Есть ли шанс у AlphaGo в матче против Ли Седоля: мнения и оценки профессиональных игроков в го
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-02-01 22:30

В марте состоится матч го-профессионала 9Pдана и искусственного интеллекта компании Google
Ни один компьютер пока не в состоянии обыграть профессионального игрока в азиатскую настольную игру го. Дело в особенностях игры: позиций слишком много, а интуицию человека сложно описать алгоритмически. Мир придерживался подобных мнений до 27 января. Несколько дней назад компания Google опубликовала данные исследования своего подразделения DeepMind. В нём рассказывается о системе AlphaGo, которая в октябре прошлого года смогла обыграть профессионального игрока второго дана Фань Хуэя в 5 играх из пяти.
Тем не менее у профессиональных игроков и знакомых с го возникли вопросы по качеству игры. ХуэйP- трёхкратный чемпион, но он чемпион Европы, где уровень игры не слишком высок. Вызывает вопросы не только выбор игрока для демонстрации силы AlphaGo, но и некоторые ходы в партиях.
Алгоритм
Го давно считается игрой, обучить в которую искусственный интеллект затруднительно из-за огромного пространства поиска и сложности выбора ходов. Го принадлежит к классу игр с совершенной информацией, то есть игроки знают обо всех ходах, которые ранее совершили другие игроки. Решение задачи поиска исхода игры связано с вычислениями функции оптимального значения в дереве поиска, содержащем приблизительно bd возможных ходов. Здесь bP- это количество корректных ходов в каждой из позиций, а dP- длина игры. Для шахмат эти значения составляют bP-P35 и dP-P80, и полный поиск не представляется возможным. Поэтому позиции фигур оцениваются, а потом оценка учитывается при поиске. В 1996 году компьютер впервые выиграл в шахматы у чемпиона, а с 2005 года ни один чемпион уже не в состоянии выиграть у компьютера.
Для го bP-P250, dP-P150. Возможных позиций камней на стандартной доске более, чем в гугол (10100) раз больше, чем в шахматах. Число возможных позиций больше, чем атомов во Вселенной. Осложняет ситуацию то, что предсказать ценность состояний трудно из-за сложности игры. Два игрока размещают камни двух цветов на доске определённого размера, стандартное полеP- это 19-19 линий. Правила варьируются деталями, но основная цель игры проста: нужно отгородить на доске камнями своего цвета территорию большего, чем соперник, размера.
Существующие программы умеют играть в го на уровне любителей. Они используют поиск в дереве Монте-Карло для оценки ценности каждого состояния в дереве поиска. Также в программы заложены политики, которые предсказывают ходы сильных игроков.
В последнее время глубинные свёртовые нейронные сети смогли добиться хороших результатов в распознавании лиц и классификации изображений. В Google ИИ даже самостоятельно научился играть в 49 старых игр Atari. В AlphaGo похожие нейросети истолковывают положение камней на доске, чем помогают оценить и выбрать ходы. В Google исследователи применили следующий подход: они использовали сети ценности (value networks) и сети политики (policy networks). Затем эти глубинные нейросети обучаются как на множестве партий людей, так и на игре против своих копий. Новым является также поиск, объединяющий метод Монте-Карло с сетями политики и ценности.
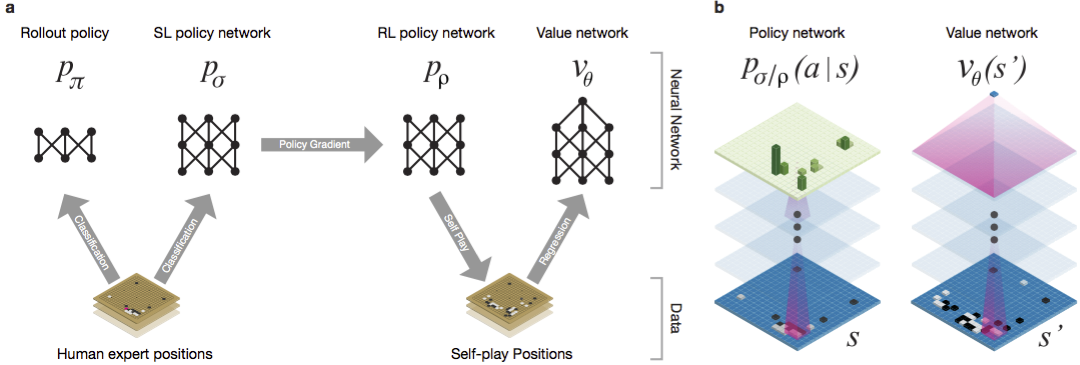
Схема обучения нейросети и архитектура.
