Го-сингулярность
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-03-16 16:19

Почему победа AlphaGo над Ли Седолем важнее победы Deep Blue над Гарри Каспаровым, и как это повлияет на обычных людей
Короткая ссылка для распространения: http://bit.ly/go-singularity
Два человека сидели друг напротив друга за чистой доской для игры Го. 12 марта 2016 года в 13:00 по местному Сеульскому времени должна была начаться третья партия в серии из пяти игр. Серии, которой было предназначено перевернуть жизни десятков миллионов игроков в Го.
Чаша с чёрными камнями на ближайшие четыре часа принадлежала Ли Седолю, одному из сильнейших профессиональных игроков мира. Белые камни ставил на доску Аджа Хуан, обладатель любительского 6 дана и один из разработчиков компьютерной программы AlphaGo. Именно она решала, какой ход сделать за белых.
Через четыре часа и тринадцать минут после начала матча взволнованный Ли Седоль собирал камни с доски, объявив третье подряд поражение от компьютера, и, тем самым, поражение в пятиматчевой серии.

Это сражение чем-то напоминало бой Оберина Мартелла и Григора Клигана в сериале «Игра Престолов». Ли Седоль в самом начале партии навязал противнику сложную борьбу (корейцы любят такой стиль), ища слабости программы, но она отвечала уверенно и красиво. В конце партии, когда у человека оставалось мало времени для раздумий, AlphaGo продемонстрировала мощную игру в ко-борьбе (форме тактической борьбы, где раньше компьютеры проигрывали людям «в одну калитку») и буквально сокрушила Ли Седоля.
Демис Хассабис, руководитель рабочей группы AlphaGo, казался растерянным на послематчевой пресс-конференции. Он начал свою речь словами «To be honest, we-re a bit stunned and speechless» («Честно говоря, мы слегка потрясены и потеряли дар речи»).
Похоже, у искусственного Го-разума не осталось слабых мест, и человечество уступило машине в следующей великой логической игре после шахмат.
Многие любители Го испытали потрясение 12 марта: привычный мир рухнул. Многие из тех, кто не играет в Го, не считают это событие значимым. Подумаешь: шашки, шахматы, Го- Какая разница? Прочитав статью до конца, вы поймёте, почему разница есть, почему мир для игроков Го не рухнул, и почему 12 марта мы сделали безвозвратный шаг в сингулярность.
Для этого нам придётся немного окунуться в историю игры.
Го как играГо ---одна из древнейших игр, доживших до современности. Точных данных о её зарождении нет. Древнейшие игровые артефакты, обнаруженные в Китае, датируют началом нашей эры. Можно точно сказать, что игра зародилась в Китае (там она называется «вейци»), распространилась по всей Азии, и расцвела в Японии приблизительно в XVI-XVII веках.
В начале XXI века Го продолжает быть популярной в Азии. Десятки миллионов японцев, китайцев и корейцев регулярно играют в Го.

Фреска из пещеры Юйлинь 32 (провинция Ганьсу), эпоха Пяти династий (907-979 гг. н.э.)
Подробнее об истории Го:
- A Pictorial History of the Game Go (en)
- История Го в Википедии (рус)
Правила Го сравнительно просты, проще шахматных. Игроки поочерёдно выставляют камни чёрного и белого цветов на перекрестья линий доски (пункты). Задача каждого игрока---к концу партии окружить наибольшую территорию. Есть правила, в каких случаях камни могут быть сняты с доски («съедены»), а также как поступать в спорных ситуациях, когда игра может «зациклиться» (правило ко). Начинающий может сыграть первую партию на учебной доске (9‡9 линий) спустя полчаса освоения правил.

