Intel добавит в CPU инструкции для глубинного обучения
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-10-16 13:30
Некоторые из последних процессоров Intel поддерживают семейство векторных инструкций AVX-512. Они выполняются блоками по 512 бит (64 байта). Преимущество аппаратной поддержки таких больших инструкций в том, что за один такт процессор обрабатывает больше данных.
Если код загружается 64-битными словами (8 байт), то теоретически, если не брать в учёт другие факторы, можно ускорить его выполнение в восемь раз, если использовать инструкции AVX-512.
Расширение AVX-512 для системы команд x86 поддерживает 8 регистров масок, 512-разрядные упакованные форматы для целых и дробных чисел и операции над ними, тонкое управление режимами округления (позволяет переопределить глобальные настройки), операции broadcast, подавление ошибок в операциях с дробными числами, операции gather/scatter, быстрые математические операции, компактное кодирование больших смещений.
В первоначальный набор AVX-512 входит восемь групп инструкций:
- AVX-512 Conflict Detection Instructions (CDI)
- AVX-512 Exponential and Reciprocal Instructions (ERI)
- AVX-512 Prefetch Instructions (PFI)
- AVX-512 Vector Length Extensions (VL)
- AVX-512 Byte and Word Instructions (BW)
- AVX-512 Doubleword and Quadword Instructions (DQ)
- AVX-512 Integer Fused Multiply Add (IFMA)
- AVX-512 Vector Byte Manipulation Instructions (VBMI)
Семейство AVX-512 поддерживается в сопроцессоре Intel Xeon Phi (ранее Intel MIC) Knights Landing, некоторых процессорах Skylake Xeon (SKX), а также будущих процессорах Cannonlake, которые появятся в продаже в 2017 году. Перечисленные процессоры поддерживают не все из инструкций. Например, Knights Landing Xeon Phi поддерживает только CD, ER и PF. Процессор Skylake Xeon (SKX) поддерживает CD, VL, BW и DQ. Процессор Cannonlake - CD, VL, BW, DQ, IFMA.
Естественно, не любой код можно обратить в векторные инструкции, но и не нужно делать это со всем кодом, пишет в своём блоге Дэниель Лемир (Daniel Lemire), профессор информатики Университета Квебека. По его словам, важно оптимизировать «горячий код», который отнимает больше всего ресурсов процессора. Во многих системах «горячий код» построен из ряда циклов, которые прокручиваются миллиарды раз. Вот именно его следует оптимизировать, в этом основная выгода.
Например, если такой питоновский код перекомпилировать со стандартных 64-битных инструкций в AVX-512 с помощью MKL Numpy , то время исполнения снижается с 6-7 секунд до 1 секунды на том же процессоре.
import numpy as np
np.random.seed(1234)
xx = np.random.rand(1000000).reshape(1000, 1000)
%timeit np.linalg.eig(xx)
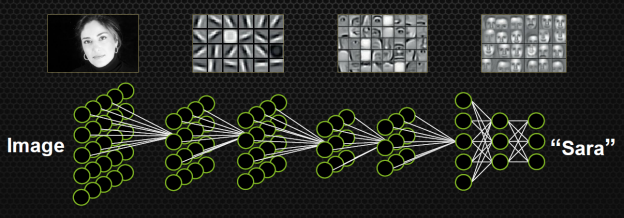
Аппаратная поддержка глубинного обучения
Нейросети и глубинное обучение - один из ярких трендов последнего времени. Google, Facebook и другие крупные компании пытаются применить нейросети где только можно: в системах рекомендаций, распознавании лиц, переводах текстов, распознавании речи, классификации фотографий и даже в настольных играх вроде го (но это скорее ради пиара, чем для коммерческой выгоды). Кое-кто пытается применить глубинное обучение в нестандартных областях, таких как обучение автомобильного автопилота.
Среди венчурных инвесторов сейчас есть понимание, что самая эффективная схема быстро разбогатеть - запустить стартап в области глубинного обучения, который сразу купит компания из «большой пятёрки» (Facebook, Google, Apple, Microsoft, Amazon). Эти фирмы в последнее время жёстко конкурируют в области скупки талантов, так что стартап уйдёт мгновенно и за большую цену из расчёта минимум $10 млн за сотрудника. Такой бизнес-план стал сейчас ещё проще, поскольку компании выпускают инструменты для разработки с открытыми исходниками, как это сделала Google с TensorFlow.
К несчастью для Intel, эта компания здесь плетётся в хвосте и почти не участвует в игре. Профессор Лемир признаёт, что сейчас отраслевым стандартом считаются графические процессоры Nvidia. Именно на них запускают код программ для машинного обучения.
Дело не в том, что инженеры Intel проспали тренд. Просто графические процессоры сами по себе без всяких специальных инструкций лучше приспособлены для расчётов deep learning.
Тем не менее, Intel готовит контратаку, в результате которой ситуация может перевернуться с ног на голову. В сентябре компания опубликовала новое справочное руководство Intel Architecture Instruction Set Extensions Programming Reference с указанием всех инструкций, которые будут поддерживаться в будущих процессорах. Если заглянуть в этот документ, то нас ждёт приятный сюрприз. Оказывается, семейство инструкций AVX-512 разбили на несколько групп и расширили.
В частности, две группы инструкций специально предназначены для глубинного обучения: AVX512_4VNNIW и AVX512_4FMAPS. Судя по описанию, эти инструкции могут быть полезными не только в глубинном обучении, но и во многих других задачах.
Источник: www.nanonewsnet.ru