Нейросети натренировывали в нескольких стадиях машинного обучения. Сначала проводилось контролируемое обучение сети политики прямо с помощью ходов игроков-людей. Другая сеть политики подвергалась обучению с подкреплением. Вторая играла с первой и оптимизировала её, чтобы политика сдвигалась к выигрышу, а не просто предсказаниям ходов. Наконец, проводилось обучение с подкреплением сети ценности, которая предсказывает победителя игр, в которые играют сети политики. Конечный результатP- это AlphaGo, комбинация метода Монте-Карло и сетей политики и ценности. Был достигнут результат корректного предсказания следующего хода в 57 % случаев. До AlphaGo лучший результат составлял 44 %.
В качестве входных данных для обучения использовались 160Pтыс. игр с 29,4Pмлн позиций с сервера KGS. Брались партии игроков с шестого по девятый дан. Миллион позиций был выделен для тестов, а собственно обучение велось на 28,4Pмлн позиций.
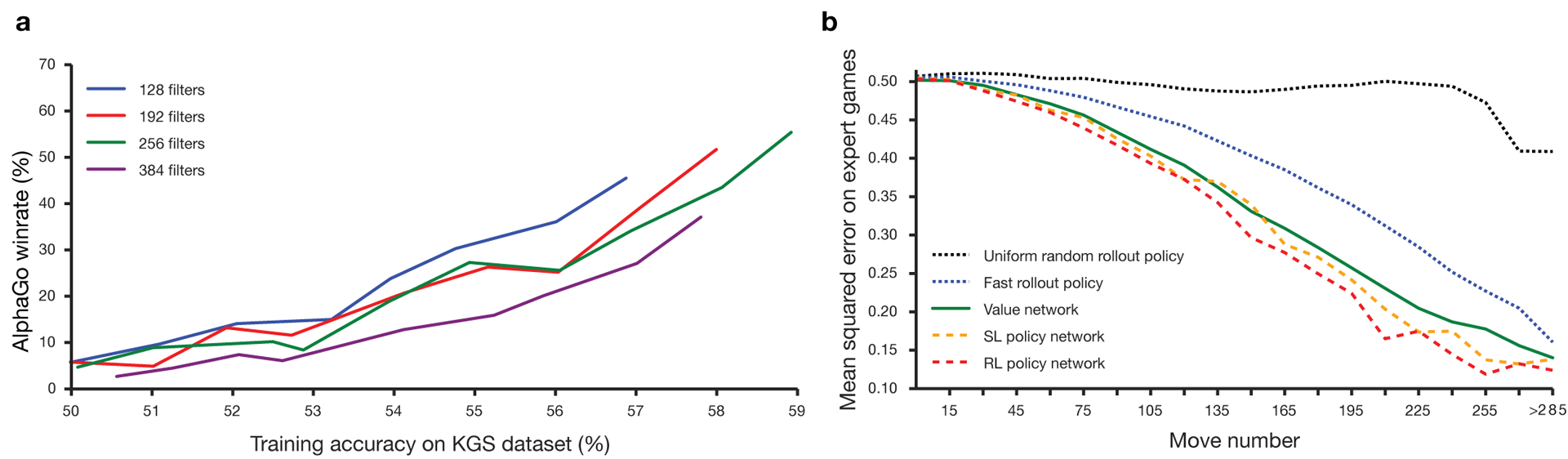
Сила и точность сетей политики и ценности.
Для работы алгоритмов нужны на несколько порядков большие вычислительные мощности, чем при традиционном поиске. AlphaGo представляет из себя асинхронную многопоточную программу, которая выполняет симуляцию на ядрах центрального процессора и запускает сети политики и ценности на видеочипах. Финальная версия выглядела как 40-поточное приложение, запускаемое на 48 процессорах (вероятно, имелись в виду отдельные ядра или даже гиперпоточность) и 8 графических ускорителях. Также была создана распределённая версия AlphaGo, которая использует несколько машин, 40 потоков поиска, 1202 ядер и 176 видеоускорителей.
