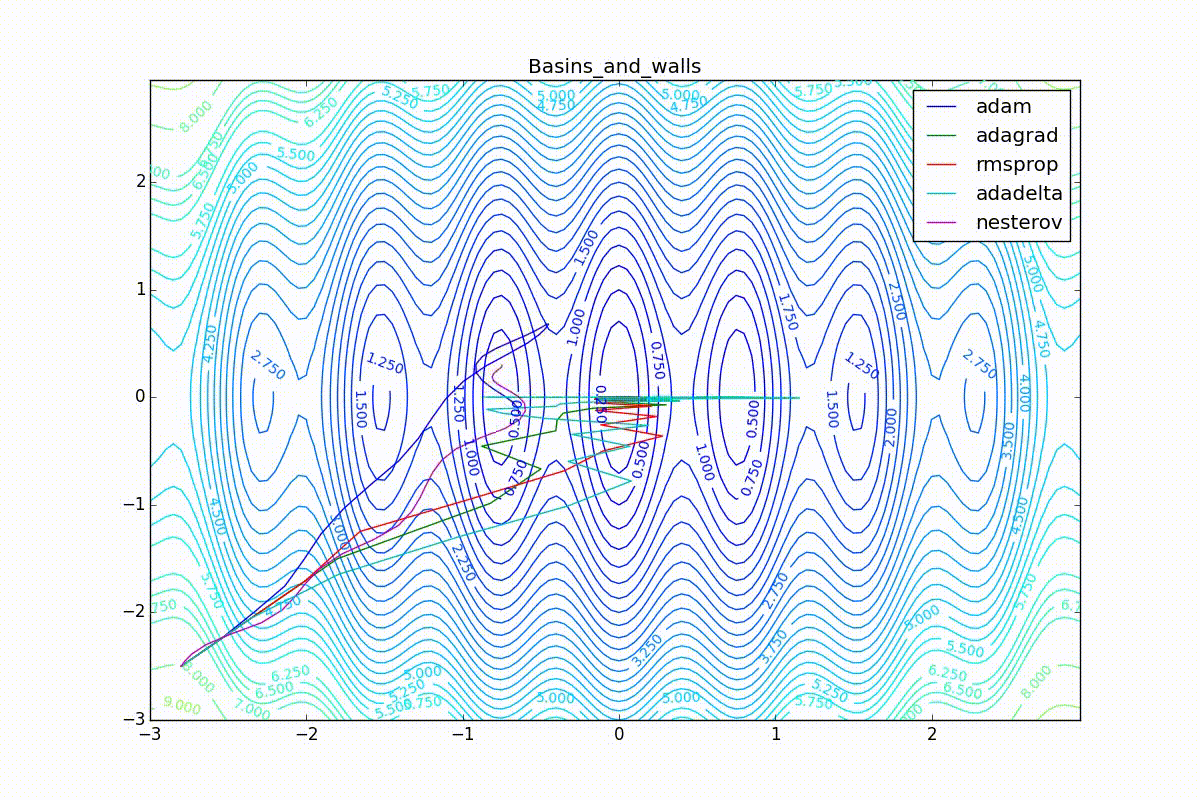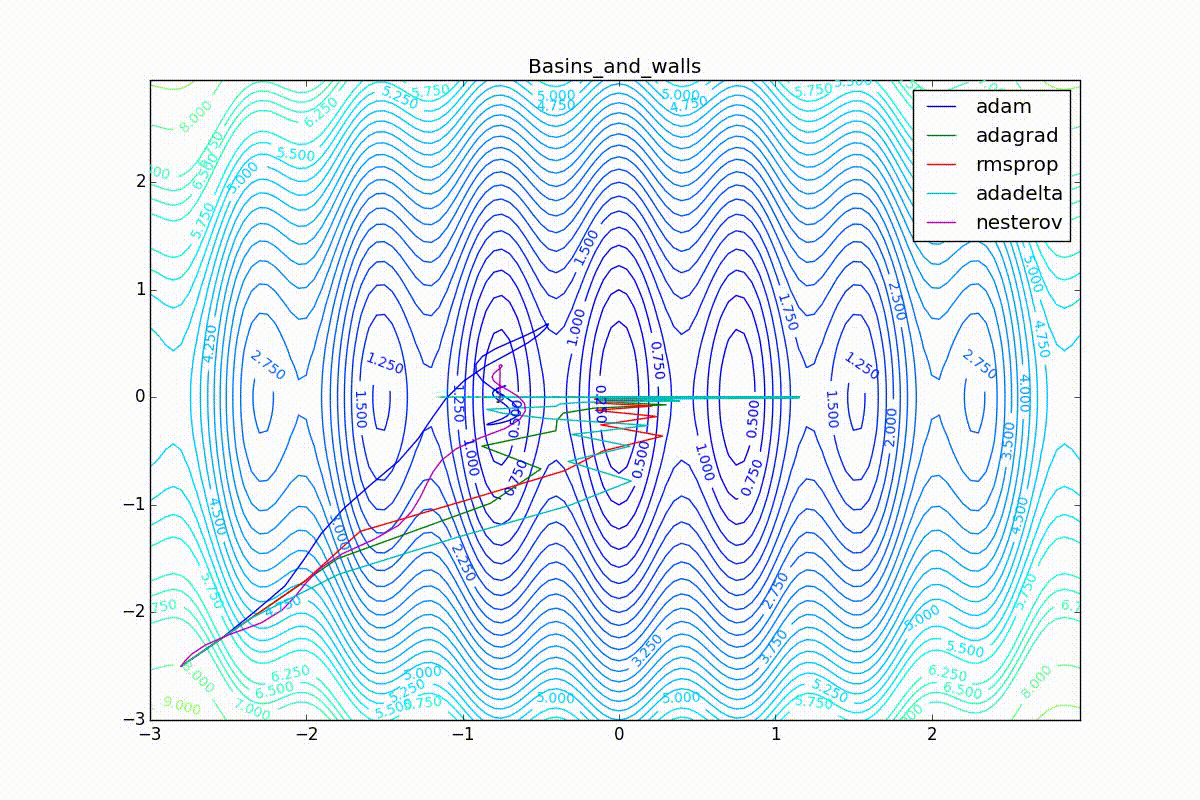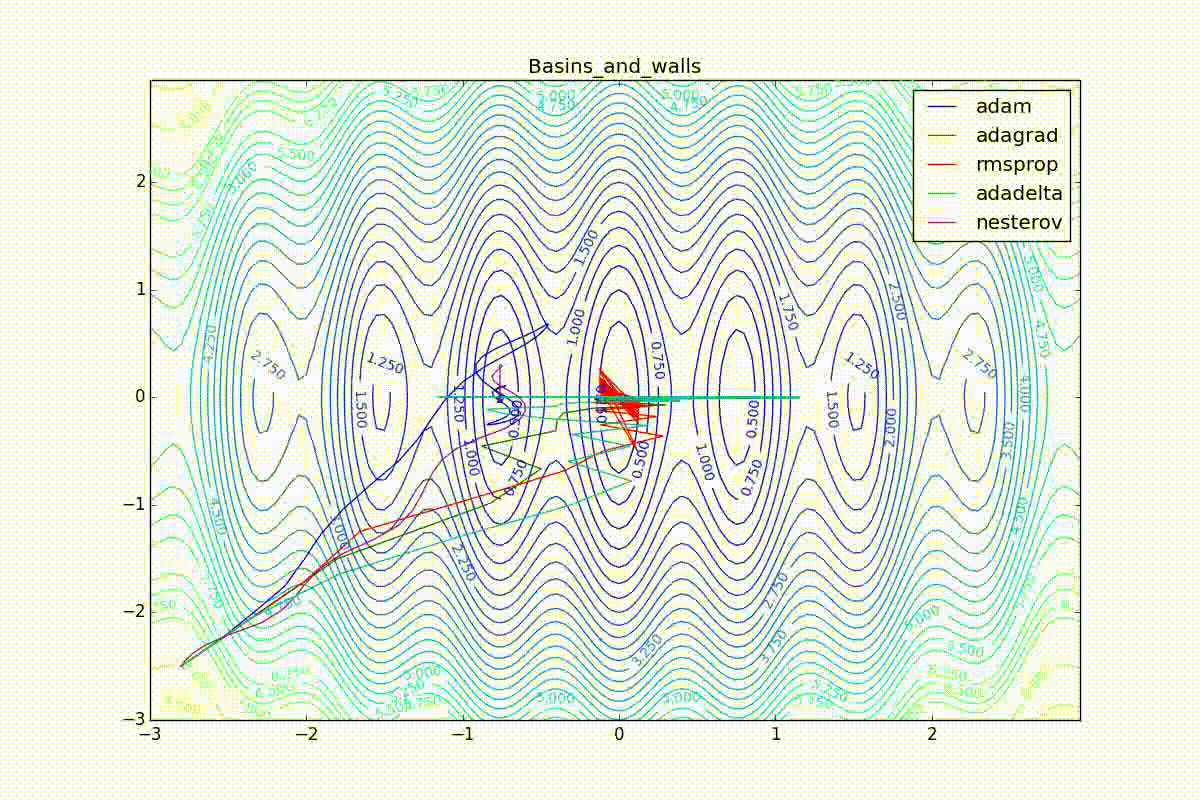
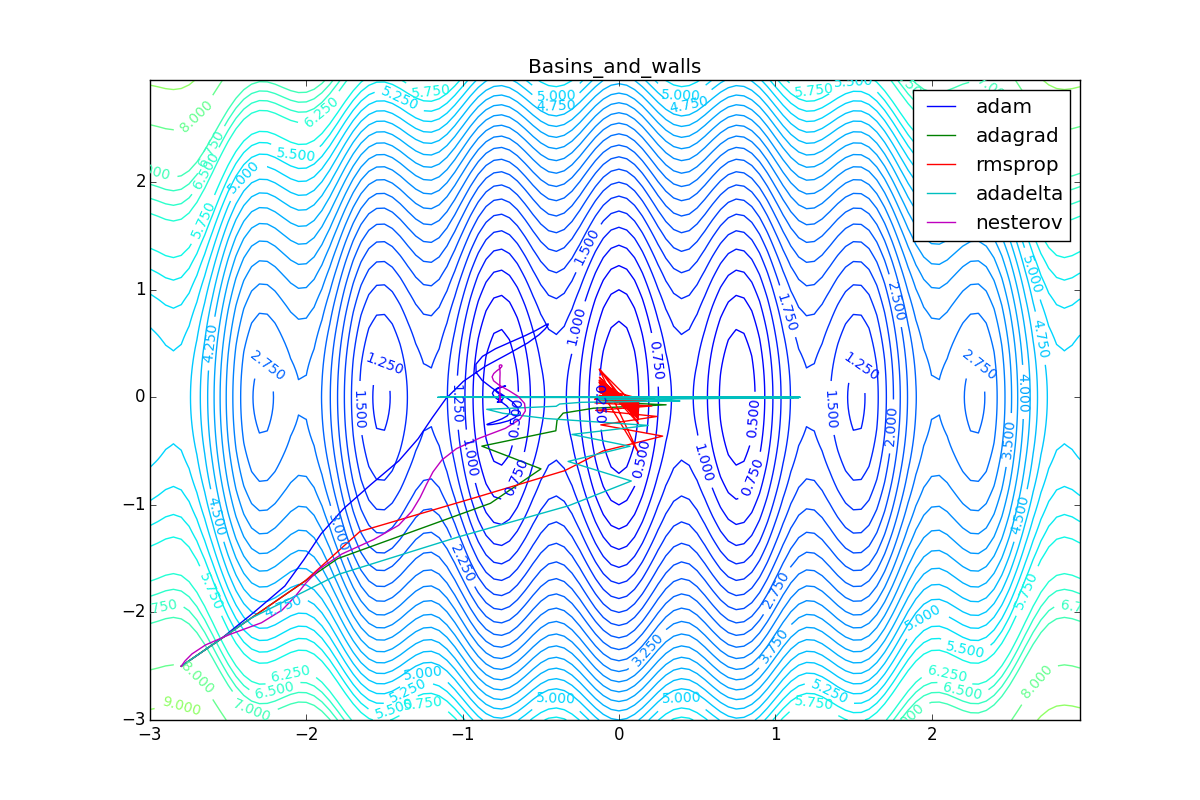
Как видно, все они довольно хорошо сходятся (с минимальным подбором скорости обучения). Обратите внимание на то, какие большие шаги совершают Adam и RMSProp в начале обучения. Так происходит потому что с самого начала не было ниаких изменений ни по одному параметру (ни