Эксперимент: создание алгоритма для прогнозирования поведения фондовых индексов
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Искусственный интеллект
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Разработка ИИГолосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИКомпьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2016-02-27 07:20
большие данные big data, генетические алгоритмы, биологические нейронные сети, искусственный интеллект

Ученые факультета вычислительной техники из исламского университета Азад, расположенного в ОАЭ, опубликовали работу, посвященную прогнозированию поведения фондовых индексов на основе технологий нейронных сетей, генетических алгоритмов и data mining с использованием опорных векторов. Мы представляем вашему вниманию главные мысли этого документа.
Введение
Одним из популярных направлений финансово анализа в последние годы является прогнозирование цен акций и поведения фондовых индексов на основе данных о предыдущих торговых периодах. Для получения сколько-нибудь релевантных результатов необходимо использование подходящих инструментов и корректных алгоритмов.
Ученые поставили своей целью разработку специального софта, который бы мог генерировать прогнозы поведения фондовых индексов с помощью предиктивных алгоритмов и математических правил.
Фондовые индексы сами по себе непредсказуемы, поскольку зависят не только от экономических событий, но на них также влияет и политическая обстановка в разных частях света. Поэтому разработать математическую модель для обработки таких непредсказуемых, нелинейных и непараметрических временных рядов крайне сложно.
При работе на фондовом рынке используют два вида анализа.
1) Технический анализ
Применяется для краткосрочных финансовых стратегий. Он используется для прогнозирования изменения цен на основе закономерностей и изменении цен схожим образом в прошлом. Как правило, анализируются графики цен, на которых выделяются паттерны определенных закономерности в ценовой динамике. Помимо изучения динамики изменения цены, в техническом анализе используется информация об объёмах торгов и другие статистические данные.
2) Фундаментальный анализ
Для долгосрочных стратегий инвестирования используется фундаментальный анализ. Он подразумевает использования для прогнозирования цены акций определенной компании, информацию о финансовых и прозводственных показателях ее деятельности.
Также, при прогнозировании возможных движений цен необходимо понимать существующие на финансовом рынке риски для действующих на нем игроков:
- Торговый риск - объём средств, которым рискует трейдер. К примеру, если он покупает финансовый актив на тысячу долларов, то торговый риск будет равняться этой сумме.
- Рыночный риск - что может случиться на рынке под влиянием в том числе глобальных экономических событий или событий в конкретной стране, где расположен финансовый рынок или акции компаний из которой торгуются на бирже.
- Маржинальный риск - если для совершения сделок используются заемные средства, возникает маржинальный риск. Взятые «в долг», к примеру, у брокера, деньги в конечном итоге придется вернуть, и если у трейдера будет недостаточно свободных средств на счете для этого, то его позиции будут принудительно закрыты даже если это не подразумевалось его торговой стратегией.
- Риск ликвидности - не из каждого финансового инструмента можно быстро «выйти».
- Риск переноса позиций «овернайт» - сохранение позиций в промежуток между торговыми днями или на протяжении нескольких торговых дней несет в себе риск, поскольку трейдер не может знать, что случится в то время, когда биржа не работает. Возможно на открытие торгового дня повлияет какое-то событие, и цена акций сразу сместится невыгодным для инвестора образом.
- Риск волатильности - цена акций колеблется в определенных диапазонах. Чем шире диапазон колебания цены, тем выше волатильность конкретного финансового инструмента.
Прогнозирование поведения фондовых индексов
Одним из популярных инструментов, использующихся для решения задач прогнозирования цен акций, является дерево принятия решений. В свою очередь, наиболее эффективным методом сбора и анализа данных является data mining. Существует несколько моделей использования data mining, которые реализуют различные подходы к сбору и анализу полученной информации.
В нашем случае исследователи выбрали модель CRISP-DM (Cross-Identity Standard Process for Data Mining). Данный метод был разработан консорциумом европейских компаний в середине девяностых годов прошлого века. Модель включает семь основных шагов:
- Определение целей для поиска информации (данные о каких акциях нужны).
- Поиск нужных данных.
- Упорядочивание данных в модели классификации.
- Выбор техники для реализации модели.
- Оценка модели с помощью известных методов.
- Применение модели в текущих рыночных условиях для генерации рекомендации о целевом действии - к примеру, покупка или продажа акции.
- Оценка полученных результатов.
После сбора данных для принятия решений используется дерево классификации. У такого подхода есть три основных преимущества: он быстрый, простой и позволяет добиваться высокой точности. В качестве параметров модели в данном случае были выбраны предыдущая цена, цена открытия, максимум, минимум, закрытие и целевое действие (previous, open, max, min, last, action).
Также для прогнозирования используются генетические алгоритмы. Они применяются для решения сложных проблем, в тех случаях, когда точные отношения между задействованными элементами неизвестны и могут в принципе отсутствовать.
Задача формализуется так, чтобы ее решение могло был закодировано в виде вектора генов («генотип»), где каждый ген может представлять бит, число или какой-либо другой объект. Далее случайным образом создается множество генотипов начальной «популяции», которые оцениваются с помощью специальной функции приспособленности. В итоге каждому генотипу присваивается значение «приспособленности» - именно оно определяет, насколько хорошо он решает задачу.
Для постоянной оптимизации параметров, задействованных в торговой стратегии, используются методы оптимизации. К примеру, ген может быть представлен в виде вектора, а соответствующий алгоритм оптимизации применяет к нему механизм промежуточной рекомбинации.
Одним из методов генерирования предсказаний о будущих движениях цен является машинное обучение. В данном случае исследователи использовали метод опорных векторов. Исследователи собрали финансовые данные с биржи NASDAQ, а также о некоторых финансовых инструментах и индексах. В резульате для NASDAQ точность предсказаний, сгенерированных системой, составила 74.4%, 77,6% для индекса DJIA и 76% для S&P500.
Для машинного обучения использовались следующие формулы:
Прежде всего, определялось xi(t), где i - {1, 2, -}.
F = (X1, X2, - Xn)T, где