Полностью с отчётом DeepMind можно ознакомиться в документе.
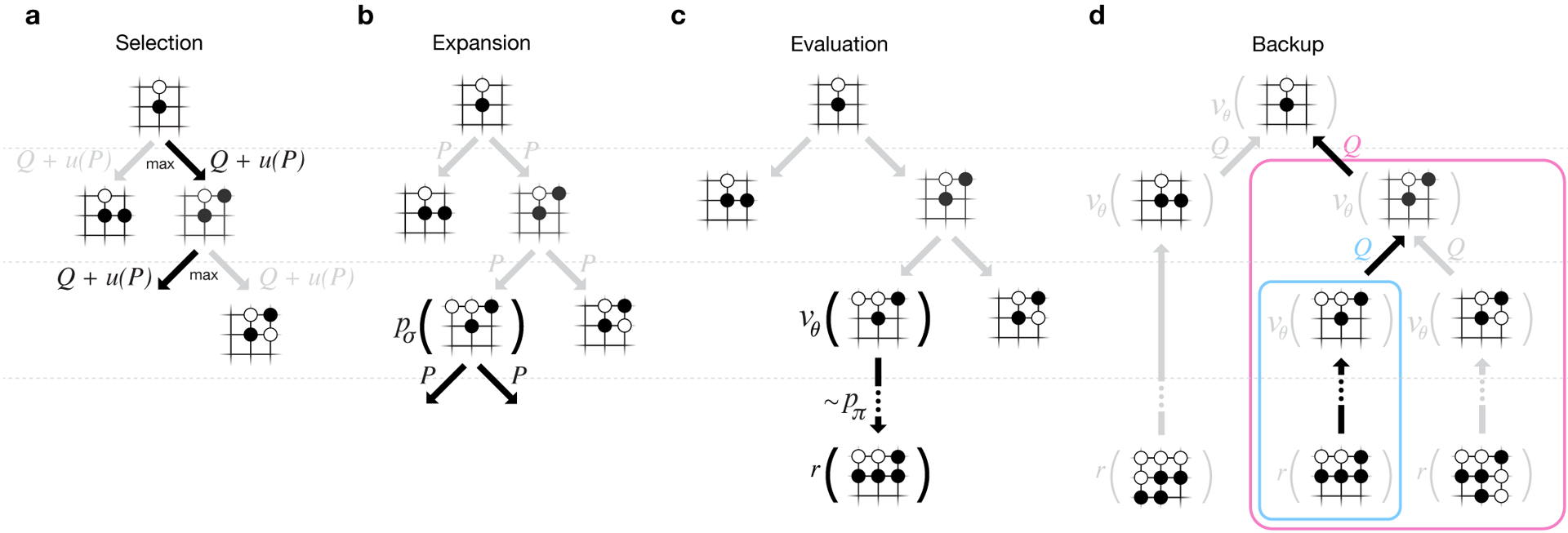
Поиск Монте-Карло в AlphaGo.
Для оценки способностей AlphaGo проводились внутренние матчи как против других версий программы, так и других подобных продуктов. В том числе сравнение велось с такими популярными коммерческими программами, как CrazyPStone и Zen, и сильнейшими открытыми проектами Pachi и Fuego. Все они основаны на высокопроизводительных алгоритмах метода Монте-Карло. Но также AlphaGo сравнили с немонтекарловской GnuGo. Программам отводилось по 5 секунд на ход. Проводилось сравнение как запускаемой на одной машине AlphaGo, так и распределённой версии алгоритма.
Как заявляют разработчики, результаты показали, что AlphaGo на много данов сильнее любых предыдущих го-программ. AlphaGo выиграла 494 из 495 игр, то есть 99,8P% матчей против других подобных продуктов. Правила го допускают фору, гандикап: на поле можно установить до 9 чёрных камней до хода белых. Но даже с 4 камнями форы одномашинная AlphaGo выигрывала в 77P%, 86P% и 99P% случаев против Crazy Stone, Zen и Pachi, соответственно. Распределённая версµ 10000 Ія AlphaGo была значительно сильнее: в 77P% игр она побеждала одномашинную версию и в 100P% игрP- все остальные программы.