Типичный финал партии в Го. Wired.com
Многие считают Го сложнее других игр с открытой информацией (включая шахматы), несмотря на простоту правил. Причина---высочайшая вариативность игры, особенно в начале партии. Каждый следующий ход может быть совершён в сотни пунктов. Оценивают, что за время существования Го не было сыграно двух одинаковых партий, а количество возможных партий превышает количество атомов во Вселенной.
Партия в Го делится на три этапа (начало, середина и завершение), аналогично шахматным дебюту, миттельшпилю и эндшпилю. Примечательно, что на каждом из этих этапов игроки борются на разных уровнях абстракции.
В начале партии (оно называется фусэки) важен баланс между заявкой на влияние на доске и заявкой на территорию. Если играть слишком осторожно и сразу ограничивать территорию в углах доски, соперник сможет усилиться и к концу партии «заработать» гораздо больше в центре доски и на её сторонах. Если же пытаться играть на влияние, то позднее противник может вторгнуться в зону влияния и «выжить» там, отобрав территорию к концу партии.
В фусэки сложно «просчитывать» ходы (кроме розыгрышей в углах), ходы совершаются на основании предыдущего опыта игрока и его «видения доски».

Пример фусэки. Майкл Редмонд комментирует второй матч серии. Ли Седоль играет белыми.
В середине игры (на этапе тюбан) на доске определён баланс влияния, и игроки борются за силу и слабость групп камней. Определяется, на какую территорию претендует каждый из игроков, какие группы камней «выживут». Также становятся критически важными формы групп.
Точная оценка территорий, на которые претендуют игроки, пока ещё невозможна.
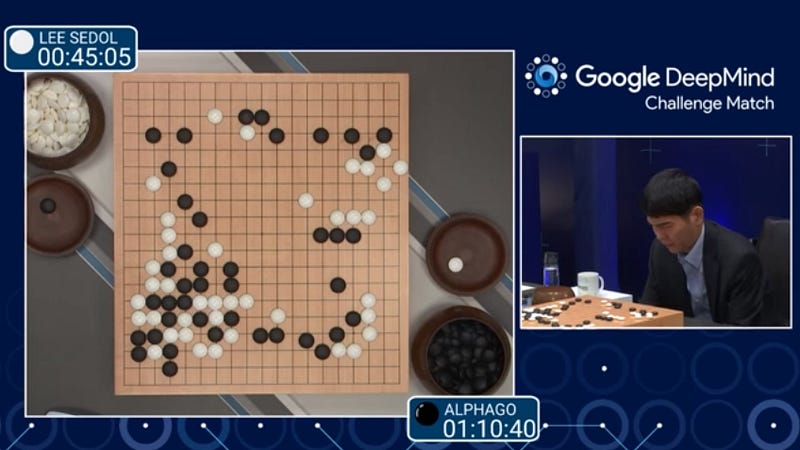
Пример тюбан. Второй матч серии.
В конце игры (на этапе ёсэ или йосэ), если баланс в игре сохранился, и ни один игрок не потерял слишком большую группу или часть территории, идёт борьба за конкретный размер территорий (очки).

Пример ёсэ. Второй матч серии.
Сильные игроки нередко доигрывают ёсэ так, что у них оказывается одинаковое количество очков. Но в Го нет ничьих, потому что игрок белыми камнями имеет компенсацию за то, что он ходит вторым (коми), равную 6,5 или 7,5 очков, в зависимости от правил. Размер коми определён статистически на основании анализа большого количества партий. Половинка очка исключает ничьи.
Одно из правил хорошего тона в Го---сдаваться и не доигрывать партию, если видишь, что её уже не спасти. Профессиональные игроки сдавались даже с «неотыгрываемой» разницей в пол-очка. Если в тюбан «умерла» большая группа камней, ёсэ часто не отыгрывают, а сразу сдаются.
Мы подошли ко второму важному отличию Го от других игр, кроме воспринимаемой сложности и абстрактности. Го---не просто игра. Это культурный феномен, превосходящий, например, футбол.
Го как культураПроцитируем текст из Википедии:
Расцвет го в Японии пришёлся на XVII---XIX века. Во многом это связано с тем, что наиболее известные военачальники и правители XVI века---Ода Нобунага, Тоётоми Хидэёси и Токугава Иэясу, ---серьёзно увлекались го, полагая игру не только времяпровождением, но и прекрасной тренировкой, помогающей правильно управлять войсками. Они держали учителей го, как для себя, так и для своих воинов. Когда в 1584 году Хидэёси стал регентом Японии, его увлечение дало толчок развитию го в стране. В 1588 году был проведён большой турнир, победитель которого, Никкай (наставник Ода Нобунага) был объявлен сильнейшим игроком Японии.
Японцы известны своей способностью доводить вещи и идеи до эстетического совершенства. Игра Го стала одним из четырёх искусств, владение которыми обязательно для аристократа---наравне с каллиграфией, стихосложением и музицированием. В игре и вокруг игры развился сложный этикет.