по одной координате) и суммы в знаменателях (14) и (23) равны нулю. Вот тут ситуация посложнее:
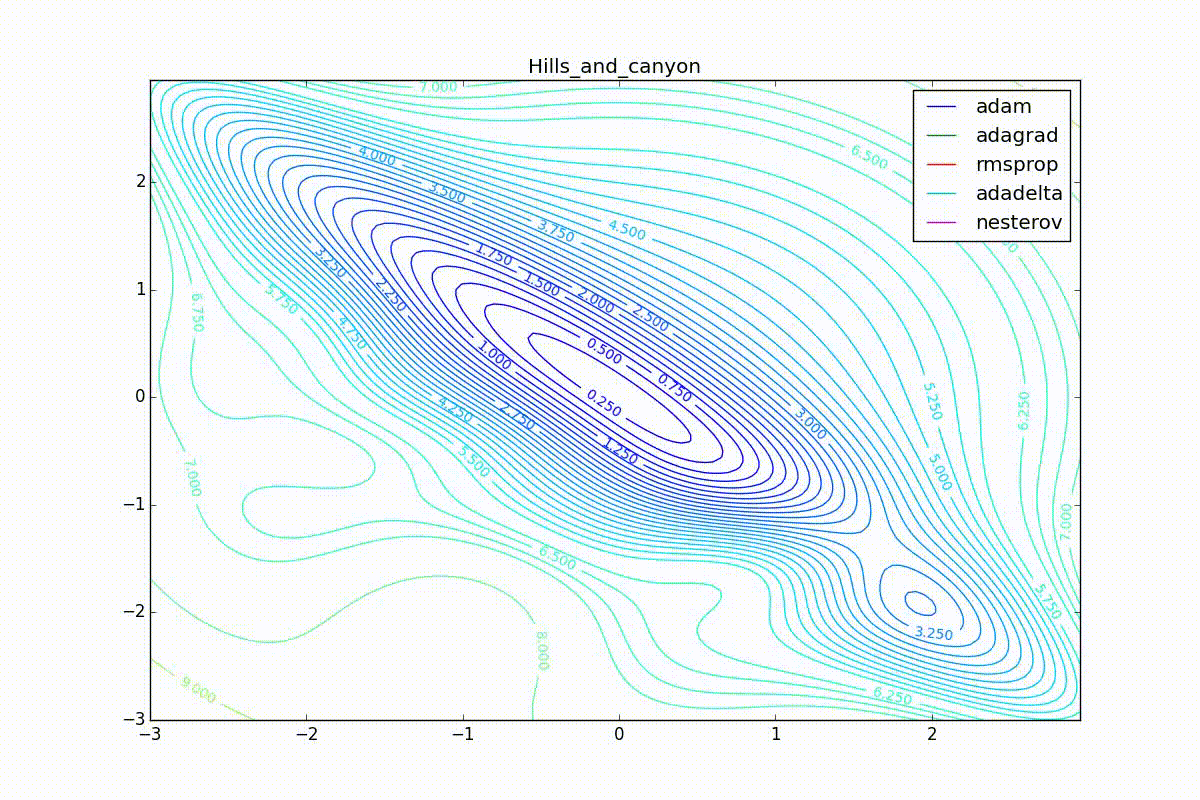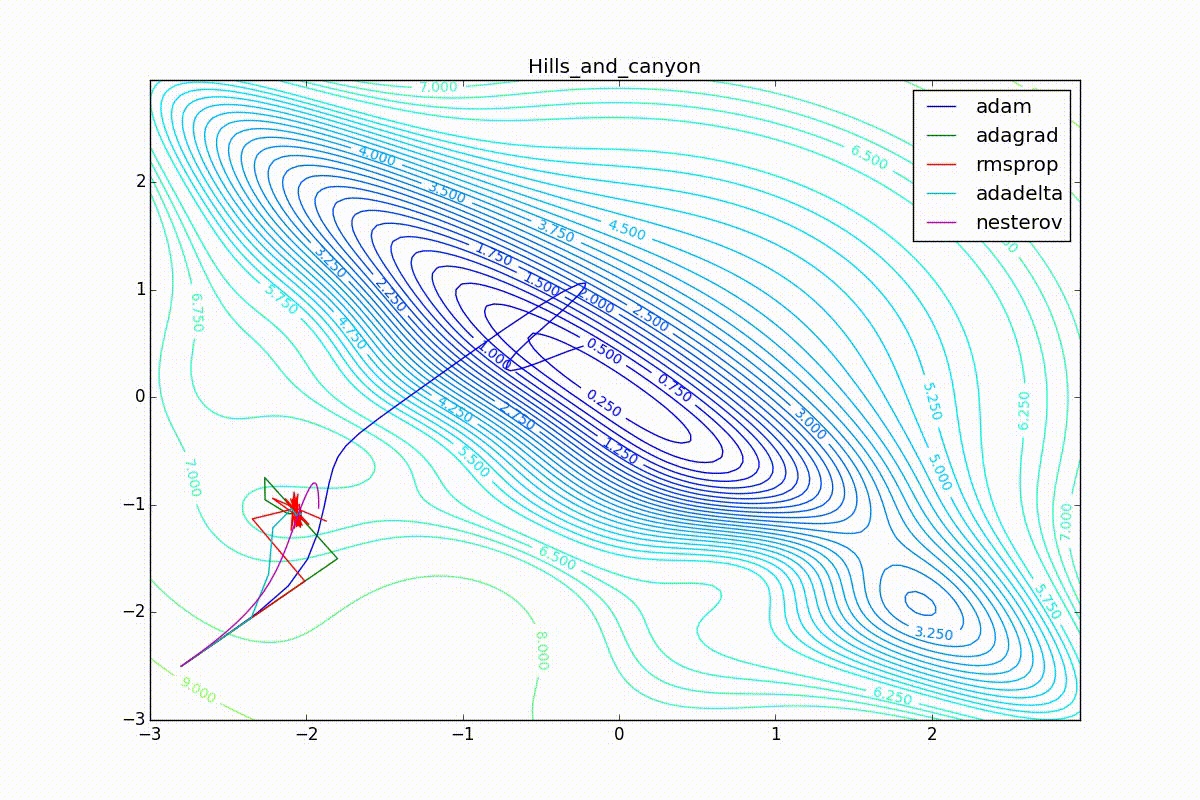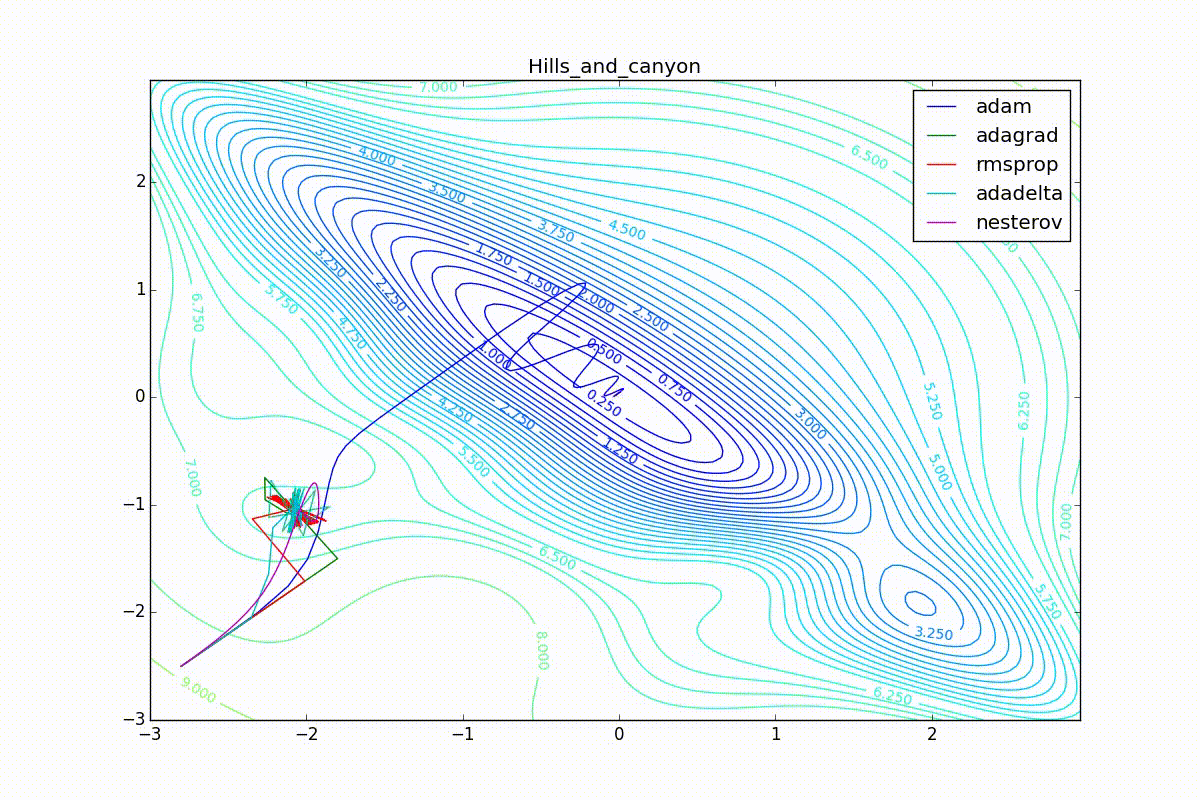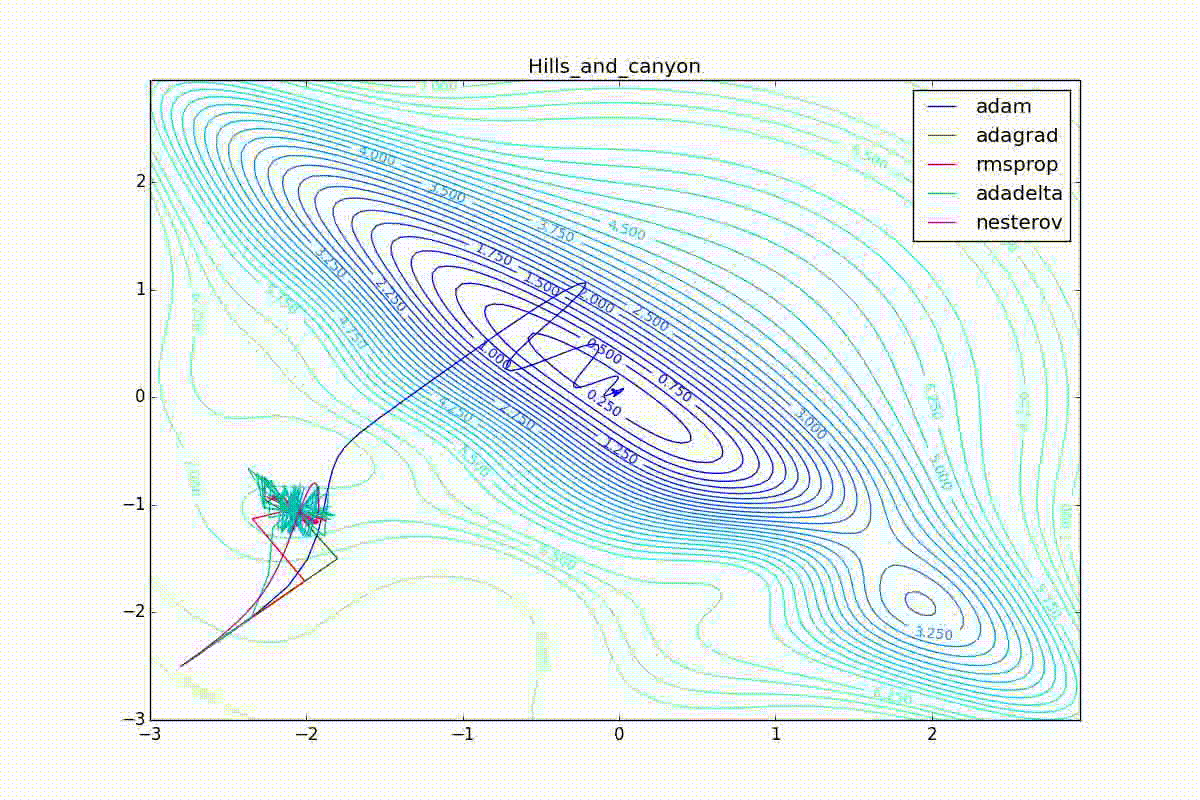
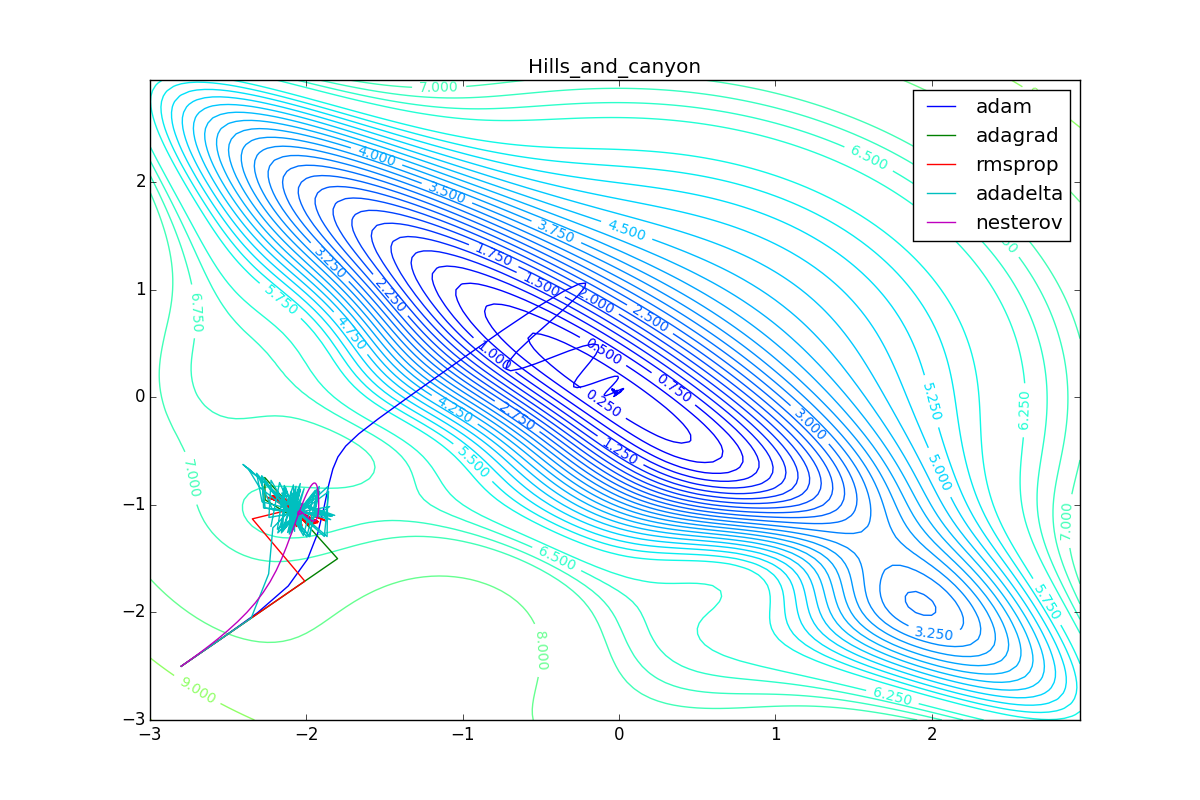
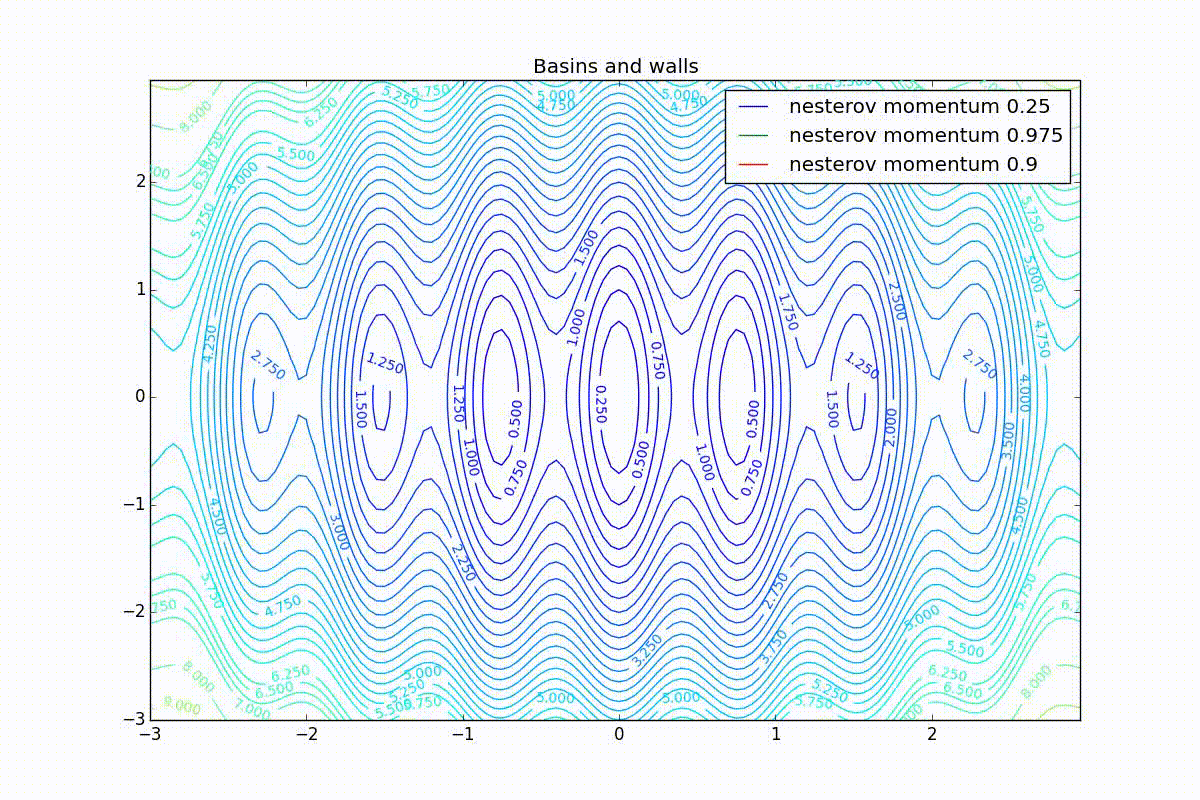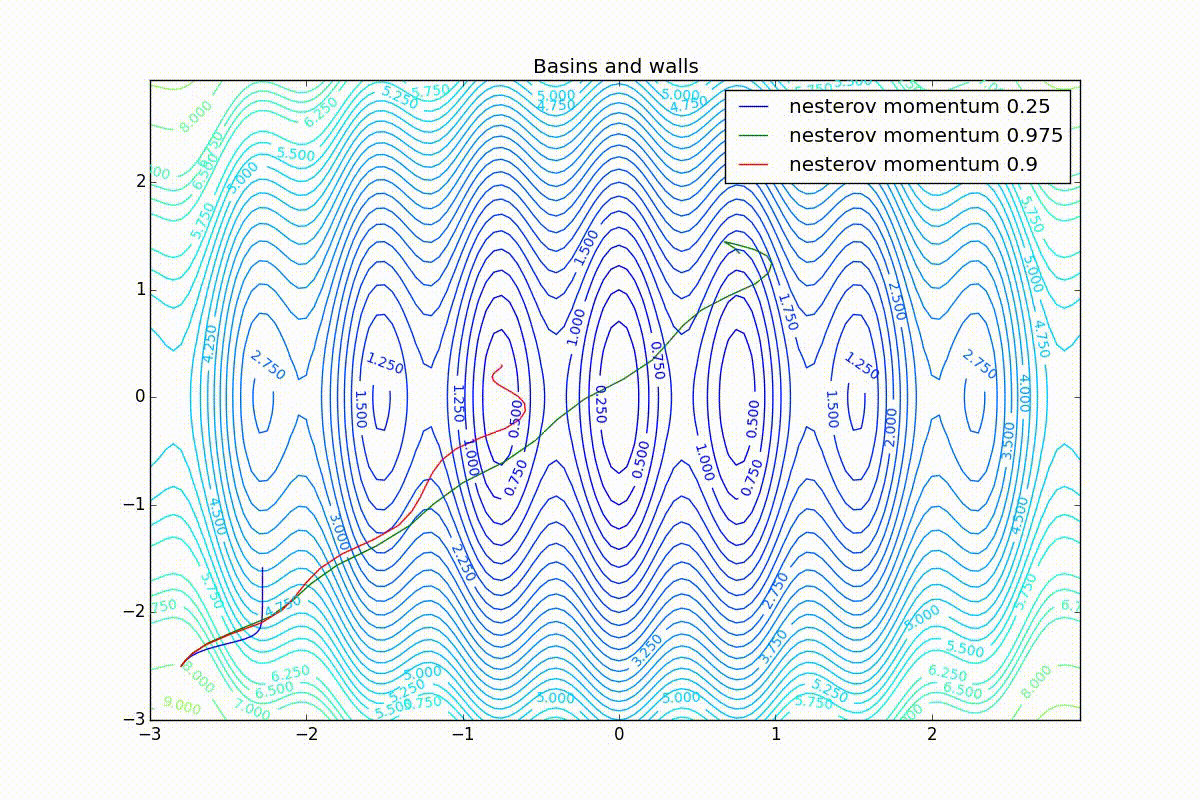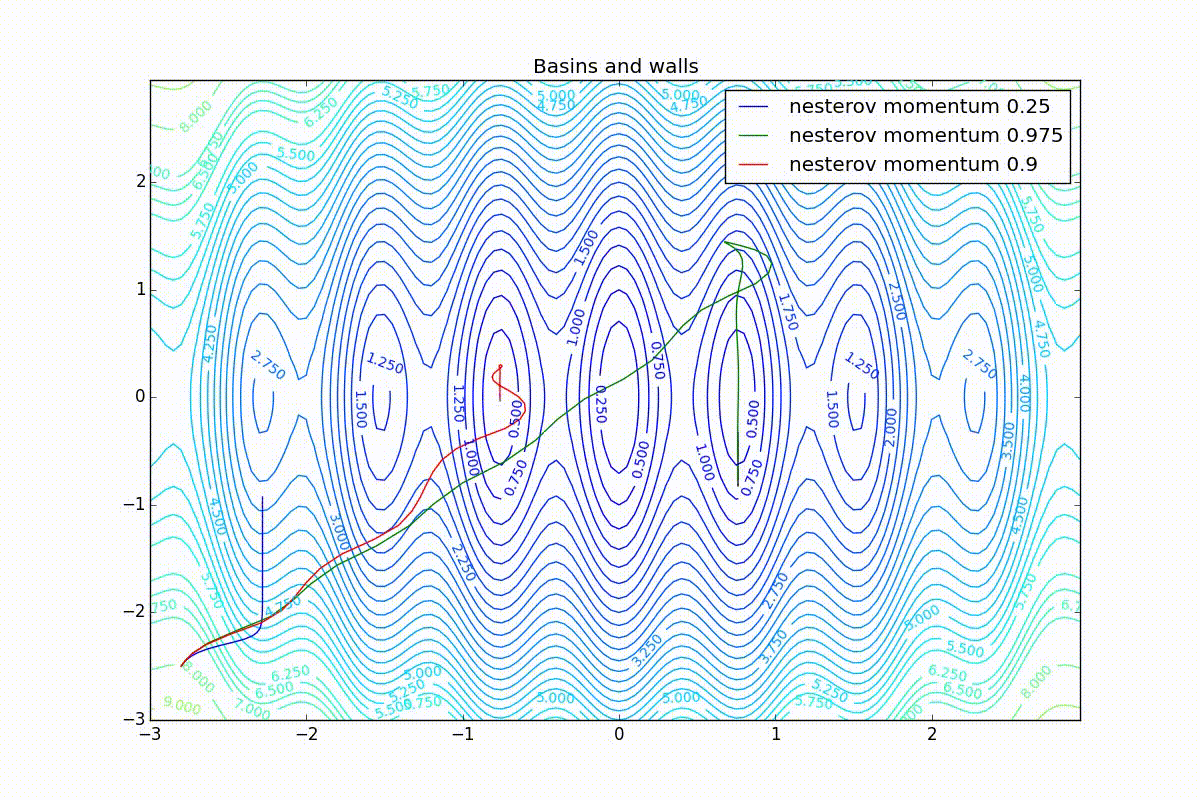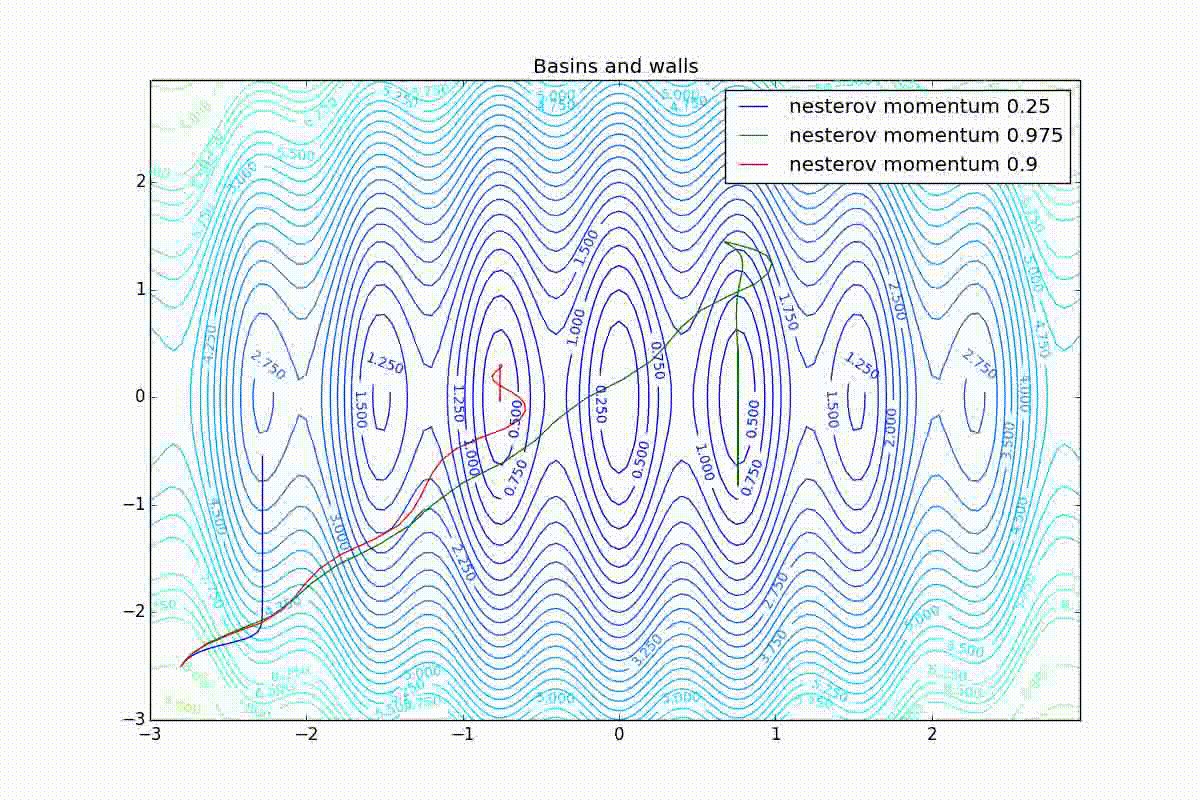