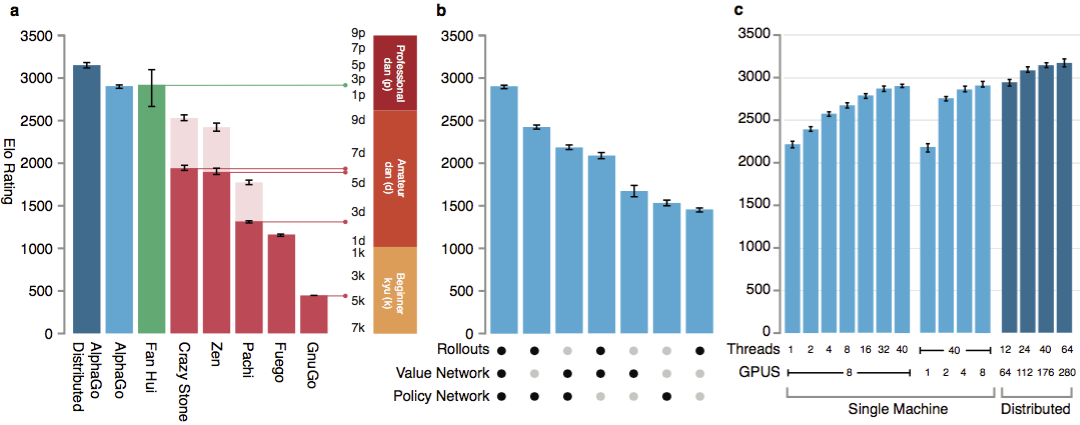
AlphaGo против других программ.
Наконец, созданный продукт сравнили с человеком. Против распределённой версии AlphaGo сразился профессиональный игрок 2 дана, победитель Чемпионата Европы по го в 2013, 2014 и 2015 года Фань Хуэй. Игры проводились при участии судьи из Британской федерации го и редактора журнала Nature. Было проведено 5 игр в период с 5 по 9Pоктября 2015 года. Все из них выиграл алгоритм разработки GooglePDeepMind. Именно эти игры стали поводом к заявлению, что компьютер впервые смог обыграть профессионального игрока в го. Кроме 5 официальных партий были проведены 5 неофициальных, которые не шли в зачёт. Две из них Фань выиграл.
Доступны записи ходов пяти игр, просмотр в веб-виджете и ролики на YouTube.
Критика от профессиональных игроков
Сомнению подвергается выбор профессионального игрока и слабая игра чемпиона. Также неясны выбранные правила: час на партию вместо нескольких часов серьёзных игр. Впрочем, формат выбирал сам Хуэй. В марте AlphaGo будет играть против Ли Седоля. Сможет ли алгоритм обыграть корейского профессионала девятого дана, считающегося одним из лучших игроков в мире? На кону миллион долларов. В случае победы человека его получит Ли Седоль, в случае победы алгоритма он уйдёт на благотворительность.
Исследователи заявляют, что во время октябрьского сражения с человеком система AlphaGo рассматривала в тысячи раз меньше позиций, чем DeepPBlue во время исторического матча с Каспаровым. Вместо этого программа использовала сеть политики для более умного выбора и сеть ценности для более точной оценки позиций. Возможно, подобный подход ближе к тому, как играют люди, говорят исследователи. Кроме того, система оценки Deep Blue была запрограммирована вручную, в то время как нейросети AlphaGo натренированы прямо из партий игры с помощью универсальных алгоритмов контролируемого обучения и обучения с подкреплением.

Ли Седоль попробует свои силы против AlphaGo в марте.
Профессиональные игроки высказывают различные точки зрения. Кому-то кажется, что Google специально выбрала не слишком сильного игрока, кто-то уверен, что Седоль проиграет уже в этом марте.
Один из сильнейших англоговорящих профессиональных игроков в го Ким Менгван (девятый дан) считает, что Фань Хуэй играл не в полную силу. На 51-ой минуте видеоролика он приводит конкретный пример из второй партии. Возможно, Фань играл как с более слабым, чтобы проверить силу компьютера, говорит Ким. Менгван признал, что AlphaGo - шокирующе сильная программа, но она вряд ли сможет победить Ли Седоля.
Судья матча Тоби Мэннинг рассказал в издании British Go Journal о матче. Он провёл анализ всех пяти игр и выделил некоторые моменты. Во второй, третьей и четвёртой партиях AlphaGo допускала ошибки, но Фань не воспользовался ими. Трёхкратный чемпион Европы отвечал собственными. Статья в журнале заканчивается общей положительной оценкой AlphaGo: программа сильна, но неясно, насколько.