Мастер учит гейш играть в Го, конец XIX века. okinawa-soba
Вторая причина расцвета Го, помимо перфекционизма японцев, заключается в том, что абстрактные концепции Го работают по аналогии в обычной жизни лучше, чем концепции других игр.
Игра Го стала моделью войны, моделью разделения рынка, моделью для политических манёвров для целой части света почти на тысячелетие. Поговорки, принципы, подходы Го применяются людьми для принятия решений за пределами игровой доски. Изучение игры развивает системное мышление.
Сегодня в Азии не просто десятки миллионов людей играют в Го. Профессиональные игроки зарабатывают сотни тысяч долларов США в турнирах, организованных крупнейшими азиатскими корпорациями уровня Samsung, LG и Fujitsu. Существуют спортивные телеканалы, посвящённые только Го. Родители отдают шестилетних детей в школы, где тех учат только играть в Го. Есть специализированные на игре Го высшие учебные заведения (представьте себе «Российский Футбольный Университет», к примеру).
За пределами Азии игра Го не так популярна, игроков меньше, и в среднем они слабее.
Сила игрока в ГоЕсли один игрок чаще проигрывает другому игроку, он слабее. Поражение в одной партии ничего не доказывает. И даже в двух или в трёх. Поэтому пока что трудно объективно сравнить силу игры AlphaGo и человека.
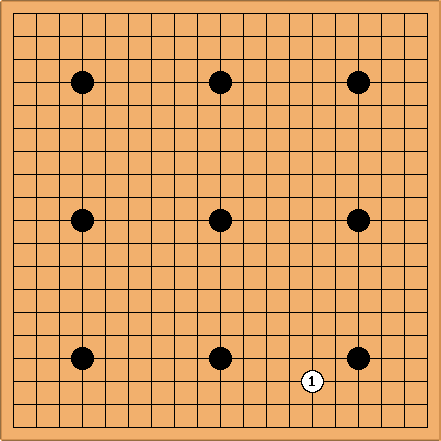
Традиционная максимальная фора в девять камней. Слабый играет чёрными, сильный игрок делает первый ход белыми. Sensei-s Library
Благодаря тому, что результат игры может быть оценен не только бинарно («победа---поражение»), но и в разнице очков, в Го легко выстраивается чёткая градация уровней силы игры. Начиная с новичков («20 кю», «19 кю» и далее возрастающей до «1 кю»), продолжая «середнячками»-любителями («1 дан», «2 дан», - , «6 дан») и заканчивая профессионалами («1 про-дан», «2 про-дан», - , «9 про-дан»). Разница в один уровень позволяет играть примерно на равных с форой в один дополнительный камень на доске.
Сила игроков оказывается легко сравнима при условии, что многие играют много партий со многими. Когда накапливается статистика, выясняется, что количество игроков в Го распределяется по силе примерно вот так, где по оси X---сила игры от слабых к сильным, а по оси Y---количество игроков. Что тоже логично: новичков много, супер-профессионалов (к которым относится и Ли Седоль, 9 про-дан)---мало.
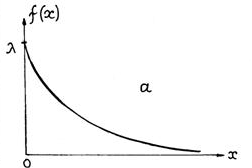
Что же делает игрока сильным? Чем Ли Седоль отличается от новичка?
Честно говоря, точно мы не знаем. Гарантированно влияют:
- знание абстрактных концепций игры и связей между ними;
- опыт, количество сыгранных и просмотренных партий, решённых задач;
- интуиция (что бы это ни было) и умение видеть доску в целом.
Из-за того, что просчитать наперёд длинные последовательности ходов невозможно, благодаря этим способностям профессионалы совершают ходы, которые новичок не в состоянии увидеть. А до недавнего времени не в состоянии были увидеть и компьютерные программы.
AlphaGo выходит на аренуДо начала 2010-х годов компьютерные программы играли не сильнее первого любительского дана. К этому времени человечество уже 10 лет как было повержено алгоритмами в шахматах. Игроки в Го были преисполнены снобизма и считали свою игру невероятно сложной для кремниевого разума.
Это было справедливо, потому что всё, что умели компьютеры---перебирать варианты ходов («я сюда---он сюда---я сюда---он сюда»), отбрасывая заведомо неудачные варианты. Количество «веток ходов» в Го, как мы уже говорили, больше количества атомов во Вселенной---особо не переберёшь.
Более того, в шахматах уже отыграны все дебюты, что помогает сократить длину перебора, а в Го количество вариаций в начале партий (фусэки) также ошеломительно велико, причём постоянно появляются новые идеи и ходы.
Сильнейшие программы эпохи до AlphaGo использовали вероятностные методы Монте-Карло: пытались просчитать наперёд как можно больше веток ходов, «бросая монетку» каждый раз.
Создатели AlphaGo объединили самые успешные подходы, накопленные в индустрии: нейронные сети глубокого обучения, генетические алгоритмы (немного отличающиеся копии AlphaGo играли сами с собой и отбирались лучшие) и методы Монте-Карло.
Подробнее см. замечательную статью Го: речь поражения на N+1.
Здесь также процитируем Александра Ершова, автора статьи.
Главное преимущество нейросетей заключается в том, что они позволяют достигать очень высоких уровней абстракции, вычленяя из изображений их, как бы сказать- чисто абстрактные черты. Например, если нейросеть обучена распознаванию котиков, то в ее первый слой просто загружается изображение, а последующие слои обрабатывают его примерно так: второй распознает контрастность пикселей, третий наличие линий, четвертый их ориентацию, пятый мохнатость, шестой «ушастость», а седьмой и последний---«кЈтовость». Важно понимать, что это очень условное представление о нейросетях---никто их заранее не программирует и не знает, что и как распознает данный слой. Как раз наоборот: все это происходит само собой по мере обучения. Суть аналогии в том, что уровень абстрактности очень сильно растет по мере движения от нижних к верхним слоям.