Кроме Adam, все оказались заперты в локальном минимуме. Сравните поведение метода Нестерова и, скажем, RMSProp на этих графиках. Ускоренный градиент Нестерова, с любым , попав в локальный минимум, некоторое время кружится вокруг, затем теряет импульс и затухает в какой-нибдуь точке. RMSProp же рисует характерных «ёжиков». Это тоже связано с суммой в знаменателе (14) — в ловушке квадраты градиента маленькие и знаменатель снова становится маленьким. На величину скачков влияют ещё, очевидно, скорость обучения (чем больше
, тем больше скачки) и
(чем меньше, тем больше). Adagrad такого поведения не показывает, так как у этого алгоритма сумма по всей истории градиентов, а не по окну. Обычно это желательное поведение, оно позволяет выскакивать из ловушек, но изредка таким образом алгоритм сбегает из глобального минимума, что опять-таки, ведёт к невосполнимому ухудшению работы алгоритма на тренировочной выборке.
Наконец, заметьте, что хоть все эти оптимизаторы и могут найти путь к минимуму даже по плато с очень маленьким уклоном или сбежать из локального минимума, если до этого они уже набрали импульс, плохая начальная точка не оставляет им шансов:

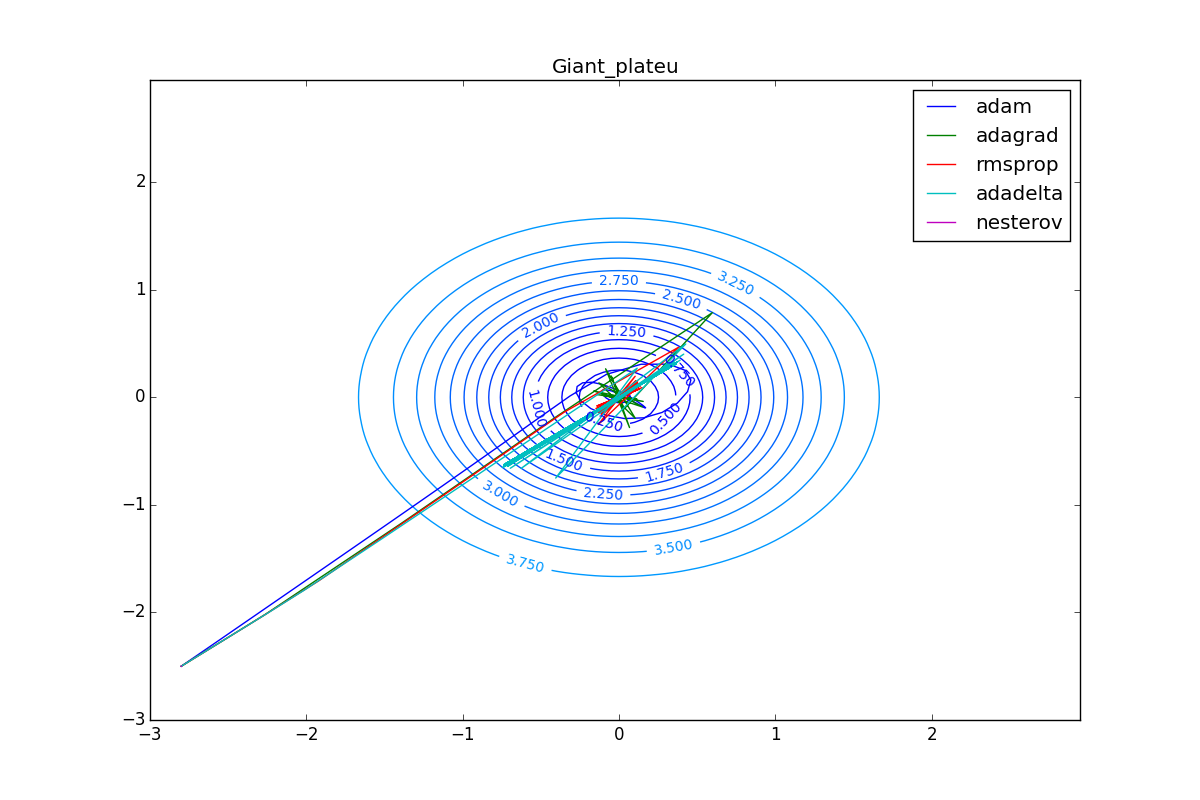
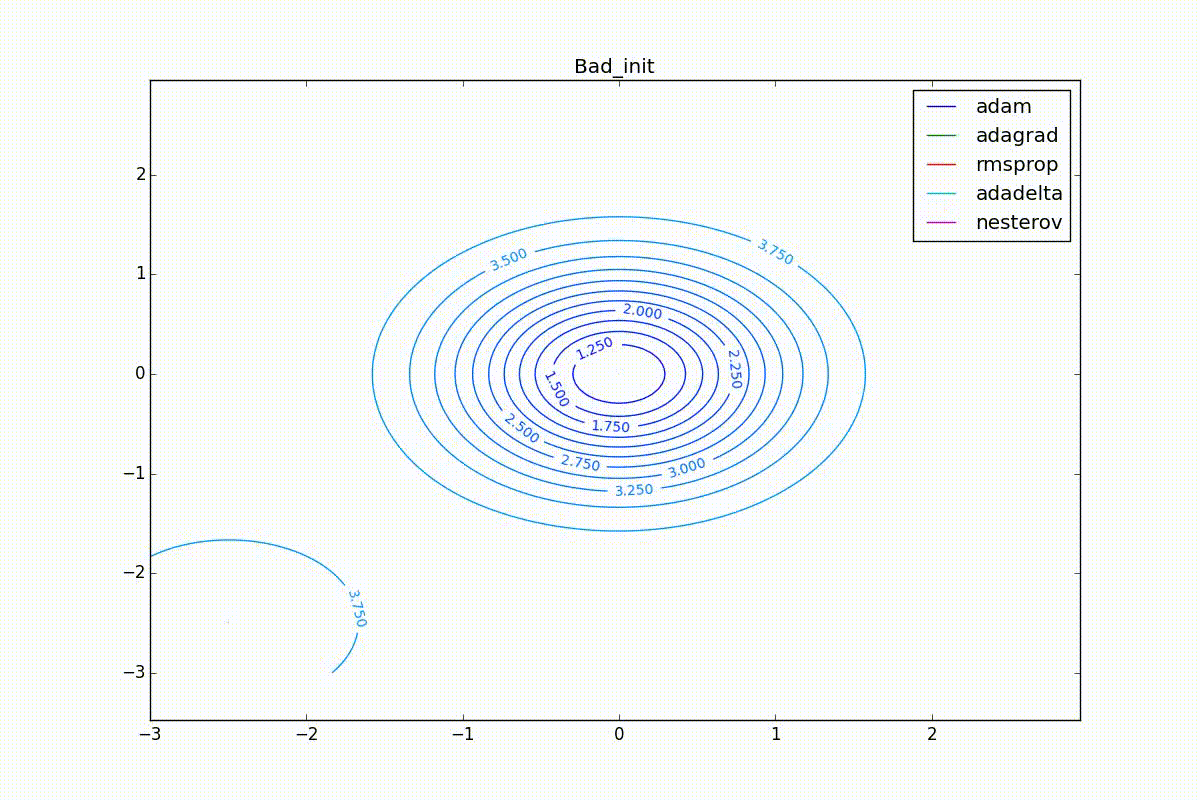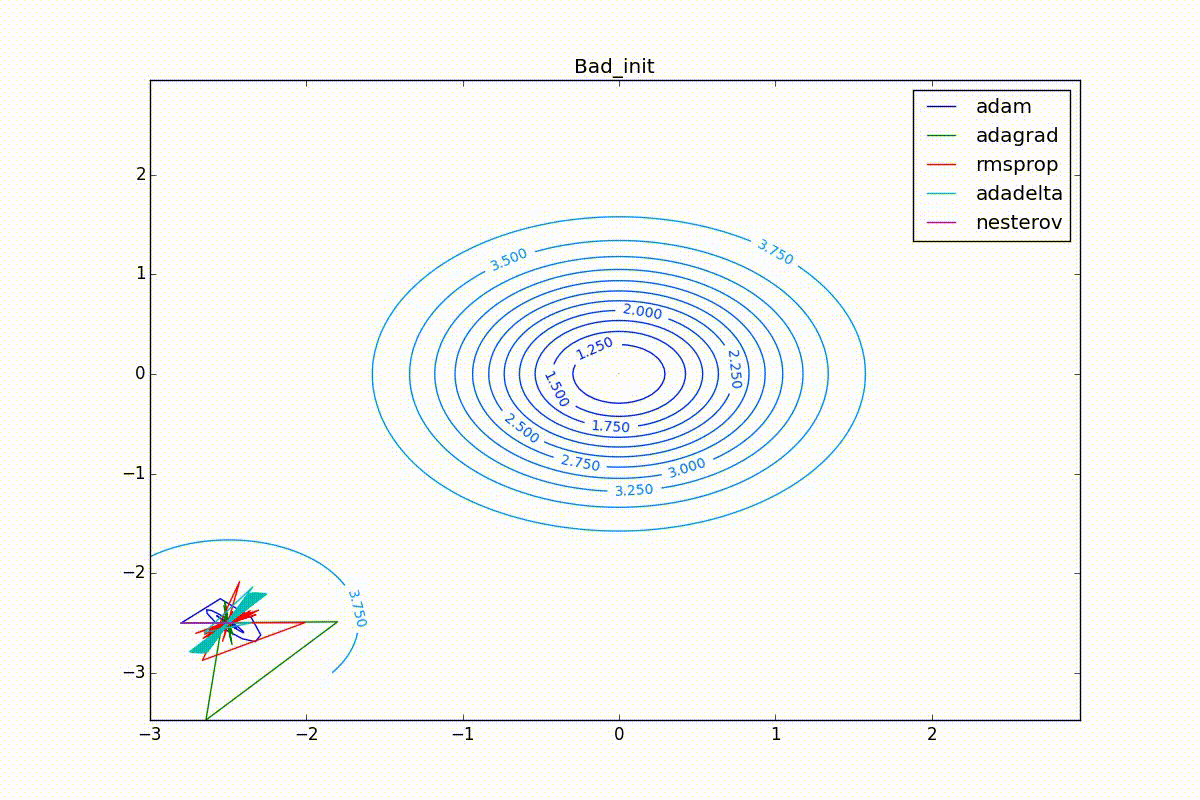