Также при подготовке материала я получил комментарии от российских профессионалов и любителей го. Александр Динерштейн (Казань), третий дан (профессиональный), семикратный чемпион Европы:
Максим Подоляк, (Санкт-Петербург), вице-президент «Российской федерации го»:
Александр Крайнов (Москва), любитель игры го:
Что говорит сам Ли Седоль
Профессиональные игроки го соревнуются не за звание чемпиона мира, а за титулы. Признание и статус мастера определяются количеством титулов, которое он смог получить в течение года. Ли Седоль входит в пятёрку сильнейших игроков го в мире, и в марте этого года ему предстоит побороться с системой AlphaGo.
Сам корейский чемпион предсказывает, что он выиграет со счётом 4-1 или 5-0. Но уже через 2-3 года Google захочет взять реванш, и вот тогда игра с обновлённой версией AlphaGo будет интересней, считает Ли.
Задача создания подобного алгоритма ставит новые вопросы о том, что такое обучение и мышление. Как напоминает М.PЕмельянов, третья сверху ступень мастерства (пин) по древней китайской классификации называется «полная ясность». Подобный уровень игры предполагает, что решения принимаются интуитивно, практически не считая варианты. Один из сильнейших мастеров XXPвека Го Сэйгэн говорил, что ему казалось, что он бы выиграл у «го-бога», взяв два или три камня форы. Сэйгэн считал, что почти дошёл до предела понимания игры. Сможет ли нейросеть достичь подобного? Быть может, человеческая интуицияP- это заложенный природой алгоритм?
Автор благодарит Александра Динерштейна и паблик go_secrets за комментарии и помощь в оформлении публикации.
Ни один компьютер пока не в состоянии обыграть профессионального игрока в азиатскую настольную игру го. Дело в особенностях игры: позиций слишком много, а интуицию человека сложно описать алгоритмически. Мир придерживался подобных мнений до 27 января. Несколько дней назад компания Google опубликовала данные исследования своего подразделения DeepMind. В нём рассказывается о системе AlphaGo, которая в октябре прошлого года смогла обыграть профессионального игрока второго дана Фань Хуэя в 5 играх из пяти.
{kind=link}
Тем не менее у профессиональных игроков и знакомых с го возникли вопросы по качеству игры. ХуэйP- трёхкратный чемпион, но он чемпион Европы, где уровень игры не слишком высок. Вызывает вопросы не только выбор игрока для демонстрации силы AlphaGo, но и некоторые ходы в партиях.
Алгоритм
Го давно считается игрой, обучить в которую искусственный интеллект затруднительно из-за огромного пространства поиска и сложности выбора ходов. Го принадлежит к классу игр с совершенной информацией, то есть игроки знают обо всех ходах, которые ранее совершили другие игроки. Решение задачи поиска исхода игры связано с вычислениями функции оптимального значения в дереве поиска, содержащем приблизительно bd возможных ходов. Здесь bP- это количество корректных ходов в каждой из позиций, а dP- длина игры. Для шахмат эти значения составляют bP-P35 и dP-P80, и полный поиск не представляется возможным. Поэтому позиции фигур оцениваются, а потом оценка учитывается при поиске. В 1996 году компьютер впервые выиграл в шахматы у чемпиона, а с 2005 года ни один чемпион уже не в состоянии выиграть у компьютера.
Для го bP-P250, dP-P150. Возможных позиций камней на стандартной доске более, чем в гугол (10100) раз больше, чем в шахматах. Число возможных позиций больше, чем атомов во Вселенной. Осложняет ситуацию то, что предсказать ценность состояний трудно из-за сложности игры. Два игрока размещают камни двух цветов на доске определённого размера, стандартное полеP- это 19-19 линий. Правила варьируются деталями, но основная цель игры проста: нужно отгородить на доске камнями своего цвета территорию большего, чем соперник, размера.
Существующие программы умеют играть в го на уровне любителей. Они используют поиск в дереве Монте-Карло для оценки ценности каждого состояния в дереве поиска. Также в программы заложены политики, которые предсказывают ходы сильных игроков.