Тот случай, когда нейросеть пытается увидеть «собаковость». The Telegraph
На «вход» в AlphaGo загрузили полторы сотни тысяч партий (в статье Wired пишут о 30 миллионах человеческих ходов), в верхних слоях нейросети образовались некие абстрактные соображения «сбалансированности игровой доски», а потом AlphaGo заставили играть саму с собой, чтобы развить эти соображения.
Подробнее об устройстве на Хабрахабре:
- AlphaGo на пальцах
Итак, к своей первой серии игр с европейским чемпионом китайского происхождения Фань Хуем нейросеть AlphaGo обладала следующим набором характеристик:
- она была обучена на огромном количестве ранее сыгранных человеком партий (опыт + память?);
- она сыграла кучу партий со своими копиями, отбраковав слабые копии (опыт);
- она накопила в себе абстрактные концепции относительно состояния игры на доске в верхних слоях нейросети.
-AlphaGo learned to discover new strategies for itself, by playing millions of games between its neural networks, against themselves, and gradually improving,- says DeepMind researcher David Silver.
Принципиальное отличие от ситуации в шахматах нарисовалось со всей очевидностью.
Бороться с Ли Седолем вышел не программный код. Казалось, что с ним борется существо, обладающее накопленной памятью, способностью к прогнозированию игровой ситуации и опытом победы в десяти миллионах матчей против таких же существ, не прошедших эволюционного отбора.