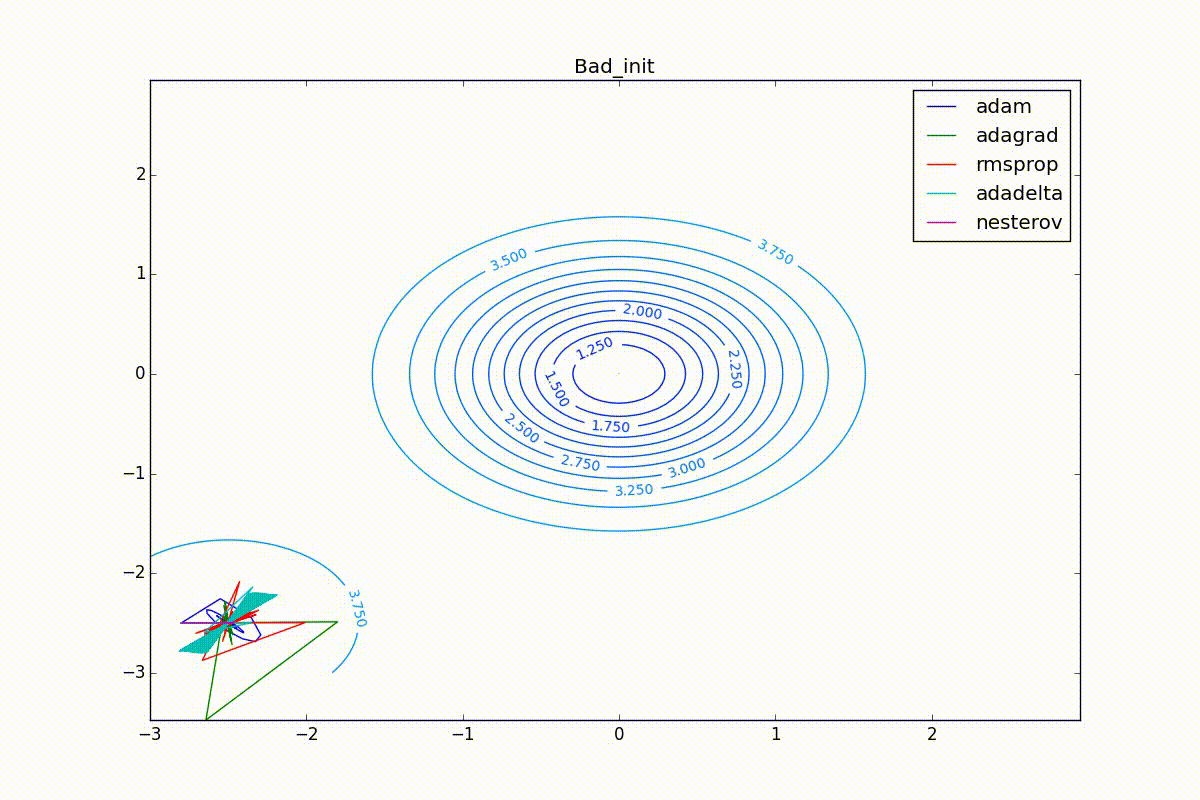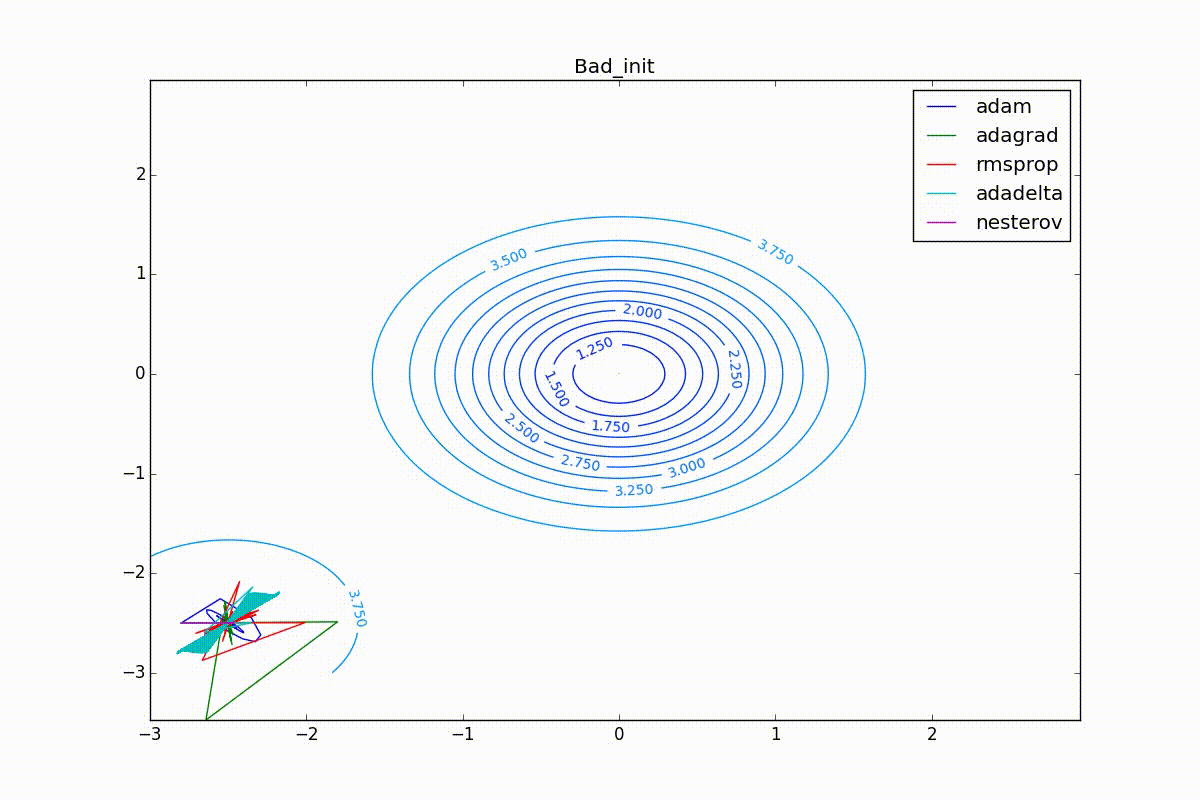
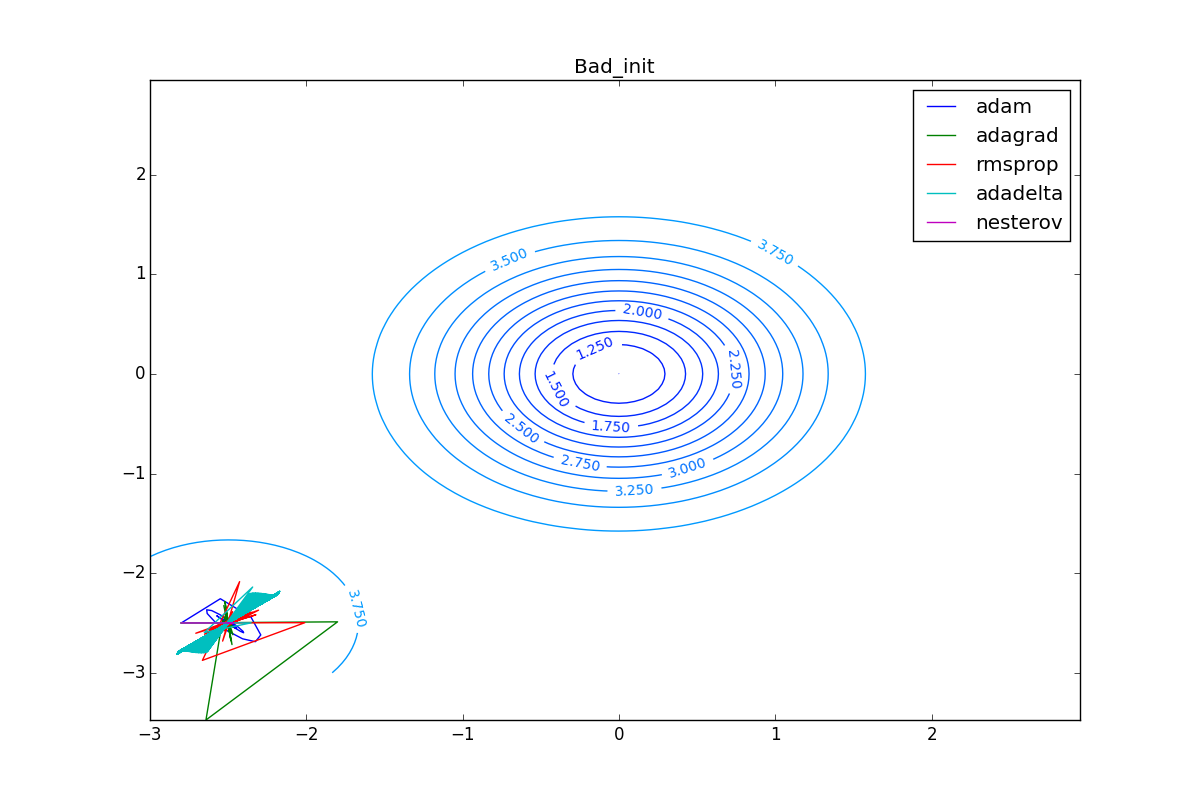
Заключение
Итак, мы рассмотрели несколько наиболее популярных оптимизаторов нейронных сетей первого порядка. Надеюсь, эти алгоритмы перестали казаться волшебным чёрным ящиком с кучей загадочных параметров, и теперь вы можете принять взвешенное решение, какой из оптимизаторов использовать в своих задачах.