В последнее время глубинные свёртовые нейронные сети смогли добиться хороших результатов в распознавании лиц и классификации изображений. В Google ИИ даже самостоятельно научился играть в 49 старых игр Atari. В AlphaGo похожие нейросети истолковывают положение камней на доске, чем помогают оценить и выбрать ходы. В Google исследователи применили следующий подход: они использовали сети ценности (value networks) и сети политики (policy networks). Затем эти глубинные нейросети обучаются как на множестве партий людей, так и на игре против своих копий. Новым является также поиск, объединяющий метод Монте-Карло с сетями политики и ценности.
Схема обучения нейросети и архитектура.
Нейросети натренировывали в нескольких стадиях машинного обучения. Сначала проводилось контролируемое обучение сети политики прямо с помощью ходов игроков-людей. Другая сеть политики подвергалась обучению с подкреплением. Вторая играла с первой и оптимизировала её, чтобы политика сдвигалась к выигрышу, а не просто предсказаниям ходов. Наконец, проводилось обучение с подкреплением сети ценности, которая предсказывает победителя игр, в которые играют сети политики. Конечный результатP- это AlphaGo, комбинация метода Монте-Карло и сетей политики и ценности. Был достигнут результат корректного предсказания следующего хода в 57 % случаев. До AlphaGo лучший результат составлял 44 %.
В качестве входных данных для обучения использовались 160Pтыс. игр с 29,4Pмлн позиций с сервера KGS. Брались партии игроков с шестого по девятый дан. Миллион позиций был выделен для тестов, а собственно обучение велось на 28,4Pмлн позиций.
Сила и точность сетей политики и ценности.
Для работы алгоритмов нужны на несколько порядков большие вычислительные мощности, чем при традиционном поиске. AlphaGo представляет из себя асинхронную многопоточную программу, которая выполняет симуляцию на ядрах центрального процессора и запускает сети политики и ценности на видеочипах. Финальная версия выглядела как 40-поточное приложение, запускаемое на 48 процессорах (вероятно, имелись в виду отдельные ядра или даже гиперпоточность) и 8 графических ускорителях. Также была создана распределённая версия AlphaGo, которая использует несколько машин, 40 потоков поиска, 1202 ядер и 176 видеоускорителей.
Полностью с отчётом DeepMind можно ознакомиться в документе.
Поиск Монте-Карло в AlphaGo.
Для оценки способностей AlphaGo проводились внутренние матчи как против других версий программы, так и других подобных продуктов. В том числе сравнение велось с такими популярными коммерческими программами, как CrazyPStone и Zen, и сильнейшими открытыми проектами Pachi и Fuego. Все они основаны на высокопроизводительных алгоритмах метода Монте-Карло. Но также AlphaGo сравнили с немонтекарловской GnuGo. Программам отводилось по 5 секунд на ход. Проводилось сравнение как запускаемой на одной машине AlphaGo, так и распределённой версии алгоритма.
Как заявляют разработчики, результаты показали, что AlphaGo на много данов сильнее любых предыдущих го-программ. AlphaGo выиграла 494 из 495 игр, то есть 99,8P% матчей против других подобных продуктов. Правила го допускают фору, гандикап: на поле можно установить до 9 чёрных камней до хода белых. Но даже с 4 камнями форы одномашинная AlphaGo выигрывала в 77P%, 86P% и 99P% случаев против Crazy Stone, Zen и Pachi, соответственно. Распределённая версµ 10000 Ія AlphaGo была значительно сильнее: в 77P% игр она побеждала одномашинную версию и в 100P% игрP- все остальные программы.
AlphaGo против других программ.
Наконец, созданный продукт сравнили с человеком. Против распределённой версии AlphaGo сразился профессиональный игрок 2 дана, победитель Чемпионата Европы по го в 2013, 2014 и 2015 года Фань Хуэй. Игры проводились при участии судьи из Британской федерации го и редактора журнала Nature. Было проведено 5 игр в период с 5 по 9Pоктября 2015 года. Все из них выиграл алгоритм разработки GooglePDeepMind. Именно эти игры стали поводом к заявлению, что компьютер впервые смог обыграть профессионального игрока в го. Кроме 5 официальных партий были проведены 5 неофициальных, которые не шли в зачёт. Две из них Фань выиграл.
Доступны записи ходов пяти игр, просмотр в веб-виджете и ролики на YouTube.