Вообще говоря, AlphaGo---не что-то суперновое или сверхъестественное. Благодаря похожим технологиям вы получаете выдачу на поисковый запрос в Яндексе. Сайты ранжируются благодаря машинному обучению, основанному на оценках живых людей (асессоров).
Следующий проект IBM после Deep Blue, Watson, обыгрывает людей в передаче «Кто хочет стать миллионером?» и учится отвечать на запросы на естественном языке. Сири, Кортана и другие «персональные голосовые помощники» в смартфонах также используют похожие или смежные технологии.
Но именно AlphaGo попало, наконец, в самую страшную мякотку.
Автоматическое распознавание лиц друзей на фотографиях Facebook не пугает нас, потому что обычный человек не видит за этим «идей», «мыслей» или «мышления».
Комментаторы серии игр AlphaGo и Ли Седоля одушевляли нейросеть. Майкл Редмонд (9 про-дан) называл программу «he» («он»), а не «it» («оно»). Александр Динерштейн (3 про-дан) постоянно говорил о планах и намерениях AlphaGo относительно развития партии.
С этим согласятся все, кто смотрел игры и немного знает Го: AlphaGo играло как очень сильный человек, то есть прошло тест Тьюринга! Если AlphaGo запустить на игровой Го-сервер KGS, никто не сможет определить, что играет не с человеком.

В эргономике и робототехнике есть наблюдение, которое назвали «зловещей долиной». Робот или существо, очень похожее на человека, но отличающееся от человека, вызывает страх или отвращение. Этот эффект с удовольствием используют в фильмах ужасов.