Напоследок, всё же уточню один важный момент: вряд ли смена алгоритма обновления весов одним вжухом решит все ваши проблемы с нейронной сетью. Конечно прирост при переходе от SGD к чему-то другому будет очевиден, но скорее всего история обучения для алгоритмов, описанных в статье, для сравнительно простых датасетов и структур сети будет выглядеть как-то так:
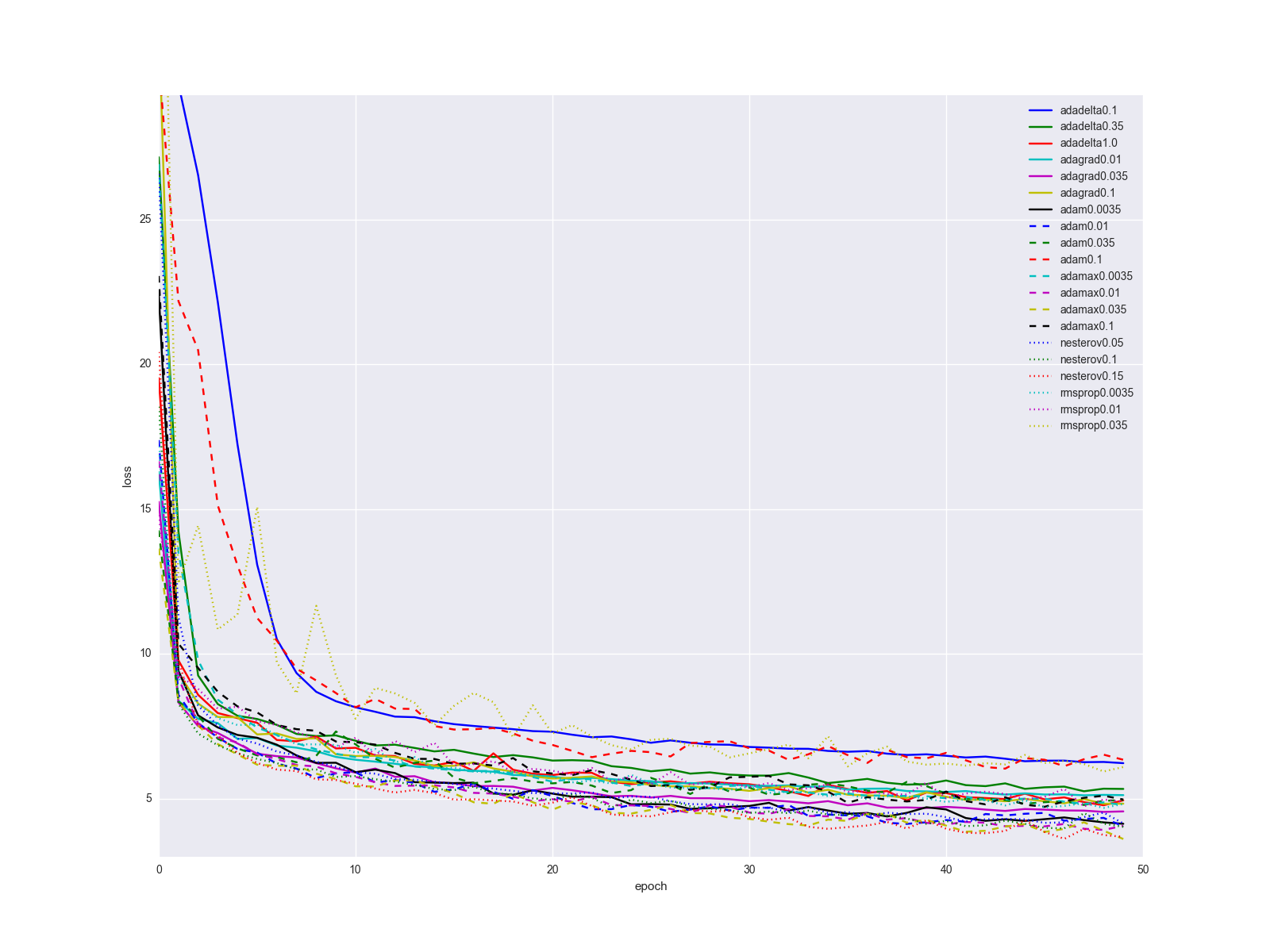
… не слишком впечатляет. Я бы предложил держать качестве «золотого молотка» Adam, так как он выдаёт наилучшие результаты при минимальном подгоне параметров. Когда сеть уже более-менее отлажена, попробуйте метод Нестерова с разными параметрами. Иногда с помощью него можно добиться лучших результатов, но он сравнительно чувствителен к изменениям в сети. Плюс-минус пара слоёв и нужно искать новый оптимальный learning rate. Рассматривайте остальные алгоритмы и их параметры как ещё несколько ручек и тумблеров, которые можно подёргать в каких-то специальных случаях.