Критика от профессиональных игроков
Сомнению подвергается выбор профессионального игрока и слабая игра чемпиона. Также неясны выбранные правила: час на партию вместо нескольких часов серьёзных игр. Впрочем, формат выбирал сам Хуэй. В марте AlphaGo будет играть против Ли Седоля. Сможет ли алгоритм обыграть корейского профессионала девятого дана, считающегося одним из лучших игроков в мире? На кону миллион долларов. В случае победы человека его получит Ли Седоль, в случае победы алгоритма он уйдёт на благотворительность.
Исследователи заявляют, что во время октябрьского сражения с человеком система AlphaGo рассматривала в тысячи раз меньше позиций, чем DeepPBlue во время исторического матча с Каспаровым. Вместо этого программа использовала сеть политики для более умного выбора и сеть ценности для более точной оценки позиций. Возможно, подобный подход ближе к тому, как играют люди, говорят исследователи. Кроме того, система оценки Deep Blue была запрограммирована вручную, в то время как нейросети AlphaGo натренированы прямо из партий игры с помощью универсальных алгоритмов контролируемого обучения и обучения с подкреплением.
Ли Седоль попробует свои силы против AlphaGo в марте.
Профессиональные игроки высказывают различные точки зрения. Кому-то кажется, что Google специально выбрала не слишком сильного игрока, кто-то уверен, что Седоль проиграет уже в этом марте.
Один из сильнейших англоговорящих профессиональных игроков в го Ким Менгван (девятый дан) считает, что Фань Хуэй играл не в полную силу. На 51-ой минуте видеоролика он приводит конкретный пример из второй партии. Возможно, Фань играл как с более слабым, чтобы проверить силу компьютера, говорит Ким. Менгван признал, что AlphaGo - шокирующе сильная программа, но она вряд ли сможет победить Ли Седоля.
Судья матча Тоби Мэннинг рассказал в издании British Go Journal о матче. Он провёл анализ всех пяти игр и выделил некоторые моменты. Во второй, третьей и четвёртой партиях AlphaGo допускала ошибки, но Фань не воспользовался ими. Трёхкратный чемпион Европы отвечал собственными. Статья в журнале заканчивается общей положительной оценкой AlphaGo: программа сильна, но неясно, насколько.
Также при подготовке материала я получил комментарии от российских профессионалов и любителей го. Александр Динерштейн (Казань), третий дан (профессиональный), семикратный чемпион Европы:
В матчах с Каспаровым над дебютом программы Deep Blue работала целая группа сильных гроссмейстеров. Возможно, что и к матчу с Ли Седолем такая команда будет собрана, но по матчу с Фань видно, что работа в этом направлении не велась в принципе. Сильнейший игрок в го из команды Google играет в силу пятого любительского дана. Это уровень четырёх камней форы с Ли Седолем.
Во всех партиях с Фань программа играла в точку 4-4 (хоси по-японски, starpoint на английском). Кроме нее есть много других возможных начал. Из распространенных: 3-3, 3-4, 5-3, плюс есть разные нестандартные дебюты, где первым ходом играют, к примеру, в центр доски. С точки зрения дебютных новинок, программа не показала ничего нового. В этом отношении она играла очень примитивно.
Дебюты, которые применял Фань, просто были забиты в ее базу. Ничего нестандартного он не использовал. Для меня это остается большим вопросом - как будет действовать программа, если с первых же ходов свернуть с дебютных справочников. На пустой доске вариантов столько, что никаким методом Монте-Карло их не просчитать. В этом го выгодно отличается от шахмат. В шахматах всё давно изучено на глубину 20-30 ходов, а в го, при желании, уже первым ходом можно создать позицию, которая не встречалось в истории профессионального го. Программе придется играть самостоятельно, а не вытаскивать варианты из базы знаний. Посмотрим, сможет ли она это сделать. Я в этом сильно сомневаюсь и ставлю на Ли Седоля.
Кстати, в Санкт-Петербурге летом 2016 года должен состояться Чемпионат Европы по го (EGC), в рамках которого всегда проходит турнир компьютерных программ. «Российская федерация го» пригласила к участию в турнире все сильнейшие программы. Если они примут приглашение, то возможно, именно на этом турнире впервые сыграют между собой программы Google и Facebook. Последняя, в отличие от своего конкурента, идёт честным путем. Бот DarkForest играет тысячи партий на сервере KGS. Сильнейшая версия приближается к шестому дану на сервере. Это очень неплохой уровень. Фань Хуэй и игроки его уровня - это примерно восьмой дан на сервере (из девяти возможных). Разница составляет примерно два камня форы. При такой разнице программа действительно может иногда обыгрывать человека. Если на равных - то примерно в одной партии из десяти.