Типичное лицо, попадающее в «зловещую долину».
Мы столкнулись с «меметической зловещей долиной». «Существо», явно имеющее какие-то идеи, обыгрывающее человека в игре, являющейся неотъемлемой частью его культуры, человеком явно не является.
Попробуем разобраться, что за отличия вызывают в нас эти чувства, и широк ли фронтир, разделяющий Ли Седоля и AlphaGo. Начнём с того, что Ли Седоль---живой человек из плоти и крови.
Эволюция идей99% человеческих генов совпадают с генами шимпанзе, а с бананом мы генетически родны наполовину. В этой статье нет возможности углубиться в доказательства, поэтому сразу приведу выводы. Всё живое (включая людей) является переносчиком генов (последовательностей нуклеотидов), которые эволюционируют. Эволюцию генов обеспечивают три фактора:
- способность генов побуждать окружающую среду к воспроизводству себя (ей обладают именно гены, не организмы), или, другими словами, способность к репликации;
- изменчивость генов, мутация;
- отбор наиболее приспособленных генов (если ген повлиял на формирование организма так, что он плохо действует в окружающей среде, организм не выживает, ген не распространяется).
Другими словами, мы, бананы и шимпанзе являемся, не больше и не меньше, единой средой для репликации генов.
Подробнее о биологической эволюции:
- «Эгоистичный ген», Ричард Докинз
- «Рождение сложности», Александр Марков
Мы старательно пытаемся доказать себе, что как вид являемся венцом эволюции, но виды не эволюционируют, эволюционируют гены.
Хорошо, а как же быть с культурой? Знаниями? Способностью менять мир?
Первым видом, изменившим мир, были бактерии, переработавшие атмосферу Земли из углекислого газа в кислород, и это было самое серьёзное (пока) воздействие биологического вида на планету Земля.
Человечество не является также и единственным носителем идей. Способность к научению развивается у животных постепенно в результате эволюции. Вслед за ней следуют первые проблески того, что мы могли бы назвать «идеями». Песни некоторых видов птиц не заложены генетически. Птенцы учат песни у старших, и в этот процесс часто закрадываются ошибки---песни немного меняются со сменой поколений. Дельфины обладают языком и личными именами.
Ричард Докинз точно подметил, что человечество (и другие некоторые животные) являются средой для репликации идей. И назвал идеи «мемами» по аналогии с генами. Меметическая эволюция происходит ровно по тем же законам, что и биологическая, только в другой среде. Её обеспечивают:
- способность идей побуждать организмы-носители к воспроизводству себя для передачи другим организмам-носителям, или, другими словами, к репликации;
- изменчивость идей и появление новых идей из комбинации старых, мутация;
- отбор наиболее приспособленных идей как внутри одной головы, так и при общении организмов-носителей между собой.
Подробнее о меметической эволюции:
- «Эгоистичный ген», Ричард Докинз
- «Структура реальности», Дэвид Дойч
Абстрактные концепции игры Го, которыми мы пользуемся в игре, также являются идеями, и они точно так же появились в результате эволюции, после отыгрыша человечеством миллионов партий, обмена опытом и взаимного обучения.
Естественно, что часть игровых концепций родилась из аналогий с обычной жизнью человека («сила», «слабость», «влияние», «убегание», «баланс»). А другая часть, наоборот, родившись в игре, перешла по аналогии в действия в реальном мире («на нападение в одной части доски можно ответить не защитой, а нападением в другой части доски, чтобы не терять темп»).
Подробнее о структуре личности и мышлении:
- «Мозг и душа», Крис Фрит
- «The Ego Tunnel», Thomaz Metzinger
Человечество сегодня---самая эффективная на Земле среда для воспроизводства неспецифичных идей (предположительно, благодаря существованию языка и грамматики, см. «Язык как мышление» Стивена Пинкера).
Благодаря развитию нейробиологии и компьютерных наук мы почти научились создавать новые среды для эволюции идей (чем и является сильный искусственный интеллект). Именно в этом «почти» кроется повод для человеческого оптимизма и выход из «зловещей долины».
- Копии AlphaGo для игры с самой собой создаются и отбираются алгоритмом, написанным человеком (пока что). AlphaGo не может (пока что) самостоятельно побуждать среду к воспроизведению себя.
- Идеи AlphaGo (и других нейронных сетей) узкоспецифичны. AlphaGo отлично играет в Го, но она не умеет писать картины. Deepart умеет писать картины, но не умеет играть в Го.
Похоже, именно это отличие делает AlphaGo «зловещим». Нам кажется, что AlphaGo---злобный гомункул, который идеальной игрой разрушит культуру Го, но это не так.

Привет, человечество!
AlphaGo как расширение средыВсе предметы, которыми мы пользуемся: от зубной щётки до смартфона, это овеществлённые идеи, это расширения наших тел и разумов. Камень в руке питекантропа---продолжение его руки. Это не красивое обобщение, нейрофизиологические исследования показывают, что шимпанзе, держащая в руке палку, воспринимает её кончик как свою руку, включает палку в образ своего тела.
Вы можете легко проверить это на себе: включите любимую музыку и попробуйте стучать о стол дальним кончиком вилки в ритм музыки, как показано на следующем изображении. В этот момент ваше внимание будет сосредоточено именно на кончике вилки, а не в пальцах руки. Если вы сосредоточитесь на пальцах руки, стучать в ритм не получится.