Если хотите несколько собственных графиков с градиентами, воспользуйтесь этим скриптом на питоне (требуется python > 3.4, numpy и matplotlib):
Код
from matplotlib import pyplot as plt import numpy as np from math import ceil, floor def linear_interpolation(X, idx): idx_min = floor(idx) idx_max = ceil(idx) if idx_min == idx_max or idx_max >= len(X): return X[idx_min] elif idx_min < 0: return X[idx_max] else: return X[idx_min] + (idx - idx_min)*X[idx_max] def EDM(X, gamma, lr=0.25): Y = [] v = 0 for x in X: v = gamma*v + lr*x Y.append(v) return np.asarray(Y) def NM(X, gamma, lr=0.25): Y = [] v = 0 for i in range(len(X)): v = gamma*v + lr*(linear_interpolation(X, i+gamma*v) if i+gamma*v < len(X) else 0) Y.append(v) return np.asarray(Y) def SmoothedNM(X, gamma, lr=0.25): Y = [] v = 0 for i in range(len(X)): lookahead4 = linear_interpolation(X, i+gamma*v/4) if i+gamma*v/4 < len(X) else 0 lookahead3 = linear_interpolation(X, i+gamma*v/2) if i+gamma*v/2 < len(X) else 0 lookahead2 = linear_interpolation(X, i+gamma*v*3/4) if i+gamma*v*3/4 < len(X) else 0 lookahead1 = linear_interpolation(X, i+gamma*v) if i+gamma*v < len(X) else 0 v = gamma*v + lr*(lookahead4 + lookahead3 + lookahead2 + lookahead1)/4 Y.append(v) return np.asarray(Y) def Adagrad(X, eps, lr=2.5): Y = [] G = 0 for x in X: G += x*x v = lr/np.sqrt(G + eps)*x Y.append(v) return np.asarray(Y) def RMSProp(X, gamma, lr=0.25, eps=0.00001): Y = [] EG = 0 for x in X: EG = gamma*EG + (1-gamma)*x*x v = lr/np.sqrt(EG + eps)*x Y.append(v) return np.asarray(Y) def Adadelta(X, gamma, lr=50.0, eps=0.001): Y = [] EG = 0 EDTheta = lr for x in X: EG = gamma*EG + (1-gamma)*x*x v = np.sqrt(EDTheta + eps)/np.sqrt(EG + eps)*x Y.append(v) EDTheta = gamma*EDTheta + (1-gamma)*v*v return np.asarray(Y) def AdadeltaZeroStart(X, gamma, eps=0.001): return Adadelta(X, gamma, lr=0.0, eps=eps) def AdadeltaBigStart(X, gamma, eps=0.001): return Adadelta(X, gamma, lr=50.0, eps=eps) def Adam(X, beta1, beta2=0.999, lr=0.25, eps=0.0000001): Y = [] m = 0 v = 0 for i, x in enumerate(X): m = beta1*m + (1-beta1)*x v = beta2*v + (1-beta2)*x*x m_hat = m/(1- pow(beta1, i+1) ) v_hat = v/(1- pow(beta2, i+1) ) dthetha = lr/np.sqrt(v_hat + eps)*m_hat Y.append(dthetha) return np.asarray(Y) np.random.seed(413) X = np.arange(0, 300) D_Thetha_spikes = np.asarray( [int(x%60 == 0) for x in X]) D_Thetha_rectangles = np.asarray( [2*int(x%40 < 20) - 1 for x in X]) D_Thetha_noisy_sin = np.asarray( [np.sin(x/20) + np.random.random() - 0.5 for x in X]) D_Thetha_very_noisy_sin = np.asarray( [np.sin(x/20)/5 + np.random.random() - 0.5 for x in X]) D_Thetha_uneven_sawtooth = np.asarray( [ x%20/(15*int(x > 80) + 5) for x in X]) D_Thetha_saturation = np.asarray( [ int(x % 80 < 40) for x in X]) for method_label, method, parameter_step in [ ("GRAD_Simple_Momentum", EDM, [0.25, 0.9, 0.975]), ("GRAD_Nesterov", NM, [0.25, 0.9, 0.975]), ("GRAD_Smoothed_Nesterov", SmoothedNM, [0.25, 0.9, 0.975]), ("GRAD_Adagrad", Adagrad, [0.0000001, 0.1, 10.0]), ("GRAD_RMSProp", RMSProp, [0.25, 0.9, 0.975]), ("GRAD_AdadeltaZeroStart", AdadeltaZeroStart, [0.25, 0.9, 0.975]), ("GRAD_AdadeltaBigStart", AdadeltaBigStart, [0.25, 0.9, 0.975]), ("GRAD_Adam", Adam, [0.25, 0.9, 0.975]), ]: for label, D_Thetha in [("spikes", D_Thetha_spikes), ("rectangles", D_Thetha_rectangles), ("noisy sin", D_Thetha_noisy_sin), ("very noisy sin", D_Thetha_very_noisy_sin), ("uneven sawtooth", D_Thetha_uneven_sawtooth), ("saturation", D_Thetha_saturation), ]: fig = plt.figure(figsize=[16.0, 9.0]) ax = fig.add_subplot(111) ax.plot(X, D_Thetha, label="gradient") for gamma in parameter_step: Y = method(D_Thetha, gamma) ax.plot(X, Y, label="param="+str(gamma)) ax.spines['bottom'].set_position('zero') full_name = method_label + "_" + label plt.xticks(np.arange(0, 300, 20)) plt.grid(True) plt.title(full_name) plt.xlabel('epoch') plt.ylabel('value') plt.legend() # plt.show(block=True) #Uncoomment and comment next line if you just want to watch plt.savefig(full_name) plt.close(fig)Если хотите поэкспериментировать с параметрами алгоритмов и собственными функциями, используйте это, чтобы создать собственную анимацию траектории минимизатора (требуется вдобавок theano/lasagne):
Ещё код
import numpy as np import matplotlib matplotlib.use("Agg") import matplotlib.pyplot as plt import matplotlib.animation as animation import theano import theano.tensor as T from lasagne.updates import nesterov_momentum, rmsprop, adadelta, adagrad, adam #For reproducibility. Comment it out for randomness np.random.seed(413) #Uncoomment and comment next line if you want to try random init # clean_random_weights = scipy.random.standard_normal((2, 1)) clean_random_weights = np.asarray([[-2.8], [-2.5]]) W = theano.shared(clean_random_weights) Wprobe = T.matrix('weights') levels = [x/4.0 for x in range(-8, 2*12, 1)] + [6.25, 6.5, 6.75, 7] + list(range(8, 20, 1)) levels = np.asarray(levels) O_simple_quad = (W**2).sum() O_wobbly = (W**2).sum()/3 + T.abs_(W[0][0])*T.sqrt(T.abs_(W[0][0]) + 0.1) + 3*T.sin(W.sum()) + 3.0 + 8*T.exp(-2*((W[0][0] + 1)**2+(W[1][0] + 2)**2)) O_basins_and_walls = (W**2).sum()/2 + T.sin(W[0][0]*4)**2 O_ripple = (W**2).sum()/3 + (T.sin(W[0][0]*20)**2 + T.sin(W[1][0]*20)**2)/15 O_giant_plateu = 4*(1-T.exp(-((W[0][0])**2+(W[1][0])**2))) O_hills_and_canyon = (W**2).sum()/3 + 3*T.exp(-((W[0][0] + 1)**2+(W[1][0] + 2)**2)) + T.exp(-1.5*(2*(W[0][0] + 2)**2+(W[1][0] -0.5)**2)) + 3*T.exp(-1.5*((W[0][0] -1)**2+2*(W[1][0] + 1.5)**2)) + 1.5*T.exp(-((W[0][0] + 1.5)**2+3*(W[1][0] + 0.5)**2)) + 4*(1 - T.exp(-((W[0][0] + W[1][0])**2))) O_two_minimums = 4-0.5*T.exp(-((W[0][0] + 2.5)**2+(W[1][0] + 2.5)**2))-3*T.exp(-((W[0][0])**2+(W[1][0])**2)) nesterov_testsuit = [ (nesterov_momentum, "nesterov momentum 0.25", {"learning_rate": 0.01, "momentum": 0.25}), (nesterov_momentum, "nesterov momentum 0.9", {"learning_rate": 0.01, "momentum": 0.9}), (nesterov_momentum, "nesterov momentum 0.975", {"learning_rate": 0.01, "momentum": 0.975}) ] cross_method_testsuit = [ (nesterov_momentum, "nesterov", {"learning_rate": 0.01}), (rmsprop, "rmsprop", {"learning_rate": 0.25}), (adadelta, "adadelta", {"learning_rate": 100.0}), (adagrad, "adagrad", {"learning_rate": 1.0}), (adam, "adam", {"learning_rate": 0.25}) ] for O, plot_label in [ (O_wobbly, "Wobbly"), (O_basins_and_walls, "Basins_and_walls"), (O_giant_plateu, "Giant_plateu"), (O_hills_and_canyon, "Hills_and_canyon"), (O_two_minimums, "Bad_init") ]: result_probe = theano.function([Wprobe], O, givens=[(W, Wprobe)]) history = {} for method, history_mark, kwargs_to_method in cross_method_testsuit: W.set_value(clean_random_weights) history[history_mark] = [W.eval().flatten()] updates = method(O, [W], **kwargs_to_method) train_fnc = theano.function(inputs=[], outputs=O, updates=updates) for i in range(125): result_val = train_fnc() print("Iteration " + str(i) + " result: "+ str(result_val)) history[history_mark].append(W.eval().flatten()) print("-------- DONE {}-------".format(history_mark)) delta = 0.05 mesh = np.arange(-3.0, 3.0, delta) X, Y = np.meshgrid(mesh, mesh) Z = [] for y in mesh: z = [] for x in mesh: z.append(result_probe([[x], [y]])) Z.append(z) Z = np.asarray(Z) print("-------- BUILT MESH -------") fig, ax = plt.subplots(figsize=[12.0, 8.0]) CS = ax.contour(X, Y, Z, levels=levels) plt.clabel(CS, inline=1, fontsize=10) plt.title(plot_label) nphistory = [] for key in history: nphistory.append( [np.asarray([h[0] for h in history[key]]), np.asarray([h[1] for h in history[key]]), key] ) lines = [] for nph in nphistory: lines += ax.plot(nph[0], nph[1], label=nph[2]) leg = plt.legend() plt.savefig(plot_label + '_final.png') def animate(i): for line, hist in zip(lines, nphistory): line.set_xdata(hist[0][:i]) line.set_ydata(hist[1][:i]) return lines def init(): for line, hist in zip(lines, nphistory): line.set_ydata(np.ma.array(hist[0], mask=True)) return lines ani = animation.FuncAnimation(fig, animate, np.arange(1, 120), init_func=init, interval=100, repeat_delay=0, blit=True, repeat=True) print("-------- WRITING ANIMATION -------") # plt.show(block=True) #Uncoomment and comment next line if you just want to watch ani.save(plot_label + '.mp4', writer='ffmpeg_file', fps=5) print("-------- DONE {} -------".format(plot_label))Спасибо Роману Парпалак за инструмент, благодаря которому работа с формулами на хабре не так мучительна. Можете посмотреть статью, которую я брал за основу своей статьи — там есть много полезной информации, которую я опустил, чтобы лучше сфокусироваться на алгоритмах оптимизации. Чтобы ещё сильнее углубиться в нейронные сети, рекомендую эту книгу.
Хороших новогодних выходных, Хабр!
Источник: habrahabr.ru