Максим Подоляк, (Санкт-Петербург), вице-президент «Российской федерации го»:
Мне трудно поверить в то, что крупнейший разработчик ПО приступает к решению сложнейшей, а вообще говоря, неразрешимой, задачи, никак не освещает свою работу, не показывает промежуточные результаты, успешные или нет, и сразу достигает грандиознейшего успеха. Скорее я поверю в то, что Google разработал прекрасный рекламный ход: нашёл не самого сильного игрока с профессиональным статусом и чемпионским титулом, который на некоторых условиях согласится не очень убедительно сыграть. Вот это очень похоже на мир, который я знаю. Простое и понятное решение: никаких рисков, никакого судебного преследования за обман, никаких последствий, только сравнительно небольшой гонорар живому участнику. А плюсы настолько велики, что трудно представить: главный конкурент отправлен в нокаут, весь мир гремит о грандиозном успехе и невиданном прорыве. Google может всё. Даже если позже обман и вскроется, то этого никто не заметит. Да и кто его вскроет? Кто проверит качество теста?
Александр Крайнов (Москва), любитель игры го:
Я, в силу профессиональной деятельности, довольно хорошо знаю ситуацию «с той стороны».
В 2012 году в области машинного обучения в целом произошел качественный скачок. Количество данных для обучения, уровень алгоритмов и мощности для обучения вышли на такой уровень, что искусственные нейронные сети (разработанные как принцип довольно давно) стали давать фантастические результаты.
Принципиальное отличие обучения на нейронных сетях заключается в том, что им не надо давать на вход факторы (в случае го, объяснять, например, какие формы являются хорошими). Им в пределе даже правила можно не объяснять. Главное дать большое количество положительных (ходы выигрышной стороны) и отрицательных (ходы проигравшей стороны) примеров. И сеть научится сама.
Как только алгоритм выходит на высокий уровень игры, программа может играть сама с собой огромное количество партий, обучаясь на результате. Причем не обязательно партии доигрывать. Можно делать так: берётся любая позиция, сеть предсказывает несколько хороших ходов, ходы просчитываются (используя традиционные алгоритмы перебора по дереву решений) насколько возможно, результат добавляется в обучающую выборку.
Я бы не рекомендовал делать ставки на Седоля, ориентируясь на игру программы с Фань.
Мы, грубо говоря, наблюдая за игрой программы, наблюдаем за игрой талантливого четырёхлетнего ребенка. К моменту игры с Седолем в марте он может сильно прибавить. Нейросетевые модели сейчас очень быстро обучаются при достаточном количестве данных. А в случае с го данных очень много. Плюс, как я сказал раньше, их можно генерировать.
Что говорит сам Ли Седоль
Профессиональные игроки го соревнуются не за звание чемпиона мира, а за титулы. Признание и статус мастера определяются количеством титулов, которое он смог получить в течение года. Ли Седоль входит в пятёрку сильнейших игроков го в мире, и в марте этого года ему предстоит побороться с системой AlphaGo.
Сам корейский чемпион предсказывает, что он выиграет со счётом 4-1 или 5-0. Но уже через 2-3 года Google захочет взять реванш, и вот тогда игра с обновлённой версией AlphaGo будет интересней, считает Ли.
Задача создания подобного алгоритма ставит новые вопросы о том, что такое обучение и мышление. Как напоминает М.PЕмельянов, третья сверху ступень мастерства (пин) по древней китайской классификации называется «полная ясность». Подобный уровень игры предполагает, что решения принимаются интуитивно, практически не считая варианты. Один из сильнейших мастеров XXPвека Го Сэйгэн говорил, что ему казалось, что он бы выиграл у «го-бога», взяв два или три камня форы. Сэйгэн считал, что почти дошёл до предела понимания игры. Сможет ли нейросеть достичь подобного? Быть может, человеческая интуицияP- это заложенный природой алгоритм?
Автор благодарит Александра Динерштейна и паблик go_secrets за комментарии и помощь в оформлении публикации.
Источник: geektimes.ru