Расширением человеческих тел и мозгов (как среды воспроизводства идей) являются стулья, книги, телефонные сети, интернет, Википедия- Всё, что нас окружает и чем мы пользуемся---расширение среды распространения идей и/или результат их распространения.
Подробнее на эту тему:
- «Понимание медиа», Маршалл Маклюэн
AlphaGo, как и Википедия, это расширение среды распространения Го-идей, артефакт человечества, а не сын:
- нейросеть обучена на смыслах (записях партий), которые созданы в результате деятельности людей;
- нейросеть эволюционирует только вследствие активации отбора людьми,
- нейросеть содержит только идеи относительно игры Го.
Если Википедия---внешняя память человечества, то AlphaGo---внешняя способность человечества играть в Го.
В этом новом расширении пространства для эволюции Го-идей благодаря десяткам миллионов итераций появились новые идеи «балансовости партии», которые невозможно выразить на человеческом языке, потому что они находятся где-то внутри нейросети, а AlphaGo языком не владеет в силу специфичности.
Более того, идеи AlphaGo насчёт правильной игры в Го эффективнее, чем наши, потому что AlphaGo обыгрывает Ли Седоля!
Причина, по которой AlphaGo не претендует на разрушение человеческой культуры Го, проста: новые смыслы, которые уже созданы (sic!) внутри нейросети, никак не передать напрямую обратно в людей.
Го как тренировка сингулярности12 марта 2016 года войдёт в историю как день яркой демонстрации того, что человечество не является исключительной средой для распространения идей.
Эта демонстрация приближает нас к созданию неспецифического (сильного) искусственного интеллекта, и даёт нам возможность подготовиться к нему. Мы получили очень узкую «заводь смыслов Го», специфическое и сверхэффективное расширение человечества как среды распространения идей. Ближайший вызов---научиться сосуществовать с ним. Мы должны это сделать, потому что нам придётся учиться сосуществовать с гораздо более широкими «заводями», принимающими за нас решения о лечении болезней (IBM Watson уже это делает), о путях доставки грузов и движении транспорта, о выборе образовательных программ-
Руководители Google и AlphaGo должны понимать, что вопрос не только в технологии обучения нейросети. Гораздо важнее---интеграция технологий в человеческое общество. Интеграция AlphaGo в Го-сообщество может стать пилотным проектом.
Что может сделать Google?
- Выпустить AlphaGo на игровой сервер.
- Создать рабочую группу, чтобы профессионалы могли экспериментировать с обучением копий AlphaGo на разных начальных выборках.
- Запустить серию экспериментов с различными вариантами начала партии, чтобы развить теорию фусэки.
Это позволит радикально ускорить развитие человеческого понимания Го. Нам придётся смириться, что мы никогда не поймём Го лучше, чем AlphaGo, потому что наш понятийный аппарат не узкоспецифичен для этой задачи. Зато новое понимание Го обогатит набор игровых концепций, которые мы сможем использовать в реальной жизни, в неигровых ситуациях.
Худшее, что может сделать Google---выключить рубильник, просто обкатав технологии (как это сделали IBM с Deep Blue). Го-сообщество велико, и ему нанесён слишком серьёзный психологический удар.
Резюме- Поражение Ли Седоля от AlphaGo---серьёзный прорыв в понимании нами окружающего мира и нас самих. Принципиально бо±льший, чем в случае с шахматами и DeepBlue.
- Нет, AlphaGo---это не SkyNet.
- Да, AlphaGo понимает игру Го лучше человека. Проблема в том, что идеи AlphaGo невозможно изъять из него и перевести на человеческий язык.
- AlphaGo---расширение коллективной памяти и коллективного опыта человека, а не deus ex machina.
- Пока что нейросети специфичны и не автономны. Ждём новых применений, и до чего же это волнительно!
Завершим цитатой из заметки -The Sadness and Beauty of Watching Google-s AI Play Go- в Wired.
Играя матч за матчем против AlphaGo прошедшие пять месяцев, он [Фань Хуэй] замечал, как машина развивается. Но также он замечал, как развивается сам. Этот опыт, буквально, изменил взгляд человека на игру. Когда Фань Хуэй впервые сыграл против программы Google, он был 633-м игроком в мире. Сейчас он входит в 300 сильнейших. За месяцы, прошедшие с октября [2015 года], AlphaGo научила его, человека, играть лучше. Он видит то, что не видел раньше. И поэтому он счастлив. «Так красиво,»---говорит он.---«Так красиво.»
Если вам понравилась эта история, поделитесь ей с другими читателями или нажмите сердечко
Источник: medium.com