Для оценки используемой модели использовался метод вычисления среднеквадратичной ошибки (RMSE, Root of Mean Square Error):

Мультиклассовая классификация
Для минимизации рисков и повышения прибыли используется модель опорных векторов. Она подразумевает классификацию данных в три категорий: позитивную, негативную и нейтральную. Это помогает выявлять наиболее рискованные прогнозы и отклонять их. Для создания такого мультиклассового классификатора, неободимо определить ширину центральной зоны:

tp: true positive
fp: false positive
fn: false negative
Предложенная модель
Как было отмечено выше, собираемые данные имели шесть атрибутов. Для использования в дереве принятия решений данные должны быть конвертированы в дискретные значения. Для этого можно использовать критерий, основанный на цене закрытия рынка. В случае, если величина open, max, min и last превышает предыдущее значение атрибута в ходе текущего торгового дня, то позитивное значение должно быть заменено на предыдущий атрибут. Напротив, негативное значение устанавливается вместо предыдущего атрибута, а если значения равны, то устанавливается соответствующий атрибут.
Вот так выглядит набор данных по шести атрибутам до их перевода в дискретные значения:
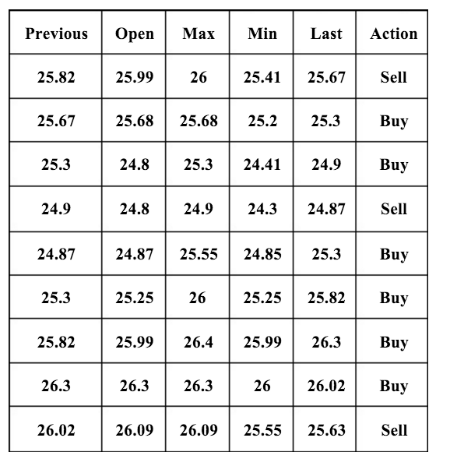
А вот так после перевода:

После получения такого набора дискретных значений необходимо построить модель классификации с помощью дерева принятия решения.
В данном исследовании рассматривается два возможных сценария действий.
Сценарий #1
Необходимо проделать следующие действия:
- Собрать финансовые данные о торгах за 30 дней.
- Выделить данные по шести атрибутам в 9 моментов времени в течение одного торгового дня.
- Для каждого набора сформировать матрицу.
- Вычислить XX^T и применить метод опорных векторов для генерирования собственного значения.
- Вычисление среднего объёма продаж и покупок.
- Вычисление среднего значения каждого торгового дня.
- Присвоение разных весов для первого дня, седьмого и тридцатого дня, а также среднего значения месяца.
- Для генерирования рекомендации о действии необходимо сравнить текущее значение с первым, седьмым, тридцатым днем, а также средним значением за весь месяц.
- Если результат предсказания за 4 торговых дня одинаковый, то следует осуществить покупку, если присутствует совпадение для трех торговых дней, то покупка будет иметь риск в 25%, для двух дней риск составит 50%.
Для каждого торгового дня из тридцати необходимо сгенерировать матрицу, в которой Xi представляет девять разных моментов в течение одного дня:

После этого вычисляется R = XXT - каждую матрицу нужно умножить на транспонированную версию. Затем подсчитывается опорный вектор и его собственное значение.
Сценарий 2
В данном случае выполняются все те же шаги, однако метод опорных векторов применяется не к «сырым» данным, а к матрице, полученной после автокорреляции. Для каждого торгового дня генерируется матрица автокорреляции:

Здесь используется следующая формула:

После автокорреляции мы получаем новую матрицу (матрицу Теплица):

И уже для нее подсчитывается опорный вектор и собственное значение. Для сравнения отклонения от среднего значения среди различных торговых дней, вычисляется среднее значение, дисперсия и стандартное отклонение, которые хранятся в векторе.
Заключение
Для получения наилучших результатов исследователи применили все описанные методы шаг за шагом: начиная с фундаментального анализа, использования генетического алгоритма, нейронных сетей, машинного обучения и метода опорных векторов.

При этом добиться стопроцентной точности прогнозов изменения значений фондовых индексов добиться не удалось. Для различных финансовых инструментов точность предсказания поведения индексов на промежутке в один торговый день довольно сильно отличается:
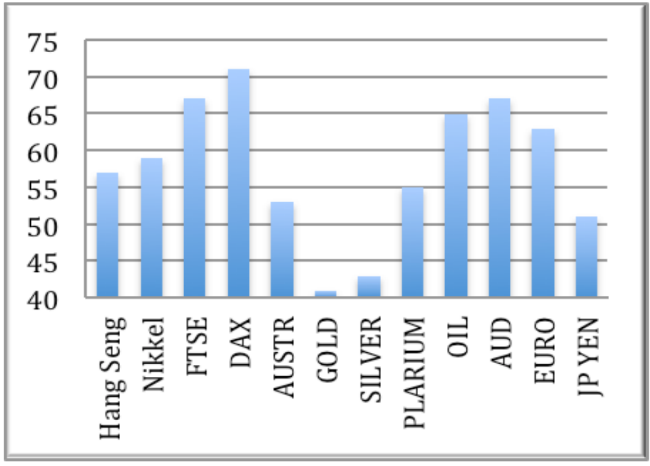
Наилучшим результатом стала точность в 70,8% для немецкого индекса DAX. Для достижения большей точности при долгосрочных прогнозах (период больше 30 дней), использовалась следующая формула:
Pr {vt+1 - vt > ct }, где ct = -(vt-ts - vt)
В этом случае наилучший результат точности прогноза составил 85,0%.
Другие материалы о прогнозировании цен акций и использовании алгоритмов на фондовом рынке:
- Техники машинного обучения для прогнозирования цен акций: функции индикаторов и анализ новостей
- Как предсказать цену акций: Алгоритм адаптивной фильтрации
- Обнаружение инсайдерской торговли: Алгоритмы выявления и паттерны незаконных сделок
- Машинное обучение как способ анализа микроструктуры рынка и его применение в высокочастотном трейдинге
- Алгоритмы и торговля на бирже: Скрытие крупных сделок и предсказание цены акций
Источник: habrahabr.ru